
元記事:https://www.octoparse.jp/blog/build-a-web-crawler-with-selenium-and-python/
Webサイトから大量のデータをできるだけ早く取得する必要があるとします。それぞれのWebサイトに手動でアクセスして、コピペでデータを取得することなく、どうやって自動的にデータを取得するのでしょうか?その答えが「Webスクレイピング」です。Webスクレイピングに通じて、この作業を自動化にしてくれます。
今回はPythonでWebサイトからデータをクローニングして、CSVファイルに書き込むというようなWebクローラーを実際に作成してみましょう。
一、必要なPython開発環境を導入
Pythonには、プログラムを組むために便利な標準ライブラリが数多くあります。今回は、以下のライブラリを使用しています。
・Selenium ーー ブラウザを自動的に操作するライブラリです。主にWebアプリケーションのテストやWebスクレイピングに利用されます。
・BeautifulSoup ーー HTMLおよびXMLドキュメントを解析するためのPythonパッケージです。
・csv ーー CSVフォーマットで保存するために使用されます。
したがって、プログラミングを実戦する前に、以下の準備が必要となります。
・Python 2.xまたはPython 3.xの環境
・Selenium、BeautifulSoup、csvライブラリの導入
・Google Chrome ブラウザ
それでは、早速始めましょう!
二、ページ要素(HTMLドキュメント)の検証
Webサイトから、要素(HTMLドキュメント)を検証し、データがどのように構成されているかを分析する必要があります。HTML基礎知識はこちらのリンクで参照ください。今回はテーブルのデータを抽出するように試してみましょう。
Ctrl + Shift + I を押して、テーブルの要素を指定すると、HTMLのソースコードに表示されます。
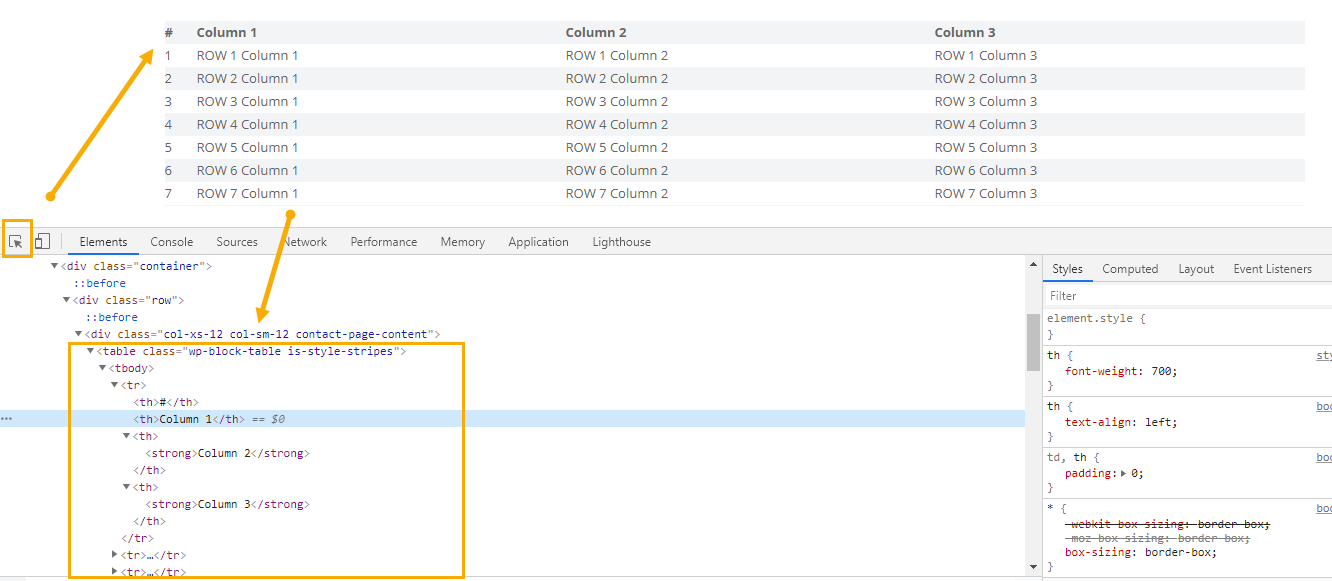
したがって、テーブルの要素名は「table」と分かっています。
なお、Webクローラーを構築するたびに、HTMLドキュメント内の要素を定位するため、xPathの知識が必要となります。xPathのチュートリアルはこちらのリンクからアクセスできます。
三、コードを書く
1.まず、必要なライブラリをすべてインポートしましょう。
web-scraping.py
import csv # csvモジュールをインポート
from selenium import webdriver # selenium webdriver をインポート
