今回は、ゲームソフトの売れ行きを予測するモデルをVARISTAで生成してみたいと思います。
下記のCodexaの記事を参考にしてVARISTAで予測モデルの構築までやってみました。
記事ではAWS SageMakerを使っていますがVARISTAでやってみます。
ゲームソフトの売行きをXGBoostで予測してみた【Amazon SageMaker ノートブック+モデル訓練+モデルホスティングまで】
ただ、若干データの整形でコードを書く必要があったので、そこだけGoogle Colabratoryで行っています。
(一応、 Pythonはかじったくらいの知識レベルです。)
所要時間
実際の操作は10分程度
学習はレベル1で1、2分、レベル3で1.5時間程度
発生する費用
VARISTAのFreeアカウントであれば無料
データのダウンロード
Kaggleの下記ページからダウンロードします。
Video Game Sales with Ratings
Kaggleに記載されていたデータの説明
このデータセットはMetacriticのスクレイピングでしたものです。
残念ながら、Metacriticはプラットフォームのサブセットをカバーしているだけなので、集計データが不足しています。
また、一部のゲームにおいて、以下で説明する変数に欠損があります。
Critic_score - Metacriticのスタッフが集計した批評家スコアです。
Critic_count - Critic_score(批評家スコア)の算出に使用した批評家の数。
User_score - Metacriticの購読者によるスコア
Usercount - ユーザースコアを投票したユーザーの数
Developer - ゲーム開発会社
Rating - ESRBの評価
と言うわけで、結構欠損があったり全てのゲームの販売データではないという点だけご留意ください。
データの加工
今回は、参考にした記事の通り若干データの加工をします。
販売数100万件以上をヒットとして定義しているので、100万件以上をYes、それ以外はNoとして新しく列を追加します。
ローカルに環境を作るのがあまり好きではないので、Google Colaboratoryでこんなコードをを書いてデータを加工します。
import pandas as pd
filename = './sample_data/kaggle/Video_Games_Sales_as_at_22_Dec_2016.csv'
data = pd.read_csv(filename)
# ターゲットを設定
# Global_Salesで1(100万本)以上の売上を基準としてyを作成
data['y'] = 'no'
data.iloc[data['Global_Sales'] > 1, 'y'] = 'yes
pd.set_option('display.max_rows', 20)
# データを表示
data
# 加工したデータを新しいCSVとして保存
data.to_csv('sample_data/kaggle/Add_y_Column_Video_Games_Sales.csv')
一番右の列にyが追加されていることがわかります。

