前回の記事では、XPathの基本概念を簡単にご紹介しました。今回はXPathによるWebページ(HTML)からデータを指定・取得する方法、つまりXPathの書き方を解説します。
1.タグ(要素)で指定する
下記のHTMLサンプルで、文章が<html> </html>のように、<> </>といった記号で囲まれているのが分かります。このような<> </>といった記号を、タグと言います。
<タグ名>ここにコンテンツが入ります... </タグ名>
最初のタグを 「開始タグ」、最後のタグを 「終了タグ」 といいます。そしてこの開始タグから終了タグまでの全体を、「要素」 と呼びます。
以下のHTMLで、紫色で表示されている部分はタグです。(Firefoxで青色、Chromeでは紫色で表示されます。)
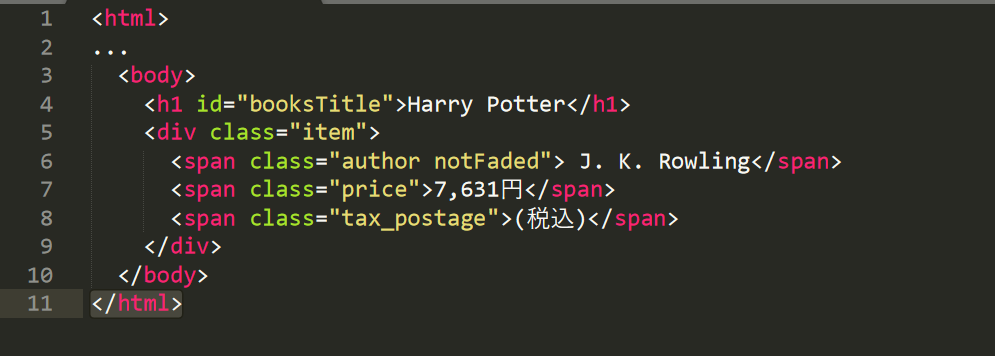
以下は、HTMLでよく使われるタグの一覧です。詳しくはHTML Living Standard 要素一覧も併せてご覧ください!
XPathの最も一般的な書き方は、スラッシュ"/"でタグを区切って記述します。
例えば、以下のHTMLから「Harry Potter」を取得したい場合は、ツリー構造の上から順に「htmlタグ→bodyタグ→h1タグ」と指定できます。
絶対XPathは次のように書きます。
/html/body/h1
また、短いXPathの場合、「//」を用いて、途中までのパスを省略することができます。
//h1
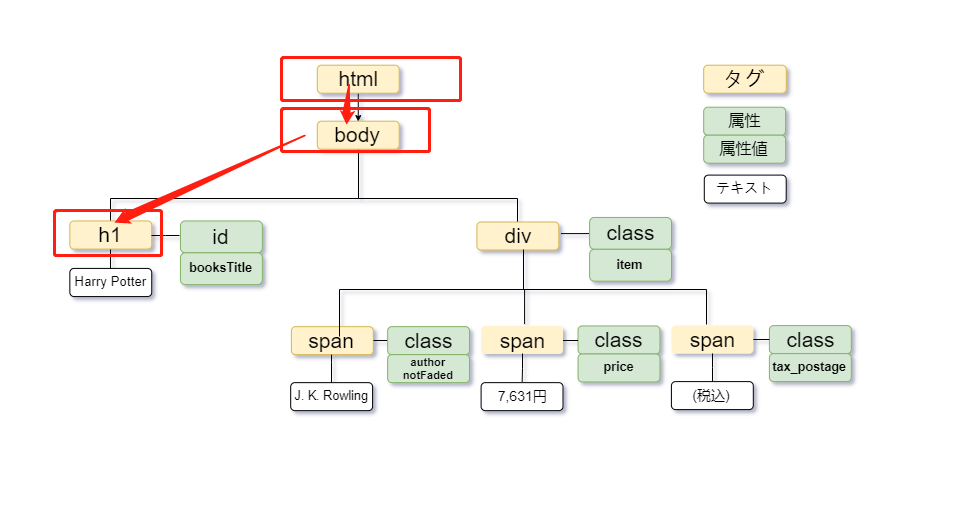
複数のタグが該当する場合は、N番目のタグを指定することが可能です。例えば、同じ図には「7,631円」を取得する場合、「div」内の2番目の「span」を指定する必要があるため、次のように記述します。
//div/span[2]
抽象的に表現すると、タグ(要素)を使ったXPathの構文はこのようになります。
//タグ名/タグ名
2.属性で指定する
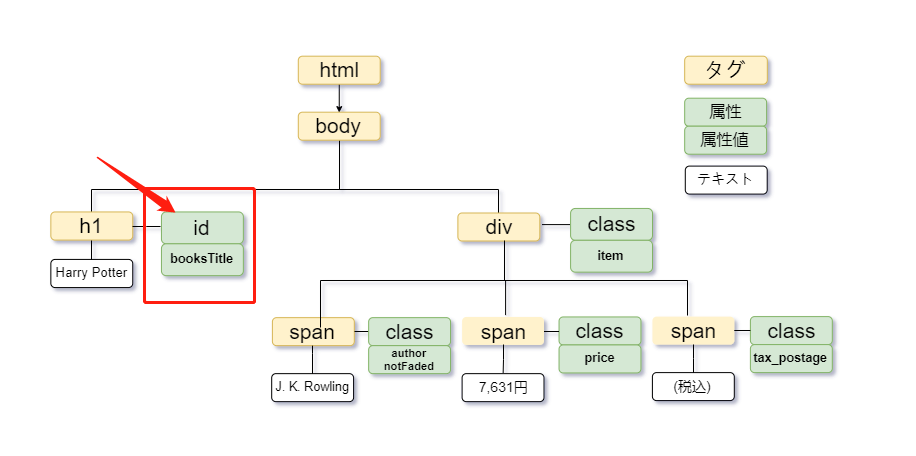
属性とは、タグの中に記載されている、タグの情報を詳細に表すものです。属性を付けることで、要素に特定の効果を指定したり、詳細な指示を加えることができます。通常、属性は 「id="booksTitle"」 のように表示されます。また、属性は複数指定することも可能です。
<タグ名 属性名="属性値">
最も一般的な属性には、href、title、style、src、id、class などがあります。詳しくはHTML Living Standard 要素一覧を合わせてご覧ください!
XPathでは属性を「@」の関数で表します。
@ は、XPathで特定の要素の属性を選択するために使用されます。例えば、「Harry Potter」を取得したい場合、XPathは次のように書きます。
//h1[@id="booksTitle"]
抽象的に表現すると、属性で書くXPath構文はこうなります。
//タグ名[@属性名="属性値"]
同じ属性を持つすべての要素を取得したい場合、次のように記述します。* は、XPathにおいて「任意の要素」を表すワイルドカードです。つまり、特定のタグ名に関係なく、すべての要素にマッチさせたい場合に使用されます。
//*[@属性名="属性値"]
3.テキストで指定する
下記のようにタグで囲まれているのはテキストです。
<タグ名>ここにテキストが入ります... </タグ名>
Webページからデータを取得するのは、通常ページ内のコンテンツまたはテキストを取得することです。ですから、取得したいテキストを直接指定することができます。
XPathではテキストを[text()]の関数で表します。
text() は、XPathで特定の精確なテキストを持つ要素を検索するために使用されます。例えば、「Harry Potter」を取得したい場合、テキストで指定すると、次のように書きます。
//h1[text()="Harry Potter"]

