ランダムな作業ログ → 作業内容ごとに[1回目],[2回目]…という形に集計したい
作業記録テーブル(test_log)の概要
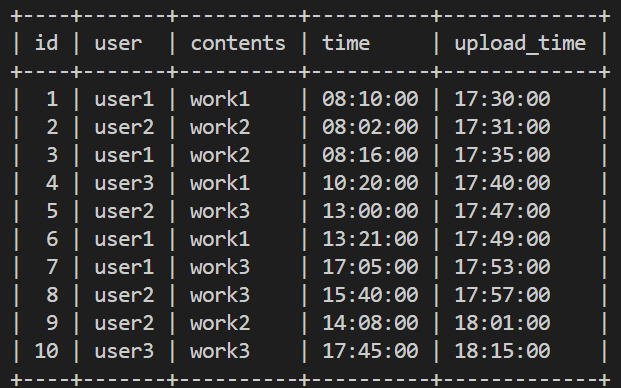
特徴
- カラムは
id、user(作業者)、contents(作業内容)、time(作業時刻)、upload_time(記録した時刻) - 同じ作業内容が複数回行われるが、その際の作業者・作業時刻はランダムに決まっている
- 記録した時刻順にidが振られるため、レコードの順序は
upload_timeの時系列と一致するが、実際の作業時刻であるtimeの時系列とは必ずしも一致していない
これを集計して以下のように、それぞれの作業内容(contents)について、作業回数ごとに作業時刻(time)と作業者(user)の情報を表示したい。![]()

WINDOW関数:NTH_VALUE(☆) OVER(PARTITION BY ★)を使って集計する
【step1】n番目の値を表示するためのwindow関数
FIRST_VALUE(カラム名2) OVER (PARTITION BY カラム名1)
レコードを[カラム名1]の値でパーティショニングして、各パーティションの最初のレコードでの[カラム名2]の値を表示する
これを用いると、test_logテーブルにおける各作業内容(contents)の1回目の作業時刻は以下のコードで表示できる。
SELECT DISTINCT
contents, FIRST_VALUE(time) OVER (PARTITION BY contents) AS 1ST_TIME
FROM
test_log;
*結果*
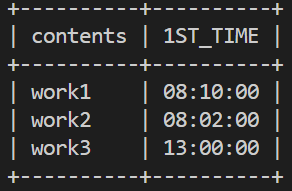
コードも結果で得られるテーブルも、見た目がわりとすっきりシンプル。
しかし、このコードから結果のテーブルが得られるまでの過程の理解は、(初心者にとっては)ちょっとややこしかった。
以下に要点のみをメモ(折りたたみ)
① OVER(PARTITION BY contents)によるレコードの並べ替え
まずtest_logテーブルのレコードを並べ替えて、contentsの値でパーティショニングする

②FIRST_VALUE(time) OVER (PARTITION BY contents)によるカラムの追加
次に各パーティションの最初の作業時刻を表すカラム[1ST_TIME]をテーブルに追加する
(同じパーティションに属するレコードでは、値は当然すべて同じものになる)

③ SELECT DISTINCTで必要なカラムを重複なく表示する
最後にパーティション内で一定の値のみを示しているカラム(contents, 1ST_TIME)のみを選択して、重複を消去する

また、パーティションごとに2番目以降のデータを表示させるときは、以下の関数を用いる
nTH_VALUE(カラム名2, n) OVER (PARTITION BY カラム名1)
レコードを[カラム名1]の値でパーティショニングして、各パーティションのn番目のレコードでの[カラム名2]の値を表示する
【step2】window関数を使った結果と問題点の確認
これらを合わせて、各作業内容(contents)について1~4回目の作業時刻をそれぞれ集計してみる。SELECT文が長くなるので、名前付きwindow関数を使ったコードの書き方に変更。
SELECT DISTINCT
contents,
FIRST_VALUE(time) OVER w AS 1ST_TIME,
nTH_VALUE(time, 2) OVER w AS 2ND_TIME,
nTH_VALUE(time, 3) OVER w AS 3RD_TIME,
nTH_VALUE(time, 4) OVER w AS 4TH_TIME
FROM
test_log
WINDOW
w AS (PARTITION BY contents);
*結果*

