Webページ上の大量のデータを、プログラムを使って効率よく収集したいと思ったことはありませんか?手作業で情報をコピー&ペーストするのは手間がかかり、時間もかかります。特に、商品情報や記事データ、リンクの一覧などを大量に取得したい場合、手動での収集は現実的ではありません。
本記事では、Pythonを使用してHTMLからテキストやURLを取得・抽出する方法について、サンプルコードを交えながら解説します。
PythonでテキストやURLを取得する方法とは
はじめに、PythonでテキストやURLを取得するための方法を解説します。ここでは、HTMLの構造やライブラリ、スクレイピングについて学びましょう。
HTML構造の理解
Webページからデータを取得するには、まずHTMLを理解する必要があります。HTMLはWebページの構造を定義するマークアップ言語であり、要素(タグ)を使ってテキストや画像、リンクなどを配置します。たとえば、<p>タグは段落を、<a>タグはリンクを表します。
<html>
<body>
<h1>スクレイピングの基礎</h1>
<p>Pythonを使えば簡単にWebページの情報を取得できます。</p>
<a href="https://example.com">詳しくはこちら</a>
</body>
</html>
上記のHTMLコードだと、以下のようなWebページを作ることができます。
Pythonで情報を取得する際は、HTMLのタグ構造を把握することが重要です。
実際のWebページのHTMLを確認するには、ブラウザ上を右クリックから「ページのソースを表示」または「Ctrl + U」から閲覧が可能です。
プログラミング言語、ライブラリの理解
スクレイピングにはさまざまなプログラミング言語が使えますが、Pythonは特に適しています。その理由は、シンプルな構文で学習しやすく、スクレイピングに必要なライブラリが充実しているためです。
Pythonで利用できる、スクレイピングに適したライブラリはrequests、BeautifulSoup、Seleniumなどがあります。各ライブラリの特徴は以下の通りです。
| ライブラリ | 用途 |
|---|---|
| requests | WebページのHTML取得 |
| BeautifulSoup | HTMLなど静的データの取得 |
| Selenium | JavaScriptなど動的データの取得 |
スクレイピング
スクレイピングは、Webページから特定の情報を自動的に取得する技術です。
手作業でコピー・ペーストするのと違い、短時間で大量のデータを収集できるため、データ分析や情報収集の分野で活用されています。
スクレイピングを実施するには、上述した通りまずHTMLやデータソースの構造を理解し、適切なライブラリを選定しましょう。
ただし、スクレイピングをする際にはいくつかの注意点もあります。
詳しくは下記の記事をご参照ください。
Webスクレイピングは違法?合法的なやり方と禁止サイトの確認方法を解説
【サンプルコード付き】PythonでHTMLソースを取得する方法
ここまで、スクレイピングに必要なHTML構造やライブラリの種類などを紹介しました。
ここからは、実際にPythonを使ってHTMLソースを取得する方法について解説します。
今回はexample.comというサイトを実際にスクレイピングしていきましょう。
BeautifulSoupでHTMLを取得する
BeautifulSoupは、PythonでHTMLを解析し、特定の情報を簡単に取得できるライブラリです。
静的なWebページを取得する際は、requestsと組み合わせて利用します。
まず、コマンドプロンプトやターミナルから、以下のコマンドでBeautifulSoupとrequestsをインストールします。
pip install beautifulsoup4 requests
次に、Pythonでコードを記述します。「test.py」としてデスクトップに保存します。
今回は、example.comのHTML全体を抽出してみましょう。
import requests
from bs4 import BeautifulSoup
# 解析するWebサイトのURL
url = "https://example.com" # 解析したいURL
# HTMLを取得
response = requests.get(url)
# BeautifulSoupで解析
soup = BeautifulSoup(response.content, "html.parser")
# HTML全体を出力
print(soup.prettify())
最後にコマンドプロンプトやターミナルからプログラムを実行すると、無事HTMLコードが取得できます。
Desktop> python .\test.py
<!DOCTYPE html>
<html>
<head>
<title>
Example Domain
</title>
<meta charset="utf-8"/>
…以下略
もしURLを取得したい場合は、soup.find("a") や soup.select("a") を使って <a> タグの href 属性を取得できます。
# ページ内のすべてのリンクを取得
links = [a["href"] for a in soup.find_all("a") if a.get("href")]
print(links)
SeleniumでHTMLを取得する
Seleniumは、ブラウザを自動操作しながらWebページを取得できるライブラリです。
以下のコマンドでライブラリをインストールしましょう。
また、Webブラウザを操作するためのWebDriverのインストールします。
pip install selenium
pip install webdriver-manager
BeautifulSoupと同様に、test-2.pyとして以下のコードを記述しましょう。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# WebDriverのセットアップ
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
# 指定したURLを開く
url = "https://example.com"
driver.get(url)
# ページのHTMLを取得
html = driver.page_source
print(html)
# ブラウザを閉じる
driver.quit()
BeautifulSoupと同様の手順でプログラムを実行すると、対象WebページのHTMLを取得できます。
もしURLを取得したい場合は、driver.find_element() や driver.find_elements() を使用して、ページ内の <a> タグの href 属性を取得できます。
# ページ内のすべてのリンクを取得
links = [a.get_attribute("href") for a in driver.find_elements("tag name", "a") if a.get_attribute("href")]
print(links)
Pythonを使わずにスクレイピングをするには?
