 自分だけが沼ったのかも。
自分だけが沼ったのかも。
やること
フリーの大規模言語モデルであるChatRWKVのためにRTX-3090でCUDAを使いたいと思います。
バージョンを合わせる作業が面倒そうなので、調べずにあてずっぽにやってスルーできたらいいなと思ったのですが、やはり一発では通してもらえませんでした。
心を落ち着けてメモをとりながら整理していきます。
Windows10でいきます。
NVIDIAのドライバを更新する
まず最初にドライバを更新しておきます。ダウングレードもできるようです。
下記のサイトが参考になります。
ドライバーを更新した後、コマンドプロンプトで
nvidia-smi
と入力すると、下記のように表示されました。
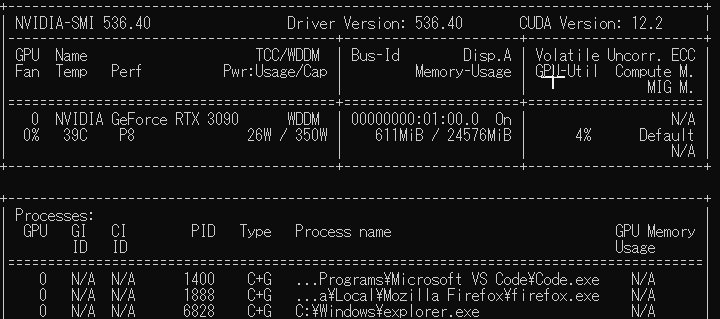
ここで「CUDA Version: 12.2」という表示がありますが、これはこのドライバに適合するCUDAのバージョンが12.2という意味らしく、実際にCUDA 12.2がインストールされているわけではない(らしい)ので注意が必要です。
実際にインストールされているCUDAのバージョンは、
nvcc -V
というコマンドで表示されます。
CUDAのインストール前であればたぶんこのコマンドは使えません。
キーとなるモージュールを見つける
今回のRWKV向けのインストールで関係してくる要素はだいたい下記の通りです。
- Windows10
- NVIDIA GeForce RTX 3090
- 上記ドライバ
- CUDA Toolkit
- cuDNN
- python
- pytorch
- torchvision
- torchaudio
- ninja
この中からバージョン耐性が一番低く、ちょっとのことで動かなくなるようなキーモジュールをみつけます。扱いがめんどくさいその繊細野郎を気遣って周囲が合わせてやれば、全体の歯車がかみ合って勝つるというわけです。
計算の根幹を担当するハードウェアのRTXかCUDAを基軸として他を構築するのが順当な気もしますが、今回は実はpytorchがバージョン合わせのカギを握っています。
インストール作業を途中まですすめてから、こいつが主役だったか!と気づきました。
ということで、pytorchを軸にそれ以外の要素のバージョンをそろえていきます。
pytorchの適合相手を調べる
pytorchの公式サイトで適合する要素の組み合わせを調べられます。

Stable(2.0.1)版を選ぶと必然的にCUDAは11系になります。
11.7と11.8がありますが今回はRWKVの導入記事でよく見るCUDA11.7を採用してみます。
また、OSにWindows、Pythonの環境にはCondaを選んでみます。
適合する相手がわかったので、pytorchをインストールする前にCUDA11.7をインストールしに行きます。
CUDAを探しに行く
そもそもCUDAが何物かも知らなかったのですが、GPU用のプログラム開発環境とのことです。
GPUの複数の演算器を利用した高速な並列演算処理をC言語のように行えるようです。
さて、そのCUDAをインストールしようと調べると、Visual Stuioがあったほうが良いという記事に出会います。特に抵抗がなければここでVisual Stuioのインストールを。自分はVisual Studioを普段使いしているので気にせず進みます。
あとでRWKC?がコンパイラのclを使うようで、それがVisual Stuioに含まれているようです。あとでパスを設定します。
NvidiaのCUDAのサイトに進み、CUDAのアーカイブから11.7.1を選んでみます。
環境に合わせてパネルを選択することで正解のファイルにたどり着けます。
pytorchの時と同じようなUIですが、わかりやすくて助かります。
選択したファイルをインストールします。
cuda-toolkitを導入することでCUDA本体がインストールされます。
cuDNNを奉納する
cuDNN(クドンと読むらしい)はCUDAでつかうディープラーニング用のライブラリで、これが必要だそうです。太陽エネルギーの施設は見つけたけどラオ博士がいないと動かない的な。
この世のどこかにあるというcuDNNを見つけ出し、適切な場所に格納しなくてはなりません。
Nvidiaのcdunnのサイトに行き、cuDNN v8.9.3 for CUDA 11.xを選びDLします。
