はじめに
はじめまして、千々松のいるです。
Python。人気ですよね。
統計学や機械学習の人気が上昇すればするほど人気になっている感じがします。私もこれから機械学習を勉強していこうかなという人間なので、今回は私と同じようにこれからPythonを学んでいく人向けに基礎文法についてまとめてみました。
馴染みやすさを重視しているので厳密な解説は公式ドキュメント等で確認いただけたらと思います。
対象読者
- これからPythonを学ぼうとしている方
- 学生の方
目次
概観
まず1章では、プログラミングの要となるデータの型について見ていきます。コンテナと呼ばれるlistのような型から徐々に複雑になっていきますが、できるだけ体系立てて学んでいけたらと思います。
2章では、プログラミングの流れとなる制御フローについて見ていきます。制御フローに関しては、ピアノの楽譜によく似ていると思います。ピアノでもトゥ・コーダでコーダの位置までジャンプしたり、ダル・セーニョでセーニョの位置まで戻ったりしますよね。これをプログラミングではgotoやreturnで表現します。なにも難しいことじゃなくて、楽譜やソースコードの中で分岐や繰り返しがよく行われるというだけの話だと思います。
3章では、関数について見ていきます。
関数はよく利用する処理をまとめて再利用可能にするために使われます。引数の使い方などを確認していきます。
4章では、クラスについて見ていきます。関数と同じくコードの再利用という意味合いが強いですね。
ここでは実際にポケモンのクラスからポケモンを生成して、クラスを利用する意義と、あと継承について学んでいきたいと思います。
環境
Python 3.7.0
1. データ型
さて、プログラミングといえばまずはデータですよね。データは料理で言えば食材みたいなもので、データがないとプログラミングははじまりません。
プログラミング言語で扱うデータには型というものが存在しています。
型っていうのを簡単に言うと分類だと思います。
料理でも、和食・洋食・中華があるようにプログラミングのデータにもいろいろな型があります。
和食だったら白だし、洋食だったらコンソメ、中華だったら鶏がらというように、データも型によって使える関数が違ってきたりするので、型とその型がどういう処理に対応しているかを学ぶことは重要ですね。
ちなみに、PythonはJavaやGoなんかの静的型付け言語とは違って動的型付け言語なので、型を指定する必要はないんですよね。
でも、Pythonにもデータ型は存在するので以下の表を使って説明していきます。
※型付けに関しては、ここでは深く触れません。
表1. Pythonのデータ型
| 項番 | 大分類 | 小分類 | 具体例 |
|---|---|---|---|
| 1-1 | 真理値型 | bool型 | True, False |
| 1-2 | 文字列型 | str型 | 'あいう', 'abc' |
| 1-3 | 数値型 | int型 | 1, 0, -3 |
| 1-4 | 数値型 | float型 | 3.14, 0.3, -2.7 |
| 1-5 | 数値型 | complex型 | 2j, 3+5j |
| 1-6 | 配列型 | list型 | ['a','あ', 2.5] |
| 1-7 | 配列型 | tuple型 | (-3j, True) |
| 1-8 | 辞書型 | dict型 | {'key': 'value'} |
| 1-9 | 集合型 | set型 | {'a', -3.14} |
1-1. bool型
真理値として用いる組み込み定数は2つしかないです。TrueとFalseだけですね。ランプのON/OFFみたいなイメージなのかなと思ってます。
真理値? 何それ?? って感じだと思うんですけど
数学用語で言うと、真と偽ってやつですね。論理と集合の単元で出てきたやつです。
全てのオブジェクトは組み込み関数bool()によって、TrueかFalseに分類されます。零や空のオブジェクトはFalseを返して、それ以外はTrueを返しますね。
>>> bool(2)
True
>>> bool(0)
False
>>> bool('')
False
真理値に対して適用される演算子は論理演算子(ブール演算子)と呼ばれていて、and, or, notの3種類が存在します。and, orに関してはビット演算子を用いても同じ結果になりますね。
>>> t = True
>>> f = False
>>>
>>> t and f
False
>>> t or f
True
>>> not t
False
>>> t & f # andと同じ
False
>>> t | f # orと同じ
True
1-2. str型
''や""みたいなアポストロフィかクォーテーションでデータを囲んで扱う文字列型です。逆に言えば、引用符で囲まれたデータは真理値や数値だって全部str型になるということです。
ちなみに、データが何の型かは組み込み関数**type()**で判別できます。
>>> s1 = '文字列'
>>> s2 = 'True'
>>> s3 = '3'
>>>
>>> type(s1)
<class 'str'>
>>> type(s2)
<class 'str'>
>>> type(s3)
<class 'str'>
演算子としては、算術演算子の+と*が使えます。あと、str型はイテラブル(繰り返し可能)なオブジェクトなので、for文みたいなループ処理も使えます。
私はstr型にfor文が使えるの、最初は意外でした。
皆さんはそうでもなかったですか?