ここまで、Pythonを使ったスクレイピングを紹介しましたが、プログラミングが難しいと感じた人もいるでしょう。
最後に、プログラミング知識不要でスクレイピングができる「Octoparse」をご紹介します。
スクレイピングツール「Octoparse」を利用する
Octoparseは、プログラミング不要でWebデータを取得できるスクレイピングツールです。クリックでWebページの情報の抽出・保存が可能です。上記で述べたような、HTMLやライブラリの知識も必要ありません。
データ収集用のテンプレートも豊富で、導入後すぐに大規模なデータ収集ができます。
詳しくは、 【活用事例】Webスクレイピングでビジネスを成長させる方法30選をご覧ください。
Octoparseを使ったスクレイピングの方法
Octoparseを使ったスクレイピングの例をご紹介します。
例えば、ニュース記事の「タイトル」を取得したいとしましょう。
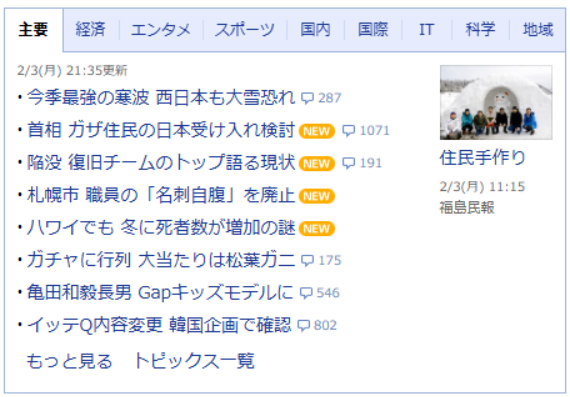
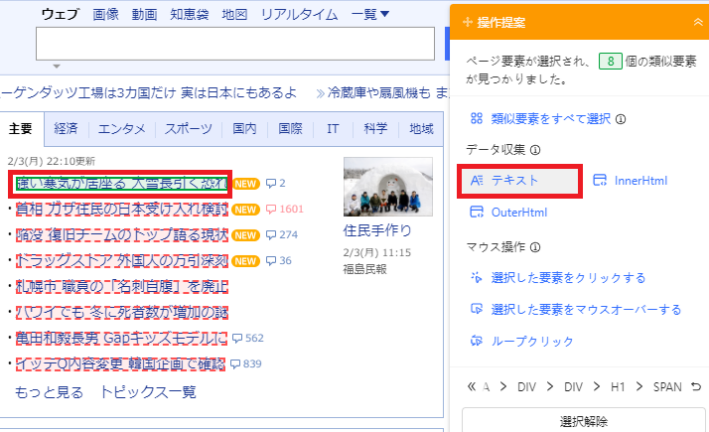
- Octoparse上で取得したいURLを入力し、「テキスト」をクリックします。
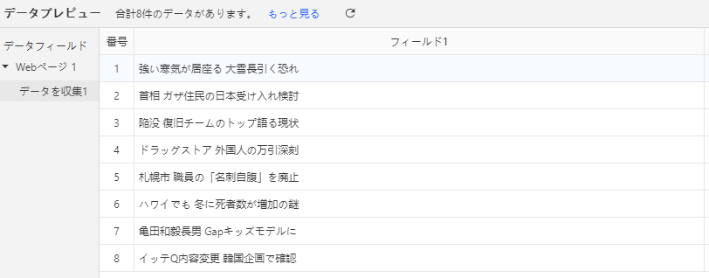
2.データプレビュー画面に早速8件のデータが表示されました。Octoparseでは、要素をクリックすると同列の情報を一括で取得できるようになっています。
3.最後に、「実行する」ボタンをクリックすると、自動でデータの取得が行われます。
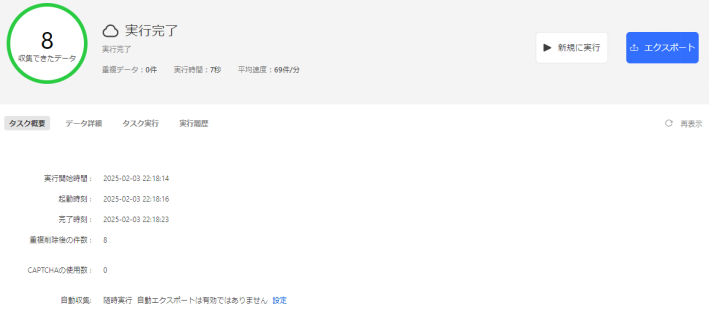
いかがでしょうか。
今回の検証もOctoparseのツールを立ち上げて約2分でスクレイピングまでできました。プログラミングを学習するコストや期間を考えると、スクレイピングツールを活用した方が効率的にデータ収集できることが分かります。
まとめ
本記事では、Pythonを使ったスクレイピングの方法を、サンプルコードを交えて詳しく解説しました。データを手動で取得するのは労力が必要ですが、スクレイピングを活用することで、効率的に情報収集が可能となります。
しかし、Pythonによるスクレイピングは多くの学習コストが必要です。学習後も対象Webページの調査やエラー対応など開発コストも掛かるでしょう。
そのため、プログラミングなしでスクレイピングを実行できる、Octoparseのようなノーコードツールを活用するのも一つの選択肢となります。
どの方法を選ぶかは、取得したいデータの種類や、技術習得にかけられる時間によって異なります。本記事を参考に、自身に最適なスクレイピングの手法を見つけ、効率的よくデータを取得しましょう。