まえがき
日々、大量の情報に埋もれている無料で使用できるツールの情報...
これらの優秀なツールを1つでも知らないというのは、エンジニアとして選択肢を狭めていると思います。
そこで本記事では、そのような情報を収集するプログラムを作成し、整理をして見やすくするところまでを行います。
集めた情報をどう使うかは本記事では紹介しません。あなた次第です。
手段
筆者の感覚では無料ツールに関する情報は、はてなブックマークで知ることが多い気がします。
そこで、はてなブックマーク検索APIで「無料 ツール」を検索した結果を収集し、集計・ソートなどで見やすい形にするというところまでを行います。
使用言語がバラバラかつプログラムがスマートでないのは、筆者の怠慢です。
道筋
- はてなブックマーク検索APIを用いて、情報を集める (Ruby)
- 見やすい形にする (Python)
情報を集める (Ruby)
ここではRubyを用いて、はてなブックマーク検索APIからの結果をCSVファイルに保存するという処理を行います。
貪欲に集められる限りの情報が欲しいので、はてなブックマークで集められる2009年から2019年まで各日に関してそれぞれAPIを投げます。
今回はカテゴリーが「テクノロジー」もののみ収集します。
require "rss"
require "uri"
require "nokogiri"
keyword = "無料 ツール" # 検索ワード
years = 2009..2019
for year in years
dt = DateTime.new(year, 1, 1)
days = dt.leap? ? 366 : 365 # 閏年のときは366日
days.times do |day|
sleep(1) # 負担をかけないよう1秒間隔を空ける
date_begin = (dt + day).strftime("%Y-%m-%d")
url = "https://b.hatena.ne.jp/search/title?q={#{keyword}}&sort=popular&mode=rss&date_begin=#{date_begin}&date_end=#{date_begin}"
begin
# URLに日本語が混じるのでパーセントエンコーディングを行う
url = URI.encode(url)
rss = RSS::Parser.parse(url)
aritcle_info = rss.items
aritcle_info.each do |x|
if x.dc_subject == "テクノロジー"
sleep(1)
# ブックマーク数を問い合わせる
bookmarkcount_link = "http://api.b.st-hatena.com/entry.count?url=#{x.link}"
doc_b = Nokogiri::HTML(open(bookmarkcount_link, :read_timeout => 10))
bookmarkcount = doc_b.xpath('/html/body/p')[0].children.text.to_i
# CSVのフォーマットに即した出力を行う
title = x.title.gsub!(",", " ") # タイトルからコンマを除去
if title == nil # タイトルにコンマがない場合、元のタイトルを保存
print x.title
else
print title
end
print ","
print x.link
print ","
print bookmarkcount
print ","
puts date_begin
end
end
rescue => e
next
end
end
end
上記の処理の結果をCSVファイルに保存します。
ruby hoge.rb > hoge.csv
これでhoge.csvに無料ツールに関する情報が収集できました。
収集した情報を見やすくする (Python)
上記で作成したCSVファイルをpandasを用いて、見やすい形に変えます。
はてなブックマークの仕様上、同じ記事が別日で保存されている場合があるので、タイトルが同じものは除去します。
import pandas as pd
df = pd.read_csv('./hoge.csv', header=None)
df = df.rename(columns={0: 'title', 1: 'link', 2: 'bookmark', 3: 'date'}) # カラム名を指定
df = df.drop_duplicates(subset='title') # タイトルが同じものを除去
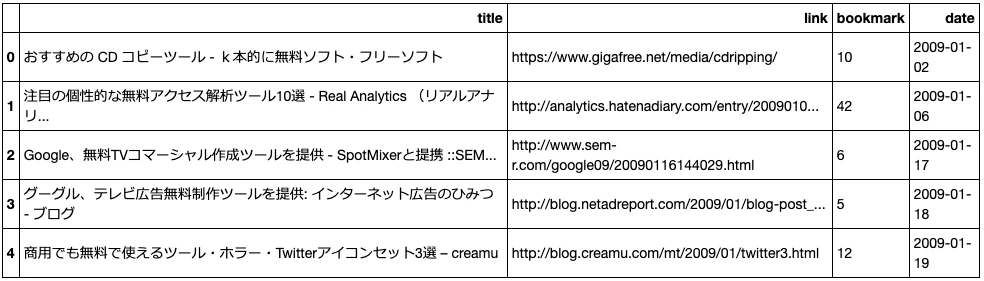
df.head()
以上の最低限の前処理を行うと下のような結果が得られたと思います。
今回は千件以上の情報があるうえに、人によってはいらない情報もあるかもしれません。
そこで、情報を見やすくしましょう。
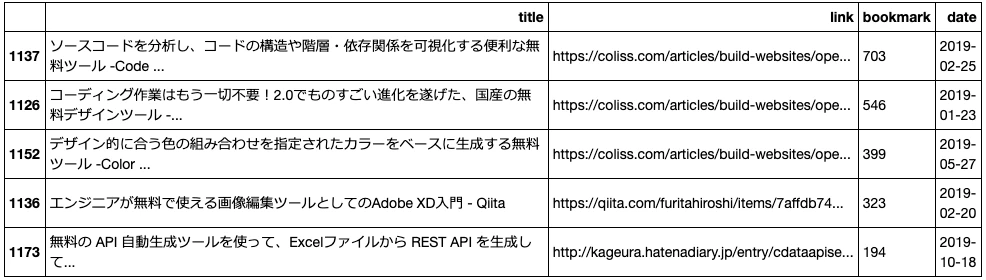
例えば、年別でブックマーク数でソートしてみます。
df_markdown_sorted = df.sort_values("bookmark", ascending=False)
df_markdown_sorted.query('date.str.startswith("2019")', engine='python').head()
pandasの条件抽出を簡単にするために下記の記事を参考にしています。
pandas.DataFrameの行を条件で抽出するquery
上記の処理で下のような結果が得られたと思います。
あとがき・今後の展望
本記事では「無料 ツール」の情報を収集するため、はてなブックマーク検索APIを用いた情報検索と情報整理を行いました。
欲しい情報は得られたでしょうか?
今後の展望としては
- 収集した記事をクラスタリングし、興味のある分野のクラスタを抽出する。
- 記事についているタグの情報も収集する
などあるかと思います。