抽象的に表現すると、属性で書くXPath構文はこうなります。
//タグ名[text()="取得するテキスト"]
同じ属性を持つすべての要素を取得したい場合、次のように記述します。
//*[text()="取得するテキスト"]
4.タグ関係で指定する
HTMLのツリー構造において、すべての要素が親子/兄弟関係を持っています。
1つまたは複数の要素を含む要素は親要素と呼ばれ、含まれる要素は子要素といいます。
子要素は必ず1つの親要素に属し、その親の開始タグと終了タグの間に位置しています。
また、同じ親要素を持つ要素同士は兄弟要素と呼ばれます。
具体的な例も見てみましょう。
以下のサンプルでは、[body]要素を基点に、[body]要素が[h1]要素と[div]要素の親であり、[h1]要素と[div]要素はそれぞれ[body]要素の子要素です。この親子・兄弟関係にある要素を取得し、それぞれのスタイルを変更する例を示します。
[h1]要素と[div]要素は、同じ親である[body]要素を持つため、兄弟要素と呼ばれます。
さらに、[div]要素は2つの[span]要素の親であるため、これらの[span]要素は[body]要素の子孫要素となります。
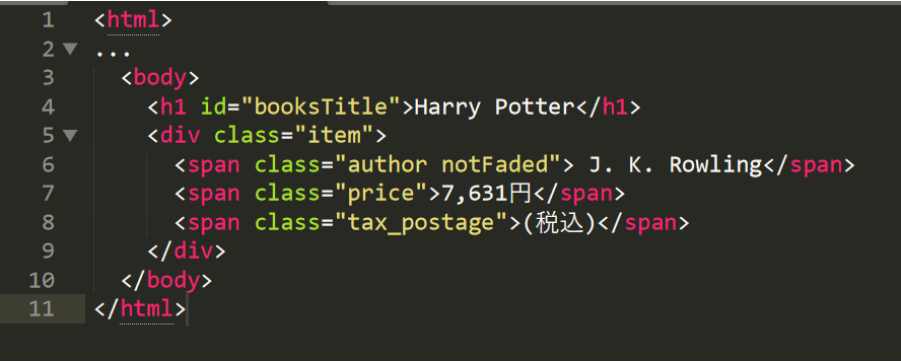
カレント要素を基点に、親子関係や兄弟関係にある要素を取得することができます。例えば、「7,631円」を取得したい場合、タグの関係を利用して次のように指定することができます。
[div]要素の子要素とする場合
//div/span[2]
[body]要素の子孫要素とする場合
//body//span[2]
[span class="author notFaded"]要素の兄弟要素とする場合
//span[@class="author notFaded"]/following-sibling::span[1]
[span class="tax_postage"]要素の兄弟要素とする場合
//span[@class="tax_postage"]/preceding-sibling::span[1]
兄弟関係のあるタグを指定するには『following-sibling::』と『preceding-sibling::』という2つの関数をよく使います。
- 『following-sibling::』は、指定された要素より後の兄弟要素を指定する
- 『preceding-sibling::』は、指定された要素より前の兄弟要素を指定する
『following-sibling::』は、テーブル要素を指定する時に大活躍します。例えば、下記のHTMLサンプルがあります。

このHTMLはページに変更すると、以下のようなテーブルの形になります。

この例では、店名の『12345』取得します。ただし、[td]要素が複数あり、//td[1] で対応できなくなります。また、もし複数のページから、同じ構造のテーブルを一括取得する場合、固定的な値「店名」を基点として、『following-sibling::』を使うほうが薦めです。次のように書きます。
//th[text()="店名"]/following-sibling::td[1]

抽象化にすると、タグ関係で書くXPath構文はこうなります。

もし上記の構文で複数に合致する場合に、[N] を付けてN番目のタグを指定することができます。
いかがでしょうか?以上は最も使われるXPath書き方です。さっそくお試してみてください。次回はXPathによく使われる関数を紹介します。お楽しみに!