はじめに
本エントリーは某社内で実施するSQLアンチパターン勉強会向けの資料となります。
本エントリーで書籍「SQL アンチパターン」をベースに学習を進めます。書籍上でのサンプルコードはMySQLですが、本エントリーでのサンプルコードはSQL Serverに置き換えて解説します。
また本章以外のエントリーおよび利用するSQLリソースなどは、以下のGitHubを参照ください。
本章のナイーブツリーは、現在では多くのデータベースで共通テーブル式がサポートされたことにより、多くのデータベースにおいてアンチパターンとはなりません。
SQLアンチパターンの書籍内で指摘されていた、共通テーブル式がサポートされていないデータベースの内、2018.09.04現在において、サポートされていないのはIBM Informixのみとなっているようです。
そこで、本章ではアンチパターンとされた理由を解説した上で、その問題を共通テーブル式を利用して解決する方法を説明します。
目的
再帰的な階層構造を保存し、クエリーを実行する事を検討します。階層構造はTree状の構造を持ち、Treeの各要素をノードと呼びます。本エントリーではノードを次のように区分して記述します。
- 根(ルート):親を持たない最上位のノード
- 葉(リーフ):子を持たない末端のノード
- 非葉:根と葉の中間ノード
具体的には、組織構造や掲示板のスレッドなどが該当します。
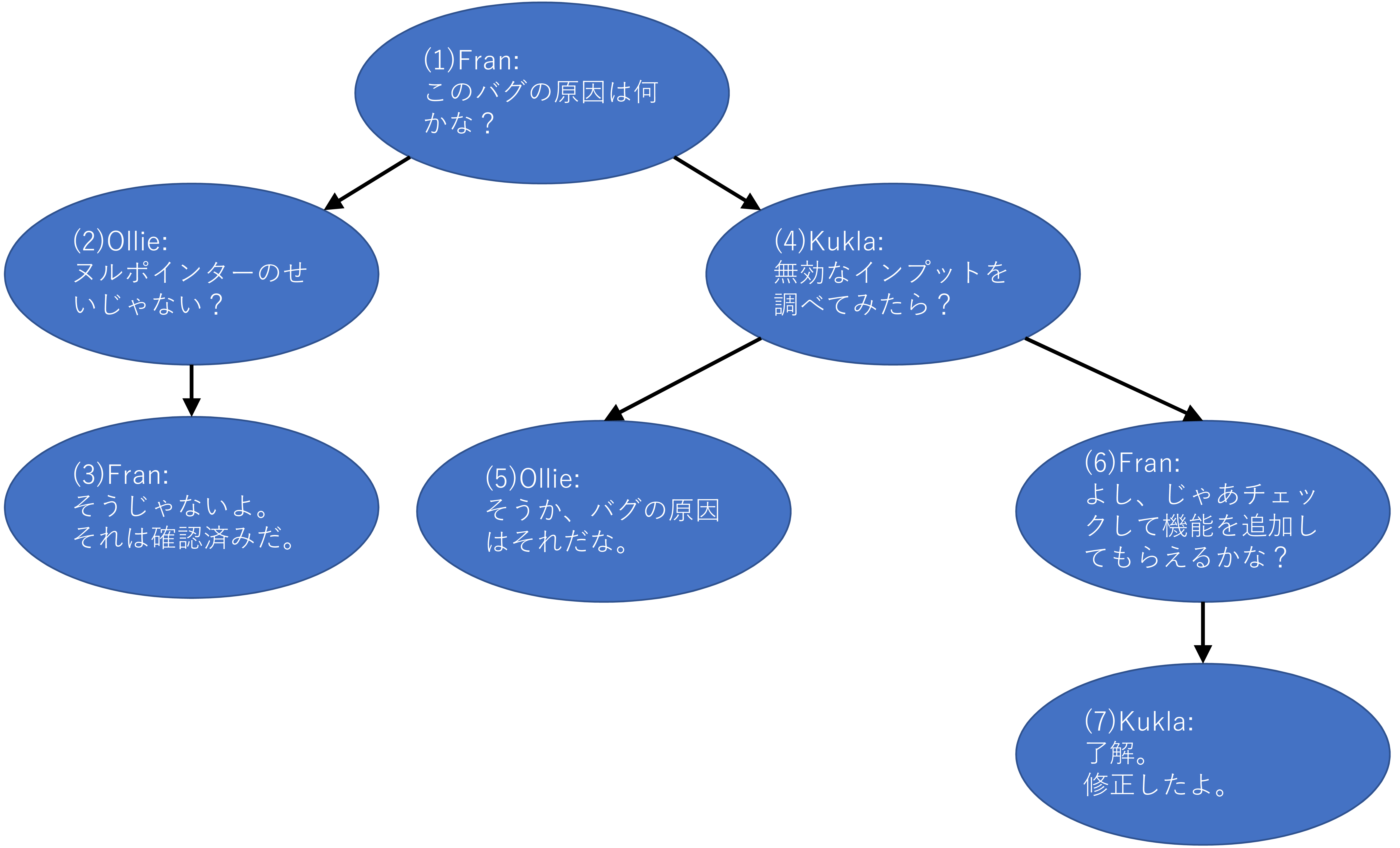
本エントリーではつぎのようなバグに対するツリー状のコメントをサンプルとして利用します。
ナイーブツリー(隣接リスト)
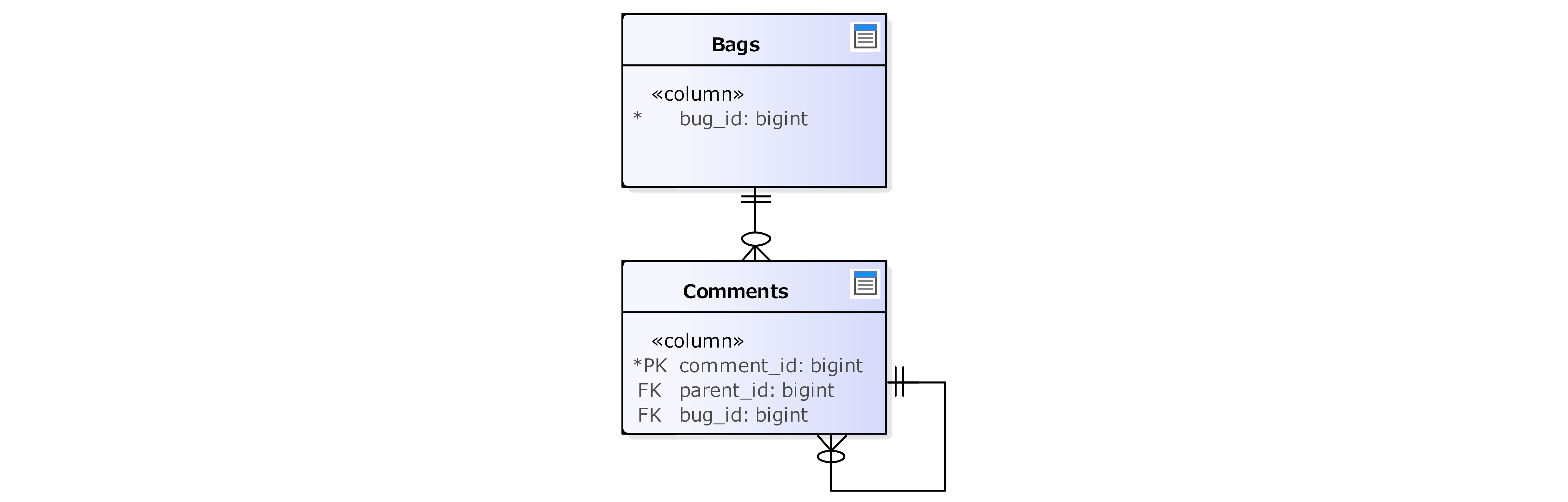
ノードが直近の親のIDのみを保持するような素朴(ナイーブ)なデータ構造を「隣接リスト」と呼びます。具体的には以下のようなテーブルになります。
CREATE TABLE Comments (
comment_id BIGINT identity,
parent_id BIGINT,
bug_id BIGINT NOT NULL,
author BIGINT NOT NULL,
comment_date DATETIME NOT NULL,
comment TEXT NOT NULL,
CONSTRAINT PK_Comments PRIMARY KEY CLUSTERED (comment_id),
FOREIGN KEY (parent_id) REFERENCES Comments(comment_id),
FOREIGN KEY (bug_id) REFERENCES Bugs(bug_id),
FOREIGN KEY (author) REFERENCES Accounts(account_id),
);
CREATE NONCLUSTERED INDEX IDX_Comments_01 ON Comments (parent_id);
テーブルには、つぎのようなデータが投入されます。
| comment_id | parent_id | bug_id | 発言者 | コメント |
