1. Read Data by "with open" method
青空文庫の 芥川龍之介の"鼻" を読み込んでみる
ファイルの文字コードは、shift_jis

# Pythonでのtext fileの読み書き(入出力)
with open('/hana.txt', mode='r', encoding='shift_jis') as f:
nose_hana = f.read()
print(nose_hana)

2. Preprocessing of "HANA"
# データの前処理
import re
import pickle
nose = re.sub('《[^》]+》', '', nose_hana) # ルビを削除する
nose = re.sub('[|― 「」\n]', '', nose) # |― と全角スペース、「」と改行の削除
nose = re.sub('[ ]', '', nose) #半角スペース削除
nose = re.sub('[\u3000]', '', nose) #\u3000削除
sentense_end = '。'
nose_list = nose.split(sentense_end)
nose_list.pop()
nose_list = [x+sentense_end for x in nose_list]
print(nose_list)
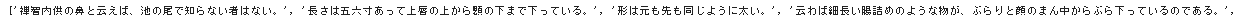
3. WAKATI "分かち書き"
from janome import tokenizer
s = Tokenizer()
t = nose_list
for _ in nose_list:
print(s.tokenize(_, wakati=True))

4. Analysis of results of "WAKATI"
# collectionsで、出現頻度をカウントすることができる
import collections
s = Tokenizer() # インスタンス化
words = []
for _ in nose_list:
words += s.tokenize(_, wakati=True)
c = collections.Counter(words)
print(c)