初めまして、NSSOLで研究員としてデータ分析技術を中心とした研究開発に携わっている、KNです。
NSSOL Advent Calender 2021 18日目は、私が最近気になっている深層学習のモデル軽量化技術についてご紹介したいと思います。
深層学習のモデル軽量化(以下モデル軽量化)について、基礎的な部分をさっくりと知りたい方向けに書いたものになります。
これまでに私が業務内で調査した内容となりますが、至らぬ点等もあると思います。ご指摘等ある際はぜひコメント等いただければと思います。
**注1:**今回の記事では、「学習済みモデルを軽量化する」ことに焦点を当てているため、学習中に適用する手法や再学習を必要とする手法には言及しません。
**注2:**当記事を作成するにあたって、その内容、機能等について細心の注意を払っておりますが、記事の内容が正確であるかどうか、安全なものであるか等について保証をするものではなく、何らの責任を負うものではありません。本記事の利用により、万一、利用者に何らかの不都合や損害が発生したとしても、記事の作者や作者の所属組織は何らの責任を負うものではありません。利用者は本記事の作者や所属組織が責任を負わないことを明確にする義務があります。
目次
1. モデル軽量化とは
深層学習モデルは、最先端の性能を実現するために膨大な数のパラメータを有しており、高い計算能力が必要となります。
モデル軽量化とは、モデルの精度をなるべく保ったままメモリ使用量の削減、処理時間の高速化を行うための技術です。モデル軽量化により、以下のような恩恵があります。
- 高速化により、リアルタイム(に近いスピード)で推論結果が得られる
- モデルサイズの削減により、限られた計算資源で推論が可能になる(環境にも優しい??)
また、具体的な技術の適用先として、以下が挙げられます。
-
エッジデバイスへのモデル実装
- リアルタイム性、通信不安定時もデバイス単体での処理が可能に
- 製造ラインでの部品異常検知、アクティビティセンシング、自動運転
-
サービスでの処理時間高速化
- リアルタイム性
- 顔認証システムの高速化
2. どんな手法があるか
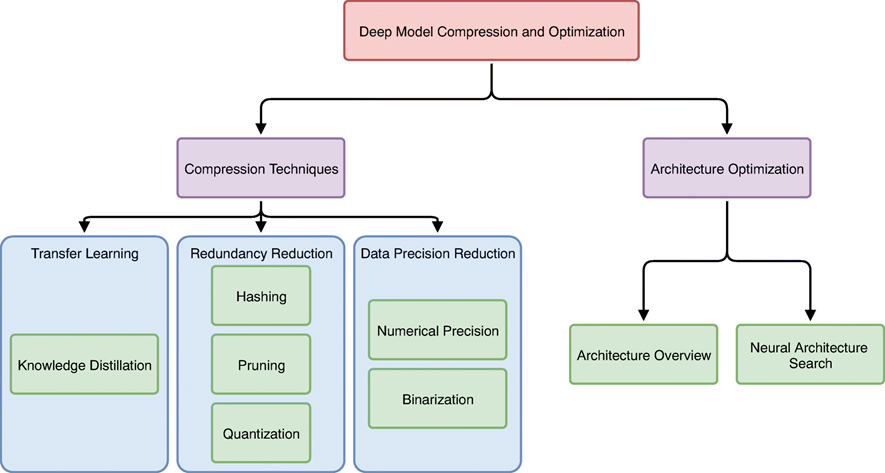
[Anthonyらのサーベイ論文]
(https://link.springer.com/article/10.1007/s11265-020-01596-1)によると、深層学習モデルの軽量化・最適化は以下のように分類できます。
 (https://link.springer.com/article/10.1007/s11265-020-01596-1)
(https://link.springer.com/article/10.1007/s11265-020-01596-1)
今回は、モデルの軽量化に焦点を当てているため、図の左側の部分の中から
- 知識蒸留(Knowledge Distillation)
- 枝狩り(Pruning)
- 量子化(Quantization)
の3手法を紹介します。
3. 知識蒸留(Knowledge Distillation)
知識蒸留(以下蒸留)とは、複雑、巨大な学習済みモデル(教師モデル)の関数を近似し、コンパクトなモデル(生徒モデル)を学習(知識を継承)するための手法です。
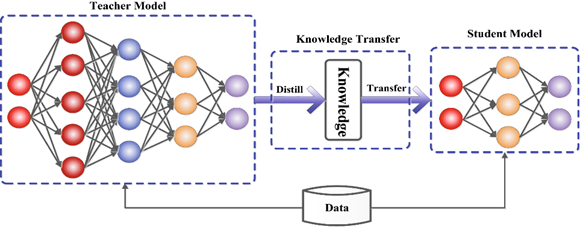
(https://arxiv.org/abs/2006.05525)
蒸留は以下の要素で構成され、要素の組み合わせや違いにより、様々な種類が存在します。
- 知識
- 蒸留スキーム
- 生徒と教師のアーキテクチャ
- 蒸留アルゴリズム
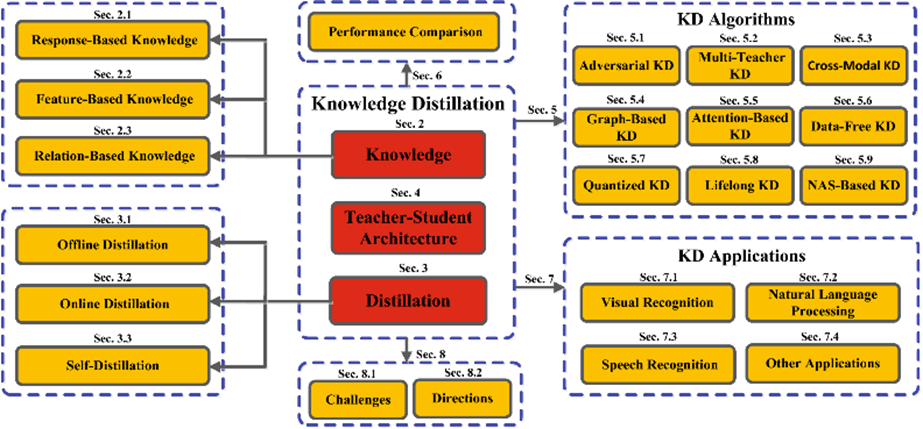
(https://arxiv.org/abs/2006.05525)
蒸留の手法のうち、画像分類タスクで有名なものとしてsoft targets(Hintonら, 2015)があります。
$$L_{ResD}(p(z_t,T),p(z_s,T))=L_R(p(z_t,T),p(z_s,T))$$
$$p(z_i,T)=\frac{exp(\frac{z_i}{T})}{\sum_j exp(\frac{z_j}{T})}$$
- $T$:温度
- $z_t,z_s$:活性化関数で変換前の教師モデル、生徒モデルの出力
- $L_R$:損失関数。KL Divergence等