>>> s1 = 'フシギダネ'
>>> s2 = 'つるのムチ'
>>>
>>> s1 + s2
'フシギダネつるのムチ'
>>> s2 * 3
'つるのムチつるのムチつるのムチ'
>>>
>>> for s in s1:
... print(s)
...
フ
シ
ギ
ダ
ネ
1-3. int型
数値型には整数を扱うint型、浮動小数点数を扱うfloat型、複素数を扱うcomplex型の3種類が存在します。
まずは整数を扱うint型から。
算術演算子としては、+, -, *, /, %, //, **の7演算子全てが使えます。四則演算では、除算以外がint型に閉じていると言えますね。
>>> 3 + 4
7
>>> 3 - 4
-1
>>> 3 * 4
12
>>> 3 / 4 # float型になる
0.75
>>> 3 % 4 # 剰余
3
>>> 3 // 4 # 切り捨て除算
0
>>> 3 ** 4 # べき乗
81
1-4. float型
浮動小数点数を扱う数値型ですね。int型と同じく全ての算術演算子をサポートしていて、float型の四則演算はfloat型に閉じます(強制的にfloat型で表記されます)。
あと、無限大(infinity)やNaN(Not a Number)もfloat型として扱われるから注意です。
そして、無限大やNaNを含む数値同士の演算結果は無限大やNaNをそのまま返します。
>>> 0.25 + 4
4.25
>>> 0.25 - 4
-3.75
>>> 0.25 * 4 # float型は維持される
1.0
>>> 0.25 / 4
0.0625
>>> 0.25 % 4
0.25
>>> 0.25 // 4
0.0
>>> 0.25 ** 4
0.00390625
>>> infinity = float('inf')
>>> infinity * 100 # infを含む演算
inf
>>> nan = float('nan')
>>> nan - 3.14 # NaNを含む演算
nan
1-5. complex型
複素数を扱う数値型ですね。複素数平面すら理解していない私が説明するのもなんですが、とりあえず数値にjかJを付けると虚数として認識されます、それだけです。
ちなみに虚数については数学ではiを、工学ではjを用いるらしいですね。
実部は.real、虚部は.imagを付けることでfloat型として取得することも可能です。
>>> c = 2 + 3j
>>> type(c)
<class 'complex'>
>>> c.real # float型として取得
2.0
>>> c.imag
3.0
>>> type(c.real)
<class 'float'>
1-6. list型
要素を1列に並べて各要素ごとに参照できるデータ構造をコンテナオブジェクトと言って、内部の要素が可変なものをlist型、不変なものをtuple型として扱っています。
各要素が異なるデータ型であっても問題はなくて、コンテナの中にコンテナの要素を格納することだって可能です。
コンテナの中にコンテナを入れたりするのを入れ子構造(ネスト)とか言ったりします。
各要素にアクセスする際には、list[番号]のように記述すれば大丈夫です。ちなみに、listの番号(インデックス)は1からじゃなくて、0からだから注意が必要です。
>>> li1 = ['切り干し大根', 7j, False]
>>> li2 = [1, ['利根川', '最上川'], True]
>>>
>>> li1[2]
False
>>> li2[1]
['利根川', '最上川']
list型もstr型みたいに+と*の算術演算子が使用可能です。
>>> li1 + li2
['切り干し大根', 7j, False, 1, ['利根川', '最上川'], True]
>>> li2 * 3
[1, ['利根川', '最上川'], True, 1, ['利根川', '最上川'], True, 1, ['利根川', '最上川'], True]
コンテナは格納するだけじゃなくて、要素を増やしたり、減らしたりする組み込みのメソッドも用意されています。
要素を増やすときは、list.append(要素)。減らしたいときは、list.pop(インデックス)を使います。
でも、popは厳密には要素を削除してるというよりは、非復元抽出をしているイメージですね。
なので、popで抽出してきた要素は別の変数にすることも可能です。
>>> li1 = ['フ', 'シ', 'ギ']
>>> li1.append('ソウ')
>>> li1
['フ', 'シ', 'ギ', 'ソウ']
>>> li1.pop(1)
'シ'
>>> li1
['フ', 'ギ', 'ソウ']
>>> li1 = ['フ', 'シ', 'ギ', 'ソウ']
>>>
>>> var = li1.pop(3)
>>> var # 要素が抽出されている
'ソウ'
最後にスライスについて説明します。スライスっていうのは言葉通り、list型の要素を部分的に抽出するものですね。
イメージでいうと、カステラを包丁で切っているような感じでしょうか。
list[始点:終点]のようにして要素を抽出します。
インデックスに負数を入力すると、末尾の要素から起算して要素を抽出することになります。
あと、スライスしても元の配列は維持されます。
>>> li = ['フシギダネ', 'フシギソウ', 'フシギバナ', 'ヒトカゲ', 'リザード', 'リザードン']
>>> li_slice = li[1:3]
>>> li_slice
['フシギソウ', 'フシギバナ']
>>> li_reverce = li[-3:-1]
>>> li_reverce
['ヒトカゲ', 'リザード']
>>> li_reverce = li[-3:]
>>> li_reverce
['ヒトカゲ', 'リザード', 'リザードン']
>>> li
['フシギダネ', 'フシギソウ', 'フシギバナ', 'ヒトカゲ', 'リザード', 'リザードン']
