はじめに
構造化データの前処理は、基本pandasを使っているんですけど、
SQLだと簡単に書けるのに、pandasではどう書くんだっけと、時々忘れてしまうことが多々あり、、、
そんな悩みを解決してくれたライブラリがSQLっぽく直感的にテーブル操作できるdfply
使用データ概要
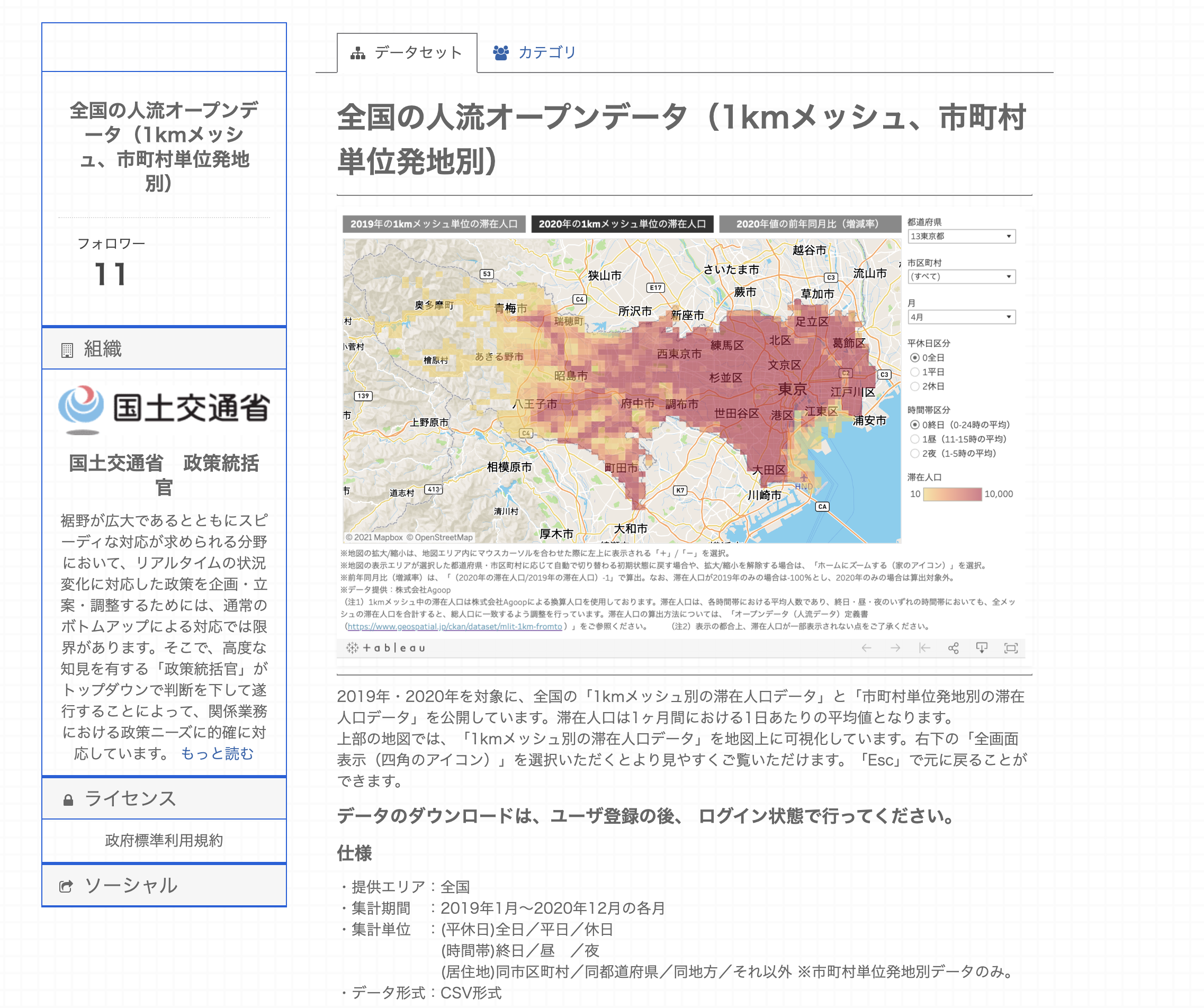
本記事で使用するデータは、人流オープンデータ(国土交通省)よりダウンロードしました。(東京都と神奈川県のみ)
・monthly_mdp_mesh1km_{pref_code}:1kmメッシュ別の滞在人口
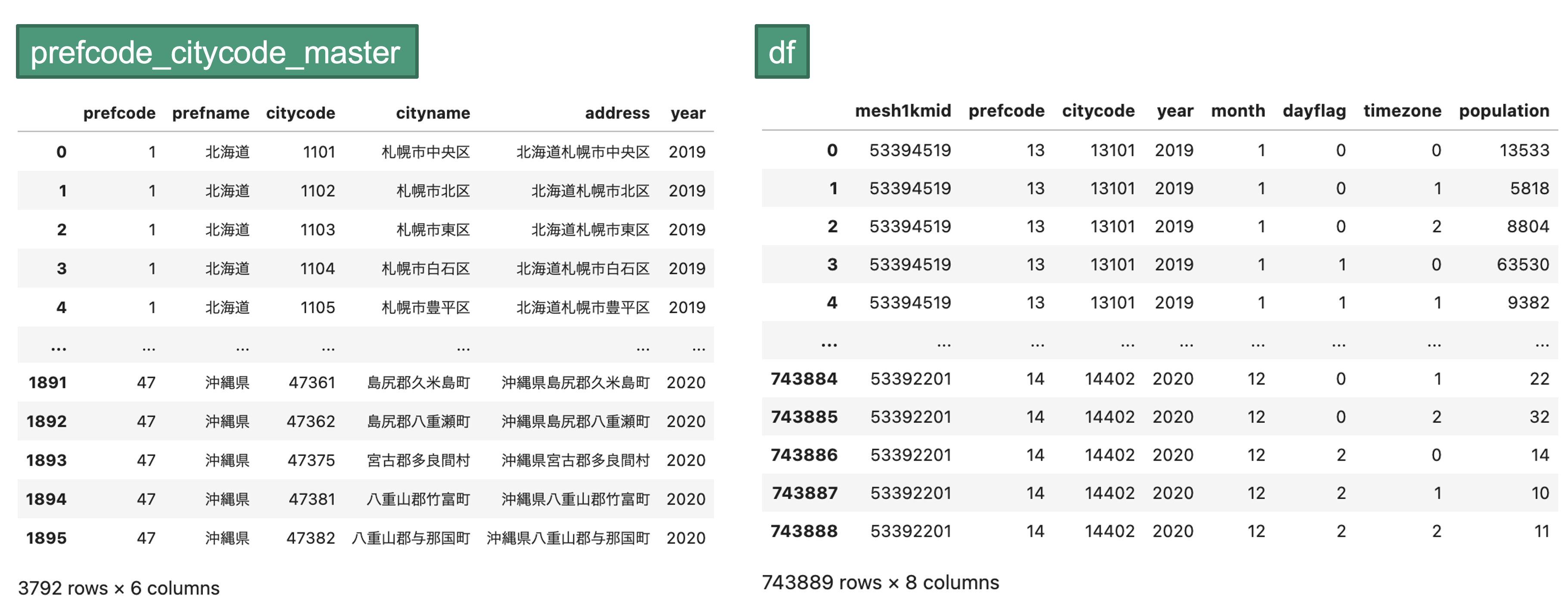
・prefcode_citycode_master:都道府県コード、市区町村コードのマスタデータ
データ前処理
'''
Agoop/
└── data
│ └── {pref_code}_mesh1km
│ │ └── 2019/{mm}/monthly_mdp_mesh1km.csv.zip:2019年{mm}月の1kmメッシュ滞在人口
│ │ └── 2020/{mm}/monthly_mdp_mesh1km.csv.zip:2020年{mm}月の1kmメッシュ滞在人口
│ └── prefcode_citycode_master
│ └── prefcode_citycode_master_utf8_2019.csv.zip:都道府県・市区町村マスタ-_2019年ver
│ └── prefcode_citycode_master_utf8_2020.csv.zip:都道府県・市区町村マスタ-_2020年ver
└── src
└── sample.py
'''
import pandas as pd
from dfply import *
prefcode_citycode_master = pd.DataFrame()
for year in [2019, 2020]:
tmp_df = pd.read_csv(f'../data/prefcode_citycode_master/prefcode_citycode_master_utf8_{year}.csv.zip')
