1. scikit-mobilityとは?
scikit-mobilityは位置情報データを使用して人の動きを解析したり、可視化することができるpythonライブラリです。
公式ドキュメント:https://scikit-mobility.github.io/scikit-mobility/index.html
GitHub:https://github.com/scikit-mobility/scikit-mobility
公式ドキュメントは英語しかありませんが結構充実していて、
GitHubにはチュートリアル等も載っているので試してみるのがおすすめです。
scikit-mobilityの主な機能と、チュートリアルについて解説しているQiitaもありますのでこちらも是非参考にしてください。
2. 今回紹介する関数
- カテゴリ:preprocessing(前処理)
preprocessing(前処理)に分類される関数には、以下の二種類の関数があります。- 生の緯度経度データを解析、加工がしやすいように不要なデータを削除したり、データ量を減らす処理を行うことができる関数
- 同じ条件下にあるデータをクラス分けすることができる関数
今回はpreprocessing(前処理)の関数のうち、
2. 同じ条件下にあるデータをクラス分けすることができる関数
に該当する二つの関数をコードを交えて紹介していきます。
- detection.stay_locations:指定した範囲内に少なくとも指定した時間滞在した場合にデータポイントが検出される
- clustering.cluster:異なる時間の同じ場所への訪問をクラスタリングする関数
※ 今回この記事で使用しているデータは社内検証用のデータになります。
3. 前提処理
ライブラリのインストール
$ pip install scikit-mobility
詳しい環境構築はこちらを参考にしてください
TrajDataFrameデータの作成
- 以下の項目を含むデータを用意します。
latitude(type: float); 緯度(必須)
longitude (type: float); 経度(必須)
datetime (type: date-time); 日時(必須)