上記コードを実行すると、「Add_y_Column_Video_Games_Sales.csv」というファイルが生成されますので、そちらをダウンロードします。
VARISTAにデータのアップロード
VARISTAで新しいプロジェクトを作成して、作成したAdd_y_Column_Video_Games_Sales.csvをアップロードします。
今回、予測する列はyを選択します。
データの確認
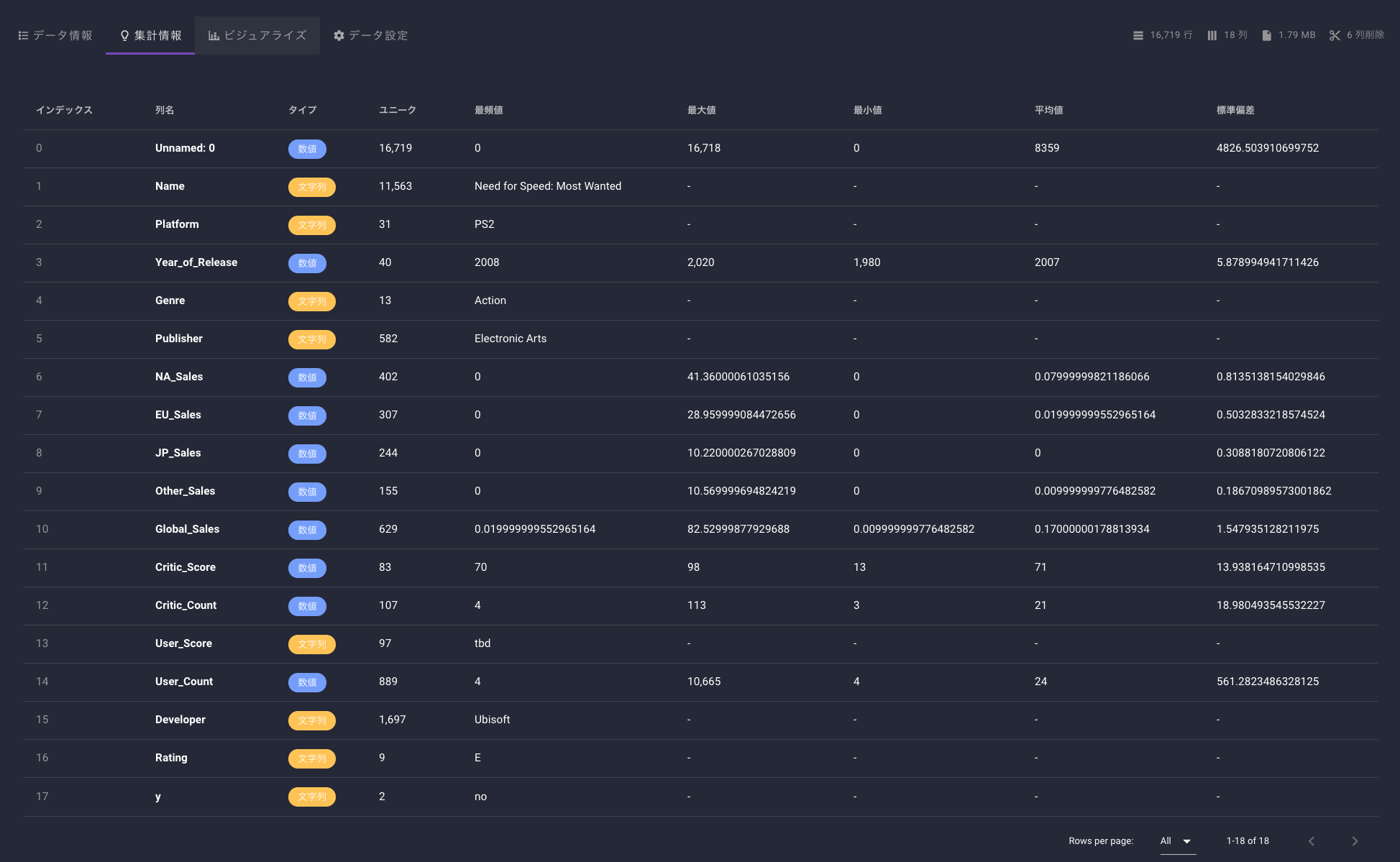
データの概要はこのようになっています。
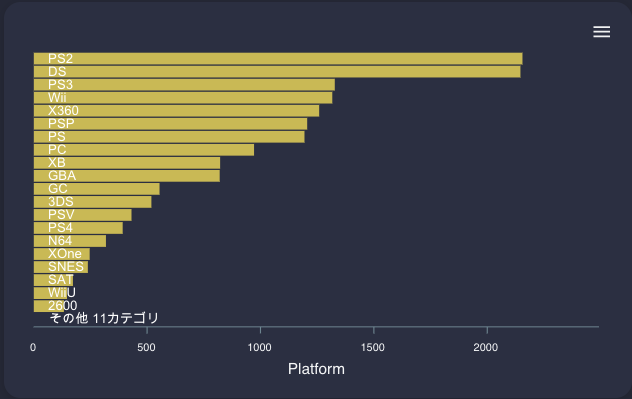
リリース本数は2008-2010がピークのようです。