tmp_df['year'] = year
prefcode_citycode_master = pd.concat([prefcode_citycode_master, tmp_df])
dfs = []
for pref_code in [13, 14]: # 東京都(pref_code=13), 神奈川県(pref_code=14)
for mm in range(12):
mm = str(mm+1).zfill(2)
dfs.append(pd.read_csv(f'../data/{pref_code}_mesh1km/2019/{mm}/monthly_mdp_mesh1km.csv.zip'))
dfs.append(pd.read_csv(f'../data/{pref_code}_mesh1km/2020/{mm}/monthly_mdp_mesh1km.csv.zip'))
df = pd.concat(dfs).reset_index(drop=True)
dfply vs pandas
基本的な使い方はデータに対する操作を>>演算子で連鎖させていく感じです。
SQLに慣れてる人なら、dfplyの方が使いやすいかも
①特定の列のみを参照したい
参照したい列名をselect
# dfply
df >> select(X.mesh1kmid, X.year, X.month, X.dayflag, X.timezone, X.population)
# pandas
df[['mesh1kmid', 'year', 'month', 'dayflag', 'timezone', 'population']]
②特定の列のみ削除したい
削除したい列に~をつける
# dfply
df >> select(~X.prefcode, ~X.citycode)
# pandas
df.drop(['prefcode', 'citycode'], axis=1)
③特定の列で並び替えしたい
arrangeを使う