$L_{ResD}(p(z_t,T),p(z_s,T))$(Distillation Loss)を最小化するようにモデルを学習させ、教師モデルから生徒モデルに知識(ここでは教師モデルの出力)を継承させます。また、出力をそのまま使用するのではなく、温度付きSoftmaxを用いることで、分布の出力をソフトにして、確率の低いクラスの情報を残りやすくしています。
知識として継承されるものとしては、
-
Response-Based Knowledge: モデルの出力
-
Feature-Based Knowledge: モデルの出力と中間層の特徴マップ
-
Relation-Based Knowledge: 上記に加えて、層間、データ間の関係性を考慮
などがあります。また、モデルサイズの軽量化や推論高速化が目的で行われることが多いですが、精度向上を目的とするような手法も存在します。
- DINO
- Noizy Student
などはkaggle等の機械学習コンペでも使用される例が見られました。
4. 枝狩り(Pruning)
枝狩りとは、深層学習モデルのノード間の重みが小さい接続、または影響の小さいノードを削除することで、モデルサイズ、パラメータ数を削減する手法です。
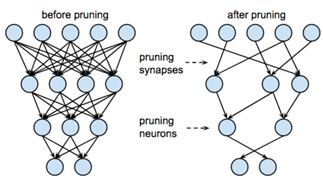
(https://towardsdatascience.com/pruning-neural-networks-1bb3ab5791f9)
枝狩りは一般的に以下の手順で行われます。
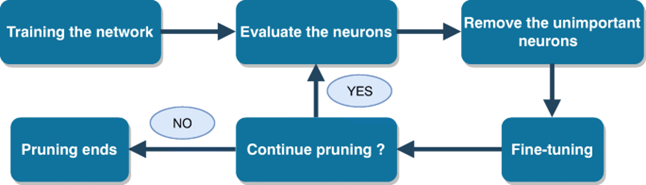
(https://link.springer.com/article/10.1007/s11265-020-01596-1)
Blockらのサーベイ論文によると、枝狩り手法の主な違いは以下の4つで大別できます。
-
Structure:枝狩り後のモデル構造の規則性
- 重み単位、層単位、フィルター単位など、枝狩りする単位
-
Scoring:削除する要素の決定基準
- 重みの絶対値、ニューロンの重要度など
-
Scheduling:枝狩りを行うタイミング
- one-shot、反復的など
-
Fine-Tuning:再学習の方法
- 枝狩り前の重みを使用、ランダムな初期値を使用
枝狩りの有名な手法としては以下がありますが、具体的なアルゴリズムの説明は省略します。
- Magnitude-Based Pruning:ニューロンではなく、重みを削除する手法。
- L0 Regularization:L0正則化付きでモデルを学習させる手法。学習時の話なので今回は省略
- 変分ドロップアウト:こちらも学習時の話なので省略
また、枝狩りの有名な話として、宝くじ仮説というものがあります。とてもざっくりいうと
- 宝くじ仮説:学習済みのモデルには、一部を切り出して同じ程度学習させても元の学習済みモデルと同程度の性能をもつ部分ネットワーク(当たりくじ)が存在する、という仮説
というものです。論文内の検証において、元のネットワークの10%〜20%のサイズ、かつ元のネットワークよりも精度の高い当たりくじが発見できた、と報告されています。
5. 量子化(Quantization)
量子化とは、重みなどのパラメータをより小さいビット(32, 16bit→8,4bit)で表現し、メモリの使用率を下げるなどして、ネットワークの構造を変えずにモデルの軽量化を図る手法です。
量子化の手法は、主に以下の二つに大別できます。
- Post-Training Quantization:学習後にモデルを量子化する
- Quantization-Aware Training:学習中に量子化誤差も含めてモデルを学習。
今回は、「学習済みモデルの軽量化」に焦点を当てるため、Post-Training Quantizationに関する手法について言及します。
まず、一般的な量子化後のテンソル(or行列)は以下で計算されます。
$$X_q=f(s*g(X_r)+z)$$
- $X_r$:量子化前のテンソル(or行列)
- $s, z$:量子化パラメータ
- $f(・)$:丸め関数
また、$g(・)$は以下のように計算されます。
$$g(・)=clamp(x,α,β)=max(min(x,β),α)$$
- $x$:$X_r$の各要素
- $α,β$:手法により異なるパラメータ
