Nospareの佐藤 & Nospare・東京大学の菅澤です.
今回はRue et al. (2009)で提案されたINLA(Integrated Nested Laplace Approximation)を使った大規模データの近似ベイズ法について紹介します.
大規模データに対してMCMCによるベイズ分析を実行する場合
- 巨大な行列やベクトルの計算を各繰り返しで行う必要がある
- (潜在変数モデルでは特に) 各繰り返しで生成するパラメータや変数の数が非常に多い
などの理由で,計算に非常に時間がかかってしまいます.このような問題に対して様々な近似解法が提案されていますが,本来実行したいMCMCと同等の精度を保持しつつ低計算コストを達成する方法を作ることは容易ではありません.
INLAは潜在ガウスモデル(Latent Gaussian Models; LGM)と呼ばれるクラスに対して使える方法ですが,このモデルは典型的な回帰モデルや一般化線形混合モデル,加法モデル,生存解析モデル,時空間モデルなど含む非常に汎用性の高いモデルのクラスです.
INLAはLGMに対してMCMCよりもはるかに高速にパラメータや潜在変数の周辺事後分布の正確な近似を得ることができます.MCMCで数時間や数日かかってしまうような計算でも,場合によっては数分で正確な計算ができてしまいます.
潜在ガウスモデル(LGM)
LGMの基本的な設定を以下にまとめます.
- $\boldsymbol{y}=(y_1,y_2,\ldots,y_N)$:観測される被説明変数
- $y_i$は平均$\mu_i$,リンク関数$g(\cdot)$を持つ指数型分布族(正規分布,二項分布,ポアソン分布など)にしたがう
- $\eta_i$:線形予測子
g(\mu_i)=\eta_i, \ \ \ \
\eta_i = \alpha + \sum_{j = 1}^{n_f} f_{j}(u_{ji}) + \sum_{k = 1}^{n_\beta} \beta_k z_{ki} + \varepsilon_i \qquad i = 1,2,\ldots, N.
- $\alpha$:切片項 $\beta_j$:回帰係数 $z_{ij}$:説明変数 ${f^{(j)}(\cdot)}$:関数 $\varepsilon_i$:ランダムな誤差項
- $\boldsymbol{x}$:${\eta_i}, \alpha, {f^{(j)}}, {\beta_k}$をまとめた$n$次元ベクトル (潜在変数)
このときLGMは以下のように記述されます.
y_i \mid \boldsymbol{x},\boldsymbol{\theta}_2 \sim \pi(y_i\mid\boldsymbol{x},\boldsymbol{\theta}_2), \ \ \ \ \ \ \ \
\boldsymbol{x}\sim N(\boldsymbol{0}, \boldsymbol{Q}^{-1}(\boldsymbol{\theta}_1))
$\pi(y_i\mid\boldsymbol{x},\boldsymbol{\theta}_2)$はdispersionパラメータ$\boldsymbol{\theta}_2$をもつ指数型分布族で,$\boldsymbol{Q}(\boldsymbol{\theta}_1)$は精度行列(分散共分散行列の逆行列)です.INLAではこの精度行列に注目して計算していくのが肝となります.
上記のモデル式から,潜在変数$\boldsymbol{x}$を経由して$y_i$のモデル化を行っており,潜在変数の分布が(事前分布として)正規分布にしたがっていると解釈することができます.これがLGMの名前の由来になっています.
以下では$\boldsymbol{\theta} = (\boldsymbol{\theta}_1, \boldsymbol{\theta}_2)$という表記も使います.これは観測分布や潜在変数分布を決めるハイパーパラメータです.
LGMにおいてINLAを考える上での重要な仮定は以下の3つです.
- (条件付き独立性) 潜在変数$\boldsymbol{x}$が所与のもとで各$y_i$は独立
- (スパース性) 精度行列$\boldsymbol{Q}(\boldsymbol{\theta}_1)$はスパース (ほとんどの要素がゼロ)
- (ハイパーパラメータの低次元性) $\boldsymbol{\theta}$の次元$m$は大きくない (論文中では$m\leq 6$程度を想定)
潜在変数の次元$n$は基本的にサンプルサイズ$N$に応じて増えていきます.したがって$N$が大きくなるにつれて$\boldsymbol{x}$の分散共分散行列を含んだ計算は困難になっていきます.しかし,多くのモデルにおいて精度行列$\boldsymbol{Q}(\boldsymbol{\theta}_1)$はスパースである場合が多く,$\boldsymbol{Q}$を中心に計算方法を設計することで,スパース行列の高速計算手法を適用できるようにするのがINLAのコアとなっているアイデアの一部です.