# dfply
df >> select(X.mesh1kmid, X.year, X.month, X.dayflag, X.timezone, X.population) >> arrange(X.year, X.population)
# pandas
df[['mesh1kmid', 'year', 'month', 'dayflag', 'timezone', 'population']].sort_values(by=['year', 'population'])
④列名を変更したい
dfply:rename(新しい名前=X.古い名前)と、代入する感覚
pandas:rename(columns={'古い名前':'新しい名前'}) or rename(columns={'新しい名前':'古い名前'})のどっちだっけってなる
# dfply
df >> select(X.mesh1kmid, X.year, X.month, X.dayflag, X.timezone, X.population) >> rename(地域1kmメッシュコード=X.mesh1kmid, 年度=X.year, 月=X.month, 平日休日=X.dayflag, 時間帯=X.timezone, 滞在人口=X.population)
# pandas
df[['mesh1kmid', 'year', 'month', 'dayflag', 'timezone', 'population']].rename(columns={'mesh1kmid':'地域1kmメッシュコード', 'year':'年度', 'month':'月', 'dayflag':'平日休日', 'timezone':'時間帯', 'population':'滞在人口'})
⑤重複を削除したい
SQLと同様にdistinctが使える
# dfply
prefcode_citycode_master >> select(~X.year) >> distinct()
# pandas
prefcode_citycode_master.drop('year', axis=1).drop_duplicates()