※NVIDIA Developer Program へのメンバーシップへの加入が必要かもしれません。
解凍すると「cudnn-windows-x86_64-8.9.3.28_cuda11-archive」というようなフォルダができるので、中にあるフォルダたち(bin, include, lib)を
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7
のディレクトリ下に貼ります。(必要な中身がマージされると思います。)
パスを設定する
cuDNNへのパスを設定します。
使用する環境変数名が決まっているようで、Pathへの追記という方法ではなく、変数名として指定します。
Windowsの左下ボックスから「システム環境変数の編集」でシステムのプロパティを開きます。(※「環境変数の編集」ではないので注意)
「詳細設定」→「環境変数」→「システム環境変数」→「新規ボタン」で下記の設定を行います。
システム環境変数
| 変数名 | 変数値 |
|---|---|
| CUDA_PATH | C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7 |
| CUDA_PATH_V11_7 | C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7 |
| CUDNN_PATH | C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7 |
(でもなんとなく不安なので、念のためPathへの追記もしておきました。)
pythonの仮想環境に入る
ここで必要に応じてpythonの仮想環境に入っておきます。
自分はcondaを使っています。
pythonは他との相性を見て3.10を使っています。
conda activate xxxxx(作成済みの環境名)
pytorchをインストールする
pytorchの公式サイトに戻り、インストールコマンドを調べます。
自分の場合は以下になりました。
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
これでたぶんPytorchまでは入ったと思います。
ここから先はChatRWKCのインストールです
VisualStudioのパスを通す
ビルドに向けて、Visual Studioに含まれるcl.exeが必要になるのですが、前述のようにこのパスを通しておく必要があります。
まず、cl.exeまでのパスを調べます。
自分の環境では以下のような場所でしたが、似たようなところにあると思いますので、お手元の環境でのパスを特定してください。
例)C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\xx.xx.xx\bin\Hostx64\x64
次にシステム環境変数を書き換えます。
先ほどと同じやり方で「システム環境変数の編集」を開きます。
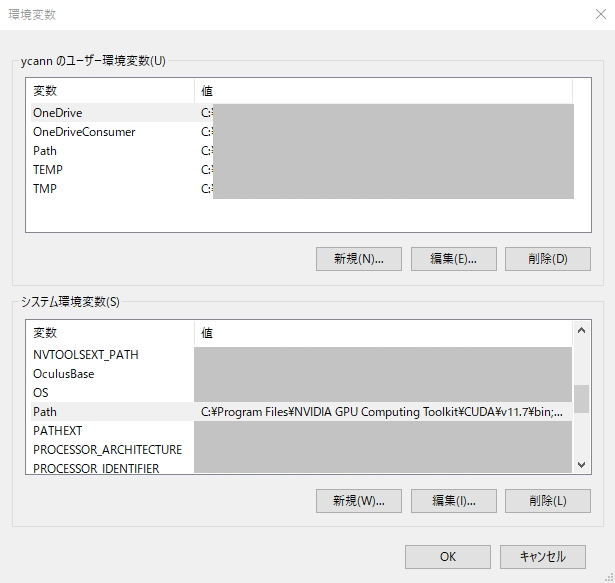
「詳細設定」→「環境変数」→「システム環境変数」→「Path」を選択→「編集ボタン」を押します。
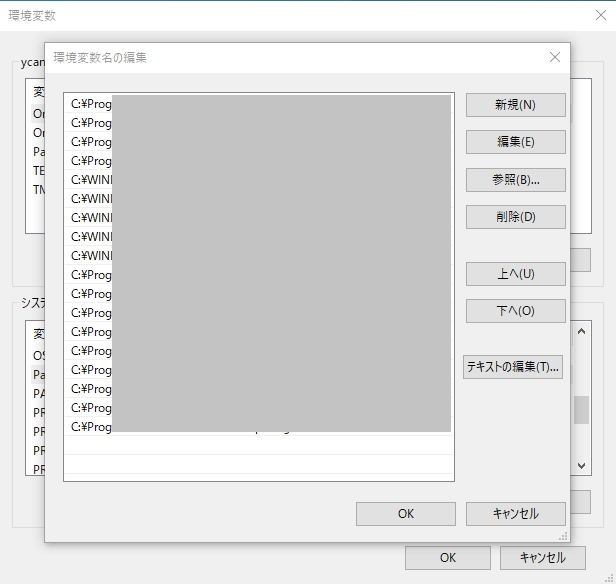
パスの一覧が出ますので、ここで「新規」を押し、cl.exeまでのパスをペーストします。パスはcl.exeの手前のディレクトリまででOKです。
これでパスが通ったはずです。
ターミナルウィンドウを新規で開きclと打って下記のように返答があれば成功です。

ChatRWKVをクローンする
Python用の適当なディレクトリに移動して、ChatRWKVをgit cloneします。
cd ~/xxxx(作業に使いたいディレクトリ)
git clone https://github.com/BlinkDL/ChatRWKV
cd chatRWKV
ninjaをインストールする
高速なビルドツールであるNinjaを導入します。
anaconda.orgでNinjaのインストールコマンドを調べ、実行します。
conda install -c conda-forge ninja
RWKVに必要なものをインストールする