プラットフォームはPS2, DSが多く、その次にPS3が来ています。
スマホは含まれていないようです。
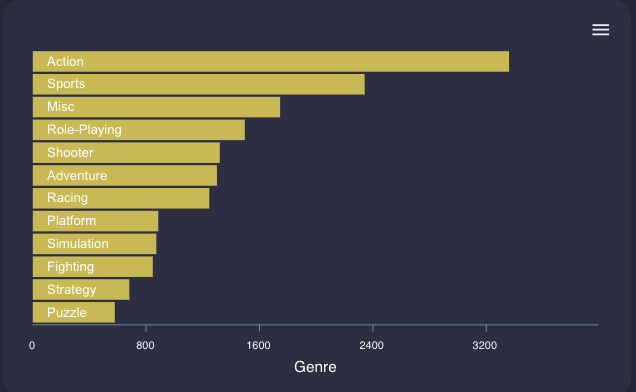
ジャンルの分布はこのようになっています。
Publishしている本数はEAがトップのようです。
日本のゲーム会社が多く入っているのは嬉しい限りです。

肝心のヒットしたかどうかについては、2,057 / 16,719本となかなかの狭き門です。
私も以前スマホゲーム開発をしていましたがミリオンヒットは資本力があるか運ゲーという印象でした。ましてや、こちらのデータはコンシューマー機なので大変ですね。。

相関を見る
yes (黄色):ミリオンヒット以上
no (水色):ミリオンヒット未達
Platformは、NESとGBがミリオンヒット率が高いです。
これらのゲーム機が流行っていた時代は他にそこまで選択肢がなかったからでしょうか。。?

Publisher / Developer
どうしても日本人なのでNintendoやSquareEnixなどに目が行ってしまいますが、このデータに載っている開発した全てのタイトルがミリオンヒットというのはすごいですね。
このグラフから勝手に想像しますが、任天堂は企画開発が得意で、他社が開発したゲームの販売はあまり得意ではないのかもしれません。

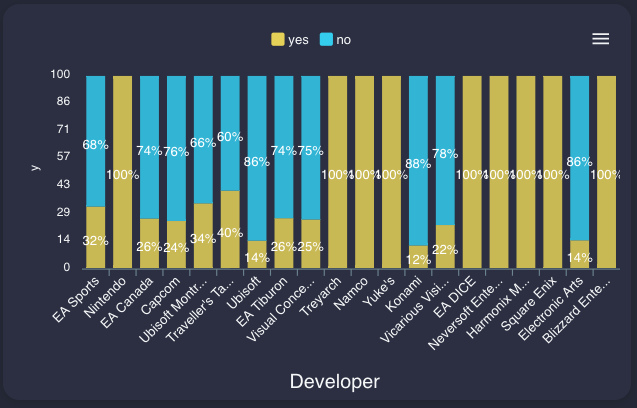
PublisherとDeveloperの違いは、Publisherはゲームを販売提供する企業で、Developerはゲームを開発する企業です。
DeveloperがPublisherを兼ねていることもあります。
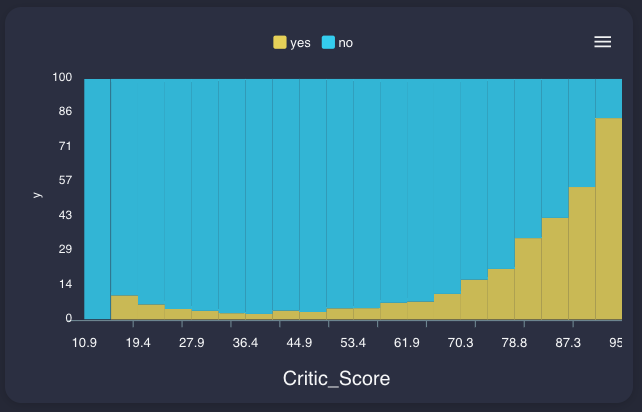
Critic_score & Critic_count
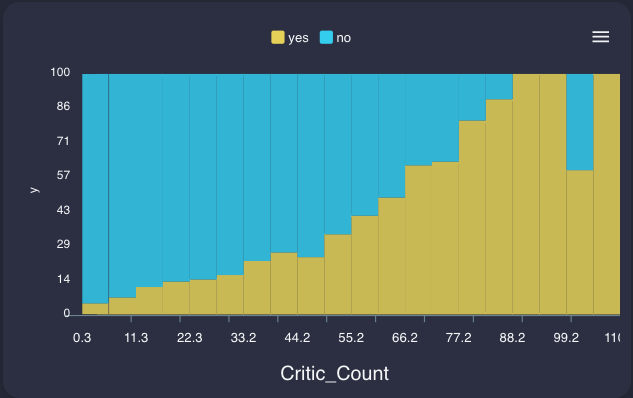
User_score