$f(・)$でどれくらいのbit数に落とすかを決定し、量子化パラメータ$s,z$の決め方や$g(・)$の決め方により量子化前の値の再現度や計算コストが変わってきます。
量子化パラメータ$s,z$の決め方は、**静的量子化(static quantization)と動的量子化(dynamic quantization)**に大別されます。静的量子化は、中間層を(推論前に)あらかじめ量子化しておく手法で、動的量子化は、推論時に量子化を行う手法となっています。2手法間の比較は以下のようになっています。(低、高などは表内の他の手法と比較して)
| 手法 | 計算コスト | 量子化後の誤差 | 特徴 |
|---|---|---|---|
| 静的量子化 | 低 | 高 | - 中間層をあらかじめ量子化 - 事前に入力空間を代表するようなデータ集合を用意して、全ての中間層に対する量子化パラメータを求める - 代表データの選び方に注意が必要 |
| 動的量子化 | 高 | 低 | - 推論時に量子化 - 層ごとの量子化パラメータを動的に求める - 量子化する層/しない層を混ぜられる |
基本的に量子化後の値の精度と計算コストはトレードオフな関係になっており、量子化を行うツールによりどちらが採用されているかが異なったり、選択できたりします。
次に、$g(・)$についてですが、こちらは代表的なものとしてmin-max法とmax-abs法が存在します。定式化と特徴をそれぞれ説明します。
-
min-max法
$$g(x)=clamp(x,m,M)$$
$$s=\frac{n-1}{M-m},z=\frac{m*(1-n)}{M-m}$$ -
$m=\min{X_r},M=\max{X_r}$
-
$n$:bit幅から算出された表現可能な最大数
min-max法は、有効範囲が広く、元の値をより正確に再現できることが特徴です。一方で、量子化前の0と量子化後の0が一致していない(asymmetricな方法)ため、計算コストがかかります。
- max-abs法
$$g(x)=clamp(x,-R,R)$$
$$s=\frac{n-1}{R},z=0$$
- $R=\max{{abs{Xi}}}$
max-abs法は、量子化前の0と量子化後の0が一致する(symmetricな方法)ため、計算コストが低いことが特徴です。一方で、有効範囲が狭いため元の値からの精度劣化はmin-max法より大きくなってしまいます。
基本的には、達成したい精度や計算スピード、使用可能な計算リソース等に応じて、手法を選択していくことになります。
6. まとめ
今回は、深層学習のモデル軽量化技術として、蒸留、枝狩り、量子化の3手法を紹介しました。枝狩り、量子化についてはTensorFlow LiteやPyTorchのモジュール、TensorRT,OpenVINOなどツール群も充実しており、比較的試しやすくなっていると思います。
次回はツールの比較、実際にツールを使った検証についての記事を書きたいと考えておりますので、しばしお待ちください。
それでは、お読みいただきありがとうございました!!
7. 参考文献
- Deep Model Compression and Architecture Optimization for Embedded Systems: A Survey
- Knowledge Distillation: A Survey
- Pruning and quantization for deep neural network acceleration: A survey
- WHAT IS THE STATE OF THE ART NEURAL PRUNING?
- NISP: Pruning Networks using Neuron Importance Score Propagation
- Block Pruning For Faster Transformers
- PyTorchのモデルを別形式に変換する方法いろいろ(TorchScript, ONNX, TensorRT, CoreML, OpenVINO, Tensorflow, TFLite)
- PyTorch, ONNX, Caffe, OpenVINO (NCHW) のモデルをTensorflow / TensorflowLite (NHWC) へお手軽に変換する
- ニューラルネットワークのPruningの最新動向について
- ONNX
- デーィプラーニングを軽量化する「モデル圧縮」3手法