また,ハイパーパラメータの低次元性も多くのモデルで満たされる性質です.
INLA (Integrated Nested Laplace Approximation)
LGMにおける$(\boldsymbol{x},\boldsymbol{\theta})$の事後分布は次のようになります.
\pi(\boldsymbol{x},\boldsymbol{\theta}|\boldsymbol{y})
\propto
\pi(\boldsymbol{\theta})|\mathbf{Q}(\boldsymbol{\theta}_1)|^{1 / 2} \exp \left[-\frac{1}{2} \mathbf{x}^{\mathrm{T}} \mathbf{Q}(\boldsymbol{\theta}_1) \mathbf{x}+\sum_{i=1}^N \log \left\{\pi\left(y_{i} \mid \boldsymbol{x}, \boldsymbol{\theta}_2\right)\right\}\right]
単純なラプラス近似
ラプラス近似は正規近似を利用した積分の近似計算方法です.
例えばLGMにおいて$x_i$の周辺事後分布の近似を求める場合,同時事後分布からの積分
\pi(x_i|\boldsymbol{y})=\int\pi(\boldsymbol{x},\boldsymbol{\theta}|\boldsymbol{y})d\boldsymbol{x}_{-i} d\boldsymbol{\theta}
に対してラプラス近似を適用するのが愚直なラプラス近似の適用方法です.
この場合,同時事後分布が正規分布にある程度近ければそれなりに精度の良い近似が得られるのですが,$\boldsymbol{\theta}$のような分散やdispersionに関連するパラメータの事後分布は正規分布とはかなり異なった形状を示すことが多く,上記の方法に対して精度の高い近似はほとんど期待できないでしょう.
段階的な近似
INLAのベースとなっているアイデア自体は非常にシンプルです.
- $(\boldsymbol{x},\boldsymbol{\theta})$の同時事後分布ではなく$\boldsymbol{\theta}$所与での$\boldsymbol{x}$の条件付き事後分布を正規近似すれば良い.
- $\boldsymbol{\theta}$の周辺事後分布に関しては$\boldsymbol{\theta}$の低次元性を利用してグリッドによる近似を採用すれば良い.
1番目のアイデアについてはLGMモデルを考えていること,すなわち$x$の事前分布が正規分布であるという事実が根底にあります.ラフに言うと**「事前分布が正規分布だから事後分布も正規分布に近い形になるよね」**という考えです.
具体的なINLAの方法
INLAの目標は各パラメータや潜在変数の周辺事後分布 $\pi(x_i | \boldsymbol{y})\ (i=1,\ldots,n)$,$\pi(\theta_j | \boldsymbol{y})\ (j=1,\ldots,m)$ の近似を得ることです.
そのために以下のような積分から出発します.
\pi(x_i | \boldsymbol{y}) = \int \pi(x_i | \boldsymbol{\theta}, \boldsymbol{y}) \pi(\boldsymbol{\theta} | \boldsymbol{y})d\boldsymbol{\theta}\\
\pi(\theta_j | \boldsymbol{y}) = \int \pi(\boldsymbol{\theta} | \boldsymbol{y}) d \theta_{-j}
INLAは上記の積分に登場する $\pi(\boldsymbol{\theta}|\boldsymbol{y})$ と $\pi(\boldsymbol{x}|\boldsymbol{\theta}, \boldsymbol{y})$を高速かつ高精度に近似することが基本的なアイデアです.
潜在変数の条件付き事後分布の正規近似
条件付き事後分布$\pi(\boldsymbol{x}|\boldsymbol{\theta}, \boldsymbol{y})$は以下のように書けます.