1-7. tuple型
tuple型は、list型の要素を不変にしたものです。
不変なので、要素を増やしたり引いたりすることはできません。でも、tupleをスライスして別のtupleを作成したりすることは可能です。
>>> tu = ('アチャモ', 'キモリ', 'ミズゴロウ')
>>> tu.append('エネコ') # 要素は変えられない
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'tuple' object has no attribute 'append'
>>> tu_slice = tu[1:3]
>>> tu_slice
('キモリ', 'ミズゴロウ')
>>> tu # 元のtupleに影響はない
('アチャモ', 'キモリ', 'ミズゴロウ')
1-8. dict型
ここまでの配列はなんとなく分かるかと思いますが辞書型がちょっととっつきにくいですよね。
dict型は{'key': 'value'}のように記述されて、keyとvalueの組み合わせを格納します。これまでのものは要素をインデックスで取得していましたが、dict型はkeyを指定して要素を取得する点で違いがあります。
あと、for文の使い方も少し工夫が必要です。
>>> dic_eva = {'序': 'YOU ARE (NOT) ALONE.', '破': 'YOU CAN (NOT) ADVANCE.', 'Q': 'YOU CAN (NOT) REDO.', 'シン': 'シ ン・エヴァンゲリオン劇場版'}
>>> dic_eva['序'] # keyでvalueを取得できる
'YOU ARE (NOT) ALONE.'
>>> dic_eva[0] # インデックスでは値を参照できない
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 0
>>> for key in dic_eva:
... print(key)
...
序
破
Q
シン
普通にfor文を回すとkeyの値が取得されます。valueの方を取得したい場合は以下のようにする必要があります。また、keyとvalueを両方を取得することも可能です。
>>> for value in dic_eva.values(): # valueを取得
... print(value)
...
YOU ARE (NOT) ALONE.
YOU CAN (NOT) ADVANCE.
YOU CAN (NOT) REDO.
シン・エヴァンゲリオン劇場版
>>> for key, value in dic_eva.items(): # keyとvalueを取得
... print(key, value)
...
序 YOU ARE (NOT) ALONE.
破 YOU CAN (NOT) ADVANCE.
Q YOU CAN (NOT) REDO.
シン シン・エヴァンゲリオン劇場版
1-9. set型
私はあんまり使ったことがありませんが集合を表すデータ型です。数学記号と同じく{要素1, 要素2, ... , 要素n}というように書きます。
listと同じように見えますが大きな違いは、setには順序性がないことです。
というのも、setでは要素の取得をすることができません。setでできるのは要素の追加と削除くらいになります。
>>> se = {'サンダー', 'ファイアー', 'フリーザー'}
>>> se.add('ホウオウ')
>>> se.add('ルギア')
>>> se
{'ルギア', 'ファイアー', 'サンダー', 'フリーザー', 'ホウオウ'} # 順序性がない
>>> se.remove('ホウオウ') # 要素を指定して削除
>>> se
{'ルギア', 'ファイアー', 'サンダー', 'フリーザー'}
>>> se.pop() # なにが削除されるかは不定
'ルギア'
>>> se
{'ファイアー', 'サンダー', 'フリーザー'}
>>> se.pop()
'ファイアー'
>>> se
{'サンダー', 'フリーザー'}
あと、不変の集合型でfrozenset型もあります。これはlistなりsetなりのコンテナに組み込み関数frozenset()を適用してあげると実装できます。
>>> li = [1,2,3]
>>> frozen_li = frozenset(li)
>>> type(frozen_li)
<class 'frozenset'>
コンテナオブジェクトの特性
また、コンテナにはそれぞれイテラブル、シーケンス、ミュータブルなどの特性が存在します。
まず、イテラブルというのは、日本語では反復可能体みたいに言われていて、簡単に言うとfor文のようなループ処理が可能なデータ型を指します。
解説したデータ型の中では、(str, list, tuple, dict, set, frozenset)がイテラブルにあたります。これらはfor文のinの先に指定できるということですね。
>>> st = 'オーダイル'
>>> for s in st:
... print(s)
...
オ
ー
ダ
イ
ル
>>> li = [1,2,3]
>>> for i in li:
... print(i)
...
1
2
3
>>> tu = ('a', 'b', 'c')
>>> for f in tu:
... print(f)
...
a
b
c
>>> dic = {1: 'フシギダネ', 2: 'フシギソウ', 3:'フシギバナ'}
>>> for key in dic:
... print(key)
...
1
2
3
>>> se = {1,2,3}
>>> for f in se:
... print(f)
...
1
2
3
>>> frozen_se = frozenset(se)
>>> for f in frozen_se:
... print(f)
...