|---|---|---|---|---|
| 1 | NULL | 1 | Fran | このバグの原因は何かな? |
| 2 | 1 | 1 | Ollie | ヌルポインターのせいじゃない? |
| 3 | 2 | 1 | Fran | そうじゃないよ。それは確認済みだ。 |
| 4 | 1 | 1 | Kukla | 無効なインプットを調べてみたら? |
| 5 | 4 | 1 | Ollie | そうか、バグの原因はそれだな。 |
| 6 | 4 | 1 | Fran | よし、じゃあチェックして機能を追加してもらえるかな? |
| 7 | 6 | 1 | Kukla | 了解。修正したよ。 |
| 8 | NULL | 2 | Fran | What is this? |
8番目だけ違うバグに対するコメントである点に注意してください。
このようなテーブル構造は、指定のノードの子孫ノードをすべて取得する場合や、逆に指定ノードの祖先ノードをすべて取得する事が困難でした。しかし共通テーブル式が多くのデータベースでサポートされたことにより、この問題の多くは解決されました。
逆に隣接リストは構造がシンプルで、ノードの移動や中間ノードの削除・中間ノードの挿入といった処理が簡単にできるため、共通テーブル式が利用できないために発生していた不都合が解消されるのであれば、隣接リストを用いる方が良いケースが多いかと思います。
では具体的に共通テーブル式による解決方法を見ていきましょう。
指定バグに紐づくすべてのコメントを取得する
つぎのSQLが共通テーブル式を利用した再帰クエリになります。
with CommentTree
(comment_id, parent_id, bug_id, author, comment_date, comment, depth)
as (
select
*, 0 as depth
from
Comments
where
parent_id is null
union all
select
Comments.*, CommentTree.depth+1 as depth
from
CommentTree
inner join Comments
on CommentTree.comment_id = Comments.parent_id
)
select * from CommentTree where bug_id = 1
withで定義されたCommentTreeが共通テーブル式になります。
as の内部を見ると、Commentsテーブルでparent_idがnullのレコードをすべて取得し、一旦CommonTreeに結果を返しているのが見て取れます。その後、union allの後のselect句でCommonTreeをselectしており、先に選択された行の直接の子供のレコードを選択しています。
これを再帰的に実行する事で、bug_idが1のバグに紐づく、全てのCommentsが取得されます。
つぎの表が実行結果になります。
| comment_id | parent_id | bug_id | author | comment_date | comment | depth |