uid (type: string);(オプション)
tid (type: string); (オプション)
特に使いたいデータがない場合はscikit-mobilityのチュートリアルを参考にこちらのデータをダウンロードするといいと思います。
※自動でデータがダウンロードされるので気をつけてください
# ファイルのダウンロード(google colab等で実行する場合はこうすると楽です。)
import urllib.request
url='https://raw.githubusercontent.com/scikit-mobility/scikit-mobility/master/examples/geolife_sample.txt.gz'
save_name='geolife_sample.txt.gz'
urllib.request.urlretrieve(url, save_name)
- 用意したデータをTrajDataFrameに変換します。
import skmob
# リストをTrajDataFrameに変換する場合
tdf = skmob.TrajDataFrame(data_list, latitude=1, longitude=2, datetime=3)
# pandas.DataFrameをTrajDataFrameに変換する場合
tdf = skmob.TrajDataFrame(data_df, latitude='latitude', datetime='hour', user_id='user')
3. preprocessing(前処理)
参考URL:https://scikit-mobility.github.io/scikit-mobility/reference/preprocessing.html
概要
データ解析をしやすくするための前処理を行うことができる関数
detection.stay_locations(滞在検出処理)
概要
与えられた軌跡点から指定した距離 stop_radius_factor * spatial_radius_km 以内に少なくとも指定した時間(minutes_for_a_stop分間)滞在した場合にユーザーの滞在場所として検出されます。
