codamaとは
みなさんこんにちは.codamaとはユカイ工学が発売している,自分でウェイクアップワードが設定できるボードです(https://codama.ux-xu.com) .codamaは単体でノイズキャンセリング,音声ビームフォーミングと音声識別(ウェイクアップワードのみ)ができます.ウェイクアップワードが自分で設定できるボードなんて実はcodama以外この世にまだ存在していないんですよね.SnowboyやvGateなどの音声認識エンジンを組み込んで使うことが一般的だと思います.しかし,codamaは簡単に設定ができるんです.
そんなcodamを今回初めて使って,VUIアプリを作ってみたいと思います!
codamaのセットアップ
codamaは3種類のモードがあります.
- Raspberry piとI2C通信で使うモード
- Raspberry piとUSB通信で使うモード
- パソコンなどのデバイスにUSBマイクとして使うモード
今回はなんとなくパソコンと繋げたいと思い,USBマイクとしてセットアップを行いたいと思います.
まずは公式のセットアップ方法(https://github.com/YUKAI/codama-doc-r0/wiki) を参照して下さい.
※現在Raspberry pi 4もサポートされています
そしてラズパイのOSアップデートによりセットアップ中にエラーが出るようです.下記リンクを参照して下さい.
https://qiita.com/minwinmin/items/e45e1e8c57324489e739
ラズパイとcodamaのセットアップが終わったら,次はウェイクアップワードを作成します.codamaの設定はここで終了です.

今回はこの方式です.

LinuxではUAC1.0,つまりHID機器として認識しました.ちなみに,Windowsでは謎のデバイスとして認識されました.
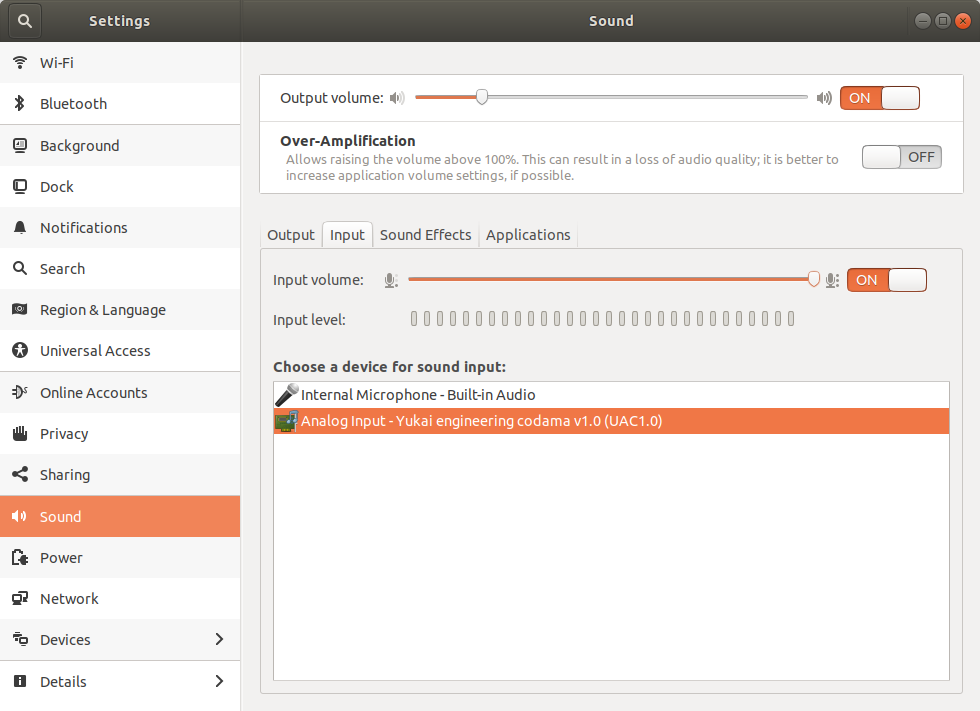
さて,ウェイクアップワードを好きに設定できますが,ここで僕は思いました.「誤認識したら嫌だなぁ〜」と.