from bs4 import BeautifulSoup # BeautifulSoup をインポート
2.Webdriverを使用する前に、chromedriverへのパスを設定する必要があります。
※/path/to/chromedriverをWebdriverのパスに変更してください。
web-scraping.py
driver = webdriver.Chrome("/path/to/chromedriver")
3.以下のコードを参照してURLを開いてください。
web-scraping.py
driver.get("http://test-sites.octoparse.com/?page_id=192")
4.URLを開くためのコードが書けたところで、いよいよWebサイトからデータを抽出します。
先に述べたように、抽出したいデータは
要素に入っています。データを持つ要素を探し出し、データを抽出します。以下のコードを参照してください。
web-scraping.py
content = driver.page_source
BS = BeautifulSoup(content, "html.parser")
table = BS.findAll("table", {"class":"wp-block-table is-style-stripes"})[0] # テーブル"wp-block-table is-style-stripes"を指定
rows = table.findAll("tr") # テーブル中<tr>要素の内容を抽出
print(rows) # 抽出したHTMLドキュメントを検証
最後に、web-scraping.pyで保存します。
四、コードを実行してデータを抽出する
コードを実行して、必要なHTMLドキュメントを正しく抽出するかどうかを確認します。

五、データを必要なフォーマットで保存
データを抽出した後、抽出したデータをCSV(Comma Separated Value)形式で保存します。そのため、コードに以下の内容を追加します。
web-scraping.py
with open("web-scraping.csv", "w", encoding='utf-8', newline="") as file: # ファイル名は「web-scraping.csv」を指定する
writer = csv.writer(file)
for row in rows:
csvRow = []
for cell in row.findAll(['td', 'th']): # tdとth要素をループでファイルに書き込む