停止位置の座標は、指定された距離内に見つかった点の緯度と経度の中央値になります。
inputに必要なデータとパラメータ、outputされるデータについて
-
inputデータ
- tdf(TrajDataFrame): 緯度経度データ
-
パラメータ
- stop_radius_factor(default:0.5)
- minutes_for_a_stop(default:20.0min): 最小停止時間(分単位)
- spatial_radius_km(default:0.2)
- leaving_time(default:True): 停止場所からの出発時刻をデータに追加
- no_data_for_minutes(default:1e12): 2つの連続するポイント間の時間が指定より大きい場合、欠落データとされる
- min_speed_kmh(default:None): 速度が指定より大きい場合は、停止終わりにあるポイントを削除する。
-
inputデータ例
- データ型がTrajDataFlameのデータを使うことができます。
- 中身はこんな感じです。
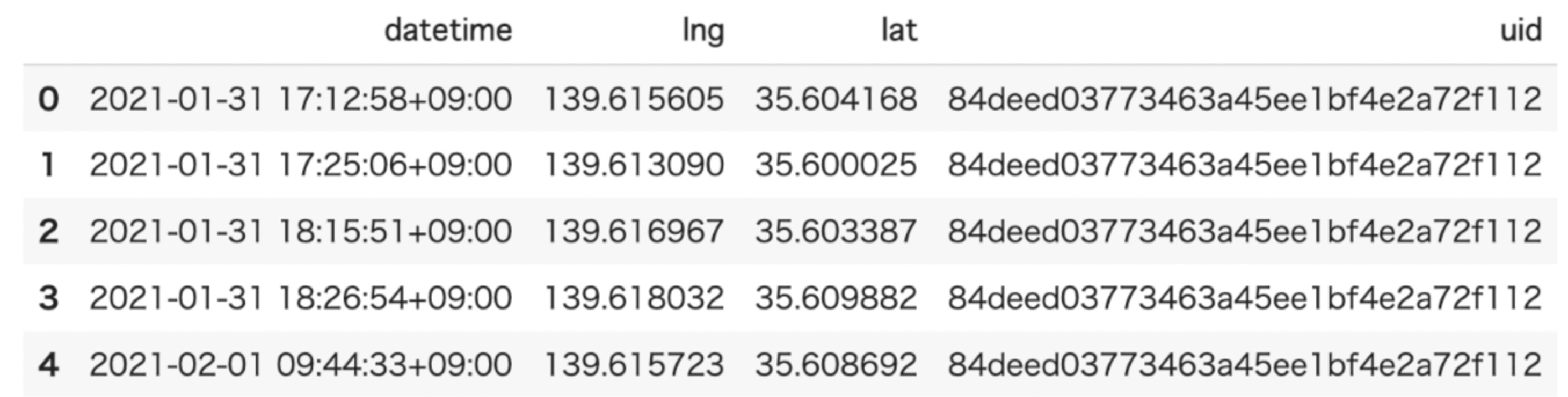
-
Outputデータ
滞在地の座標(緯度経度)を含むTrajDataFrameが出力されます。
入力したデータのカラムにleaving_datetime(ユーザーがその場所を離れたとされる時間)の項目が追加されて出てきます。- アウトプットデータ例
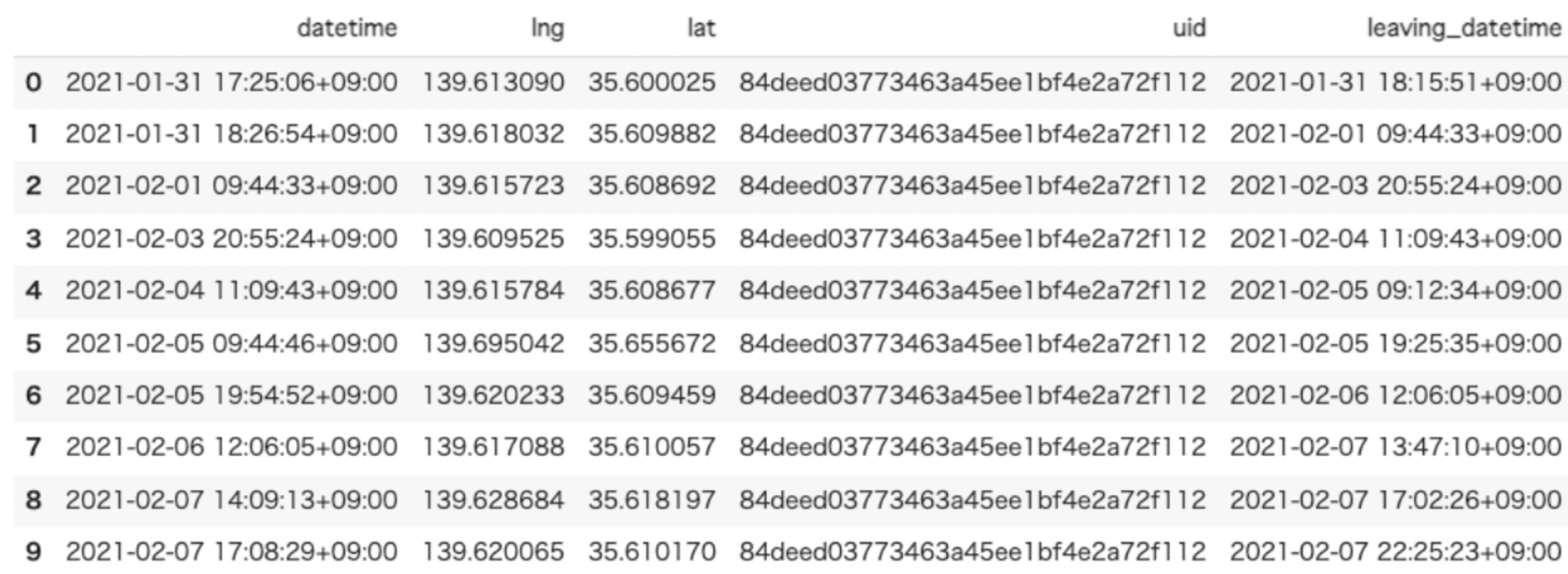
- アウトプットデータ例
コード例
- 滞在解析を行うのはこんな感じです。
from skmob.preprocessing import detection
stdf = detection.stay_locations(
tdf, stop_radius_factor=0.5, minutes_for_a_stop=20.0, spatial_radius_km=0.2, leaving_time=True
)
stdf.head()
- 滞在解析関数の結果を可視化することも簡単にできます。