|---|---|---|---|---|---|---|
| 1 | NULL | 1 | 1 | 12:13.0 | このバグの原因は何かな? | 0 |
| 2 | 1 | 1 | 2 | 12:13.0 | ヌルポインターのせいじゃない? | 1 |
| 3 | 2 | 1 | 1 | 12:13.0 | そうじゃないよ。それは確認済みだ。 | 2 |
| 4 | 3 | 1 | 3 | 12:13.0 | 無効なインプットを調べてみたら? | 3 |
| 5 | 4 | 1 | 2 | 12:13.0 | そうか、バグの原因はそれだな。 | 4 |
| 6 | 4 | 1 | 1 | 12:13.0 | よし、じゃあチェックして機能を追加してもらえるかな? | 4 |
| 7 | 6 | 1 | 3 | 12:13.0 | 了解。修正したよ。 | 5 |
comment_idが5と4の行のdepthを見てください。ちゃんといずれも4になっていることが見て取れます。
実行プランもすべてインデックスが適切に利用されていることが見て取れるでしょう。
指定ノードと、その子孫をすべて取得する
では続いて、comment_idが4のコメントと、それに紐づくすべての子孫ノードを取得してみましょう。
with CommentTree
(comment_id, parent_id, bug_id, author, comment_date, comment, depth)
as (
select
*, 0 as depth
from
Comments
where
comment_id = 4
union all
select
Comments.*, CommentTree.depth+1 as depth
from
CommentTree
inner join Comments
on CommentTree.comment_id = Comments.parent_id
)
select * from CommentTree
asの直後のselect文のwhere句にてcomment_idを明示的に指定しています。実行結果はつぎのとおりです。
| comment_id | parent_id | bug_id | author | comment_date | comment | depth |
|---|---|---|---|---|---|---|
| 4 | 3 | 1 | 3 | 12:13.0 | 無効なインプットを調べてみたら? | 0 |
| 5 | 4 | 1 | 2 | 12:13.0 | そうか、バグの原因はそれだな。 | 1 |
| 6 | 4 | 1 | 1 | 12:13.0 | よし、じゃあチェックして機能を追加してもらえるかな? | 1 |
| 7 | 6 | 1 | 3 | 12:13.0 | 了解。修正したよ。 | 2 |
正しく取得されているのが見て取れるでしょう。
指定ノードと、その祖先をすべて取得する
comment_idが6のコメントと、それに紐づくすべての先祖を取得します。
with CommentTree
