概要
Selenideとは、Junitベースのテストの中で
ブラウザを操作し想定の画面遷移やデータが表示されるかの確認を行えるもの
初期設定
環境
言語:JDK 1.8
Mavenの記載
pom.xmlに以下の記載を追加
<dependencies>
<!-- 中略 -->
<dependency>
<groupId>com.codeborne</groupId>
<artifactId>selenide</artifactId>
<version>4.9</version>
<scope>test</scope>
</dependency>
</dependencies>
4.9:2018/3/12時点でのSelenideの最新バージョン
SpringBootの場合
SpringBootを導入している場合、Selenideが参照しているライブラリ(Selenium)のバージョンが古いため
selenideを動作させるためには以下の設定が追加で必要となる
追加設定内容
<dependencies>
<!-- 中略 -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-api</artifactId>
<version>3.8.1</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-chrome-driver</artifactId>
<version>3.8.1</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-firefox-driver</artifactId>
<version>3.8.1</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-remote-driver</artifactId>
<version>3.8.1</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-support</artifactId>
<version>3.8.1</version>
</dependency>
</dependencies>
FireFox及びChromeで動作させる前提であれば上記設定のみで動作しました
その他NoClassDefFoundやNoSuchMethodの類のエラーが出た際には
selenium-apiの依存関係を確認し、ローカルで有効になっているバージョンと比較を行うこと
Driverの準備
ChromeDriverの準備
起動させるブラウザが、FireFox以外の場合にはDriverファイル(Selenideで記載している内容を受け、ブラウザの操作/情報取得を行ってくれる実行ファイル)が必要となります
ダウンロードサイトから環境にあったファイルを取得し、Junitで指定できる場所に配置してください
独り言1
selenide4.8以降は不要という記事を読んだのですが、私が実行したときはダウンロードが実施されなかったので ドライバを準備しておきました。独り言2
ドライバをローカルに配置した場合は、対象のファイルに対して実行権限があるか確認が必要 ない場合は、別途実行権限を設定する必要がある Docker等Windows以外の環境で実施する場合は注意が必要ドライバ起動~終了まで
Driverの初期設定
以下の手順でDriverの設定を行う
@Beforeメソッドの中で設定を行う
Chromeの場合
@Before
public void before() {
Configuration.browser = WebDriverRunner.CHROME;
//Chromeドライバのパスを設定(ここでは設定ファイルから取得)
System.setProperty("webdriver.chrome.driver", getClass().getResource(properties.getChromeDriver()).getPath());
ChromeOptions chromeOptions = new ChromeOptions();
//HeadLessモード指定
if (properties.isHeadless()) {
chromeOptions.addArguments("--headless");
}
Map<String, Object> chromePrefs = new HashMap<>();
//PopUp表示を抑制
chromePrefs.put("profile.default_content_settings.popups", 0);
//ダウンロードフォルダ指定(テストメソッドごとに格納パスを切り替える等任意で設定)
chromePrefs.put("download.default_directory", "/User/Temp/result/DownloadFile");
//ダウンロード先指定ダイアログ表示抑制
chromePrefs.put("download.prompt_for_download", false);
chromeOptions.setExperimentalOption("prefs", chromePrefs);
driver = new ChromeDriver(chromeOptions);
//WebDriverRunnerにDriverを指定
WebDriverRunner.setWebDriver(driver);
Configuration.fastSetValue = true;
//スクリーンショットの設定ディレクトリ設定
Configuration.reportsFolder = "/User/Temp/result/ScreenShot";
}
以下で各指定内容について記載します
ヘッドレスモードの指定
以下の指定を行うと、HeadlessModeでChromeを起動し、ブラウザでの確認を行えます。
この指定を行うことによりUI無しの環境でも自動検証を行うことが出来ます
chromeOptions.addArguments("--headless");
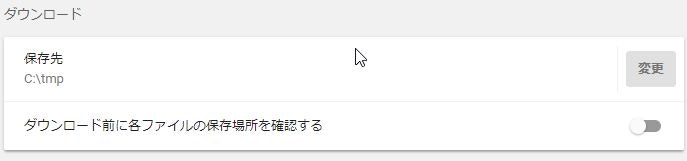
ファイルダウンロードパスの指定
以下2行でファイルダウンロード時のディレクトリ指定と
ダウンロード時にダイアログが表示されるのを抑制します。
//ダウンロードフォルダ指定(テストメソッドごとに格納パスを切り替える等任意で設定)
chromePrefs.put("download.default_directory", "/User/Temp/result/DownloadFile");
//ダウンロード先指定ダイアログ表示抑制
chromePrefs.put("download.prompt_for_download", false);
Chrome設定画面の以下の箇所に反映されます
スクリーンショット保存先
以下でスクリーンショットの保存先指定を行います
(スクリーンショットについては後述)
//スクリーンショットの設定ディレクトリ設定
Configuration.reportsFolder = "/User/Temp/result/ScreenShot";
文字入力指定
以下指定を行うことにより、inputタグに文字を入力する際に、
指定した文字を一括で指定します
(以下の指定を行わない場合、1文字づつ画面に入力されます)