一見うまく集計できてそうだが、実はwork3の時系列が2NDと3RDで逆になってしまっている。
元々test_logテーブルは記録時刻(upload_time)の順に並んでいるため、作業時刻(time)の時系列が考慮されていないことが原因。
【step3】timeの時系列を反映させる方法の検討
検討した方法は2つ
- サブクエリで先にレコードを並べ替えておく
- パーティショニングの際に
timeの値で並べ替える
(これらを順番に試していくと、ORDER BYの扱いの難しさがほんのり実感できる気がした)
1. サブクエリで先にレコードを並べ替える
FROM句にORDER BYを含むサブクエリを入れて試すと…
(※エイリアスAS ~がないとエラーになるので注意)
SELECT
contents,
FIRST_VALUE(time) OVER w AS 1ST_TIME,
nTH_VALUE(time, 2) OVER w AS 2ND_TIME,
nTH_VALUE(time, 3) OVER w AS 3RD_TIME,
nTH_VALUE(time, 4) OVER w AS 4TH_TIME
FROM (
SELECT *
FROM test_log
ORDER BY time ) AS new_table
WINDOW
w AS (PARTITION BY contents)
ORDER BY
contents;
*結果*

FROM句のORDER BYがクエリの最後に実行され、PARTITION BYによって並び替えたレコードの順序すら崩れてしまう。
そもそもSQLでは、サブクエリでは順序が指定できない、または特殊な場合しか順序が指定できない、というものが多い。
今回(MySQL)はサブクエリに書かれたORDER BY句はSQLエンジンの裁量によって処理の最後に実行されているが、使用するデータベースの種類によっては異なるタイミンで実行される場合もあるし、このORDER BY句をまるっと無視して処理が実行される場合もある。
このようにデータベースによって得られる結果に差が出やすいため、基本的にORDER BYはクエリの最後にしか使わないようにすることが好ましいらしい。
したがって、1.の方法を手軽に実行するのは難しそう。
クエリの書き方に様々な工夫を凝らせば実現できるかもしれないが、初心者にはちょっと荷が重い。
ORDER BYはクエリの最後でのみ使う(その方がたぶん無難)
2. パーティショニングの際にtimeの値で並べ替える
次に検討した方法によるコード。
PARTITION BYの部分にORDER BY timeを追加してみる。
SELECT
contents,
FIRST_VALUE(time) OVER w AS 1ST_TIME,
nTH_VALUE(time, 2) OVER w AS 2ND_TIME,
nTH_VALUE(time, 3) OVER w AS 3RD_TIME,
nTH_VALUE(time, 4) OVER w AS 4TH_TIME
FROM
test_log
WINDOW
w AS (PARTITION BY contents ORDER BY time);
*結果*

時系列の並びは正しく反映されている。しかし各作業内容毎に
1回目、
1回目~2回目、
1回目~3回目、
という形で時刻が表示されてしまう。
実はOVER句におけるORDER BYは範囲指定の役割を持つため、その結果はただのレコードの並べ替えとは異なる。
デフォルトで(特に範囲の指定なく)ORDER BYを用いるとき、PARTITION BYで作業毎に並べ替えられたレコードは、
①その後作業内容ごとに作業時刻順で並べ替えられ、
②さらに集計対象を1行目から現在行までに限定してnTH_VALUEが実行
という過程で集計・表示される。
つまり②の集計対象を変更するため、以下のようにORDER BYに続けてWINDOW(frame)指定を追加する必要がある。
ORDER BY 指定カラム ROWS BETWEEN 開始行 AND 終了行
「開始行から終了行までの、指定カラムの値」で集計
ORDER BY 指定カラム RANGE 10 PRECEDING
「指定カラムの値が、現在行の値から10以下の範囲にあるもの」で集計
ORDER BY句のWINDOW指定の方法はROWSとRANGEの2種類から選択でき、集計開始行と終了行を自由に指定することができる。
今回はパーティショニング後の各作業内容について、1行目から最後の行までを集計対象として指定する。したがってORDER BY timeに続けて、
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
と書く。
SELECT
contents,
FIRST_VALUE(time) OVER w AS 1ST_TIME,
nTH_VALUE(time, 2) OVER w AS 2ND_TIME,
nTH_VALUE(time, 3) OVER w AS 3RD_TIME,
nTH_VALUE(time, 4) OVER w AS 4TH_TIME
FROM
test_log
WINDOW
w AS (PARTITION BY contents ORDER BY time ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING);
*結果*

集計範囲、時系列ともに正しく反映されている。(上の結果と比較するため、SELECT文のDISTINCTなしで表示。)
作業記録テーブルを集計するための、最終的なコード例
↓以上をふまえて、作業者カラムも追加した完成コード↓
SELECT DISTINCT
contents,
FIRST_VALUE(time) OVER w AS FIRST_TIME,
FIRST_VALUE(user) OVER w AS user,
nTH_VALUE(time, 2) OVER w AS SECOND_TIME,
nTH_VALUE(user, 2) OVER w AS user,
nTH_VALUE(time, 3) OVER w AS THIRD_TIME,
nTH_VALUE(user, 3) OVER w AS user,
nTH_VALUE(time, 4) OVER w AS FOURTH_TIME,
nTH_VALUE(user, 4) OVER w AS user
FROM
test_log
WINDOW
w AS (PARTITION BY contents ORDER BY time ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING);
*結果*