\pi(\boldsymbol{x}|\boldsymbol{\theta}, \boldsymbol{y})\propto
\exp\left\{-\frac12\boldsymbol{x}^{\top}\boldsymbol{Q}(\boldsymbol{\theta_1})\boldsymbol{x}+ \sum_{i=1}^N \log \pi(y_i|\boldsymbol{x},\boldsymbol{\theta_2})\right\}
指数関数内の第一項目は$\boldsymbol{x}\sim N(\boldsymbol{0},\boldsymbol{Q}(\boldsymbol{\theta_1}))$に由来する部分です.部分的に正規分布の項が現れているので,全体もうまく正規近似できそうです.
具体的には,モード$\boldsymbol{x}^\ast(\boldsymbol{\theta})$とヘッセ行列$H(\boldsymbol{\theta})$を用いて
\pi(\boldsymbol{x}|\boldsymbol{\theta}, \boldsymbol{y})
\approx
\tilde{\pi}_G(\boldsymbol{x}|\boldsymbol{\theta}, \boldsymbol{y})
\propto \exp\left\{-\frac12(\boldsymbol{x}-\boldsymbol{x}^\ast(\boldsymbol{\theta}))^{\top}\boldsymbol{H}(\boldsymbol{\theta})(\boldsymbol{x}-\boldsymbol{x}^\ast(\boldsymbol{\theta}))\right\}
と近似することができます.
ハイパーパラメータの周辺事後分布の近似
次に$\pi(\boldsymbol{\theta}|\boldsymbol{y})$の近似を考えます.
同時分布の分解$\pi(\boldsymbol{x},\boldsymbol{\theta},\boldsymbol{y})=\pi(\boldsymbol{x}|\boldsymbol{\theta},\boldsymbol{y})\pi(\boldsymbol{\theta}|\boldsymbol{y})$において$\pi(\boldsymbol{x}|\boldsymbol{\theta},\boldsymbol{y})$の近似を適用すると,
\pi(\boldsymbol{\theta} | \boldsymbol{y})
\approx
\tilde{\pi}(\boldsymbol{\theta} | \boldsymbol{y})
\propto
\frac{\pi(\boldsymbol{x}, \boldsymbol{\theta}, \boldsymbol{y})}{\tilde{\pi}_{G}(\boldsymbol{x}|\boldsymbol{\theta}, \boldsymbol{y})}\Bigg|_{\boldsymbol{x} = \boldsymbol{x}^{\ast}(\boldsymbol{\theta})}
といった近似が得られます.
この表現から$\boldsymbol{\theta}$を入力すると正規化されていない周辺事後密度の近似値が計算できることがわかります.これを用いて周辺事後分布をグリッドで近似していきます.
論文中では以下のような方法が提案されています.
-
$\log \tilde{\pi}(\boldsymbol{\theta} | \boldsymbol{y})$を最大化させる$\boldsymbol{\theta}^\ast$を計算します.
-
$\log\tilde{\pi}(\boldsymbol{\theta} | \boldsymbol{y})$ のヘッセ行列 $\boldsymbol{H}$を計算し,$\boldsymbol{H}^{-1} = \boldsymbol{V} \boldsymbol{\Lambda} \boldsymbol{V}^T$ の固有値分解を用いて$\boldsymbol{\theta}(\boldsymbol{z}) = \boldsymbol{\theta}^\ast + \boldsymbol{V}\boldsymbol{\Lambda}^{\frac{1}{2}}\boldsymbol{z}$とreparametarizetionを行います.
-
$\boldsymbol{\theta}^\ast$を中心に事後密度がある程度小さくなる範囲まで探索してグリッドを集めていきます.具体的には,$\boldsymbol{z}=\boldsymbol{0}$を出発地点として$z_1$($\boldsymbol{z}$の第一要素)の正の方向にステップサイズ$\delta_z$ (例えば$\delta_z=1$)で点列を作っていき,
\log \tilde{\pi}(\boldsymbol{\theta}^\ast) - \log \tilde{\pi}(\boldsymbol{\theta}(\boldsymbol{z})) < \delta_\pi
となる点を全てを採用するといった方法です.
$\delta_\pi$はモードにおける密度がどれくらい下がるまで点を採用するかを決める量で,論文中では$\delta_\pi=2.5$といった値が提示されています.