あまり会話に出ない,しかし3〜4文字くらいで言いやすい...と考えた結果,今回はウェイクアップワードを「うんこ」に設定しました.ウェイクアップワードの検出モデル作成はユカイ工学が用意しているWebサイト(https://tools.codama.me) から誰でも無料にできます.
ワード検出の確認方法
公式ではpyusbを使ってワード検出を確認する方法が載っています.
しかし,よく見ているとウェイクアップワードを検出した時にcodamaの3つのLEDが高速に点滅しだすことがわかりました.もしPCにpythonの環境が入ってない場合はとりあえずウェイクアップワードをcodamaに話してみてLEDの動きを確認してみてください.ちなみにただの音に反応したときは赤いLEDが点灯します.
システム構成
スマートスピーカーに必要な要素は以下です
- ウェイクアップワード検知
- 音声認識
- 機器連携
流れは
ウェイクアップワード→録音→音声認識→機器連携
です.ウェイクアップワードはcodama単体でOKで,録音はPCなどで良いでしょう.音声認識はクラウドサービスを用いて,機器連携は今回は簡単にシリアル通信のみとします.ということで下記のような構成になりました.
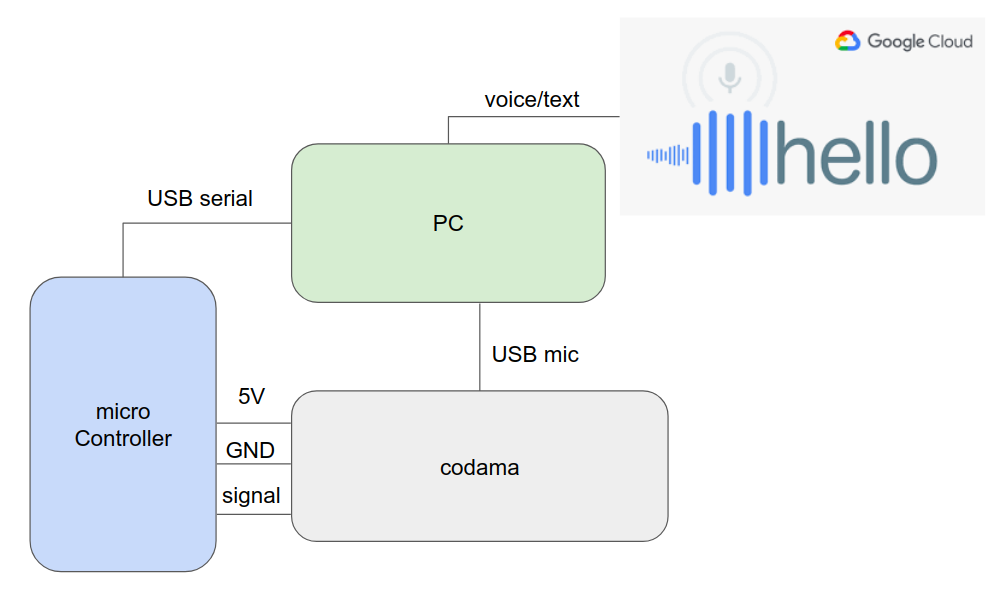
マイコン側
codamaはウェイクアップワードを検出し,トリガーを出すものとして考えます.そのトリガーを検知して,録音 → 文字起こし → なにかしらの動作がシステムの一連の流れになります.マイコンはトリガーを監視し,その先の流れを担います.今回はPCのデスクトップアプリが録音と文字起こしを担当するので,マイコンはcodamaとアプリの橋渡し的存在ですね.
マイコンはUSBシリアルがあれば何でもいいんですが,今回は手元にあったesp32を使用します.ラズパイはでかい.
配線は適当にこんな感じにしました.

esp32の5VとGNDをcodamaの5V,GNDに接続します.そしてここが重要(?)なのですが,ラズパイのGPIO 27にあたるピンソケット位置をesp32のGPIOピンのいずれかに接続します.ここでは35ピンを選びました.特に理由はない.
ウェイクアップワードの検知の際,codamaは27ピンがHIGHになります.これを監視すれば良いのです.
緑色のLEDが光ってますが,音声でとりまLチカする用です.
GCPのセットアップ
ウェイクアップワードを検知したら声による命令を認識する必要があります.codamaは文字起こしが出来ないので外部エンジンが必要になります.今回はGoogle Cloud Platform(GCP)のSpeech-to-textを使います.