1
2
3
次に、シーケンスですが、これは順序性のあるコンテナになります。簡単に言うと、[インデックス]のような形で要素を取得できるデータ型のことを言います。
具体的には、(str, list, tuple)などがシーケンスですね。
最初の頃はstr型がシーケンスな感じがしないですが、慣れてくるとだんだんコンテナっぽく見えてくるはずです。
>>> st[0] # str型
'オ'
>>> li[1] # list型
2
>>> tu[2] # tuple型
'c'
最後に、ミュータブルです。日本語で言うと変更可能体とか言うそうです。これは要素の変更、追加や削除ができるものを指します。逆にできないものはイミュータブルと言います。
ミュータブルなコンテナオブジェクトは、(list, dict, set)で、それ以外はイミュータブルなものになりますね。
>>> li # list型
[1, 2, 3]
>>> li[1] = 7
>>> li
[1, 7, 3]
>>> dic # dict型
{1: 'フシギダネ', 2: 'フシギソウ', 3: 'フシギバナ'}
>>> dic[1] = 'チコリータ'
>>> dic
{1: 'チコリータ', 2: 'フシギソウ', 3: 'フシギバナ'}
>>> se # set型
{1, 2, 3}
>>> se.add(4) # 要素の変更はできないですが、追加・削除が可能
>>> se
{1, 2, 3, 4}
また、これらの特性については、用語集やこちらのブログに詳しくまとまっていたので適宜ご参照ください。
2. 制御フロー
次はプログラムの流れについて見ていきましょう。
概観のところでも触れましたが、ソースコードは楽譜のように、順序や流れのある命令文となっています。
具体的には、条件分岐や繰り返し、例外処理などがそれにあたりますね。
制御フローの文は複合文と言って、文のブロックの中に節を含みます。表にすると下表のようになりますね。
表2. Pythonの制御フローにおける文・節
| 項番 | 分類 | 文 | 節 |
|---|---|---|---|
| 2-1 | 条件分岐 | if文 | elif節, else節 |
| 2-2 | 繰り返し | while文 | else節 |
| 2-3 | 繰り返し | for文 | else節 |
| 2-4 | 例外処理 | try文 | except節, else節, finally節 |
2-1. if文
まず初めに、ご存知if文ですね。これは条件分岐の時に使われる制御文です。
イメージは下図みたいな感じで、条件を満たした時、満たさなかった時で、違う経路を通ります。
条件によって違う経路を通って、最終的に合流するイメージですね。
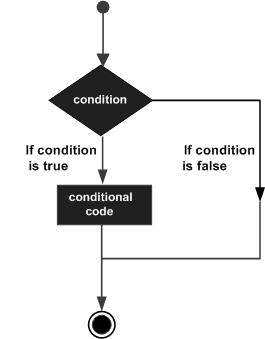
図2-1. if文のイメージ図
出典
簡単なif文の例はこんな感じです。
>>> your_age = 18
>>> if your_age < 20:
... print('お酒は禁止です')
... else:
... print('お酒OKです')
...
お酒は禁止です
your_ageが20未満だったのでif文中の命令が実行されましたね。ここで出てくるelse節というのは、それ以外という意味で、数学的には補集合のような立ち位置だと思います。if文以外の条件すべてといった感じですね。
注目して欲しいのは条件分岐なので、if文の命令文とelse節の命令文が同時には起こらないということです。
お酒は禁止な世界線とお酒OKな世界線しか選べないということですね。
最後にelif節を説明します。
これはifとelseの二元論では収まらない時に使用します。
>>> partner = input('ホウエン御三家で好きなポケモンは? :')
ホウエン御三家で好きなポケモンは? :アチャモ
>>> if partner == 'アチャモ':
... print('アチャモを てにいれました')
... elif partner == 'ミズゴロウ':
... print('ミズゴロウを てにいれました')
... else:
... print('キモリを てにいれました')
...
アチャモを てにいれました
こんな感じですね。
繰り返しになりますが、if文、elif節、else節は排他的なので同時には起こりえません。ちょうどアチャモとミズゴロウを同時にオダマキ博士からもらうのは無理なのと同じですね。
(ちなみに、私はアチャモをワカシャモにしたくなさすぎて四天王までアチャモのままで行ったことがあります ※主戦力はサーナイト)
2-2. while文
繰り返し処理ですね。
ピアノの反復記号と同じでひとかたまりの処理を繰り返します。
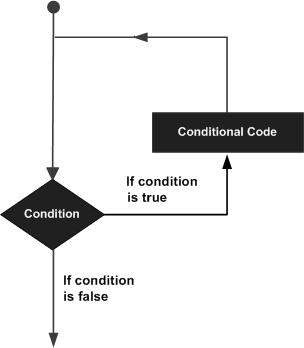
図2-2. while文のイメージ図
>>> age = 0
>>> while i < 20:
... print('お酒は禁止です')
... age += 1
...