pip install rwkv
conda install numpy
pip install -r requirements.txt
requirementsではtokenizersとprompt_toolkitがインストールされるようです。
仮想環境に入っているのでpipでのインストールがまざってもたぶん大丈夫です。と信じてます。
大規模言語モデルを格納する
実行するchat.pyの入ったv2ディレクトリに移動しておきます。
cd v2
そのディレクトリに、モデル(重み)ファイルをDLして格納します。
HuggingFaceにあるモデルから、扱いやすいrwkv-4-pile-3b(具体的にはRWKV-4-Pile-3B-20221110-ctx4096.pth)や7BのモデルをDLし、v2のディレクトリに配置します。
chat.pyを修正する
chat.pyのコードの中で、使いたいモデルを指定します。
その際.pthの拡張子は不要です。
また、モデルファイルをchat.pyと同じv2に格納する場合はパスも不要です。
elif CHAT_LANG == 'Japanese':
args.MODEL_NAME = 'RWKV-4-Pile-3B-20221110-ctx4096'
# args.MODEL_NAME = '/fsx/BlinkDL/HF-MODEL/rwkv-4-raven/RWKV-4-Raven-14B-v8-EngAndMore-20230408-ctx4096'
次に、CPU、GPU、モデルの種類なども適切なものに変更します。
下記はcudaを使って、ファイルも量子化しない(軽量化しない)場合です。
使用言語は先ほど設定したJapaneseにします。
# args.strategy = 'cpu fp32'
args.strategy = 'cuda fp16'
(中略)
os.environ["RWKV_JIT_ON"] = '1' # '1' or '0', please use torch 1.13+ and benchmark speed
os.environ["RWKV_CUDA_ON"] = '1' # '1' to compile CUDA kernel (10x faster), requires c++ compiler & cuda libraries
CHAT_LANG = 'Japanese' # English // Chinese // more to come
JITはビルドについての指定だと思いますが、よくわかりません。
chat.pyを実行する
ようやく実行です。
python chat.py
動かない場合は、モジュール不足、メモリ不足、パス不通のどれかが原因だと思います。エラーメッセーで判別できると思います。
ちなみに自分はパスの通し方で沼りました。
また、PCのメモリが足りないと3Bでも動かない場合があります。GPUへのデータコピーの時にメモリを使っているようなので、その場合はwindowsの仮想メモリを設定すれば動くと思います。
実行結果

なんとか動きました!
この実行例ではごく軽量な3Bのモデルを使っている上、無理に日本語で使っているので会話もうまくかみ合っていませんが、知らないことでもがんばってそれっぽく答えようとしていて面白いです。
RTX3090を積んでいるのにPC本体のメモリ(DMM)は8GBしかないという一点豪華主義の無謀なハードウェア構成ですが、そのまま7Bも試してみました。

起動できたりできなかったりすることがあるような気もしますが、動いているようです。
さすが、会話の噛み合い具合いはかなり向上します。
応答スピードも1秒未満で返答が始まる感じで、とてもサクサクしています。
応答をよくしていきたい
量子化や大きいモデルを使うことでよい結果が得られるようですが、記事を分けて改めてご報告します。
古いPCでメモリが16Gしか詰めないことが判明したのでメインボードの買いなおしも必要かも。
ほかのことにも使いたい
TensorflowからもCUDA、cdNNのバージョンのご指名があるようです。
CUDA 11.8でRWKVが動けばTensorflowとの共存もうまくいきそうなので、あとで試してみます。
StableDiffusionにも対応できるモジュールを入れたつもりですが、沼りませんように。
次回記事
参考
(↑モデルのコンバート方法も)