まずは,GCPへGo(https://console.cloud.google.com/?hl=ja)
アカウントを登録したら,Cloud Speech-to-textをクリックします.
ほう...強気だ...
プロジェクトを作る必要があるようです.
無料期間があるようです.鞭を与えた後のアメか...
といっても,月に1時間以内の録音データであれば無料期間過ぎても無料らしいです.数秒程度の命令を解析しないので個人で使う分にはまず課金は発生しないと思います.
基本的には下URLの公式ドキュメント通り進めればOK
https://cloud.google.com/speech-to-text/docs/quickstart-client-libraries?hl=JA
ただここでハマりポイントがありました.
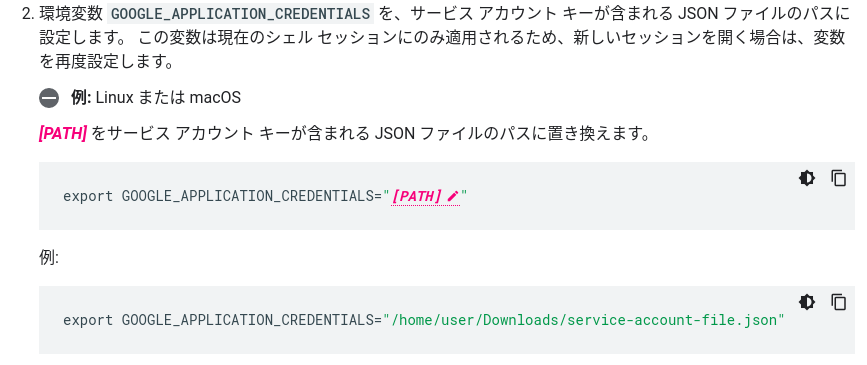
環境変数の設定ですが,例が間違っており,うまくいきません!
正しくは,
export GOOGLE_APPLICATION_CREDENTIALS="home/user/Download//service-account-file.json"
です./が一個足りない!!その他はドキュメント通りに進みました.
一通りの設定までのアクティビティが以下になります.
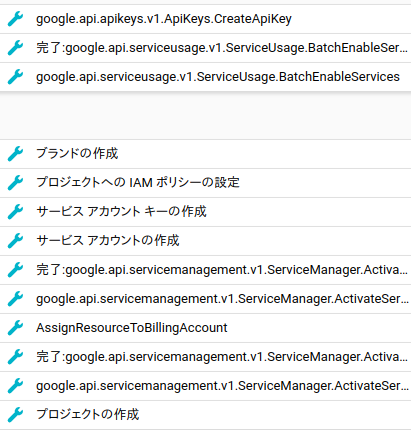
HTTP requestで音声を投げたいため,最終的にAPIKeyを取得する必要があります.
デスクトップアプリ
今回はクロスプラットホームのelectronを使います.理由はいろんなOSで動かしたいし,Node.jsで書け,GCPにPOSTしやすいからです.
codamaがウェイクアップワードを検出したらesp32がシリアルで[codama]と送り,アプリ側が5秒間録音を行います.そして,録音データをGCPにPOSTします.ここでURIにプロジェクトの設定で取得したAPI keyを含めます.
let res = await request("POST","https://speech.googleapis.com/v1/speech:recognize?key=ここにAPI keyを書く",{headers:headers,body:body});
これで録音データを文字に起こした結果が帰ってくるはずです.
なにかしらの動作
スマートスピーカーの骨組みは出来ました.実際に命令をするのですが,なにをしよう...
ウェイクアップワードを「うんこ」にしているのでせっかくだから「うんこ,うんこ作って」といったらうんこを作ってもらうことにしましょう.判定は文字起こしのテキストを命令とマッチさせます.
if(alternative.transcript.match(/.*うんこ.*作って/)){
serialWrite(makeSeiralCommand(SerialCommands.unko));
executed = true
}
さて,うんこを作る方法ですが,僕は慣れているからという理由でFusion360というCADでソフトで作ることにしました.理由はpythonで書けるAPIが用意されており,扱いやすいからです.
しかし,ハマった...
