この記事は、マイナビ Advent Calendar 2021 5日目の記事です。
何を作ったのか
簡単に言うと、検索ワードを入力したら自動でネットから画像を複数枚取得してきて、
それらを画像認識、物体認識をして何が映っているのかを予測するというものです。
なぜ
画像認識について素人である筆者が画像認識の勉強をするのと同時に
潤沢に存在するpythonのライブラリを多用してどんなことができるのか知りたかったからです。
イメージ
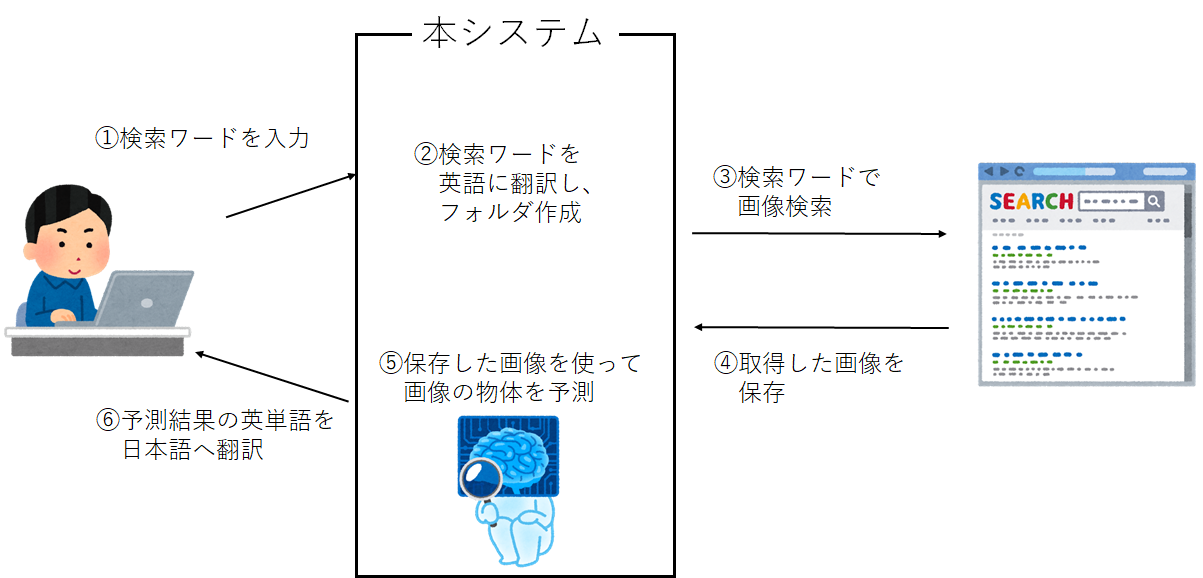
大まかな流れ
①ユーザが何かの単語を入力する(検索ワード)
②検索ワードを英語に翻訳して、フォルダを作成する
③検索ワードで画像検索をし、複数枚の画像を取得
④取得した画像を保存する
⑤保存した画像を一つずつ読み込み、映っている物体を予測する
⑥予測結果の英単語を日本語へ翻訳する
といった感じになっております。
開発環境
- Google Colaboratory
- python
画像検索、翻訳、画像認識それぞれについて
簡単に今回使用する技術の紹介をさせていただきます。
今回使用しているライブラリはとても有名なものばかりですので、
詳しい説明のほうは省略させていただこうと思います。
画像検索
今回pythonで画像検索するためにicrawlerというライブラリを使用し、検索エンジンとしてGoogleを採用しました。
!pip install icrawler
from icrawler.builtin import GoogleImageCrawler
crawler = GoogleImageCrawler(storage={'root_dir':'cats'})
crawler.crawl(keyword='猫', max_num=100)
これで猫の画像を最大100枚取得してくることができます。
keywordの引数に検索したいキーワードを入力します。
また今回はcatsフォルダに保存するために、storageで保存先の指定を行なっています。
翻訳
次に日本語から英語、英語から日本語に翻訳する必要があるため、
翻訳をしてくれるTranslatorというライブラリを使用します。
!pip install googletrans==4.0.0-rc1
from googletrans import Translator
translator = Translator()
text = "Hi,I'm happy"
translator.translate(text=text,src='en', dest='ja').text
# こんにちは、私は幸せです
ほんの数行で翻訳してくれました。(恐るべしgoogletrans)
パラメータについて簡単に説明すると、
srcで翻訳前の言語を指定して、destで翻訳後の言語を指定します。
translator.translateはオブジェクトを返すだけですので、.textを付けて翻訳後の文字列を取得します。
画像認識
画像認識については少し長くなってしまうため、簡単に実装部分だけ確認しておきます。
詳しいことは他のサイトを参考にしていただけますと、幸いです。
今回の開発環境はtensorflowとkerasが標準で搭載されているため、それらを使っていきたいと思います。
使用したライブラリは以下になります。
from keras.applications.vgg16 import VGG16, decode_predictions,preprocess_input
from keras.preprocessing import image
from PIL import Image
import numpy as np
import urllib.request as urllib
また今回はVGG16を使用しており、予測する部分については関数化しております。
def predict(filename, size=5):
img = image.load_img(filename, target_size=(224, 224)) # read image
x = image.img_to_array(img) # Convert image files to numbers
x = np.expand_dims(x, axis=0) # Increase dimensions
pred = model.predict(preprocess_input(x))
results = decode_predictions(pred, top=size)[0] # Convert to string
return results
# VGG16を使用
model = VGG16(weights="imagenet")
# filename:画像へのパス
results = predict(filename, 10)
for result in results:
print(result)
# 10個の予測を信頼度が高い順に表示
今回は結果の中で信頼度が最も高いものを表示するようにします。
実装する
ここまでの長い長い旅も終わり、実装フェーズに入ろうと思います。