Configuration.fastSetValue = true;
Driver終了
@Afterメソッドの中で実施します。
以下メソッドで、Driverを終了します
@After
public void after() {
driver.close();
}
テスト
@Testのメソッド内で実施(普通のJunitと同様)
まずざっくりの流れとしては、
-
Selenide#open(String,Class)で指定のURLを起動 - 起動したページ要素を取得し、想定の要素が表示されているか確認
- ボタン等をクリックして想定通りの遷移になるか、想定通りの動きをするの確認
"2-3"の繰り返しで複数画面の確認も可能
URLを指定して画面起動
以下のように指定ページを開く
ItemsPageObject itemsPage = Selenide.open("http://localhost:8080/items", ItemsPageObject.class);
PageObjectについて
第二引数及び返却値となるクラス(Object)はPageObjectと呼び
このPageObject内でSelenideの要素の取得や操作を行い
テストメソッド内では取得結果の判定やPageObject経由での画面操作を行うことが推奨されている
@Test
public void testItemList() throws Exception {
ItemspageObject itemsPage = Selenide.open("/items", ItemspageObject.class);
List<String> ret = itemsPage.getItemNames();
assertEquals("ItemCount", 2, ret.size());
}
上記の例だとItemspageObject#getItemNames()内でHTMLの要素を取得し
取得した内容の確認はTestメソッド内で実施している
要素の取得
Pageオブジェクト(クラス)に取得メソッドを記載することにより要素を取得する
基本的な要素取得方法
Selenide#$(String)を使用することにより対象の要素を取得することが出来る
以降こんな簡単なページを例に記載していく
<table>
<tr>
<th>Header1</th>
</tr>
<tr>
<td>Data1</td>
</tr>
<tr>
<td>Data1</td>
</tr>
</table>
以下のように取得すると<table>タグ全体を取得することが出来る
public SelenideElement getTable(){
return Selenide.$("table");
}
さらに子要素を取得したい場合は以下のように取得できる
public ElementsCollection getTableRows(){
//Tableの要素を取得
SelenideElement table = Selenide.$("table");
//子要素の一覧を取得
return table.$$("tr");
}
SelenideElement Selenide#$(String)で指定した文字列で要素を検索し、最初に取得できた要素を取得でき
ElementsCollection Selenide#$$(String)で指定した文字列で要素を検索し、最初に取得できた要素一覧で取得できる
ElementsCollectionは、AbstarctList<SelenideElement>の継承クラスなので、取得した要素数の確認や、Listの中身の検査も実施可能(詳細略)
要素取得方法(PageObjectのフィールドに設定)
PageObjectのフィールドを以下のよう@FindByに取得方法を記載することにより要素をInjectionすることが出来ます
public class ItemspageObject extends SelenideBasePageObject {
@FindBy(how = How.TAG_NAME, using = "table")
private SelenideElement table;
@FindBy(how = How.TAG_NAME, using = "tr")
private ElementsCollection rows;
上記の場合ItemspageObjectのインスタンス生成時にtag名称="table"で起動ページから要素を取得し値を設定します
上記tableの子要素を取得したい場合等、SelenideElementではなく独自クラスを指定することが出来ます
public class ItemspageObject extends SelenideBasePageObject {
@FindBy(how = How.TAG_NAME, using = "table")
private OriginalTable table;
OriginalTableは以下のようにElementsContainerを継承して作成
public class OriginalTable extends ElementsContainer {
@FindBy(how = How.TAG_NAME,using = "tr")
private List<TableRow> tableRows;
複数の要素をインジェクションしたい場合で独自クラスを指定したい場合はList<T>のように宣言しておく
TはElementsContainerを継承したクラスであること
public class TableRow extends ElementsContainer {
/**
* TableHeader
*/
@FindBy(how = How.TAG_NAME, using = "th")
private ElementsCollection headers;
要素の操作
取得した要素に対して操作について説明します
値の取得
指定要素のタグで囲まれた値を取得するためには
String SelenideElement#getText()を使用します
<th>Header1</th>
上記の"th"タグに相応するElemetに対して実行した場合は"Header1"という文字列が取得できます
属性値の取得
指定要素の属性値を取得する場合には、String SelenideElement#getAttribute(String)を使用します。
<a href="/users">Data2</a>
上記の"href"属性を取得したい場合は以下のように取得します。
SelenideElement aTag;
//中略
String hrefStr = aTag.getAttribute("href");
注意点
href属性の場合、取得してくる値は以下のようになります
http://loalhost:8080/users(相対パスではなく解釈された絶対パスが返却される)
要素に値を設定
文字列設定
以下のような文字列入力項目に対して文字列を指定する
<a>Input:<input type="text" name="NAME"></a>
SelenideElemnt#setValue(String)を使用して実施
//InputTagに文字列を設定
inputTag.setValue("aaaaa");
//設定した文字列は"SelenideElemnt#getValue()"で取得できる