この方法を$z_1$の負の方向や$z_2,\ldots,z_m$の軸に対しても同様の操作を行うことで,$m$本の軸上に点列を生成することができます.あとは$(z_1,\ldots,z_m)$の全ての組み合わせの中で上記の「モードに対する密度の基準」を満たす点を集めてグリッドを生成することができます.
以下は論文中の図を抜粋したもので,こちらの方が上記の方法のイメージが掴みやすいかもしれません.
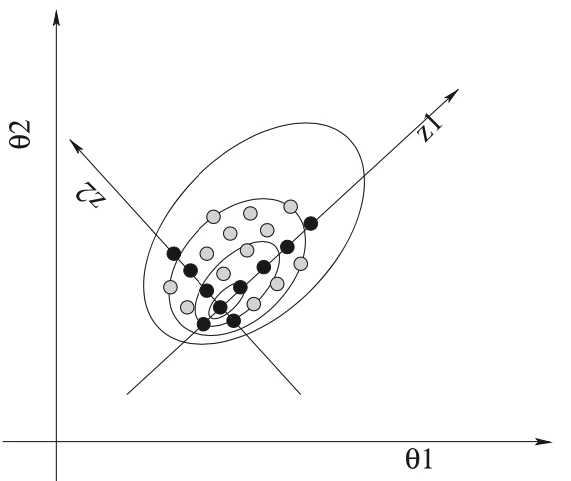
上図の黒い点がステップ1〜3で採用される軸上の点列で灰色の点が組み合わせによって生成される点です.
これで$\pi(\boldsymbol{\theta} | \boldsymbol{y})$を近似するグリッドが生成できました.各要素の事後分布$\pi(\theta_j | \boldsymbol{y})$の近似は$\tilde{\pi}(\boldsymbol{\theta} | \boldsymbol{y})$を数値積分することで得られます.
このようなグリッドによる近似や数値積分は$\boldsymbol{\theta}$の次元$m$がある程度小さくないと破綻してしまいます.INLAはこのようなグリッド近似を内部で行なっているため,$m$がある程度小さいという条件が課されています.
潜在変数の周辺事後分布の近似
$\pi(x_i | \boldsymbol{y})$は以下の積分で与えられていたことを思い出しましょう.
\pi(x_i | \boldsymbol{y}) = \int \pi(x_i | \boldsymbol{\theta}, \boldsymbol{y}) \pi(\boldsymbol{\theta} | \boldsymbol{y})d\boldsymbol{\theta}
すでに$\pi(\boldsymbol{\theta} | \boldsymbol{y})$の近似は得られていますので,$\pi(x_i | \boldsymbol{\theta}, \boldsymbol{y})$の何らかの近似$\tilde{\pi}(x_i | \boldsymbol{\theta}, \boldsymbol{y})$を得ることで,$\pi(x_i | \boldsymbol{y})$の近似を以下のように求めることができます.
\tilde{\pi}(x_i | \boldsymbol{y}) = \sum_k \tilde{\pi}(x_i | \boldsymbol{\theta}^{(k)}, \boldsymbol{y}) \tilde{\pi}(\boldsymbol{\theta}^{(k)} | \boldsymbol{y}) \Delta_k
ここで,$\Delta_k$は各グリッドごとの重みを表します.前述のアルゴリズムのように$\boldsymbol{\theta}$ の空間を格子点で近似している場合はこの重みを考える必要はありません.
$\pi(x_i | \boldsymbol{\theta}, \boldsymbol{y})$については,既に得られている$\pi(\boldsymbol{x} | \boldsymbol{\theta}, \boldsymbol{y})$の正規近似を積分する方法でも良いですが,論文中ではsimplified Laplace approximationといった方法を適用することが推奨されています.
まずは$\pi(x_i | \boldsymbol{\theta}, \boldsymbol{y})$に対する単純なラプラス近似を考えます.