学習
学習はレベル3で行いました。
細かいパラメータの設定は、タイタニック以降こんな感じでやっています。
レベル1学習は数分で完了しますが、さすがにこの設定にすると探索するパラメタの数がおおいのか1時間ちょいかかりました。

あと、データセットから予測列に直接関係してしまう列(Unnamed0, NA_Sales, EU_Sales, JP_Sales, Other_Sales, Global_Sales)はオフにして学習しました。

結果の確認
スコアを確認するとこのような感じです。

混同行列は、こんな感じで表示されています。103件を検証のテストデータとして利用して、82件は的中して、21件はヒットしないと予測したようです。

あと、今回は学習データに偏りがあったと怒られまいたね。
こればかりは、アンダーサンプリングなどをしてデータ量を調整するしかないですが、実際にやってどうなるか試したいところです。
また時間をつくって試してみます。
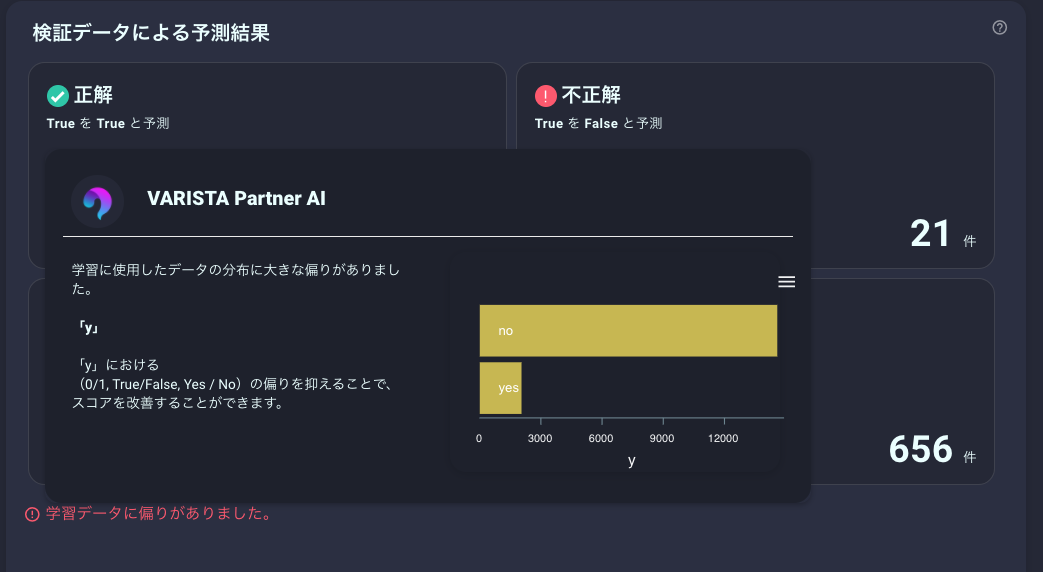
Yes / Noと判断する値も自動調整してくれるようです。
このケースでは、0.222を超えているとYESと判断するようです。

実際にテストデータがないので、本来であれば学習データからピックアップして作成しますが、
今回は簡易的にみてみたので、VARISTAが自動で分割したデータを使って検証してみました。
もし、この記事を読んでVARISTA使ってみようと思った人は是非以下のリンクからお願いします!
私にもあなたにも7$のクレジットがたまります!m(_ _)m
https://console.varista.ai/welcome/jamaica-draft-coach-cup-blend
参考記事
ゲームソフトの売行きをXGBoostで予測してみた【Amazon SageMaker ノートブック+モデル訓練+モデルホスティングまで】