assertEquals("InputTagValue", "aaaaa", inputTag.getValue());
ファイル指定
以下のようなファイル選択項目に対してファイルパスを指定する
<a>FileUp:<input type="file" name="FILE"></a>
//InputTagにファイルパスを設定
fileUpTag.uploadFile(new File("/User/Text.txt"));
上記処理を実施した際に実際にファイルがアップロードされるわけでなく、項目にファイルパスを設定するのみ
(サブミット処理を行って初めてアップロードがなされる)
hidden項目に対して値設定
type='hidden'と指定されている項目に対して値を設定したい場合は、SelenideElemnt#setValue(String)を使用するとエラーが出ます。
そのため、JavaScript経由で値の設定を行います。
<input type='hidden' name='hiddenItem' value='HiddenValue' />
上記例の'hiddenItem'の項目に値を設定するためには以下のように記載すれば値を設定できます。
String value = "設定値"
((JavascriptExecutor) webDriver).executeScript("document.getElementsByName('hiddenItem').item(0).value = '" + value + "';");
IE/FireFox/Chrome用のWebDriverはともにRemoteWebDriverを継承しており、
RemoteWebDriverがJavascriptExecutorを実装しているので、一般的なブラウザでなら対応できます。
ファイルダウンロード
Selenideで用意されているダウンロード処理
File SelenideElemnt#download()を使用するとhref属性の参照先のファイルを取得する。
JavaScriptでの動作等々、途中の処理が含まれるような処理には対応できない
必要と思われるダウンロード処理
ボタンやリンク等をクリックした後に、ダウンロードフォルダ(リンク先での設定で指定)を確認して新規に作成されたファイルをダウンロードファイルとして取得する。
以下注意点
- クリック前に指定フォルダのファイル数を保持しておく(リンク先参照)
- ダウンロード処理実施時には以下の順番でフォルダの中身が変わるので最終的にファイルダウンロード完了を検知してファイルの精査を行う必要がある
- ファイル増加なし(ダウンロード開始されていない)
- 作成されたファイルの拡張子が
.tmp(Chromeによるダウンロード中状態-1) - 作成されたファイルの拡張子が
.crdownload(Chromeによるダウンロード中状態-2) - 作成されたファイル名称が正規の名称になる(ダウンロード完了)
以下のソースで上記1-4の判定実施して取得ができます
/**
* 最新のダウンロードファイルを取得します
*
* @return 最新のダウンロードファイル
*/
public File getLatestDownloadFile() {
final File downloadDir = new File(getFileDownloadPath());
//ダウンロード完了まで10秒待機
WebDriverWait waitForUpload = new WebDriverWait(driver, 10);
waitForUpload.until(new ExpectedCondition<Boolean>() {
//ここの判定処理は、デフォルトで500ミリ秒ごとに実施
public Boolean apply(WebDriver _driver) {
//ファイル名からダウンロード中か否かを判定
return isDownloadFinish(getLatestFile(downloadDir));
}
});
//最新ファイルを取得
File retFile = getLatestFile(downloadDir);
//最新ファイルが取得できたら対象のファイルを返却
if (isDownloadFinish(retFile)) {
return retFile;
}
//出来なかったらNull返却
return null;
}
/**
* ダウンロード中か否かを判定します
*
* @param target 対象ファイル
* @return ダウンロード完了か否か
*/
private static boolean isDownloadFinish(File target) {
return target != null && !target.getName().endsWith(".crdownload") && !target.getName().endsWith(".tmp");
}
/**
* 最新ファイルを取得します
*
* @param targetDir ダウンロードディレクトリ
* @return 最新ダウンロードファイル
*/
private File getLatestFile(File targetDir) {
File[] downLoaededFiles = targetDir.listFiles();
//クリック前に保持したファイル数と変わっていなかったらNullを返却
if (downLoaededFiles == null || downLoaededFiles.length == resultFileCount) {
return null;
}
//ファイルの更新時間で比較し、最新のファイルを返却
Arrays.sort(downLoaededFiles, new Comparator<File>() {
@Override
public int compare(File file1, File file2) {
return file1.lastModified() <= file2.lastModified() ? 1 : -1;
}
});
return downLoaededFiles[0];
}
リスナーの設定
以下のように、WebDriverRunnerに対してリスナー(WebDriverEventListenerの実装クラス)を指定することでクリック前等のタイミングで処理を実行することが出来る
WebDriverRunner.addListener(new WebDriverListenerImpl());
WebDriverEventListenerの実装クラスはこんな感じで実装(クリック前に指定フォルダのファイル数を保持しておく)
/**
* WebDriverEventListenerの実装クラス
*/
public class WebDriverListenerImpl implements WebDriverEventListener {
//その他のメソッド群は省略
@Override
public void beforeClickOn(WebElement webElement, WebDriver webDriver) {
//クリック前に実績フォルダ配下のファイル数を取得する
baseClass.setResultFileCount(new File(" "/User/Temp/result/DownloadFile"").listFiles().length);
}
}