お酒は禁止です
お酒は禁止です
お酒は禁止です
お酒は禁止です
お酒は禁止です
お酒は禁止です
お酒は禁止です
お酒は禁止です
お酒は禁止です
お酒は禁止です
お酒は禁止です
お酒は禁止です
お酒は禁止です
お酒は禁止です
お酒は禁止です
お酒は禁止です
お酒は禁止です
お酒は禁止です
お酒は禁止です
お酒は禁止です
ちなみに、繰り返し(ループ)をさせていると最後だけ別の処理をしたいことってありますよね。γ世界線に移動する時とか。
そういうときはelse節を使用します。if文での補集合的な考え方とは少し違いますが、ループを抜けるときに一度だけ実行することが可能です。
>>> i = 0
>>> while i < 20:
... print('失敗した')
... i += 1
... else:
... print('ようそこ、γ世界線へ')
...
失敗した
失敗した
失敗した
失敗した
失敗した
失敗した
失敗した
失敗した
失敗した
失敗した
失敗した
失敗した
失敗した
失敗した
失敗した
失敗した
失敗した
失敗した
失敗した
失敗した
ようそこ、γ世界線へ
あと、途中でループを抜けたい時ってありますよね。ちょうど死に戻りしてばっかりでもう嫌になった時とか?
そういう時にはbreak文を使います。break文は単純文と言ってその後に節をとらずにそれだけで完結します。
break文はif文中で使われて、一度実行されると強制的にループから抜けることができます。
>>> i = 0
>>> while i < 20:
... print('死に戻り')
... i += 1
... if i == 15:
... print('諦めます')
... break
... else:
... print('ハッピーエンド')
...
死に戻り
死に戻り
死に戻り
死に戻り
死に戻り
死に戻り
死に戻り
死に戻り
死に戻り
死に戻り
死に戻り
死に戻り
死に戻り
死に戻り
死に戻り
諦めます
諦めちゃいましたね。ハッピーエンドを見ることができませんでした。
諦めるのは嫌ですよね。そういう時はループ中にある条件の時だけ処理をスキップさせて次のループに入るということもできます。そういう時に使うのがcontinue文ですね。これも単純文なのでcontinueという単語だけで完結します。
>>> i = 0
>>> while i < 25:
... i += 1
... if i == 18:
... print('諦めるのは簡単です')
... print('でも、あなたには、似合わない')
... continue
... print(i, '死に戻り')
... else:
... print('ハッピーエンド')
...
1 死に戻り
2 死に戻り
3 死に戻り
4 死に戻り
5 死に戻り
6 死に戻り
7 死に戻り
8 死に戻り
9 死に戻り
10 死に戻り
11 死に戻り
12 死に戻り
13 死に戻り
14 死に戻り
15 死に戻り
16 死に戻り
17 死に戻り
諦めるのは簡単です
でも、あなたには、似合わない
19 死に戻り
20 死に戻り
21 死に戻り
22 死に戻り
23 死に戻り
24 死に戻り
25 死に戻り
ハッピーエンド
こんな感じでcontinue文は以降の処理をスキップして次のループに入ります。
(18 死に戻りの処理を行わず次のループからはじめています)
2-3. for文
さて、ようやくお馴染みのfor文ですね。プログラミング黎明期の繰り返しと言えばwhile文だったんですが、while文って繰り返しの回数を指定して実行できないじゃないですか。
でも、現実的には繰り返しの回数を指定して繰り返し処理したい時って非常に多いです。
そこで生まれたのがfor文ですね。
while文でもiみたいに回数を数えるカウンターを置いて、ループを抜ける回数を設定していたと思います。
イメージでいうとfor文はwhile文 + カウンターといった感じですかね。
>>> for i in range(10):
... print('ねむたい')
...
ねむたい
ねむたい
ねむたい
ねむたい
ねむたい
ねむたい
ねむたい
ねむたい
ねむたい
ねむたい
for文でもwhile文と同じようにelse節でループを抜ける時の処理を記述することが可能です。
>>> for i in range(10):
... print('ねむたい')
... else:
... print('もうねよう')
...
ねむたい
ねむたい
ねむたい
ねむたい
ねむたい
ねむたい
ねむたい
ねむたい
ねむたい
ねむたい
もうねよう
内包表記
for文は回数付きのwhile文を簡略化するものでしたね。簡略化ということで、ここではコンテナを簡潔に作るテクニックにも触れておきます。
例えば、0-9の数値型を入れたリストを作りたい時とかってありますよね。
普通だったらこう書きます。
>>> li = [0,1,2,3,4,5,6,7,8,9]
>>> li
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
手作業ですね。
まぁ、10個くらいならいいんですが、100個とかになるとちょっと面倒ですし、1000個とか言われたらお手上げですよね?