Fusion360のオブジェクトモデルが複雑?でハマりました...まず,APIのオブジェクトモデル図ですが,こちらになります.http://www.makerslide-machines.xyz/wp-content/uploads/2018/06/Fusion-360-api-model-object.pdf
わからん!!特にハマったのはうんこを仕上げるときに使う,「ロフト」というフューチャーです.
これ
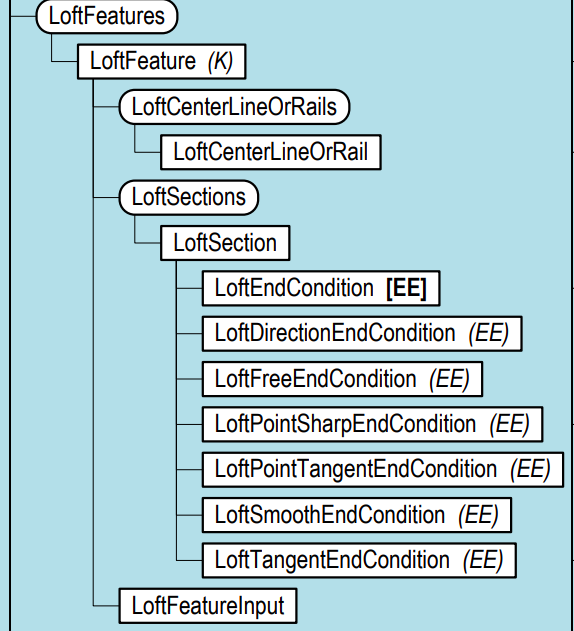
サンプルコードをみると
# Create loft feature input
loftFeats = rootComp.features.loftFeatures
loftInput = loftFeats.createInput(adsk.fusion.FeatureOperations.NewBodyFeatureOperation)
loftSectionsObj = loftInput.loftSections
loftSectionsObj.add(profile1)
loftSectionsObj.add(profile2)
loftInput.isSolid = True
# Create loft feature
loftFeats.add(loftInput)
except:
if ui:
ui.messageBox('Failed:\n{}'.format(traceback.format_exc()))
FuturesからInputオブジェクトをつくり,Sectionオブジェクトをさらに作り,うんこの円をprofileとしてaddで選択すればいいようです.ここで,うんこは渦巻きを巻いているため渦巻きのパスに沿ってロフトを作らなければなりません.オブジェクト図から見ると,loftCenterOrRailsのようですが....
一見,Futureの子供だと思い,rail = loftFeats.loftCenterOrRails,としたのですが,そんなの無いよ,と怒られてしましました.その後色々ドキュメント(http://help.autodesk.com/view/fusion360/ENU/?guid=GUID-7B5A90C8-E94C-48DA-B16B-430729B734DC )などを見ましたがよくわかりませんでした.

いや,loftCenterOrRailsあるじゃん...
結論から言うと,下記のようにInputオブジェクトにcenterLineOrRailsというインスタンスがあり,そこでaddCenterLineという関数の引数にpathオブジェクト(ここではうんこの渦巻き線)をとれば良かったのです.んー,わかりにくい...
guide = rootComp.features.createPath(spline1)
# Create loft feature input
loftFeats = rootComp.features.loftFeatures
loftInput = loftFeats.createInput(adsk.fusion.FeatureOperations.NewBodyFeatureOperation)
loftSectionsObj = loftInput.loftSections
loftInput.centerLineOrRails.addCenterLine(guide)
うんこじぇねれーたー
巻数を指定するとうんこの3Dモデルを自動生成してくれるようにしました.
Fusion360のアドインを生成します.
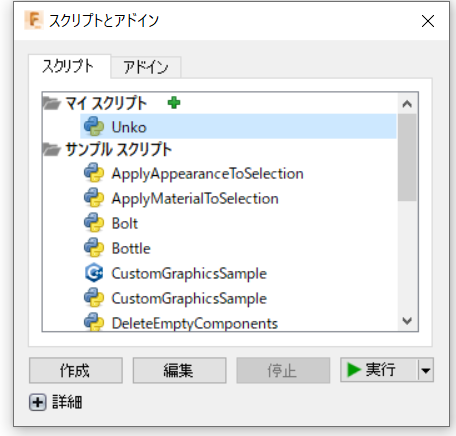
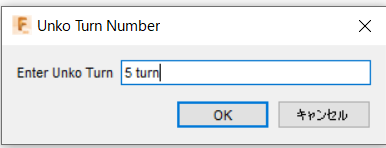
実行するとこのような入力ボックスが表示され巻数を入力することができます.
