転移学習
はじめに
本記事では参考論文を元にして.転移学習の数理を断片的に紹介するものです.
詳しくは元の論文を参考にしてください.
あくまでも転移学習の雰囲気を味わう物だということで過度な期待はしないでください.
数式が分からなければ絵だと思ってお酒を片手に眺めるだけでも良いでしょう.
ではさっそく,用語の説明から.
ドメインには二種類あり.転移する知識を送る側をソースドメイン(source domain),受け取る側をターゲットドメイン(target domain)と呼びます.
定式化
$\mathcal { D } = \{ \mathcal { X } , P ( X ) \}$であり,$\mathcal{X}$は特徴空間です.
$P ( X ) $は周辺確率分布であり,$X = \{ x _ { 1 } , \dots , x _ { n } \} \in \mathcal { X }$を満たします.
教師あり手法の定式化
以下のような最適化問題を解きます.
$argmin _ { A , U } \sum _ { t \in { T , S } } \sum _ { i = 1 } ^ { n _ { t } } L \left( y _ { t _ { i } } , \left\langle a _ { t } , U ^ { T } x _ { t _ { i } } \right\rangle \right) + \gamma | A | _ { 2,1 } ^ { 2 }$
$\text { s.t. } \quad U \in \mathbf { O } ^ { d }$
Sはソースドメイン,Tはターゲットドメインです.$U$は元の高次元データを低次元表現にマッピングするための直交行列(マッピング関数)です.
第二項は正則化項です.
教師なし手法の定式化
次はスパースコーディングを用いた手法です.
このアルゴリズムは2ステップからなっています.
$\min _ { a , b } \sum _ { i } \left| x _ { S _ { i } } - \sum _ { j } a _ { S _ { i } } ^ { j } b _ { j } \right| _ { 2 } ^ { 2 } + \beta \left| a _ { S _ { i } } \right| _ { 1 }$
$\text { s.t. } \quad \left| b _ { j } \right| _ { 2 } \leq 1 , \forall j \in 1 , \ldots , s$
この最適化問題を解くことによって,基底ベクトル$b_j$がソースドメインから学習されます.
次に以下の目的か関数を最小化して終了です.
$a _ { T _ { i } } ^ { * } = \arg \min _ { a _ { T _ { i } } } \min \left| x _ { T _ { i } } - \sum _ { j } a _ { T _ { i } } ^ { j } b _ { j } \right| _ { 2 } ^ { 2 } + \beta \left| a _ { T _ { i } } \right| _ { 1 }$
転移学習の仮定
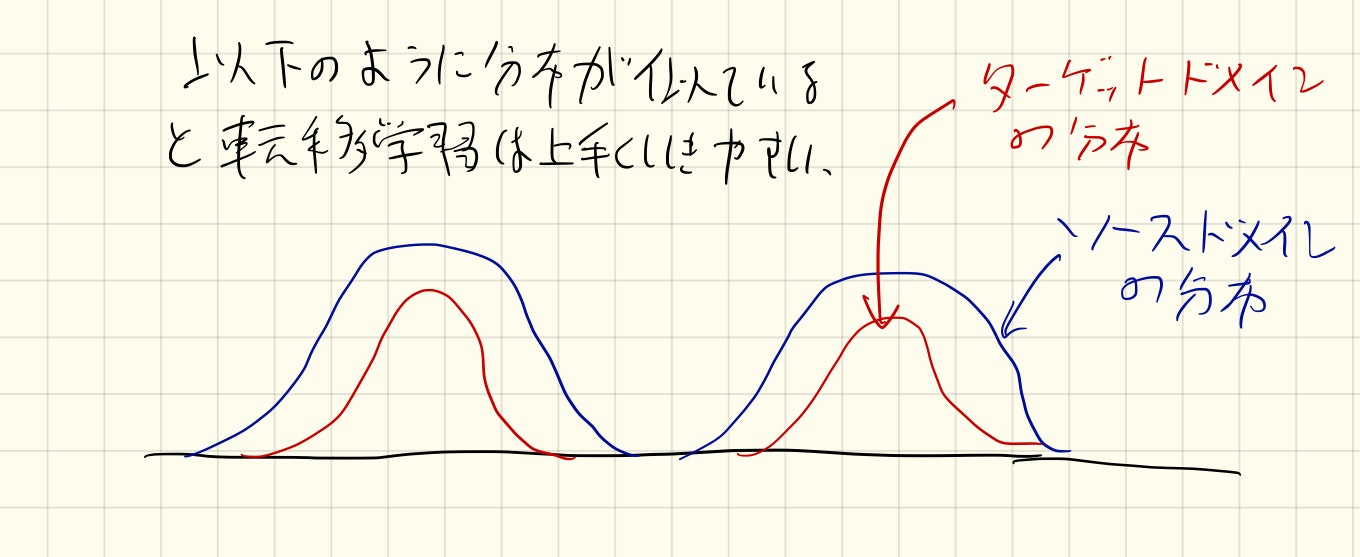
ここからは私のトンデモですが.以下のように捉えてもいいかもしれません.

[追記:2019/06/27]
実際にDiscrepancyMaxmization(DM)アルゴリズムというものが存在します.
ソースドメインの分布Aとターゲットドメインの分布BのDiscrepacyを最小化(最大化)するアルゴリズムです.
参考
A Survey on Transfer Learning
Sinno Jialin Pan and Qiang Yang Fellow, IEEE
転移学習:神嶌
転移学習のサーベイ:神嶌