はじめに
はい、こんにちは。しくみ製作所のNotch44です。
今年もアドベントカレンダーの時期がやってきました!
この時期だけは記事を書こうと、ネタ探しに躍起になっていましたが、全く見つからない・・・(どちらかといえばネタを探す時間がないだけなのかもしれない)。
せっかくAlexaを手に入れたので、なにかスキルでも作ろうと思ったんですが、たまたま知り合いからちょっとしたタスクを依頼されまして。その作業工程を記事にしたほうが、誰かの参考になりそうな気がしたので、そっちにしました。
誰向けの記事?
事前に断っておきますが、クローラー玄人向けじゃないです。バリバリ書いてる人は回れ右↩︎
どちらかと言えば、これからクローラーを使って作業してみたいけど、どんなことに使えて、どんな風に使ったら良いの?っていう事例の一つです。
要件
某施設の利用予約サイトの閲覧性が著しく低いイマイチなので、生データを取ってきて手元で加工したほうが良いな、という要望でした。とりあえずAPI作ってくれればOKってことだったんで、ここでは取ってくる手順だけ紹介。だいたい面倒なのって加工の方なんですけどね。特に今回のサイトはテーブルの作りがマジで(ry
何を使おう
- とりあえず手元のmac上で動かす
- Python3系(なんとなく)
まずはサイトを見てみよう
まずはサイトにアクセス。うん、古風なデザインだ。最近この手のサイトは減ってると思うけど、公共機関のサイトとかだとまだまだ現役だよね。
とりあえず開発者ツールでサイトを調べた感じ、がっつりJSで作られてるっぽい。しかも一つ一つの処理を見ていくと、POSTしてるパラメータがめちゃめちゃわかりづらい。これ解析してると時間かかりそうだな〜と思ったので、ここはヘッドレスブラウザを使おうと決意。
ヘッドレスChromeがリリースされてある程度経ったし、いい加減使ってみたいと思っていたのでこれを採用。まぁ理由を後付けすれば、Chromeで再現できないものは他でもたぶん無理でしょうってことで。あと、今回速度はあんまり重要じゃないから正確に描画できることの方が大事。
細かい設定とかインストールについてまとめてくれてるサイトを紹介してるので、その辺を見てもらえれば。

Xpathをとってこよう
最近のブラウザの開発者ツールはマジで優秀。3日の記事でも書いている方がいましたが、右クリックで取得したい要素のXpathが取れます。
よし、さっそく該当のXpathを取得して・・・
AttributeError: 'list' object has no attribute 'click'
あぁ、Xpathで取ってくると配列なのか、なるほど。んじゃ先頭を選んで、と。
IndexError: list index out of range
え?そもそも取れてないじゃん。おかしい・・・この要素はページに一つしかないし、開発者ツールでXpathをコピーしてるんだぞ?(ここまで作業開始からトータル15分ぐらい)
ここで超ハマる。(2時間ぐらい)
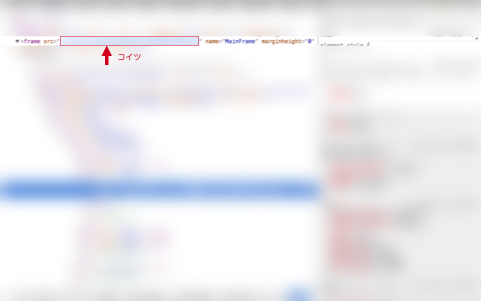
要素が取得できなかった原因
結論としては、サイトがフレーム分割されていたからでした。
しかもframeが読んでるsrcのパスが違うという、非常に(クローラーにとって)厄介な作り。当然ながら直接叩きに行くとトップにリダイレクトされる。仕方ないのでいったん該当のページに遷移してからframe内のsrcパスにアクセスし直すという手段で回避。
ここのうまい回避方法があったら知りたいけど、アクセス解析しないで突破するには一番手っ取り早いような気もする。
後処理
残りはおまけみたいもんでした。チェックボックスにチェックを入れながらボタンをぽちぽち押していく作業。該当ページにたどり着いたらBeautifulSoupで要素のタグをサクッと取得して一応クローラーとしての作業は完了。どちらかといえばこの後のデータ解析と情報再現のが辛い作業です。
ソース
Githubに公開するほどの量でもないですし、だいたい参考サイトのソースとほぼ同じなんですが、一応載っけておきます。適当な名前でコピペしてimportしてみてください。エラーハンドリングが適当なんで、もっと書いたほうが良いです、というか書かないとダメです。もし実運用する場合は、エラーハンドリングが一番大変だと思ってください。特にスクレイピングに関しては、エラーハンドリングの精度によって運用難易度の差が顕著に出ると思います。サイトは日々更新されるので、同じXpathなんてすぐ使えなくなります。その度にクローラーが落ちてしまい、メンテがとてつもなく大変なことになります。ある程度冗長化されるように頑張りましょう。
エンコーディングのチェック用
import requests
import cchardet
import timeout_decorator
@timeout_decorator.timeout(5, timeout_exception=StopIteration)
def encoding_job(ua, url):
headers = {'User-Agent': ua}
resp = requests.get(url, timeout=1, headers=headers, verify=False)
if resp.status_code != 200:
print("レスポンス取得失敗")
raise Exception('ステータスエラー')
encoding = resp.encoding
ccencoding = cchardet.detect(resp.content)["encoding"]
if len(ccencoding) > 0:
resp.encoding = ccencoding.lower()
encoding = ccencoding
print("エンコードチェック: %s" % encoding)
return encoding
raise Exception('エンコーディングエラー')
クローラー(スクレイピング)部分
import time
from selenium import webdriver
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
def settings(ua, encoding):
# Headless Chrom設定
options = Options()
# デバッグ時は一時的に外しとくとやりやすい
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('--ignore-certificate-errors')
options.add_argument('--allow-running-insecure-content')
options.add_argument('--disable-web-security')
options.add_argument('--disable-desktop-notifications')
options.add_argument("--disable-extensions")
options.add_argument('--user-agent={ua}'.format(ua = ua))
options.add_argument('--script-encoding={enc}'.format(enc = encoding))
options.add_argument('--lang=ja')
return options
def crawling_job(encoding, ua, url, url2):
options = settings(ua, encoding)
# Chrome初期化
driver = webdriver.Chrome(chrome_options=options)
driver.get(url)
# frame分割対応
driver.get(url2)
# テストは都度書くことをオススメします
assert '' in driver.title
input_element = driver.find_elements_by_xpath('')
input_element[0].click()
# ・・・次々書いていきましょう
# パーサはlxmlが安定(試したサイトだと他はダメだった)
soup = BeautifulSoup(html, "lxml")
# この辺はページ毎・欲しいもの毎に
td = soup.find_all("td", class_="欲しいクラス")
print(td[0].renderContents())
driver.quit()
参考資料
- こちらのサイトはめちゃめちゃ参考になると思います(自分が以前仕事でクローラー作ってたときに読みたかった)
- こちらのサイトは知っている人はあまり必要ないと思いますが初めての方はぜひ