そういう時に役立つのが内包表記です。
list型の場合は
["output" for "input" in range("n")]
みたいな感じで書きます。(""で囲まれた文字は任意の変数を表しています。文字列型というわけではないのでご注意ください)
>>> li = [x for x in range(10)]
>>> li
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> li = [x**2 for x in range(10)]
>>> li
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
数学的に言うと、"output"のところが出力値であるf(x)、"input"のところが入力値であるx、"n"が繰り返し回数を意味しています。
ちなみに、内包表記は後にif文を加えることも可能です。これは偶数だけ欲しい時とかに使えますね。
>>> li = [x for x in range(10) if x % 2 == 0]
>>> li
[0, 2, 4, 6, 8]
あと、dict型でも使用可能です。
{"output_key": "output_value" for "input" in range("n")}みたいな書き方になりますね。
>>> dic = {x*2: x**2 for x in range(10)}
>>> dic
{0: 0, 2: 1, 4: 4, 6: 9, 8: 16, 10: 25, 12: 36, 14: 49, 16: 64, 18: 81}
2-4. try文
これは例外が発生するif文のようなイメージです。例外というのはErrorのことですね。例えば、list型で要素が存在しないインデックスを指定するとErrorがでます。
>>> li = [0,1,2]
>>> li[3]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
こういう例外が発生しそうな処理をする時に使うのがtry文です。例外が発生しそうな処理をtry文に、例外が発生した時の処理をexcept節に記述していきます。
>>> try: # 例外が発生しそうな処理を記述
... li[3]
... except: # 例外が発生した時の処理を記述
... print('例外が発生したよ')
...
例外が発生したよ
さて、これだけではあんまり喜びを感じないかもしれませんね。
そんなtry文が本領を発揮するのはループ中だと思っています。
以下の処理を見てください。
>>> li = [2,4,'はち',16]
>>> for i in li:
... i / 2
...
1.0
2.0
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
TypeError: unsupported operand type(s) for /: 'str' and 'int'
list中の要素を2で割る処理を記述していますが、途中文字列をはさんでいるのでErrorが発生して処理が中断されてしまいました。
でも、Errorが発生してもとりあえず最後までやって欲しいなーって時ありますよね?
例えば、Webでスクレイピングとかする時にリンク切れしているページでいちいち止まられるとたまりません。そういう時に使うのがtry文です。
>>> li = [2,4,'はち',16]
>>> for i in li:
... try:
... i / 2
... except TypeError as e:
... print(e)
...
1.0
2.0
unsupported operand type(s) for /: 'str' and 'int'
8.0 # とりあえず最後まで実行できた
このようにexcept節を記述しておくととりあえず最後まで処理をしてくれます。
なので、Errorが発生しそうなループを実行する際はtry文がよく実行されます。
3. 関数
関数っていうのはコードを再利用するためのセットみたいなものです。短いコードなら関数や後述のクラスを使う必要はないんですが、コードが複数のモジュールに渡ったり、複数のパッケージを使ったりする時には必ず必要になってくるんです。
まずは簡単に下の数式を書いてみましょう。
$f(x) = x ^ 2$
def "function_name"("arguments"):
みたいな感じで書けます。
function_nameというのは関数名で、argumentsというのは引数と呼ばれていて、要は入力値ですね。複数書くことも可能です。
>>> def f(x):
... return x**2
...
>>> f(3)
9
こんな感じで簡単な二次関数を記述することができました。
引数について
関数の入力値である引数ですが、いろいろ種類がありますので確認していきましょう。
3-1. 位置引数
普通に引数を設定すると位置引数になります。
要は順番通りに反映されている値ですね。
>>> def f(a,b,c):
... print(a)
... print(b)
... print(c)
...
>>> f(1,2,3) # 順番通りに反映されます
1
2
3
ところで、*argsとか見たことありませんか?
私は学びたての頃にこの文字列を見て「?」となった経験があります。
これは可変長位置引数と言って、要は引数がいくつ続くかわからない時に仮引数に設定されるものです。
ここで仮引数というのは関数定義時に設定される引数のことで
def f("仮引数")←ここのことですね。
それに対して、実際に実行される時に代入される引数を実引数と言います。
f("実引数")みたいな感じですね。
話を戻しますが*argsというのは、仮引数をいくつ設定していいか分からない時に用いるものです。
>>> def f(*args): # 仮引数
... print(args)
...
>>> f(1,2) # 実引数
(1, 2) # tupleで取得される
>>> def f(*args):
... for arg in args: # 各要素を取得する場合
... print(arg)
...
>>> f(1,2,3)
1
2
3
このように実引数がいくつになっても(可変長であっても)対応可能で便利になりましたね。
3-2. キーワード引数
実引数にキーワードを指定して代入する方法です。
dict型の考え方と通ずるところがあって、位置(インデックス)による参照ではなくて、keyによる参照というイメージですね。実引数の順序に関わらず入力したキーワードに代入されます。
また、キーワード引数の後に位置引数は続けられないので注意です。
>>> def f(a,b,c):
... print(a)
... print(b)
... print(c)
...
>>> f(c=3, a=1, b=2)
1
2
3
>>> f(c=3, a=1, 2) # キーワード引数の後に位置引数は取れない
File "<stdin>", line 1
SyntaxError: positional argument follows keyword argument
また、位置引数と同じく可変長なキーワード引数も存在します。こちらは**kwargsと書きます。
kwargsはdict型として代入されます。
>>> def f(**kwargs):
... for key, value in kwargs.items():
... print(key, value)
...