map_f = stdf.plot_trajectory(max_points=100, start_end_markers=False, hex_color="#4682b4")
stdf_u.plot_stops(map_f=map_f)
- 出力結果はこんな感じです。
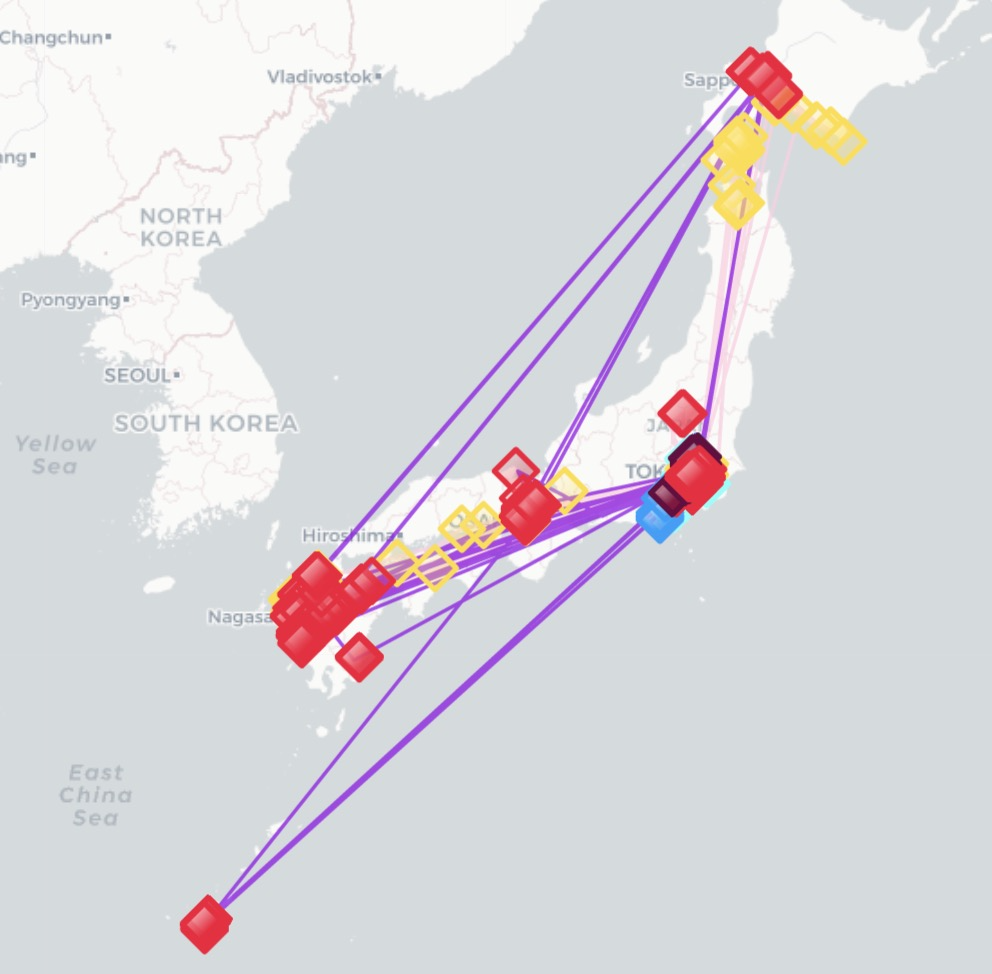
ユーザーごとに色分けされてポイントが出てきます。
四角の位置がユーザーが滞在した位置を表現しています。
地図を拡大してみるとこんな感じです。
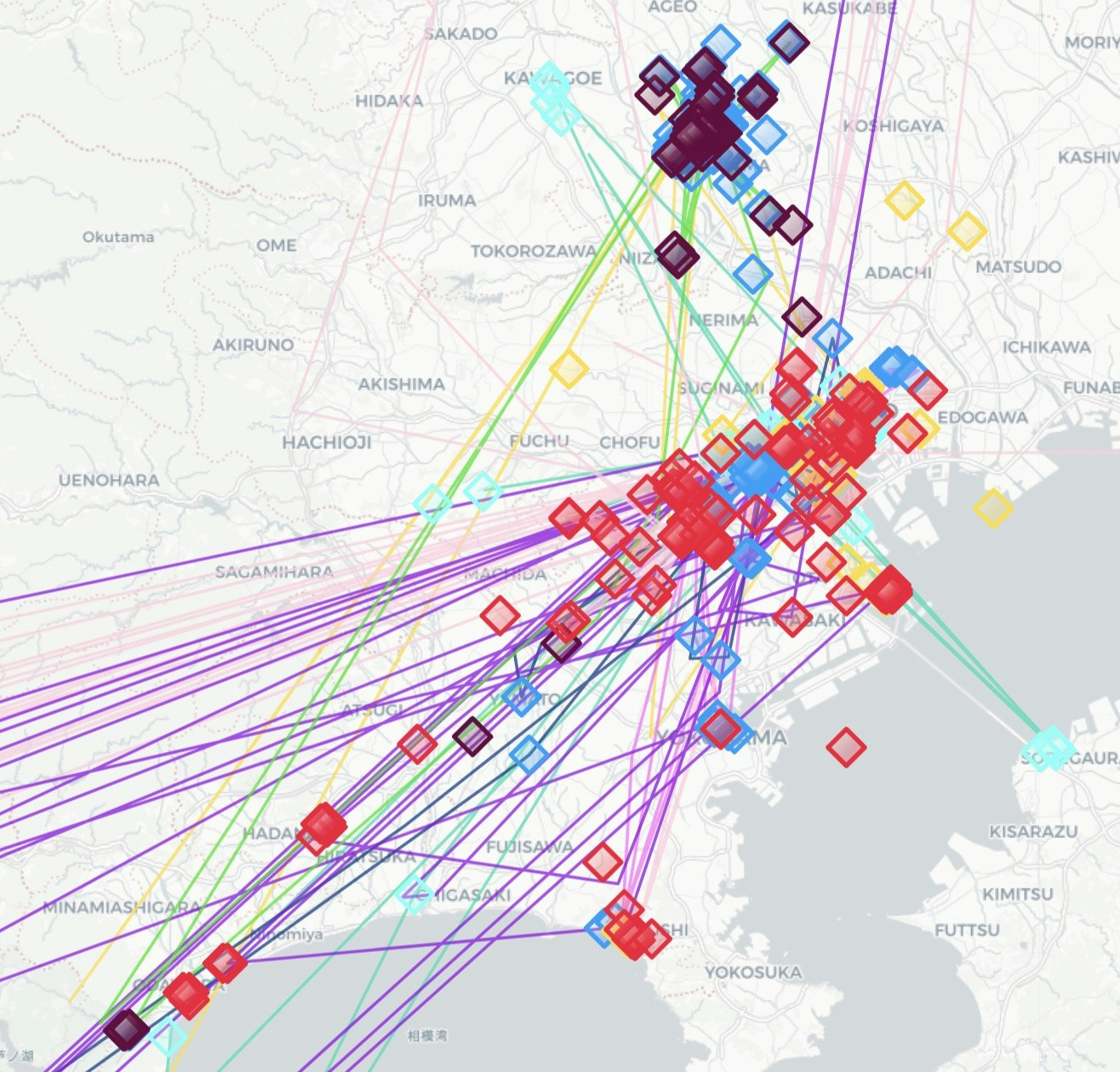
ポイント同士を繋ぐ線も出力されます。
滞在検出前と滞在検出後のデータポイントを比較
-
インプットデータ:特定のユーザーの緯度経度データ(以降元データとする)
-
アウトプットデータ:元データに対し、パラメータleaving_time=20(min)でdetection.stay_locations関数の処理を行なった後のtdfデータ
-
データ数について
| データ | インプットデータ(レコード数 ) | アウトプットデータ(レコード数) |
|---|---|---|
| 全データ | 15185 | 1574 |
| 特定のユーザーデータ | 722 | 105 |
- データをのマッピングについて
-
元データをマッピングした図
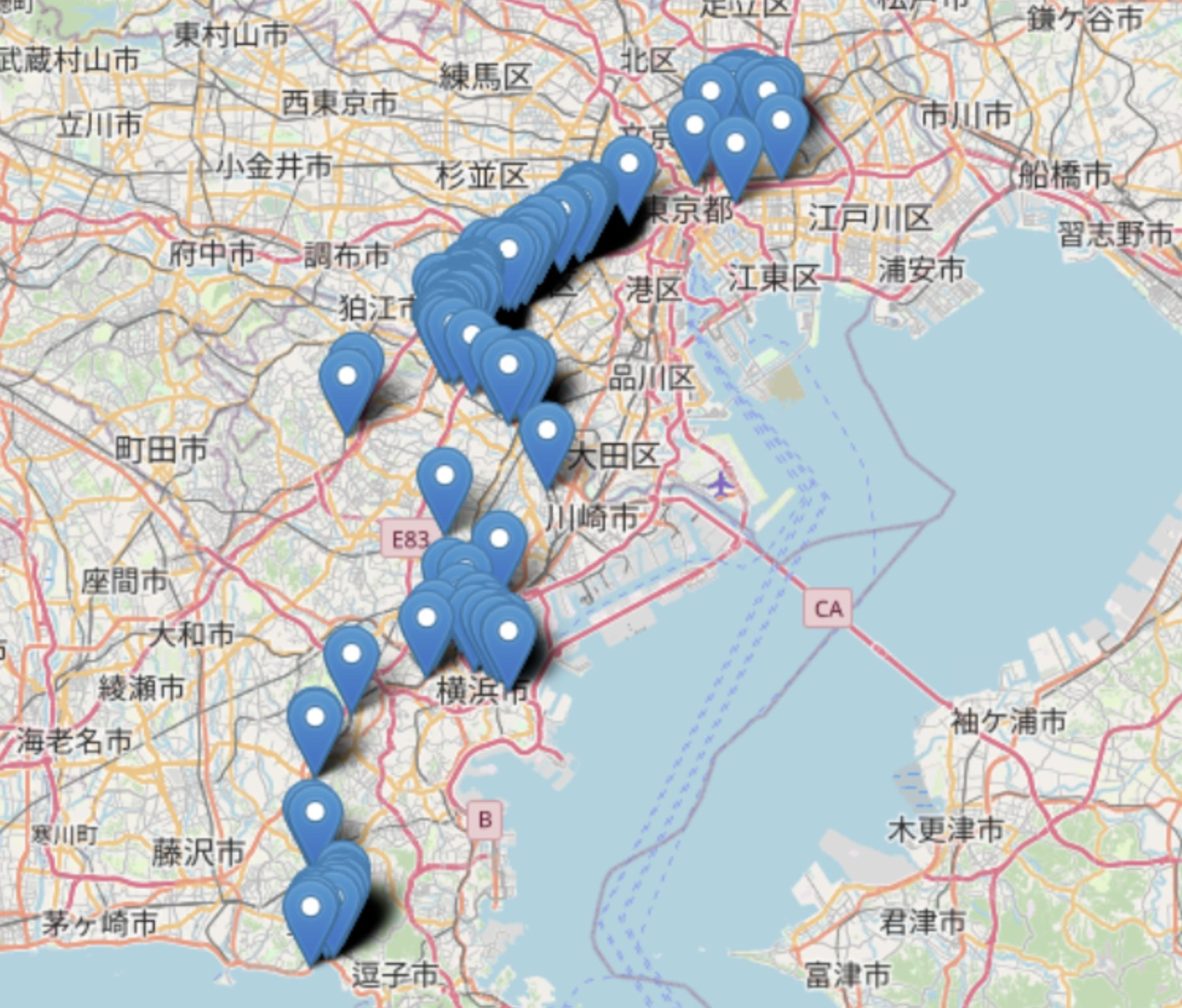
-
アウトプットデータを可視化用関数plot_trajectoryを使用してマッピングした図
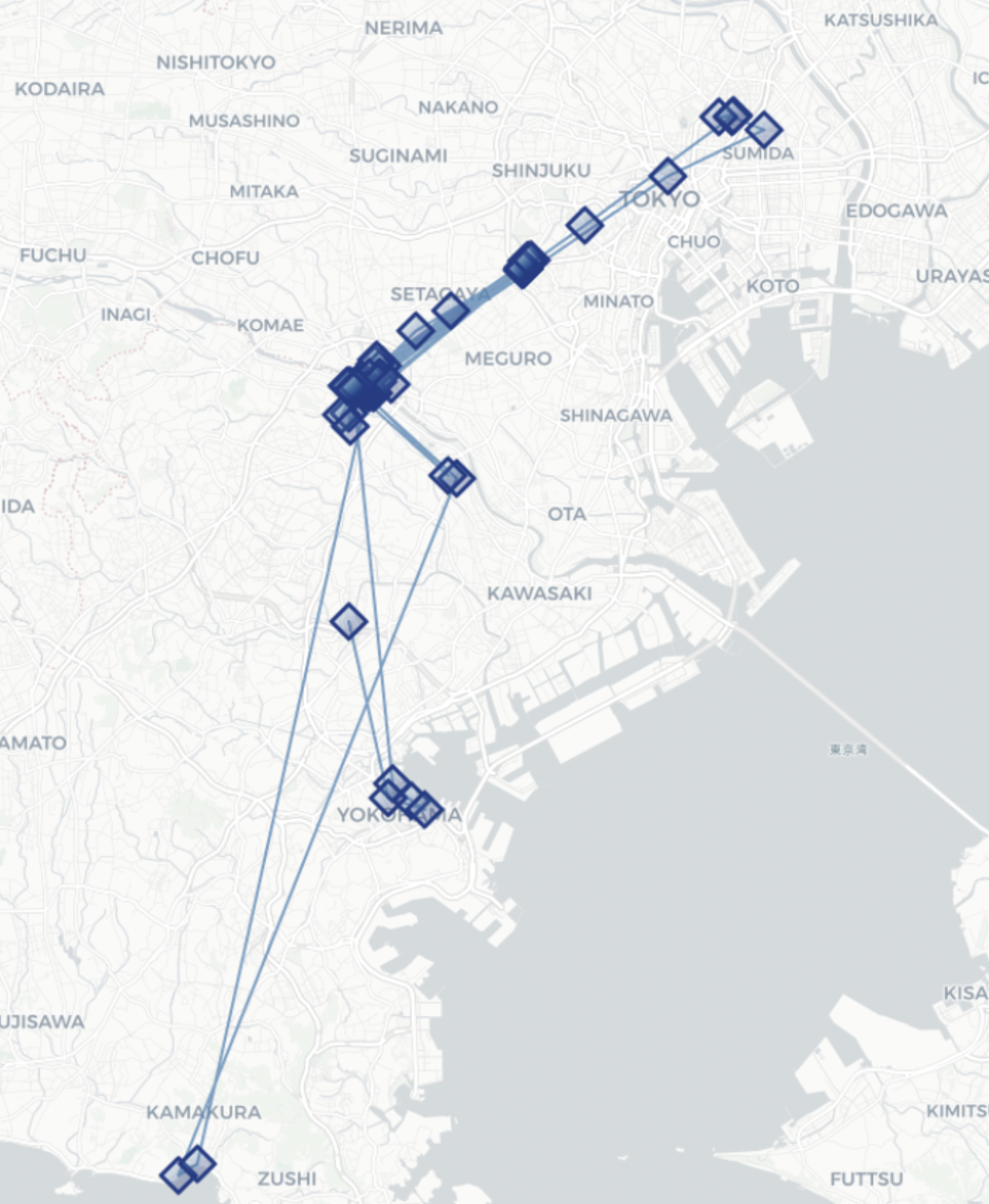
-
パラメータ(leaving_time)で指定した時間以上(デフォルト:20min)滞在した場所が可視化できます。
パラメータの変化による出力結果の違い(滞在検出処理)
-
inputデータ=全体データ(leaving_timeのみ変更)
leaving_time(min) 全体のデータ数 検出された滞在判定の数 30 15185 1347 20(default) 15185 1574 15 15185 1805 10 15185 2365 -
inputデータ=特定のユーザーデータ(パラメータのleaving_timeのみ変更)
