当プロジェクトについて
当プロジェクトは弊社アイドル三村かな子をシンデレラガールに導くためのプロジェクトである。
プロジェクトを開始するにあたって以下のグラフをご覧頂きたい。
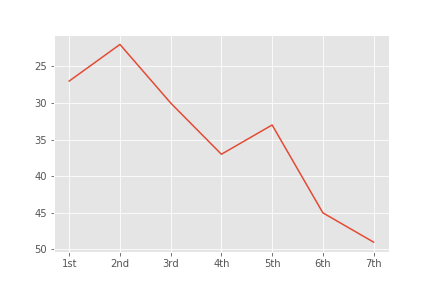
このグラフはモバマス内で過去7回行われてたシンデレラガール総選挙における三村の順位の推移である。
シンデレラガール総選挙では約200人のアイドルが被選挙権を持ち、各選挙において上位50名の順位が公表されている。
その中で、見事1位に輝いたものがシンデレラガールの称号を得るという仕組みである。
見てわかるように右肩下がりとなってはいるが、三村は全ての総選挙で上位50位以内をキープしており非常に優秀なアイドルであるとも言える。
しかし、第7回において三村は49位とボーダーの50位に肉薄しており、このままではシンデレラガールどころか、ランク圏外に落ちる可能性もあると言える。
当プロジェクトは過去7回の総選挙をデータという視点から分析し、三村をシンデレラガールへ導くために発足した。
第7回の選挙結果及び基本情報をスクレイピングにより取得する
プロジェクトに先立って、第7回シンデレラガール総選挙の結果をニコニコ大百科よりスクレイピングによって取得した。
選挙結果のスクレイピング
import requests
import csv
from bs4 import BeautifulSoup
import re
import unicodedata
url = "https://dic.nicovideo.jp/a/%E7%AC%AC7%E5%9B%9E%E3%82%B7%E3%83%B3%E3%83%87%E3%83%AC%E3%83%A9%E3%82%AC%E3%83%BC%E3%83%AB%E7%B7%8F%E9%81%B8%E6%8C%99"
req = requests.get(url)
soup = BeautifulSoup(req.content, "html.parser")
table = soup.find("table",attrs={'style':'text-align: center;'})
rows = table.find('tbody').findAll("tr")
def rank_normalization(rank_text):
r = unicodedata.normalize("NFKC",rank_text)
return re.sub('\n[Cu|Co|Pa]*[1-9]','',r.translate(mktrans))
csvFile = open("data/senkyo7.csv", 'w')
writer = csv.writer(csvFile)
title = ['1st','2nd','3rd','4th','5th','6th','7th','name','votes']
writer.writerow(title)
for row in rows:
csv_row = [rank_normalization(c.get_text()) for c in row.findAll(['td','th'])]
csv_row.pop(6)
writer.writerow(csv_row[:-1])
上記コードについていくつかはまった点があったので覚書てして残しておく
tableタグを読み込むときにちょうどいいClass,IDが存在しなかった
Beautifulsoupを使ったスクレイピングを行う際、CSSなどに使われるのClassやIDを指定すると思い通りのタグをピンポイントで持ってくることができる。
# 例
table = soup.find("table",class_='hogehoge')
しかし今回のサイトでは、当該テーブルをピンポイントで指定できるタグがなかった。
このような場合、いろいろな回避策があるがその中の一つにclass,IDではないタグのアトリビュートを指定するという方法がある。
findメソッドの引数に*attrs={アトリビュート名:アトリビュートの中身}*と指定する方法である。
今回は余り綺麗ではないがこちらを使い、対象のテーブルを取得した。
# 例
table = soup.find("table",attrs={'style':'text-align: center;'})
順位に①とか⑫とかの機種依存文字で出来た数字が使われていた
上記の方法で、データを取得することはできたが、取得したデータの中に③や㉚などの機種依存文字が使われていた。
これらを数字に変換するため、標準ライブラリのunicodedata.normalizeメソッドを使用し、数字への変換を行った。
import unicodedata
unicodedata.normalize("NFKC",'①③⑤')
# '135'
なおここでは、文字列としての数字への変換は行っているが、数値への変換は行っていない。
アイドルの基本データのスクレイピング
合わせて属性データ等を取得するため、アイドルの基本データのスクレイピングを行った。
※基本データの取得についてはこちらの記事のコードをベースにさせていただきました。
ありがとうございます。
なお使用するライブラリなど細かなところはカスタムさせていただきました。
url = "https://imascg-slstage-wiki.gamerch.com/%E3%82%A2%E3%82%A4%E3%83%89%E3%83%AB%E4%B8%80%E8%A6%A7"
req = requests.get(url)
soup = BeautifulSoup(req.content, "html.parser")
table = soup.find("table",attrs={'width':'900'})
rows = table.findAll("tr")
csvFile = open("data/mobamasdata.csv", 'w')
writer = csv.writer(csvFile)
for row in rows:
csvRow = []
for cell in row.findAll(['td', 'th']):
csvRow.append(cell.get_text())
writer.writerow(csvRow)
データ分析(未)
さて、これで分析するデータをCSVとして取得することができた。
しかし、このままでは十分に分析することはできない。
ここで取得した選挙結果を見ていただこう。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
%matplotlib inline
plt.style.use('ggplot')
master_df = pd.read_csv('data/mobamasdata.csv').set_index('名前').rename(columns={'Unnamed: 0':'type'})
senkyo_df = pd.read_csv('data/senkyo7.csv')
senkyo_df['votes'] = senkyo_df['votes'].str.replace(',','').astype(float)
senkyo_df
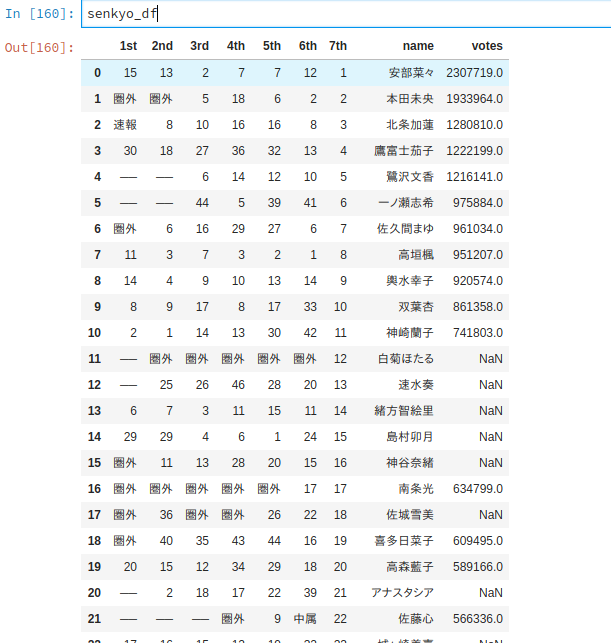
votes列に注目いただきたい。
この列は各アイドルの得票数を表している。
一部が歯抜けになっているのがお分かりいただけるだろう。
第7回総選挙では、上位50名の順位は公表されているものの、得票数はアイドル一人ひとりに設定された属性[cute,cool,passion]毎に上位5名ずつしか公表されていない。
肝心の三村についても以下のとおりである。

また、歯抜けになっているデータについても属性によりばらつきがあり、このままでは属性間の比較が難しいという問題もある。
そのため、次回はこれら上位50人の得票数を大まかながら推測し、三村の得票数の推測及び属性ごとの得票数の傾向を見ていこうと考えている。