>>> f(a=1,b=2,c=3)
a 1
b 2
c 3
3-3. デフォルト引数
仮引数にはデフォルト値を設定することができます。デフォルト値を設定してデフォルト引数とした場合は、実引数に何も代入しなかった時にデフォルト引数が暗黙的に呼び出されます。
>>> def g(a=0):
... print(a)
...
>>> g() # a=0がそのまま呼び出される
0
>>> g(3) # a=3となり、3が出力される
3
無名関数lambda
lambdaと書いてラムダと読みます。
波長かな?と思った人は物理屋さんですね。
でも、波長じゃありません。
使い捨て関数みたいな感じですね。
冒頭で関数が再利用するための道具です、みたいなこと言いましたがラムダは再利用しない1回こっきりの関数です。
関数の引数に関数を取るような時に使われますね。
例えば、map()という組み込み関数があります。
これはmap("function", "iterable")のようにして、引数に関数とイテラブルなコンテナを取って、コンテナの要素ごとに関数を実行するものになります。
使用例として、数値型を要素に持つlistの各要素に対して演算を行いたいケースを想定します。
普通にmap()を使う場合、いちいち関数を定義してあげる必要があります。
>>> li = [1,2,3,4,5]
>>> def f(x):
... return x*2
...
>>> list(map(f, li))
[2, 4, 6, 8, 10]
こんな時に使えるのがlambdaです。
関数を定義することなく1行でスマートに書くことができます。
構文は
lambda "input": "output"
のようになります。
>>> li = [1,2,3,4,5]
>>> list(map(lambda x: x*2, li))
[2, 4, 6, 8, 10]
こんな感じで、わざわざ関数を定義することなく演算することができましたね。
4. クラス
オブジェクト指向の要素の一つですね。オブジェクト指向については、いろんな流派があるようなのでここでの説明は割愛します。
クラスに関しては、よくたい焼き機だ!とか言われてますよね。
聞けば、たい焼き機が元になる設計図のようなものでクラスと呼ばれていて、たい焼きが実際に生み出されるものでインスタンスとか呼ばれています。
初心者の人には意味不明かもしれませんがとりあえずイメージを下に貼っておきますね。
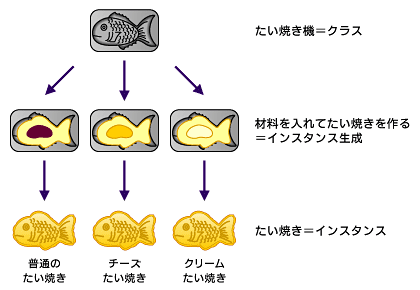
図4-1. クラスとインスタンスのイメージ
要は量産する時に役立つテンプレートみたいなものと思ってもらったらいいのかなと思います。
今回はたい焼きの代わりにポケモンを作る場合のことを考えていきたいと思います。
まず、dict型でポケモンを作っていきましょう。便宜的に順番は公式なものではないです。
まずは名前とポケモンの説明、タイプだけを定義していきます。
こちらはインタプリタ(黒い画面の即レスしてくるやつ)ではなくて、IDEのエディタ(VisualStudioCode)を使って記述していきます。
zenigame = {'name': 'ゼニガメ', 'doc': 'かめのこポケモン', 'type': 'みず'}
kameiru = {'name': 'カメール', 'doc': 'かめポケモン', 'type': 'みず'}
kamex = {'name': 'カメックス', 'doc': 'こうらポケモン', 'type': 'みず'}
hitokage = {'name': 'ヒトカゲ', 'doc': 'とかげポケモン', 'type': 'ほのお'}
rizard = {'name': 'リザード', 'doc': 'かえんポケモン', 'type': 'ほのお'}
さて、次はリザードンを作りたいのですが、困りましたね。
リザードンはご存知の通り、ほのお・ひこうタイプなのでタイプが2つあります。
なのでkeyをtypeからtype1とtype2に変更させたいです。
でも、ちょっと全部変更し直すのはちょっと面倒ですよね。まあ、今回は6体目なんで大丈夫ですけど、71体目とかではじめてタイプが2つあるポケモンがでてきたりしたらさすがに嫌ですよね。
そういう面倒な仕様変更にお応えするのがクラスです。
今度は先のdictをクラスを使って記述していきます。
クラスは
class "class_name":
で実装できます。
ちなみに、クラス内の関数のことをメソッドと呼び、メソッドは第一引数としてselfが必要です(便宜的に"self"という文字列を使ってますが規定はないです、言語によって違いがあってjavaなら"this"です)
そして、インスタンスを作る際に__init__という特殊メソッドを定義する必要があります。__init__みたいに__で囲まれたメソッドはすべて特殊メソッドとして扱われて、クラスに特性を持たせるために必要です。
class Pokemon:
"""ポケモンの型"""
def __init__(self, name, doc, type): # インスタンスを作成
self.name = name
self.doc = doc
self.type = type
zenigame = Pokemon('ゼニガメ', 'かめのこポケモン', 'みず')
kameiru = Pokemon('カメール', 'かめポケモン', 'みず')
kamex = Pokemon('カメックス', 'こうらポケモン', 'みず')
hitokage = Pokemon('ヒトカゲ', 'とかげポケモン', 'ほのお')
rizard = Pokemon('リザード', 'かえんポケモン', 'ほのお')
print(zenigame.__dict__)