leaving_time(min) 全体のデータ数 検出された滞在判定の数 30 722 94 20(default) 722 105 15 722 125 10 722 157 -
パラメータごとのデータポイントのマッピング結果を比較してみました。
(滞在検出処理,leaving_timeのみ変更)-
leaving_time=30min(output件数:94)
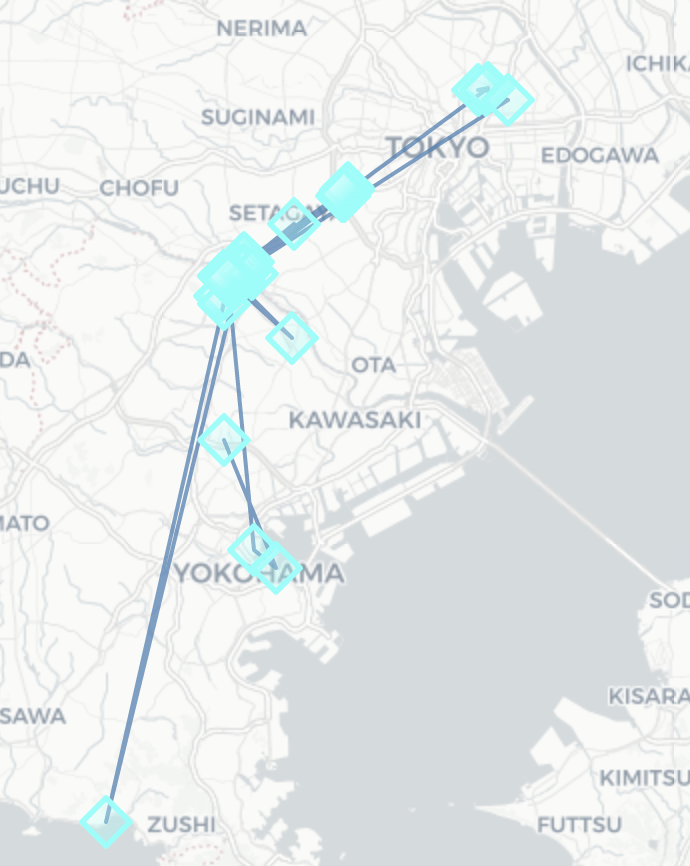
-
leaving_time=20min(output件数:105)
-
leaving_time=15min(output件数:125)
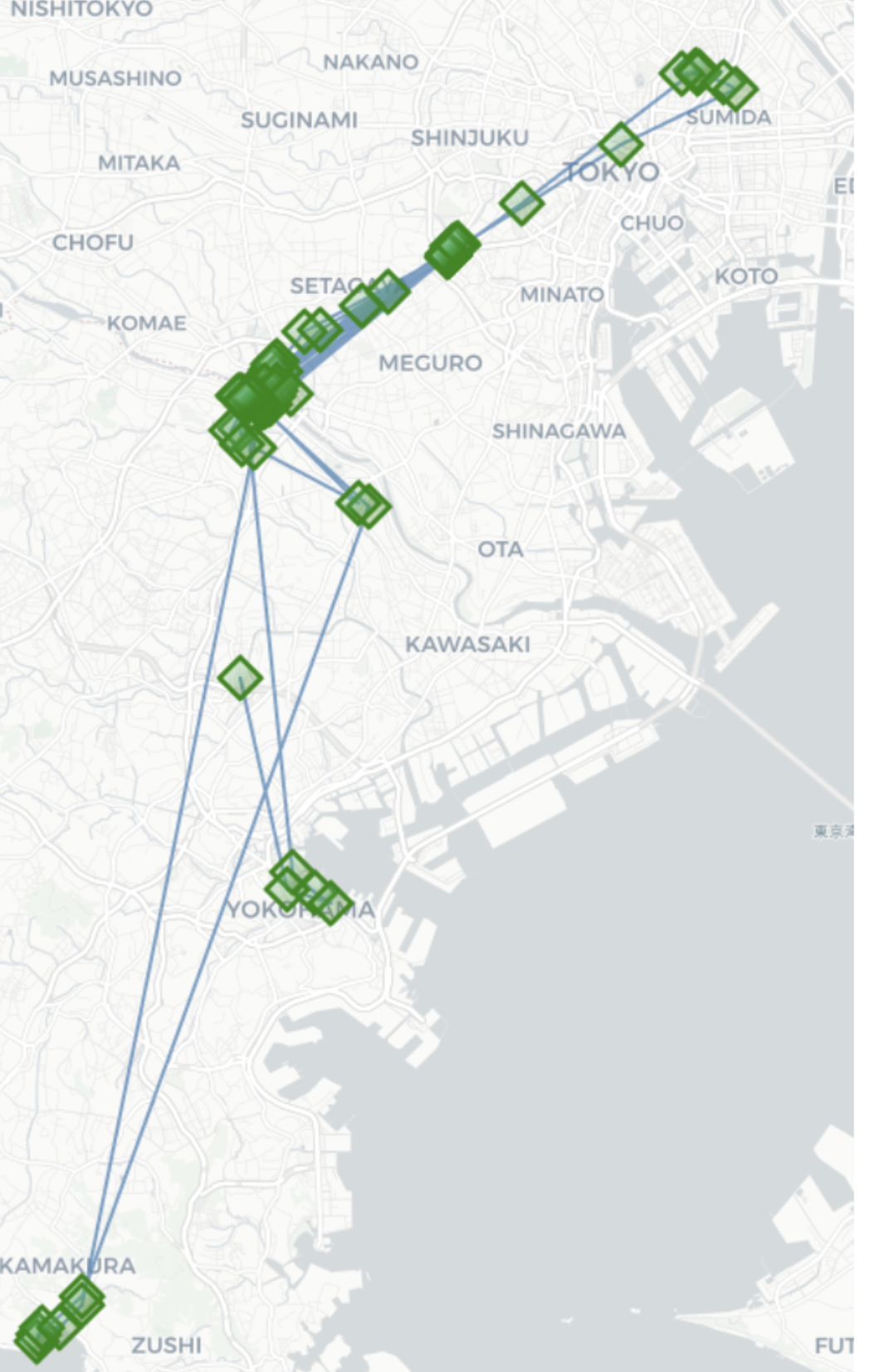
-
leaving_time=10min(output件数:157)
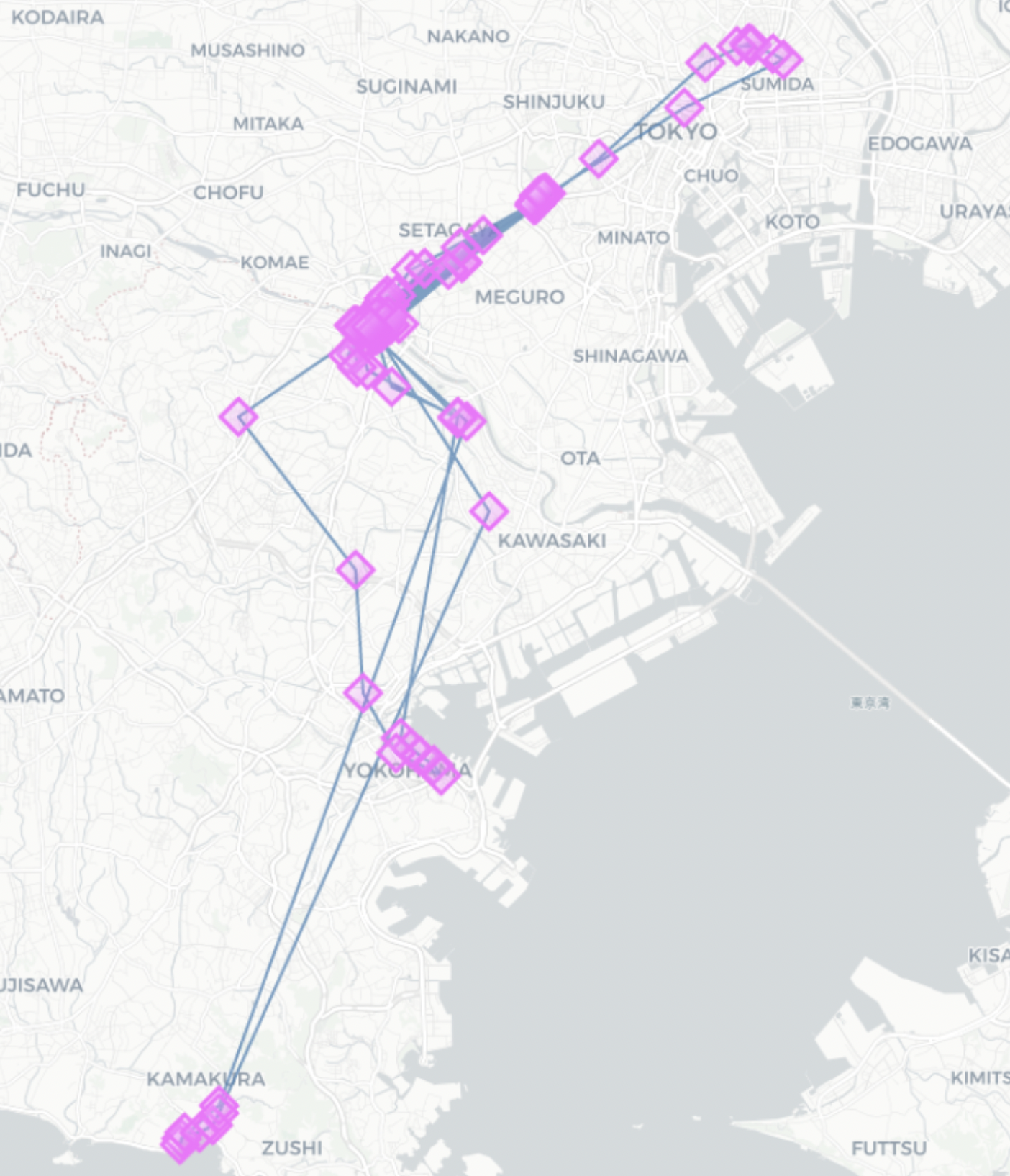
-
- inputデータ=特定のユーザーデータ(stop_radius_factor * spatial_radius_kmを変更)
| stop_radius_factor | spatial_radius_km | stop_radius_factor * spatial_radius_km | 全体のデータ数 | 検出された滞在判定の数 |
|---|---|---|---|---|
| 0.5(default) | 0.2(default) | 0.1(default) | 722 | 105 |
| 0.5 | 0.5 | 0.25 | 722 | 73 |
| 1.0 | 0.2 | 0.2 | 722 | 105 |
| 0.8 | 0.2 | 0.16 | 722 | 105 |
| 1.0 | 1.0 | 1.0 | 722 | 63 |
→ データ数が少ないと小さいパラメーター調整では検出される滞在の数は変わらないようです。
-
パラメータをごとのデータポイントのマッピング結果を比較してみました。
(滞在検出処理, stop_radius_factor, spatial_radius_kmを変更) -
stop_radius_factor=0.5, spatial_radius_km=0.2(output件数:105)