⑥フィルタリングしたい
pandasは条件が増えると、( )が多くなるのが嫌だ
# dfply
df >> mask(X.year==2019, X.month==12, X.population >= 10000, X.population <= 20000)
# pandas
df[(df['year']==2019) & (df['month']==12) & (df['population'] >= 10000) & (df['population'] <= 20000)]
⑦特定の列をキーにして、テーブル同士を結合したい
SQLと同様にinner joinが使える
# dfply
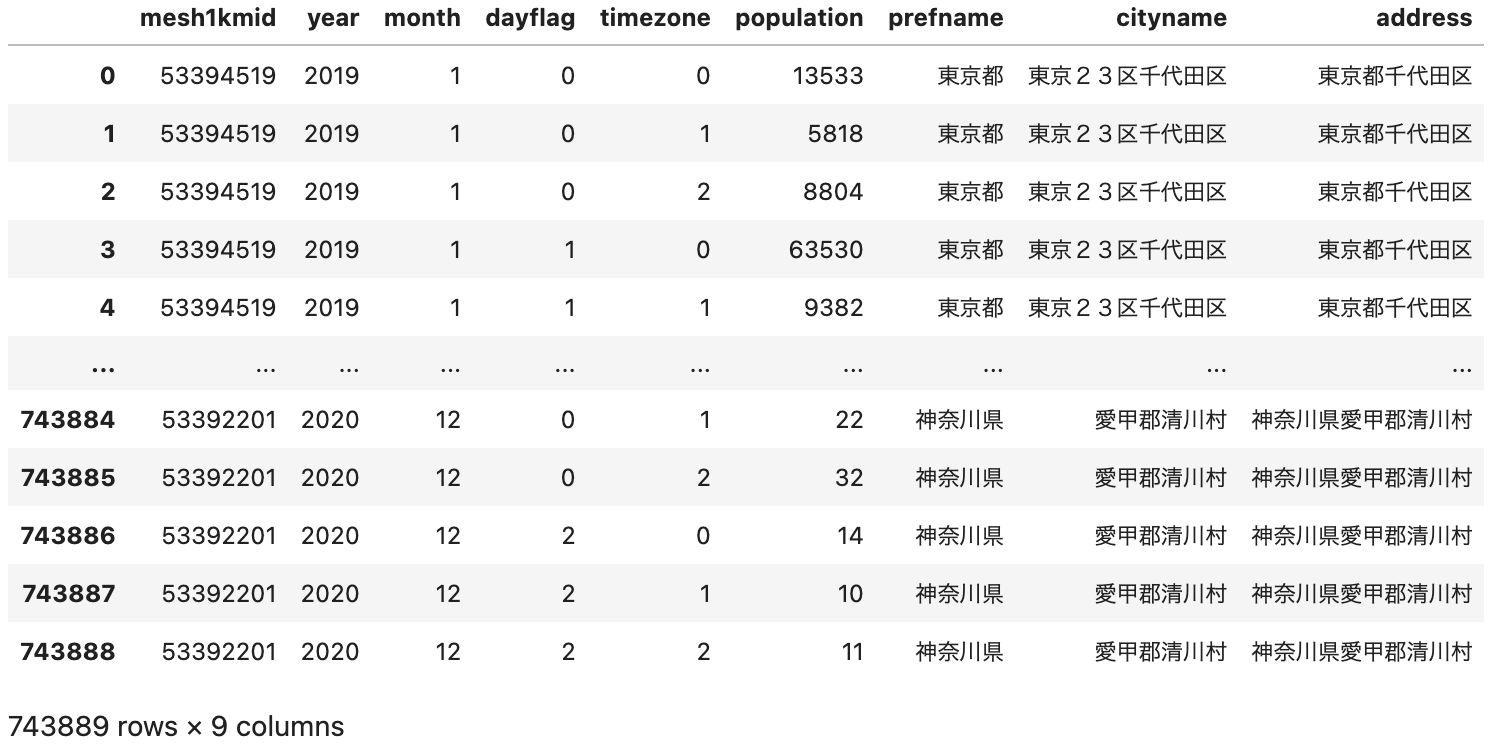
df >> inner_join(prefcode_citycode_master, by=['year', 'prefcode', 'citycode']) >> select(~X.prefcode, ~X.citycode)
# pandas
pd.merge(df, prefcode_citycode_master, on=['year', 'prefcode', 'citycode']).drop(['prefcode', 'citycode'], axis=1)
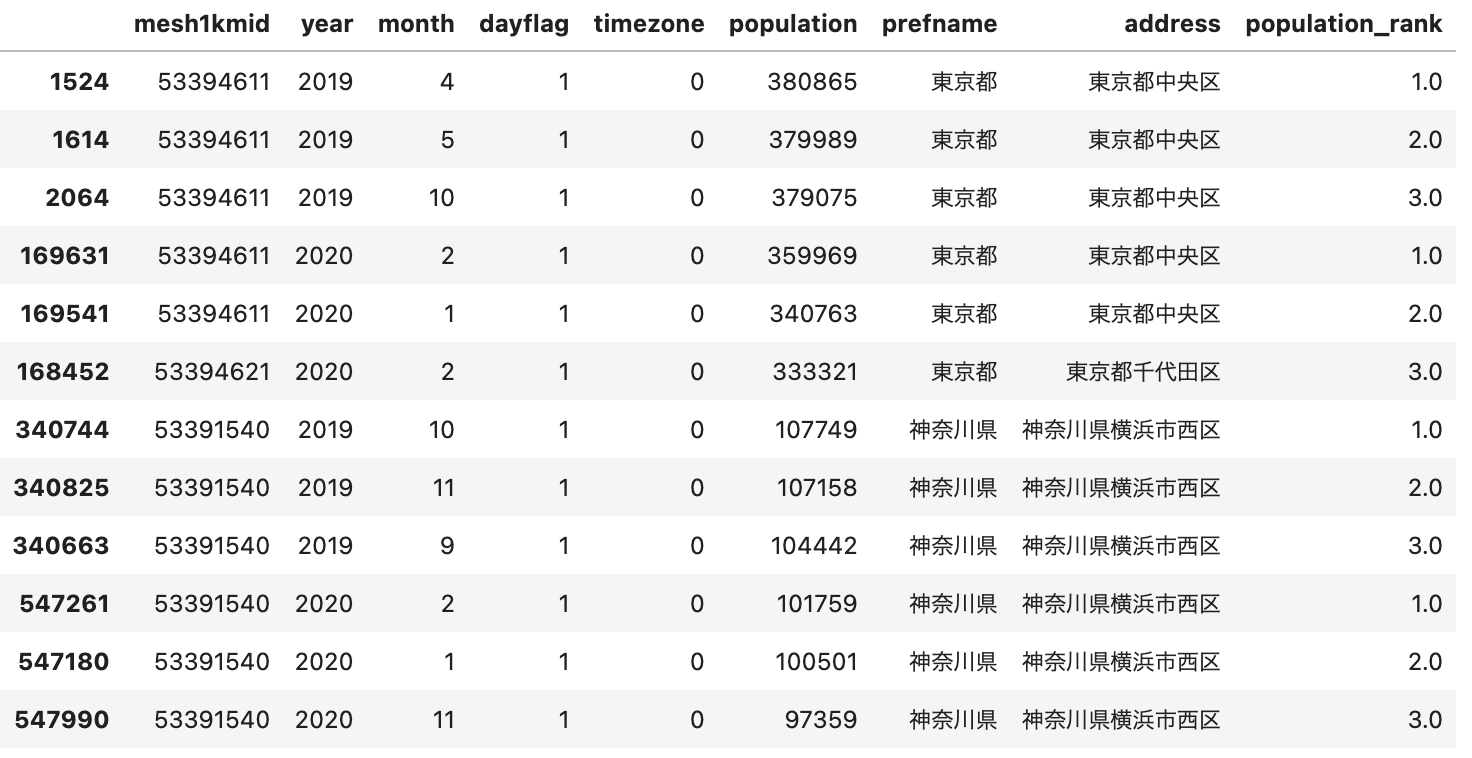
⑧複数列でグルーピング&ランク付けしたい
年度別都道府県別に滞在人口にランク付けして、上位3つを表示することを考える。つまり、SQLのpartition byに相当する操作。
dfply:一行で書こうとすると、ちょい長いが全然許容範囲。 ※mutateは列名を追加する関数です
pandas:ちゃんとググらないとわからないので、諦めました(笑)
# dfply
df >> inner_join(prefcode_citycode_master, by=['year', 'prefcode', 'citycode']) >> select(~X.prefcode, ~X.citycode, ~X.cityname) >> \