(comment_id, parent_id, bug_id, author, comment_date, comment, depth)
as (
select
*, 0 as depth
from
Comments
where
comment_id = 6
union all
select
Comments.*, CommentTree.depth+1 as depth
from
CommentTree
inner join Comments
on CommentTree.parent_id = Comments.comment_id
)
select * from CommentTree
ポイントはunion allの後のselect分です。先ほどはTreeを上から下へ探索していましたが、今度はTreeを下から上へ探索するようにしています。具体的にはinner joinのonの中の条件が異なります。
これを実際に実行したのが次の通りです。
| comment_id | parent_id | bug_id | author | comment_date | comment | depth |
|---|---|---|---|---|---|---|
| 6 | 4 | 1 | 1 | 35:59.5 | よし、じゃあチェックして機能を追加してもらえるかな? | 0 |
| 4 | 1 | 1 | 3 | 35:59.5 | 無効なインプットを調べてみたら? | 1 |
| 1 | NULL | 1 | 1 | 35:59.5 | このバグの原因は何かな? | 2 |
ちゃんと子から親へ逆順で取れているのが見て取れるでしょう。
指定ノード以下をすべて削除する
ON DELETE CASCADEで削除しましょう。以上。
まとめ
という訳で、書籍が出版された当時はアンチパターンになりがちだった(その当時でも絶対になるわけではなかった)近接リストですが、現代では共通テーブル式を利用した再帰クエリで十分なケースが多くなっているものと思います。
SQLアンチパターンでも、再帰クエリを含めた代案との比較がつぎのように説明されています。
| 設計 | テーブル数 | 子へのクエリ実行 | ツリーへのクエリ実行 | 挿入 | 削除 | 参照整合性維持 |
|---|---|---|---|---|---|---|
| 再帰クエリを使わない隣接リスト | 1 | 簡単 | 難しい | 簡単 | 簡単 | 可能 |
| 再帰クエリを使った隣接リスト | 1 | 簡単 | 簡単 | 簡単 | 簡単 | 可能 |
| 経路列挙 | 1 | 簡単 | 簡単 | 簡単 | 簡単 | 不可 |
| 入れ子集合 | 1 | 難しい | 難しい | 難しい | 難しい | 不可 |
| 閉包テーブル | 2 | 簡単 | 簡単 | 簡単 | 簡単 | 可能 |
この通り、再帰クエリを使った隣接リストが全体的に優位にあると言えます。
ただし閉包テーブルはデータ量が多くなるデメリットがありますが、親子が多対多のデータ構造も表現できるため、選択肢として持っておくと良いかもしれません。
以上です。