お気づきのとおり、コード自体はそこまで長いものではないので実装は簡単にできてしまいます。(すごい)
!pip install icrawler
!pip install googletrans==4.0.0-rc1
import os
from keras.applications.vgg16 import VGG16, decode_predictions,preprocess_input
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential, Model
from keras.layers import Input, Activation, Dropout, Flatten, Dense
from keras import optimizers
from icrawler.builtin import GoogleImageCrawler
from googletrans import Translator
import numpy as np
import time
import shutil
import glob
from PIL import Image
import urllib.request as urllib
def predict(filename, size=5):
img = image.load_img(filename, target_size=(224, 224)) # read image
x = image.img_to_array(img) # Convert image files to numbers
x = np.expand_dims(x, axis=0) # Increase dimensions
pred = model.predict(preprocess_input(x))
results = decode_predictions(pred, top=size)[0] # Convert to string
return results
# VGG16を使用
model = VGG16(weights="imagenet")
# 検索して、フォルダを作成して、保存する
keyword = input('検索:')
translator = Translator()
dir_name =translator.translate(text=keyword, src='ja', dest='en').text
crawler = GoogleImageCrawler(storage={'root_dir':dir_name})
crawler.crawl(keyword=keyword, max_num=1000, overwrite=True)
# 保存された画像から予測する
path = '/content/' + translator.translate(text=keyword, src='ja', dest='en').text + '/*'
files = glob.glob(path)
for file in files:
results = predict(file, 1)
if type(results[0][1]) is not None:
translated = translator.translate(results[0][1], dest='ja', src='en')
print(f'{results[0][1]}({translated.text})') # 第一候補
print(str(round(results[0][2]*100))+'%')
else:
print(results[0][1]) # 第一候補
print(str(round(results[0][2]*100))+'%')
最後のほうで条件分岐をしているのは予測結果が返ってこなかった場合に翻訳することができないとエラーが発生してしまうので、
その場合の対処として分岐をさせています。
テスト
それでは実装も終わったので、犬を例にテストを行なってみたいと思います。
実行すると検索欄が表示されるので、そこに「犬」と入力します。
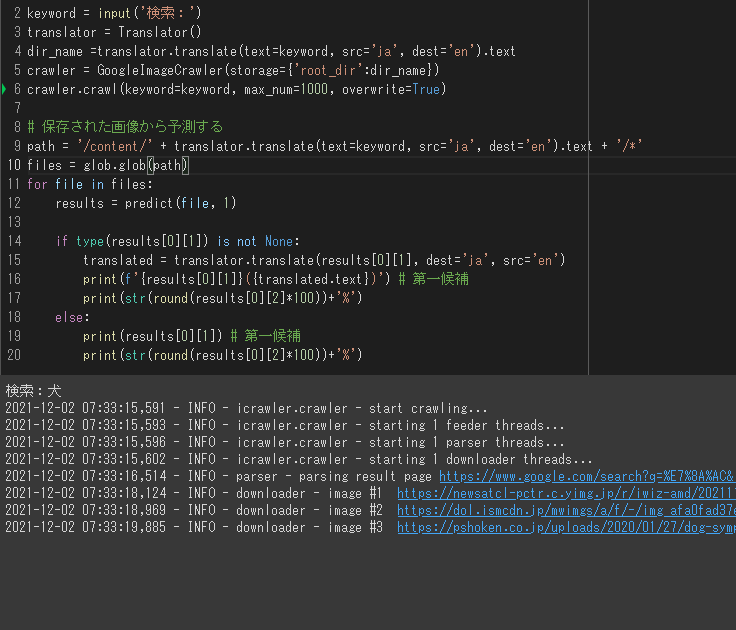
そうすると「犬」の画像検索結果から画像を取得してくれており、
フォルダ「dog」が自動生成されて保存してくれました。
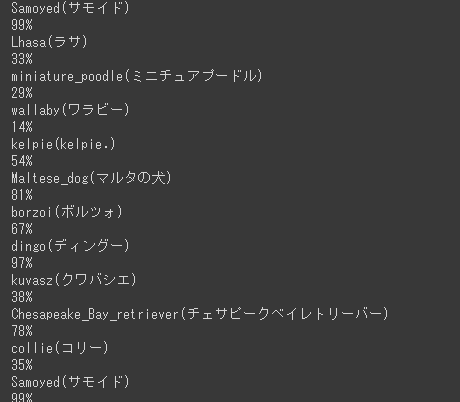
しばらくしてダウンロードが終了すると、保存した画像を読み込んで予測していきます。
本コードでは予測した英単語、日本語訳、信頼度の3つを表示しております。
私の保存した画像では以下のような予測結果になりました。
まとめ
今回、pythonの潤沢なライブラリを使用することで一見難しそうなシステムを初心者の私でも簡単に実装することができました。
また今回は実装できませんでしたが、応用すれば取得した画像から再学習することで様々な画像認識のできるモデルを構築できるのかなとも感じました。
機会があれば次回そこらへんの実装もできればと思います!(たぶん)
それではここまで読んでいただきありがとうございました。