group_by(X.prefname, X.year) >> mutate(population_rank=row_number(X.population, ascending=False)) >> mask(X.population_rank<=3) >> arrange(X.population_rank)
⑨複数列でグルーピング&前年比を集計したい
全日(dayflag=2)および終日(timezone=2)に絞って、1kmメッシュ別年平均滞在人口を算出し、前年比を集計する。
dfply:複数の関数を連鎖的に書けるのは便利!
pandas:ちゃんとググらないとわからないので、諦めました(笑)
# dfply
import numpy as np
tmp_df = df >> inner_join(prefcode_citycode_master, by=['year', 'prefcode', 'citycode']) >> mask(X.dayflag==2, X.timezone==2) >> \
select(X.mesh1kmid, X.year, X.month, X.population, X.address) >> group_by(X.mesh1kmid, X.year) >> mutate(avg_population=np.mean(X.population)) >> \
select(~X.month, ~X.population) >> distinct()
df_ratio = tmp_df >> group_by(X.mesh1kmid) >> mutate(lead_avg_population=lead(X.avg_population)) >> mutate(ratio=X.lead_avg_population/X.avg_population) >> mask(X.ratio.notnull())
個人的には、pandasよりも直感的かつ覚えやすいなと!(もちろん、pandasでも便利な書き方はググれば色々あると思いますが、あくまで自分が知っている範囲で)
参考リンク