はじめに
・機械学習について勉強を開始して約1年でチーム参加ながらKaggle M5 Forecasting Accuracyで27th (of 5558)相当のスコアを獲得できたので取り組んだ内容と感想をまとめました。
・**「27th of 5558相当のスコアを獲得できた」**と表現している理由について最後まで読んでいただければわかります。。
M5 Forecasting Accuracyについて
・ウォールマートの売り上げ予測を行うコンペです。
・予測を行う範囲はカリフォルニア、テキサス、ウィスコンシンにある合計10店舗で28日後までの売り上げ予測を行います。
・評価指標はWRMSSEというものでした。
取り組んだ内容
取り組んだ内容について時系列順に書きます。
EDA(3月〜4月)
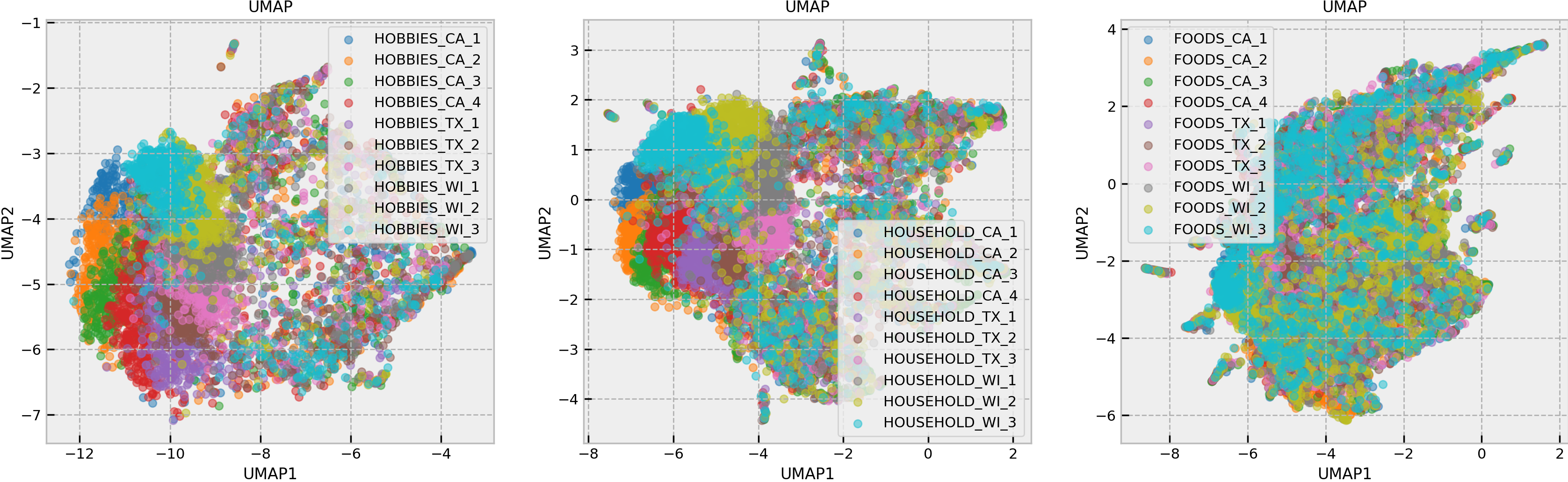
・チームメイトが売り上げデータをUMAPによる次元圧縮を用いて解析すると、ストアごとにクラスタリングされる特徴を発見し、ストアごとにモデルを作成することとしました。
ベースモデルの作成(4月〜5月)
与えられたデータの情報量が少ないことから特徴量エンジニアリングで差のつくコンペというよりかはモデルで差のつくコンペと判断し慎重にモデル選択を行いました。
・LightGBMを採用しました、他にもSARIMAXモデルやLSTMを用いた予測も行いましたが、LightGBMが強かったです。
・kaggleのDiscussionを参考に日毎に予測するモデルか再帰的に予測を行うモデルを検討しました。日毎モデルの弱点は日毎に予測モデルを作成するため学習コストが高い点と、28日目といった後半の日付の予測には直近の売り上げデータがない状態で予測を行うため精度が下がる確率が高い点です。再帰的に予測を行うモデルの弱点は特徴量に自分の売り上げ予測を用いることで、28日目でも直近の売り上げデータがある状態で予測が行える反面、予測データの精度が低い場合には再帰的に予測に誤差が乗ってしまう点です。M5コンペでは28日後までの予測とそこまで未来の予測ではないことと(日毎でもそこまで精度が落ちないと予想)、予測が難しく誤差が乗りやすいことから、日毎モデルを採用しました。
・CVは予測から直近の3ヶ月のデータを用いました。ちょうど1年前を採用する案(同月なのでデータが似ている)もありましたが、直近一年でウォールマートの売り上げが大きく伸びており、確率分布が近いのは直近のデータと判断し採用しませんでした。
この時点で**28日×10ストア** = **280モデル**と学習コストが重くなってしまい、submitから遠ざかります。。。
特徴量作成(5月〜6月前半)
移動平均などの基本的な特徴量(思考停止な特徴量)を作成した後に、追加で効果がありそうな特徴量作成を行いました。ここでは過学習をさせないため無作為に特徴量を作ったりせず**購買意欲を表現できそうな特徴量、統計学的に意味のありそうな特徴量の作成**を意識しました。作成した中でも効果の高かった特徴量を紹介します。
・商品の値段が上昇、減少をしてからの経過日数
売り上げと商品の値上げ、値下げは関係があると考え作成しました。
・特定の期間での売り上げの最大値と、最小値を記録してからの経過日数