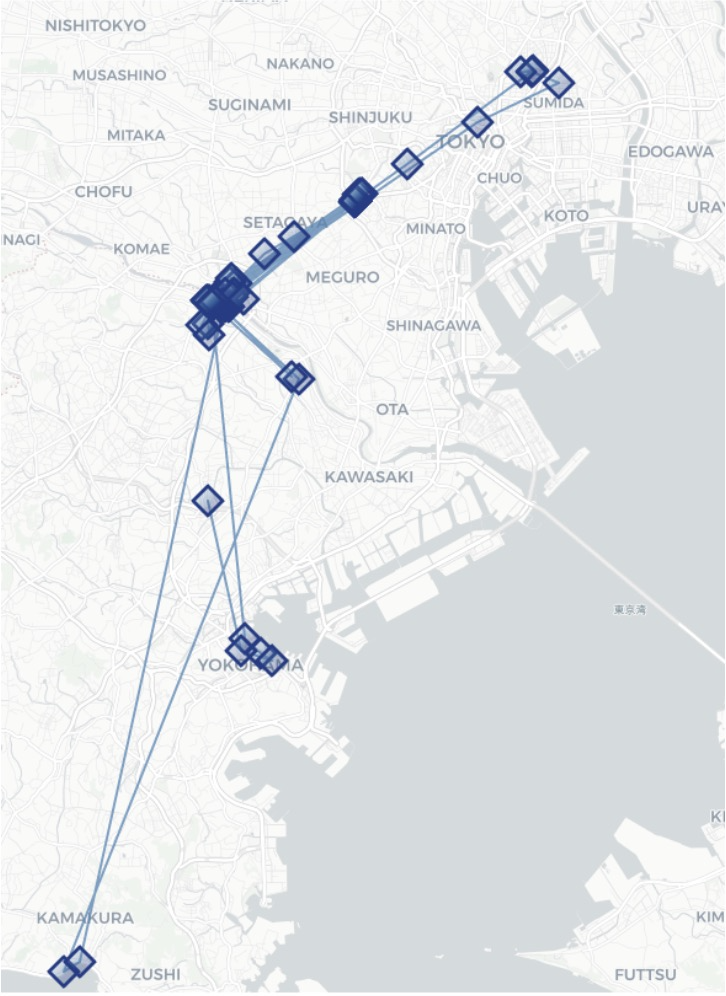
-
stop_radius_factor=0.5, spatial_radius_km=0.5(output件数:73)
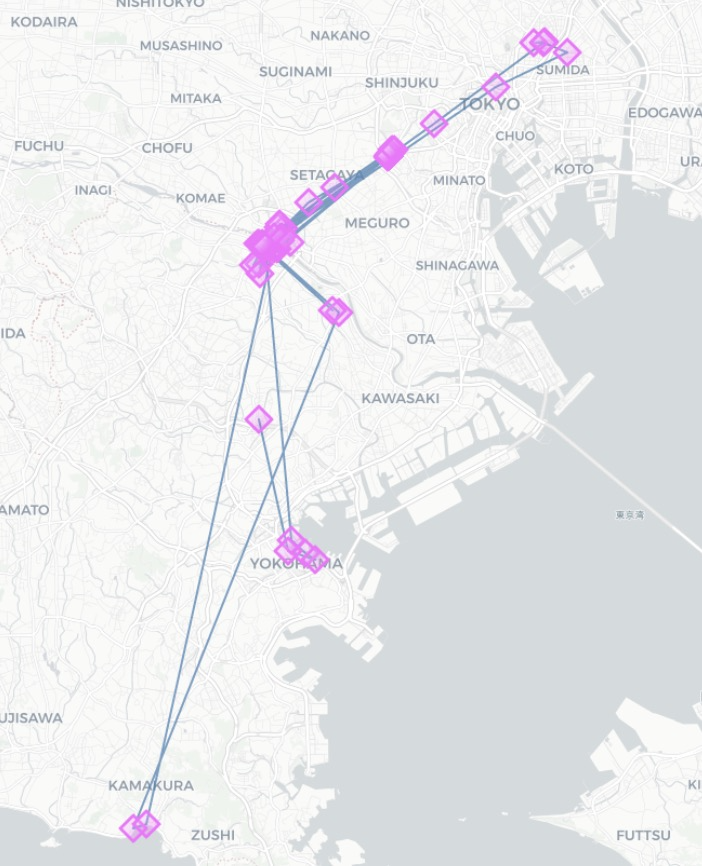
-
stop_radius_factor=1.0, spatial_radius_km=0.2(output件数:105)
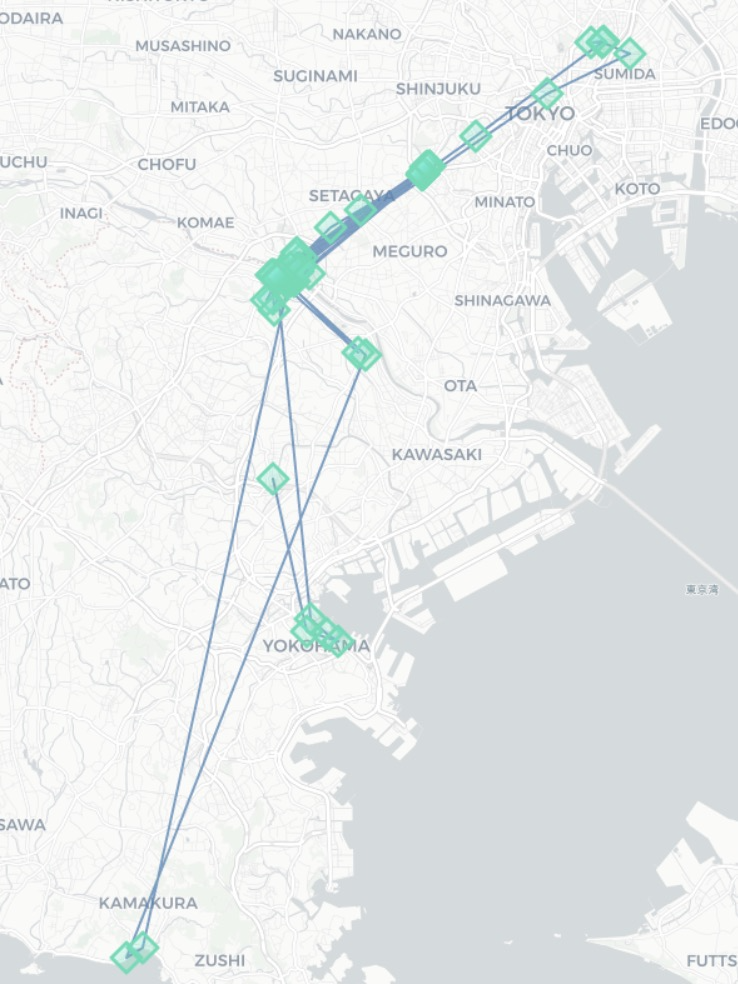
-
stop_radius_factor=0.8, spatial_radius_km=0.2(output件数:105)
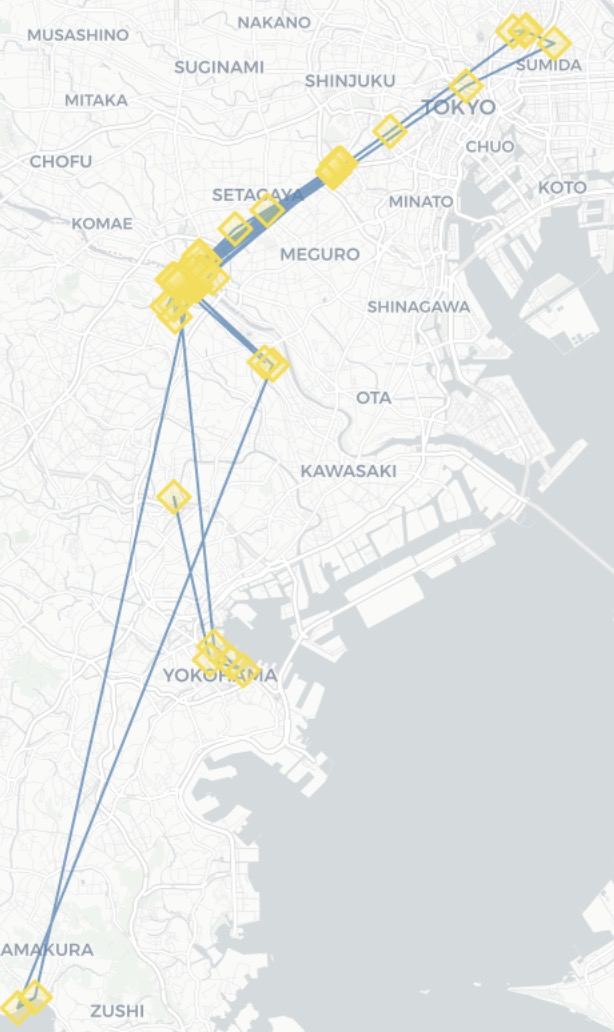
-
stop_radius_factor=1.0, spatial_radius_km=1.0(output件数:63)
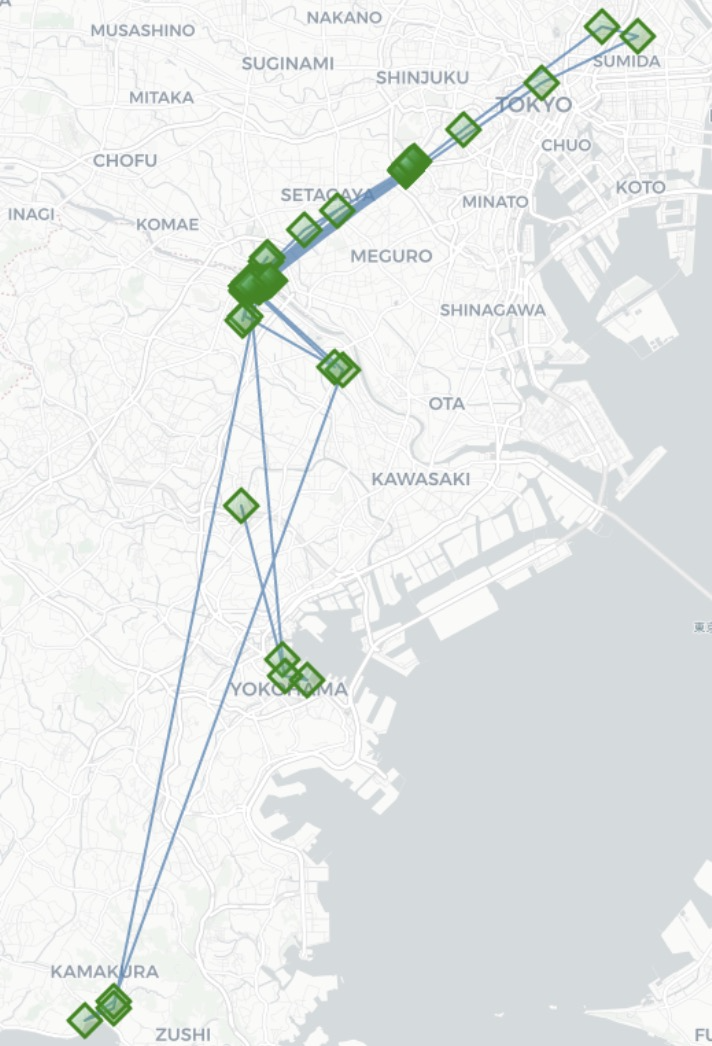
前処理後に滞在判定処理を行う
滞在判定処理を行う前にfiltering.filter関数(フィルタ処理)や、compression.compress関数(軌道圧縮処理)を使用して前処理を行うことが想定されています。
実際に前処理後に滞在判定をすることで起こるデータの変化を検証してみました。
-
filtering.filter処理
-
inputデータに全体データを入れた場合(パラメータ:default)
全体のデータ数 filter処理後のデータ数 検出された滞在判定の数 filter処理なしの場合の滞在判定数 15185 8634 1568 1574 - inputデータにユーザーデータを入れた場合(パラメータ:default)
全体のデータ数 filter処理後のデータ数 検出された滞在判定の数 filter処理なしの場合の滞在判定数 722 432 105 105 - 全体のデータ数が少ない場合でもデータ量を削減して、なおかつ滞在の判定はしっかりとできるようになっていました。
- データが多い場合はfilter前にはなかった滞在場所も判定できるようになっています。
- 外れ値を含むデータがfilterされたことで滞在の判定が適応されるデータが増えたのではないかと思いました。