# 結果はdict型の時と同じになります。
# {'name': 'ゼニガメ', 'doc': 'かめのこポケモン', 'type': 'みず'}
ここにリザードンを追加する場合はtypeをtype1にしてtype2を追加する必要がありますが、クラスを使うとクラスの定義部分を変更するだけで済みます。
class Pokemon:
"""ポケモンの型"""
def __init__(self, name, doc, type1, type2=None):
self.name = name
self.doc = doc
self.type1 = type1
self.type2 = type2
zenigame = Pokemon('ゼニガメ', 'かめのこポケモン', 'みず') # 変更なし
rizardon = Pokemon('リザードン', 'かえんポケモン', 'ほのお', 'ひこう')
print(zenigame.__dict__)
# {'name': 'ゼニガメ', 'doc': 'かめのこポケモン', 'type1': 'みず', 'type2': None}
print(rizardon.__dict__)
# {'name': 'リザードン', 'doc': 'かえんポケモン', 'type1': 'ほのお', 'type2': 'ひこう'}
また、せっかくポケモンを作ったので今度は技を覚えさせたいとしましょう。そんな要望も、クラスなら実現可能なんです。
class Pokemon:
"""ポケモンの型"""
def __init__(self, name, doc, type1, type2=None):
self.name = name
self.doc = doc
self.type1 = type1
self.type2 = type2
def attack(self, attack_name):
"""技"""
print(f"{self.name}は {attack_name}を くりだした!")
zenigame = Pokemon('ゼニガメ', 'かめのこポケモン', 'みず')
zenigame.attack('みずでっぽう')
# ゼニガメは みずでっぽうを くりだした!
こんな感じですね。
これは私の解釈ですがクラスを使うことによって、構文を英文法のようにSVO(主語・述語・目的語)でまとめることが可能なんですよね。
以下の文に注目してください。
zenigame.attack('みずでっぽう')
この文を無理やり日本語訳すると「ゼニガメが 技をくりだした みずでっぽうを」みたいに解釈できませんか?
これはzenigameがPokemonクラスのインスタンスとなりこの文の主語になっていて、その後にattack()というメソッドが述語になっていて、最後に'みずでっぽう'という引数が目的語になっています。
なんだか今まで出てきた変数や関数がまとまった感じがしますよね。これがオブジェクト指向が整理術だと言われる所以だと思っていて醍醐味なんじゃないかなぁと思います。
継承
最後にクラスの継承を説明しておきますね。
これは親クラスの属性を利用した子クラスを利用する時に使われます。数学的に言うと、ある集合の部分集合を作るイメージです。
例えば、先のPokemonクラスを親クラスとして、ひでん要員(SecretMember)クラスを子クラスとして作成してみましょう。
そうすると、SecretMemberクラスはばっこしPokemonクラスのメソッドも利用することができます。
class Pokemon:
"""ポケモンの型"""
def __init__(self, name, doc, type1, type2=None):
self.name = name
self.doc = doc
self.type1 = type1
self.type2 = type2
def attack(self, attack_name):
"""技"""
print(f"{self.name}は {attack_name}を くりだした!")
# PokemonクラスをSecretMemberクラスに継承させる
class SecretMember(Pokemon): # 親クラスを引数に取るだけです
"""ひでん要員"""
def secret_attack(self, attack_name):
"""ひでん技"""
print(f"{self.name}は {attack_name}を わすれられない!")
rizardon = SecretMember('リザードン', 'かえんポケモン', 'ほのお', 'ひこう')
rizardon.secret_attack('そらをとぶ')
# リザードンは そらをとぶを わすれられない!
rizardon.attack('かえんほうしゃ') # ちゃんと親クラスのメソッドも利用できる
# リザードンは かえんほうしゃを くりだした!
こんな感じであるクラスの属性を利用した似たようなクラスを作るときは継承を使います。
※余談ですが、昔のポケモン(7世代サン・ムーンより前)はひでん技とかいうものがあって、ひでん技は通常時では忘れされることができなかったんですよね。
7世代以降のポケモンでは、ポケモンライドとかそらとぶタクシーとかでひでん技は廃止されました。
ポケモンもいろいろ仕様変更を繰り返しているんです。
おわりに
以上で終わりです。
ここまで読んでくださった方は長々とありがとうございました。
厳密さや詳細な解説を省略して雰囲気でまとめた感が満載ですね。
読者の皆様はそろそろ厳密な解説を読みたくなってきたんじゃないかなぁということで以下参考から公式ドキュメントを見て頂ければと思います。
この記事がPythonを学ぶなにかのとっかかりになれば嬉しいです。
参考
[3]Python実践入門
[5][Snow Tree in June]
(https://snowtree-injune.com/)