予測日から特定の期間での最大値、最小値でCVの改善したので作成しました。
・売り上げが0から10のそれぞれの値になる確率
売り上げの確率分布がtwwedie分布に近い分布になっていて、その確率分布を表現するために作成しました。
・売り上げを初めて記録した日
売り上げを初めて記録した日をその商品の発売日と解釈ました。新商品は売り上げが多い、といった情報を表現できると思い作成しました。
・商品ごと,商品と価格組み合わせでのOrdered TS
Ordered TSは時系列データでリークしないTarget encodingのようなものです、弱点としては時系列ごとに特徴量を作成していくため時系列初期のデータの精度が低い点だと思います、今回のコンペでは十分にデータが与えられておりそこまでは問題にならなかったです。商品と価格の組み合わせにした理由は商品ごとの価格のユニークな数が少ないものが多かったためです。
他にもwavelet変換を用いたdenoise特徴量,UMAPによる次元圧縮を行った特徴量などを作成したのですがCVの改善がなかったため採用しませんでした。
作成した特徴量についてgitに掲載してあるので、興味のある方は見てください。
モデル学習と予測(6月後半)
・ハイパラチューニングは行いませんでしたが,n_estimator(lgbモデルの木の数)だけはWRMSSEの評価指標で過学習を起こさないように決定しました。
・CVに使用したデータも用いて予測用モデルを作成しました。木の数はCVでWRMSSEが最も下がった数よりも2割ほど少ない数を採用しました、これは今回の予測対象が難しい内容であり表現力を少し落としたモデルの方が適していると判断したためです。
・学習環境はgoogle colabを使用しました。280モデル作成するということでチームメイト二人でcolabのnotebookを合わせて10立ち上げ,並列で学習と予測を行いました。
これでもモデル作成から予測には1.5日ほど要しました。。
結果発表
・ドキドキしながら順位を確認すると、、、、

提出ファイルに不備があり(1ストア分の予測結果を足し忘れていました。。)最下位になっていました。
激しい動悸の中、提出ファイルを再作成し提出すると、、、
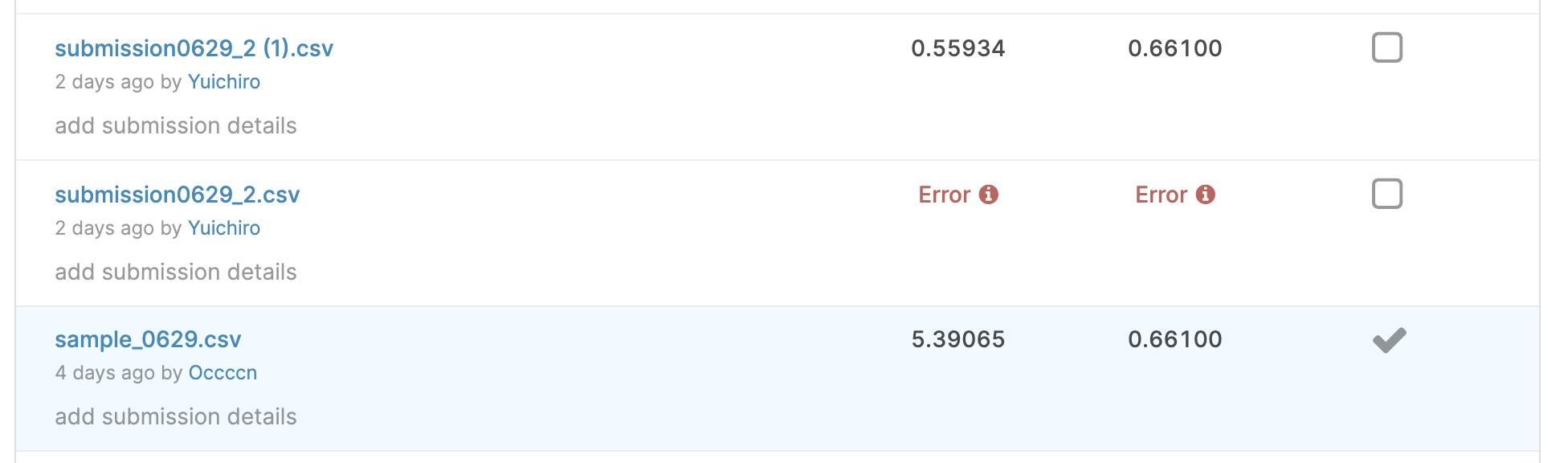
そこに表示されたのは27位相当のスコアでした。。。ベースライン作成を行ってから一度も提出しなかったことが仇となりました。
感想
・チーム全員がkaggle初心者で参加したDSB2019コンペでは公開notebookを基にしたモデル作成を行い、大きくshake downをしてしまいました。今回はその反省を活かしてベースモデルの作成から自分たちで行いメダル相当のスコアを獲得できたことは嬉しいです。
・複雑で予測が難しいデータに対して、過学習しすぎないモデル作成と特徴量作成を心がけたところが良かったと考えています。
・提出ファイルの不備も含めて実力です。次回のコンペでは、必ずメダルを獲得したいです。
・運の要素で高い順位のスコアのモデルが作れていた部分がかなりあると思うので、もっと実力をつけたいです。
運の要素もありますが、せっかくいいスコアを取れたのにメダルが取れなかった思いをぶつけたくて、投稿した記事でした。