初めに
この記事では、7人の従業員の10日分のシフトを作成します。
行列の要素には4時間の勤務と8時間の勤務、0時間勤務(休日)のバリエーションがあります。
この記事を読むと最終的に次のような勤務表を作れるようになります。
| 月 | 火 | 水 | 木 | 金 | 土 | 日 | 月 | 火 | 水 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 8 | 8 | 8 | 4 | 0 | 8 | 8 | 8 | 4 |
| 1 | 4 | 8 | 4 | 4 | 4 | 8 | 0 | 8 | 4 | 4 |
| 2 | 0 | 8 | 4 | 0 | 0 | 4 | 8 | 4 | 4 | 8 |
| 3 | 4 | 0 | 8 | 0 | 0 | 4 | 4 | 8 | 4 | 8 |
| 4 | 8 | 0 | 4 | 4 | 4 | 0 | 0 | 8 | 4 | 8 |
| 5 | 4 | 4 | 4 | 0 | 4 | 8 | 0 | 8 | 8 | 8 |
| 6 | 0 | 8 | 4 | 8 | 4 | 8 | 0 | 4 | 4 | 0 |
では、まずアルゴリズムの説明からします。
タブーサーチのアルゴリズム
① 初期解の作成
② 近傍解の作成
③ 制約条件を満たすようにペナルティーを使って最適化
簡単に説明するとこれだけです。制約条件を満たすように [0, 4, 8]の配列の中からランダムに抽出して配列を埋めていくイメージです。
初期解の作成
self.ns = np.zeros((person_num, days_num))
self.ns2 = np.zeros((person_num, days_num))
self.ns3 = np.zeros((person_num, days_num))
全部0要素をもつ(社員の数×算出する日数)の行列を作っています。
index_num = self.choice_index()
index_num2 = self.choice_index()
index_num3 = self.choice_index()
近傍解を3つ作るために変更するインデックスをそれぞれ3つ選択しています。
制約条件
if not(sum(self.ns[i]) < 64 and sum(self.ns[i]) >= 40):
penalty = penalty + 1
if not(sum(self.ns2[i]) < 64 and sum(self.ns2[i]) >= 40):
penalty2 = penalty2 + 1
if not(sum(self.ns3[i]) < 64 and sum(self.ns3[i]) >= 40):
penalty3 = penalty3 + 1
3つの近傍解の1週間の勤務時間が40時間から64時間以内という制約条件を定義しています。
制約条件を満たさなければペナルティーを一つ増やすということをしています。
タブーサーチのこころ
悪い解に陥った遷移を記録した「タブーリスト」を使って、1度探索したところ以外を調べるということを行います。
それによって収束が早くなり近似解が求められます。
全体のコード
%load_ext Cython
import numpy as np
import itertools
import matplotlib.pyplot as plt
import pandas as pd
class TabuSearch():
tabu_list = []
penalty_arr = []
def __init__(self, person_num = 7, days_num = 10, select_num = 3):
self.person_num = person_num
self.penalty_old = 7 * 2 + 10
self.days_num = 10
self.select_num = select_num
self.jikkou_num = 1
# 近似解の初期化
self.s_good = np.zeros((person_num, days_num))
self.index_list = list(itertools.product(range(0, person_num), range(0, days_num), repeat=1))
self.ns = np.zeros((person_num, days_num))
self.ns2 = np.zeros((person_num, days_num))
self.ns3 = np.zeros((person_num, days_num))
def choice_index(self):
return np.random.choice(list(range(0, self.person_num*self.days_num)), self.select_num, replace=False)
def generate_near(self):
# 近傍解の作成
# 近傍解を局所変換するので、要素を3つ選択する。(3というのは適当)
# 入れ替えるインデックス
index_num = self.choice_index()
index_num2 = self.choice_index()
index_num3 = self.choice_index()
penalty = 0
penalty2 = 0
penalty3 = 0
ns = np.zeros((self.person_num, self.days_num))
ns2 = np.zeros((self.person_num, self.days_num))
ns3 = np.zeros((self.person_num, self.days_num))
chg_flag = True
# 変更する値
new_var = [np.random.choice([8,4,0]) for i in range(0, self.select_num)]
for j in range(0, len(self.tabu_list)):
# tabu_listのうち先頭から7個までの値を見る
if j == 7:
break
for k in range(0, self.select_num):
if index_num[k] == TabuSearch.tabu_list[j][k]:
chg_flag = False
if index_num2[k] == TabuSearch.tabu_list[j][k]:
chg_flag = False
if index_num3[k] == TabuSearch.tabu_list[j][k]:
chg_flag = False
# タブーリストに値があったら値を更新しない
if chg_flag == True:
for i in range(0, len(index_num)):
self.ns[self.index_list[index_num[i]][0], self.index_list[index_num[i]][1]] = new_var[i]
self.ns2[self.index_list[index_num2[i]][0], self.index_list[index_num2[i]][1]] = new_var[i]