csvRow.append(cell.get_text())
writer.writerow(csvRow)
六、Pythonでスクレイピングしましょう
それは最終的なコードです。
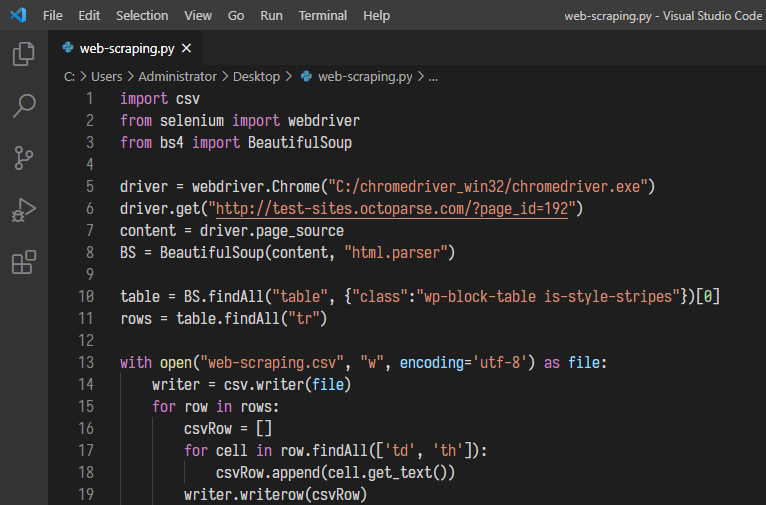
追加した後、もう一度コード全体を実行してみてください。
抽出結果は「web-scraping.csv」というファイル名が作成され、このファイルに抽出されたデータが格納されます。

七、Octoparseでスクレイピングする方法
プログラミングが苦手、或いは英語のコードばかりなので苦手意識を持っている方は、スクレイピングツールのOctoparseはおすすめします。
Octoparseは「自動識別」機能があるので、ページのURLを入力するだけで、Webページ上各項目のデータ(テキストとリンクを含む)、「次のページ」ボタン、「もっと見る」ボタン、およびページのスクロールダウンを自動的に検出し、タスク(Webクローラー)を自動的に生成することができます。
早速ですが、Octoparseで自動化の魅力を体験してみましょう。
1.Octoparseを起動して、スクレイピングしたいWebページのURLを入力します。
「抽出開始」 ボタンをクリックして進みます。

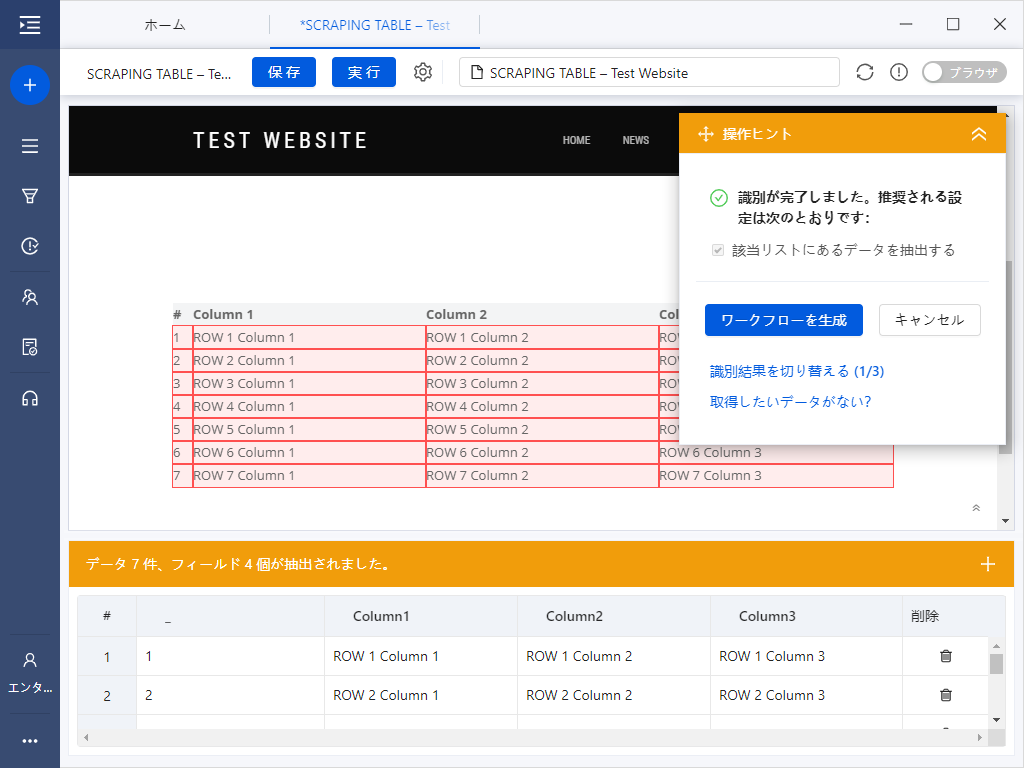
2.Octoparseでページが読み込みされたら、自動的にページ上の内容を識別します。
自動識別とは、自動的にページ上の必要なデータを検出して識別するという役立つ機能です。ポイント&クリックをする必要はなく、Octoparseは自動的に処理します。
14.Octoparse_自動識別.png
3.識別が完了すると、データプレビューで識別したデータを表示され、確認してから「ワークフローの生成」ボタンを押します。
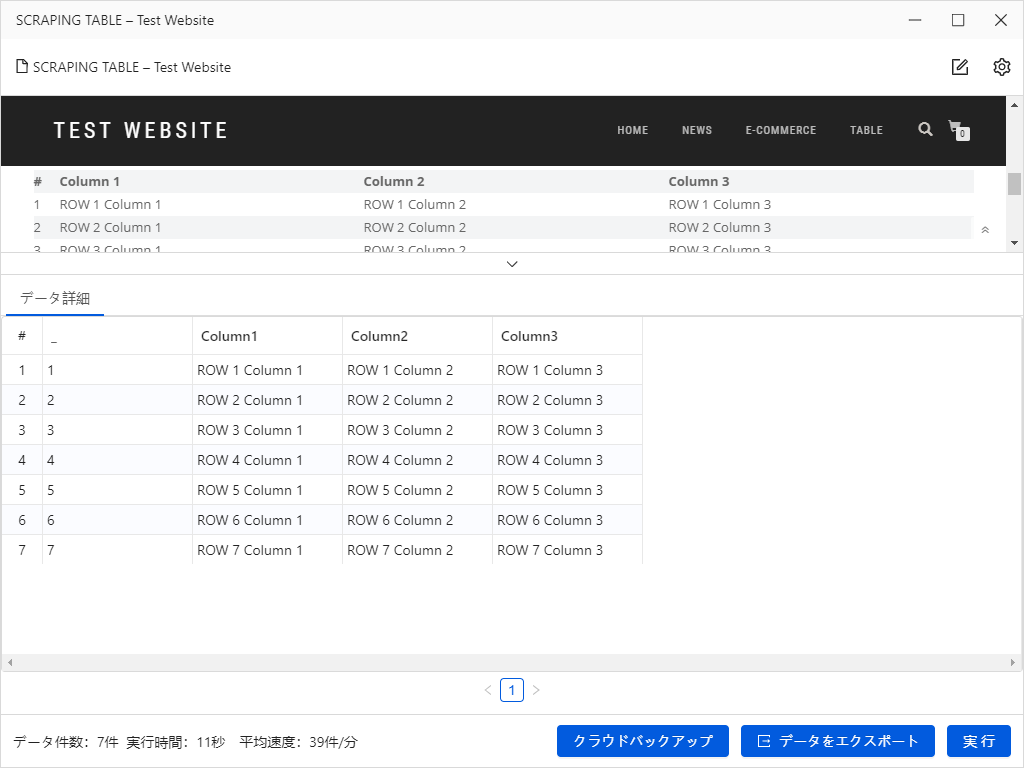
4.これで簡単にWebクローラーが作成しました!
上の「実行」ボタンをクリックして、すぐデータを抽出できます。簡単ではないでしょうか。
八、まとめ
Pythonでスクレイピングはそんなに簡単ではないので、学ぶ時間がなく、効率的にスクレイピングがしたい、プログラミングが苦手、或いは英語のコードばかりなので苦手意識を持っている方はスクレイピングツールはおすすめです。

関連記事
PHPで簡単なWebクローラーを作ってみた
PythonによるWebスクレイピングを解説
Python vs Octoparse!初心者向きのスクレイピング方法はどっち?
【初心者向け】ExcelとVBAでWebスクレイピング実戦!