VUIではこのパラメータも指定したいと思います.
生成されたうんこ

レンダリングすればザ・うんこ
誰だ!道の真ん中にうんこしたのは!

さて,骨組みも出来たし,esp32からの指令をpyserialで読んで,うんこを作ろう.
と思っていたら,なんと...
Fusion360 APIはpyserialが使えないことがわかりました...
https://stackoverflow.com/questions/44837452/does-fusion-360-not-have-access-to-usb-ports-by-default
import pyserial
とすると,エラーは吐かないのになにも表示されません.
これではesp32とやり取りができません....どうやら命令をCSVファイルに保存してそれを読み込むか,HTTPリクエストをしないとエッジデバイスとやり取りができないようです.
夢の「うんこ,うんこを6巻作って」は今記事では出来ませんでした.とほほ.
作成したソースコードは下記です.
import adsk.core, adsk.fusion, traceback
def run(context):
ui = None
try:
app= adsk.core.Application.get()
design = app.activeProduct
ui = app.userInterface
#**Default User Inputs**
steps = "5 cm"
input = steps
createInput = ui.inputBox('Enter Unko Turn', 'Unko Turn Number', input)
if createInput[0]:
(input, isCancelled) = createInput
unitsMgr = design.unitsManager
realSteps = unitsMgr.evaluateExpression(input, unitsMgr.defaultLengthUnits)
#Get root component
rootComp = design.rootComponent
#Create a new sketch on XY plane
sketch = rootComp.sketches.add(rootComp.xYConstructionPlane)
# Create an object collection for the points.
points = adsk.core.ObjectCollection.create()
R = int(realSteps*4)
#starting x and y coordiantes
x = 0
y = 0
z = 0
#Create 1st coordinate
points.add(adsk.core.Point3D.create(x,y,z))
#Starting Loft Profile Diameter
loftProfile1 = 0.1
#bins for shifting x and y coordinates
Bin1 = range(0,R,4)
Bin2 = range(1,R,4)
Bin3 = range(2,R,4)
Bin4 = range(3,R,4)
BinLoft = range(0,R)
for i in range(R):
if i in Bin1:
x = x
y -= 1/5
z += i/3
points.add(adsk.core.Point3D.create(x,y,z))
if i in Bin2:
x -= i/3
y -= 1/5
z = z
points.add(adsk.core.Point3D.create(x,y,z))
if i in Bin3:
x = x
y -= 1/5
z -= i/3
points.add(adsk.core.Point3D.create(x,y,z))
if i in Bin4:
x += i/3
y -= 1/5
z = z
points.add(adsk.core.Point3D.create(x,y,z))
if i in BinLoft:
loftProfile2 = 0.5 #Ending Loft Profile Diameter
# Create the spline.
sketch.sketchCurves.sketchFittedSplines.add(points)
# Create the Starting Loft Profile
spline1 = sketch.sketchCurves.sketchFittedSplines.item(0)
planeInput = rootComp.constructionPlanes.createInput() # you could also specify the occurrence in the parameter list
planeInput.setByDistanceOnPath(spline1, adsk.core.ValueInput.createByReal(0))
plane1 = rootComp.constructionPlanes.add(planeInput)
sketch1 = rootComp.sketches.add(plane1)
circles = sketch1.sketchCurves.sketchCircles
circles.addByCenterRadius(adsk.core.Point3D.create(0, 0, 0), loftProfile1)
profile1 = sketch1.profiles.item(0)
# Create the End Loft Sketch Profile
planeInput.setByDistanceOnPath(spline1, adsk.core.ValueInput.createByReal(1))
plane2 = rootComp.constructionPlanes.add(planeInput)
sketch2 = rootComp.sketches.add(plane2)
circles = sketch2.sketchCurves.sketchCircles
skPosition = sketch2.modelToSketchSpace(spline1.endSketchPoint.geometry)
circles.addByCenterRadius(skPosition, loftProfile2)
profile2 = sketch2.profiles.item(0)
guide = rootComp.features.createPath(spline1)
# Create loft feature input
loftFeats = rootComp.features.loftFeatures
loftInput = loftFeats.createInput(adsk.fusion.FeatureOperations.NewBodyFeatureOperation)
loftSectionsObj = loftInput.loftSections
loftInput.centerLineOrRails.addCenterLine(guide)
loftSectionsObj.add(profile1)
loftSectionsObj.add(profile2)
loftInput.isSolid = True
# Create loft feature
loftFeats.add(loftInput)
except:
if ui:
ui.messageBox('Failed:\n{}'.format(traceback.format_exc()))
動作
はい,というわけで下が今回できたデスクトップアプリの画面になります.