self.ns3[self.index_list[index_num3[i]][0], self.index_list[index_num3[i]][1]] = new_var[i]
for i in range(0, len(self.ns)):
if not(sum(self.ns[i]) < 64 and sum(self.ns[i]) >= 40):
penalty = penalty + 1
if not(sum(self.ns2[i]) < 64 and sum(self.ns2[i]) >= 40):
penalty2 = penalty2 + 1
if not(sum(self.ns3[i]) < 64 and sum(self.ns3[i]) >= 40):
penalty3 = penalty3 + 1
if penalty < self.penalty_old and penalty <= penalty2 and penalty <= penalty3:
self.s_good = self.ns
# タブーリストに値がなかったときだけpenalty_arrに値を追加する
TabuSearch.penalty_arr.append(penalty)
for j in range(0, len(self.ns)):
print(f"{j+1}行目の合計値", str(sum(self.ns[j])))
self.jikkou_num = self.jikkou_num + 1
return penalty
elif penalty2 < self.penalty_old and penalty2 <= penalty3:
self.s_good = self.ns2
TabuSearch.penalty_arr.append(penalty2)
for j in range(0, len(self.ns)):
print(f"{j+1}行目の合計値", str(sum(self.ns2[j])))
self.jikkou_num = self.jikkou_num + 1
return penalty2
elif penalty3 < self.penalty_old:
self.s_good = self.ns3
TabuSearch.penalty_arr.append(penalty3)
for j in range(0, len(self.ns)):
print(f"{j+1}行目の合計値", str(sum(self.ns3[j])))
self.jikkou_num = self.jikkou_num + 1
return penalty3
else:
# 悪いのを記録して良い方向は最適化されるようにする
TabuSearch.tabu_list.insert(0, index_num)
TabuSearch.tabu_list.insert(0, index_num2)
TabuSearch.tabu_list.insert(0, index_num3)
return self.penalty_old
else:
self.jikkou_num = self.jikkou_num + 1
TabuSearch.penalty_arr.append(self.penalty_old)
return self.penalty_old
def execution(self, times=1000000):
# 各行の合計が特定の範囲内にであれば終了するためのコード
for i in range(0, times):
penalty = self.generate_near()
if penalty < self.penalty_old:
print(f"{self.jikkou_num}回目の実行")
print("ペナルティー値", penalty)
print("全体のペナルティーの値", self.penalty_old)
self.penalty_old = penalty
if penalty == 0:
df = pd.DataFrame(self.s_good, columns=("月" , "火", "水", "木", "金", "土", "日", "月", "火", "水"))
print(df.to_markdown())
break
def plot_loss(self):
plt.plot(TabuSearch.penalty_arr)
def output_markdown(self):
df = pd.DataFrame(self.s_good, columns=("月" , "火", "水", "木", "金", "土", "日", "月", "火", "水"))
print(df.to_markdown())
実行
ts = TabuSearch()
ts.execution(100000)
出力の一部
1行目の合計値 56.0
2行目の合計値 48.0
3行目の合計値 40.0
4行目の合計値 40.0
5行目の合計値 40.0
6行目の合計値 48.0
7行目の合計値 40.0
232回目の実行
ペナルティー値 0
全体のペナルティーの値 1
| | 月 | 火 | 水 | 木 | 金 | 土 | 日 | 月 | 火 | 水 |
|---:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|
| 0 | 0 | 8 | 8 | 8 | 4 | 0 | 8 | 8 | 8 | 4 |
| 1 | 4 | 8 | 4 | 4 | 4 | 8 | 0 | 8 | 4 | 4 |
| 2 | 0 | 8 | 4 | 0 | 0 | 4 | 8 | 4 | 4 | 8 |
| 3 | 4 | 0 | 8 | 0 | 0 | 4 | 4 | 8 | 4 | 8 |
| 4 | 8 | 0 | 4 | 4 | 4 | 0 | 0 | 8 | 4 | 8 |
| 5 | 4 | 4 | 4 | 0 | 4 | 8 | 0 | 8 | 8 | 8 |
| 6 | 0 | 8 | 4 | 8 | 4 | 8 | 0 | 4 | 4 | 0 |
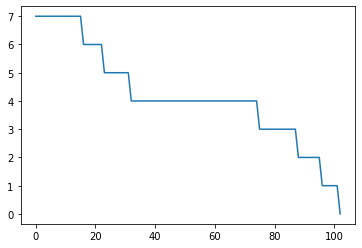
ペナルティーの値の推移を描画する
ts.plot_loss()
勤務表をマークダウンで表示する
ts.output_markdown()
| | 月 | 火 | 水 | 木 | 金 | 土 | 日 | 月 | 火 | 水 |
|---:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|-----:|
| 0 | 0 | 8 | 8 | 8 | 4 | 0 | 8 | 8 | 8 | 4 |
| 1 | 4 | 8 | 4 | 4 | 4 | 8 | 0 | 8 | 4 | 4 |
| 2 | 0 | 8 | 4 | 0 | 0 | 4 | 8 | 4 | 4 | 8 |
| 3 | 4 | 0 | 8 | 0 | 0 | 4 | 4 | 8 | 4 | 8 |
| 4 | 8 | 0 | 4 | 4 | 4 | 0 | 0 | 8 | 4 | 8 |
| 5 | 4 | 4 | 4 | 0 | 4 | 8 | 0 | 8 | 8 | 8 |
| 6 | 0 | 8 | 4 | 8 | 4 | 8 | 0 | 4 | 4 | 0 |
参考書

WhisponMLCafe.はAI受託開発しております。気軽にご相談ください。