-
-
inputデータにユーザーデータを入れた場合のデータマッピング結果(パラメータ:default)
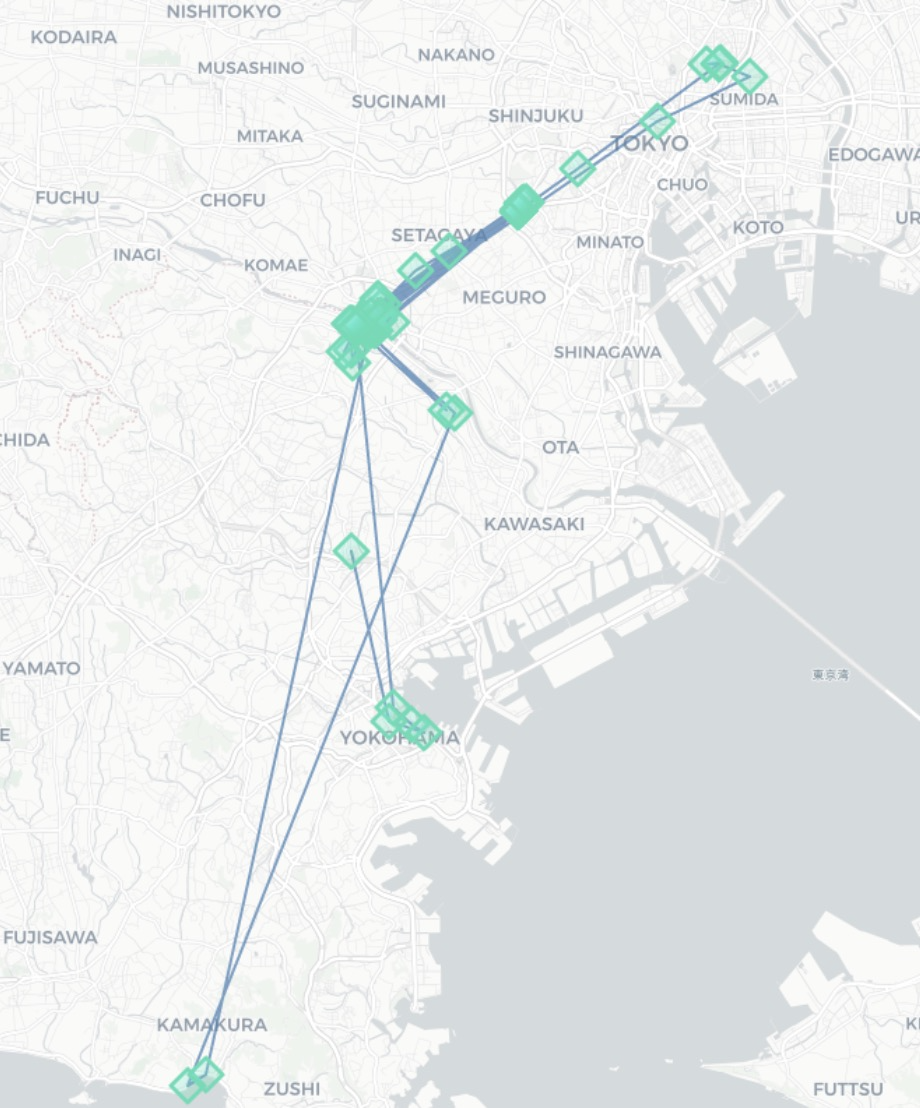
-
compression.compress処理
-
inputデータに全体データを入れた場合(パラメータ:default)
全体のデータ数 compress処理後のデータ数 検出した滞在判定数 compress処理なしの場合の滞在判定数 15185 8130 1574 1574 -
inputデータにユーザーデータを入れた場合(パラメータ:default)
全体のデータ数 compress処理後のデータ数 検出された滞在判定の数 compress処理なしの場合の滞在判定数 722 385 105 105
-
-
inputデータにユーザーデータを入れた場合のデータマッピング結果(パラメータ:default)
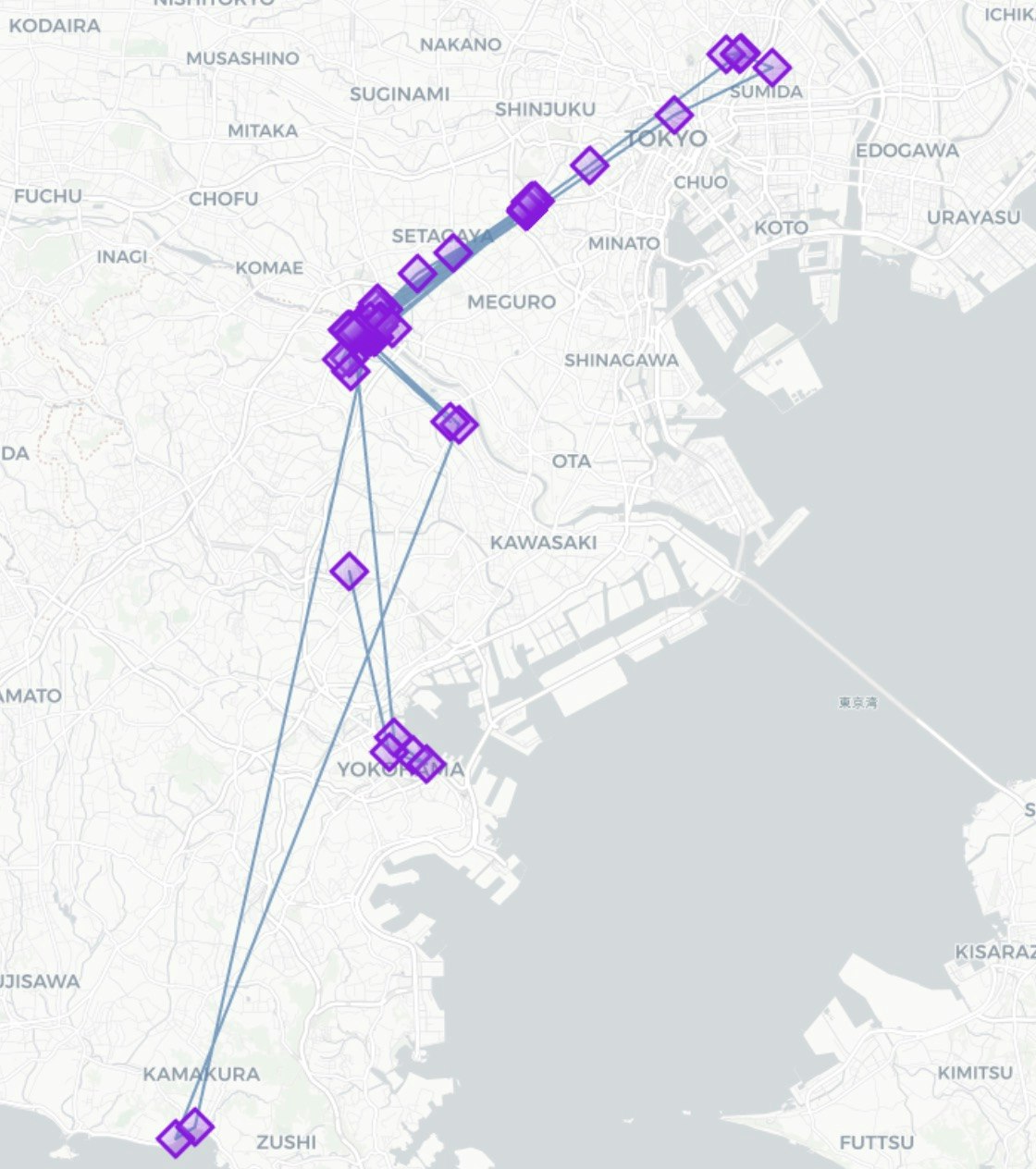
clustering.cluster(クラスタリング処理)
概要
stay_locationsで滞在を検出したデータから異なる時間の同じ場所への訪問をクラスタリングします。
訪問頻度によってラベルが付与されます。
inputに必要なデータとパラメータ、outputされるデータ
-
inputデータ
- tdf: 停止場所の情報が含まれる緯度経度データ(stay_locationsの出力結果)
※stop_detectionで滞在判定処理を行った後のデータをinputする必要があります
- tdf: 停止場所の情報が含まれる緯度経度データ(stay_locationsの出力結果)
-
パラメータ
- cluster_radius_km(default:0.1km): 近傍とみなされるサンプル間の最大距離
- min_samples(default:1): クラスターを形成するためのポイントの最小値
-
inputするデータ例
- データ型はTrajDataFrame。
- データ型はTrajDataFrame。
-
outputするデータ
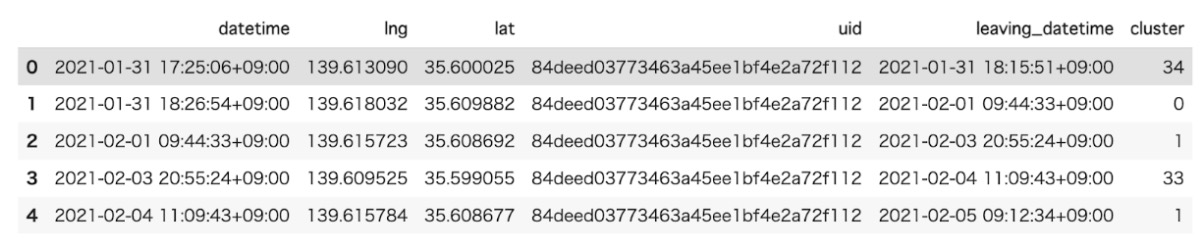