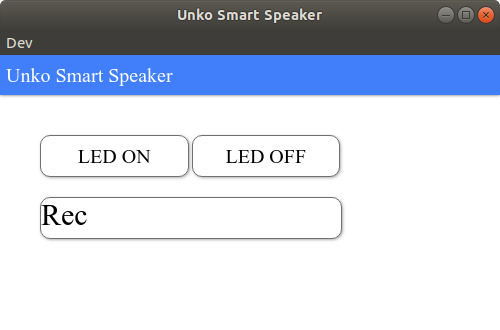
ボタン操作と音声操作が可能になっていて,Recボタンかcodamaにウェイクアップワードを言うと,
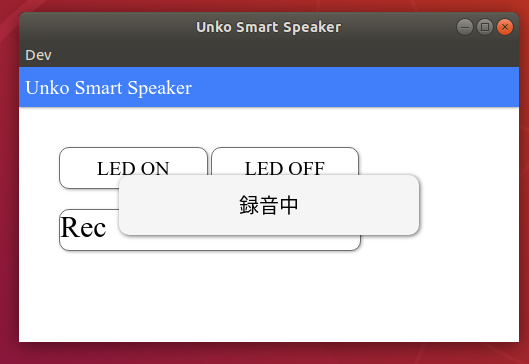
録音中の通知がでます.その間にしゃべると録音してGCPに投げてくれます.下が実行結果です.
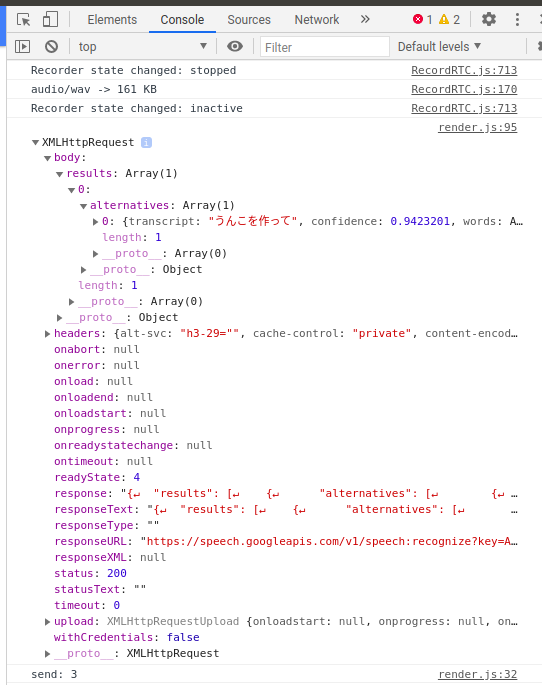
実際に,「うんこを作って」と認識でき,一番最後に
send: 3
と,esp32にコマンドを送っているのが確認できました.ついでに付けたLEDもちゃんと発話によってチカチカ出来ました.
まとめ
独自ウェイクアップワードを簡単に設定できる唯一のボードcodamaを使って,esp32・electronを使ってスマートスピーカーを作り,スマートスピーカーに必要な要素とスキルを完全に理解しました.またFusion360のAPIを使ってスクリプトでCADモデルを作成する方法も完全に理解しました.連携部分は残念な結果になりましたが,みなさんも是非自分だけのスマートスピーカーを作ってみて下さい.