\tilde{\pi}_{LA}(x_i | \boldsymbol{\theta}, \boldsymbol{y}) \propto \frac{\pi(\boldsymbol{x}, \boldsymbol{\theta}, \boldsymbol{y})}{\tilde{\pi}_{GG}(\boldsymbol{x}_{-i} | x_i, \boldsymbol{\theta}, \boldsymbol{y})}
\Bigg|_{\boldsymbol{x}_{-i} = \boldsymbol{x}_{-i}^\ast (x_i, \boldsymbol{\theta})}
$\boldsymbol{x_{-i}}^{\ast }(x_i, \boldsymbol{\theta})$ は $\boldsymbol{x_{-i}}$ についての $\pi(\boldsymbol{x}, \boldsymbol{\theta}, \boldsymbol{y})$ のモードで,分母の $\tilde{\pi}_{GG}$は正規近似を意味します.
このラプラス近似は各$i$ について$\tilde{\pi}_{GG}$ を計算しなければならず$n$が大きいときは計算が大変です.
simplified Laplace approximationはこの点をもう少し工夫します.
まずはモードを
\boldsymbol{x_{-i}}^{\ast }(x_i, \boldsymbol{\theta}) \approx E_{\tilde{\pi}_G}(\boldsymbol{x}_{-i} | x_i)
で近似します.右辺は$\tilde{\pi}_G$による期待値なので簡単に計算することができます.
次に正規近似$\tilde{\pi}_G(\boldsymbol{x} | \boldsymbol{\theta}, \boldsymbol{y})$を周辺化して$\pi(x_i | \boldsymbol{\theta}, \boldsymbol{y})$の正規近似
\tilde{\pi}(x_i | \boldsymbol{\theta}, \boldsymbol{y}) = \phi(x_i; \mu_i(\boldsymbol{\theta}), \sigma_i(\boldsymbol{\theta}))
を得ます.これらのパラメータを用いて、 $x_i^{(s)} = \sigma_i(\boldsymbol{\theta})^{-1}(x_i - \mu_i(\boldsymbol{\theta}))$ を定義します.
ここで$\log{\tilde{\pi}_{LA}(x_i^{(s)} | \boldsymbol{\theta}, \boldsymbol{y})}$ を分子分母でそれぞれ展開し,以下のような形の近似を得ることができます.
\text{(constant)} - \frac{1}{2}(x_i^{(s)})^2 + \gamma_i^{(1)}(\boldsymbol{\theta})x_i^{(s)} + \frac{1}{6}(x_i^{(s)})^3\gamma_i^{(3)}(\boldsymbol{\theta})x_i^{(s)} + \cdots
ここで,$\gamma_i^{(1)}$や$\gamma_i^{(3)}$は$\log \pi(y_i|\boldsymbol{x},\boldsymbol{\theta})$の3階微分や$\mu_i(\boldsymbol{\theta})$,$\sigma_i(\theta)$に依存する量で陽に計算することができます.(詳細な数式については論文を参照してください.)
この展開で得た${x_i^{(s)}}$についての3次の項までを上手く利用することで,単なる正規近似より精度の高い近似を得ることができます.具体的には、上記の展開式を近似するような歪正規(skew normal)分布の平均,分散,歪度のパラメータを求め,得られた歪正規分布を$\pi(x_i | \boldsymbol{\theta}, \boldsymbol{y})$の近似として用いる方法が提案されています.
手順のまとめ
INLAは以下のステップで構成されていることがわかります.
- $\pi(\boldsymbol{x}|\boldsymbol{\theta}, \boldsymbol{y})$の正規近似
- $\pi(\boldsymbol{\theta}|\boldsymbol{y})$のグリッドによる離散近似
- $\pi(x_i | \boldsymbol{\theta}, \boldsymbol{y})$のsimplified Laplace approximation
- 数値積分による$\pi(x_i|\boldsymbol{y})$の近似
さいごに
近似的なベイズ推測を行う方法は他にもあります.論文中では変分ベイズ法やexpectation propagationに対するINLAの利点についても議論されていますので,気になる方はご参照ください.
また,著者たちはRのINLAパッケージを開発しており,様々なモデルに対するINLAによるベイズ推測を簡単に利用することができます.このパッケージを用いたRのデモについても今後の記事で紹介していこうと思います.
株式会社Nospareでは統計学の様々な分野を専門とする研究者が所属しております.統計アドバイザリーやビジネスデータの分析につきましては株式会社Nospareまでお問い合わせください.