クラスタラベル(cluster)の列をもつ緯度経度データが出力され、同じクラスターに属するレコードは同じラベルをもちます。
ラベルは訪問頻度に応じたクラスタのランクに対応する整数になっていて、最も訪問されたクラスタはラベル0、その次に多く訪問されたクラスタはラベル1...と続いていきます。
入力したデータのカラムにclusterが追加されています。
クラスタリング結果を可視化する
- cluster = 0に絞って位置データを可視化してみる。
- 特定ユーザーのcluster=0を地図にプロットした図
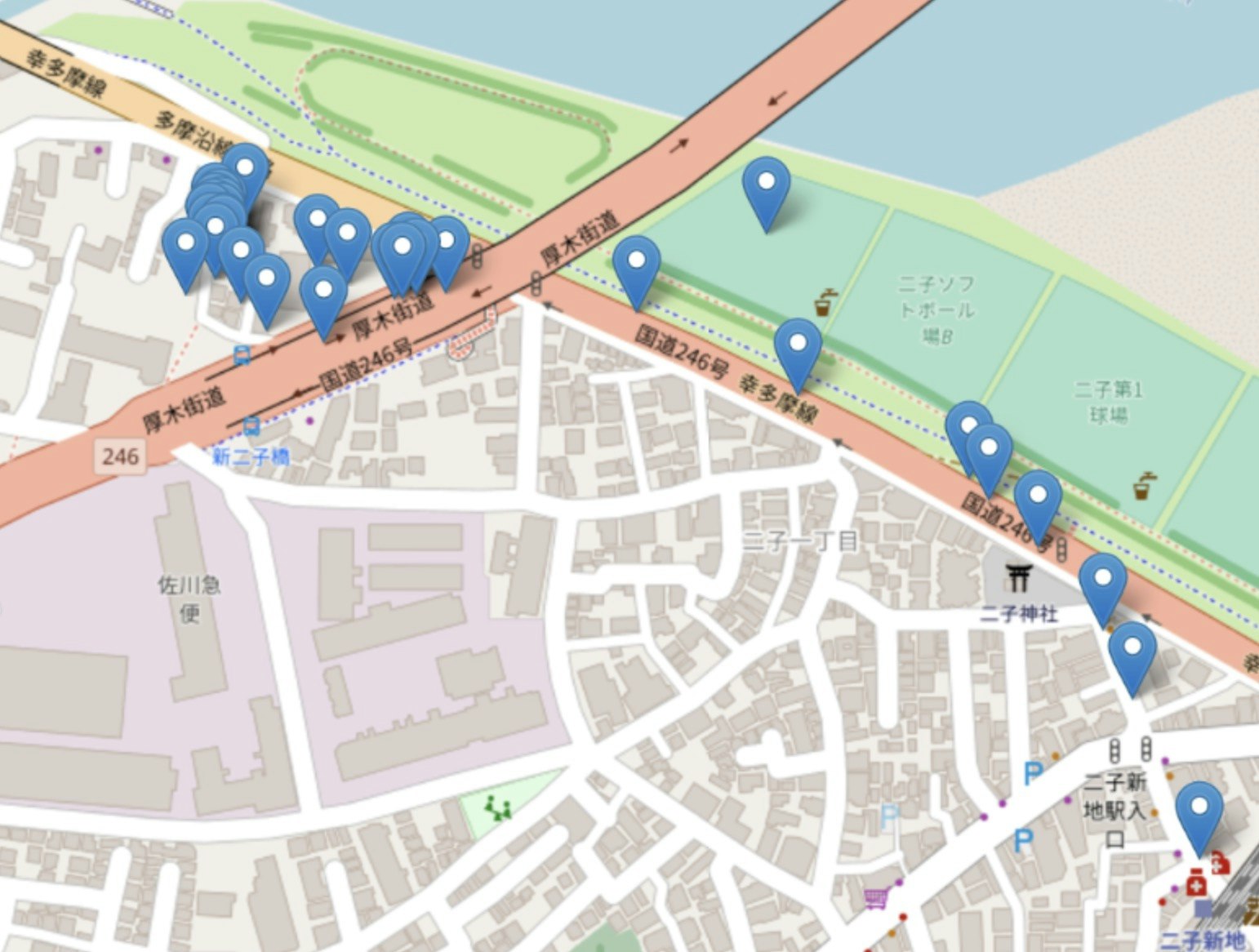
- 特定ユーザーのcluster=0を地図にプロットした図
→ 指定したユーザーの自宅付近から最寄り駅がプロットされていました。
→ よく行く場所という観点では矛盾はないと感じました。
→ バラバラのGPSデータを訪れられる頻度でクラスタ分けすることができるのは、データ全体の内容を把握するのに役立ちそうだと感じました。
5. シリーズ記事
scikit-mobilityについて、シリーズで記事を投稿しています。
シリーズの記事もぜひ読んでいただけると嬉しいです。
前回の記事はこちらです。
最後に
私たちの会社、ナイトレイでは一緒に事業を盛り上げてくれるGISチームメンバーを募集しています!
現在活躍中のメンバーは開発部に所属しながらセールス部門と密に動いており、
慣れてくれば顧客とのフロントに立ち進行を任されるなど、顧客に近い分やりがいを感じやすい
ポジションです。
このような方は是非Wantedlyからお気軽にご連絡ください(もしくは recruit@nightley.jp まで)
✔︎ GISの使用経験があり、観光・まちづくり・交通系などの分野でスキルを活かしてみたい
✔︎ ビッグデータの処理が好き!(達成感を感じられる)
✔︎ 社内メンバーだけではなく顧客とのやり取りも実はけっこう好き
✔︎ 地理や地図が好きで仕事中も眺めていたい
一つでも当てはまる方は是非こちらの記事をご覧ください 。
二つ当てはまった方は是非エントリーお待ちしております(^ ^)
「位置情報×モビリティ.まちづくりetc事業領域拡大の為GISエンジニア募集」
▼ナイトレイとは?