はじめに
最近、所属しているコミュニティでクローリングが流行っているので自分もやってみたくなりました。
まず、対象となる画面です。
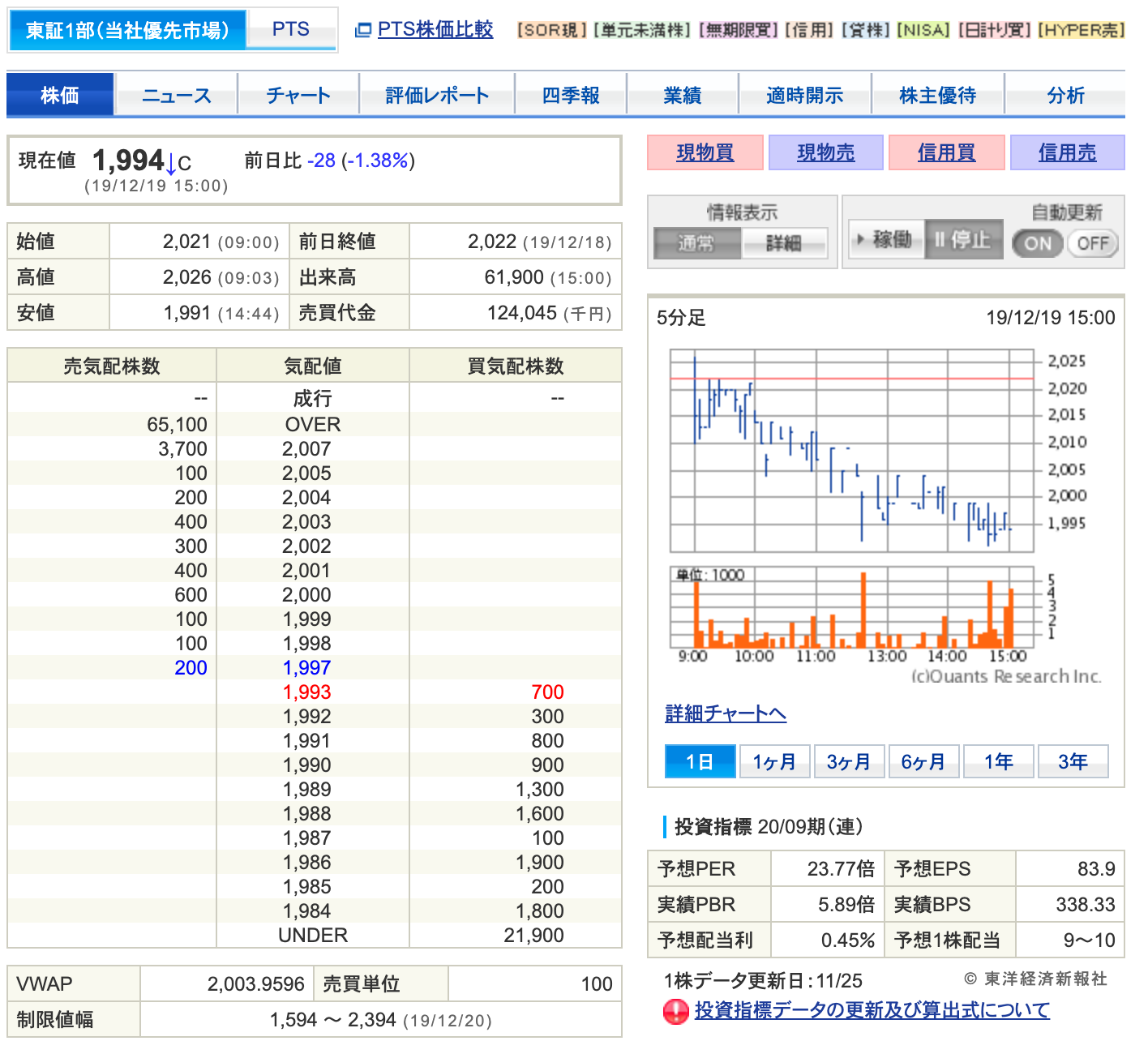
勝手にクローリングして怒られないか?という点に関しては、どこぞのサイトで商用利用しなければ問題ないというのを見た気がするので大丈夫だと信じたいです。
では早速この画面の投資指標をクローリングしていきたいと思います。
実行環境、ツール
実行環境は以下
$ sw_vers
ProductName: Mac OS X
ProductVersion: 10.15.1
BuildVersion: 19B88
$ python --version
Python 3.7.4
ツールはBeautifulSoupを使用していきます。
パッケージのインストールは pip コマンドから。
$ pip install beautifulsoup4
その他のパッケージはサイトアクセス用にrequestsを使用します。
ログイン、ページアクセス
クローリング対象の画面はログインが必要なのでログイン処理を実装します。
合わせて対象画面へのアクセス処理も実装しちゃいます。
こんな感じです。
class Scraper():
def __init__(self, user_id, password):
self.base_url = "https://site1.sbisec.co.jp/ETGate/"
self.user_id = user_id
self.password = password
self.login()
def login(self):
post = {
'JS_FLG': "0",
'BW_FLG': "0",
"_ControlID": "WPLETlgR001Control",
"_DataStoreID": "DSWPLETlgR001Control",
"_PageID": "WPLETlgR001Rlgn20",
"_ActionID": "login",
"getFlg": "on",
"allPrmFlg": "on",
"_ReturnPageInfo": "WPLEThmR001Control/DefaultPID/DefaultAID/DSWPLEThmR001Control",
"user_id": self.user_id,
"user_password": self.password
}
self.session = requests.Session()
res = self.session.post(self.base_url, data=post)
res.encoding = res.apparent_encoding
def financePage_html(self, ticker):
post = {
"_ControlID": "WPLETsiR001Control",
"_DataStoreID": "DSWPLETsiR001Control",
"_PageID": "WPLETsiR001Idtl10",
"getFlg": "on",
"_ActionID": "stockDetail",
"s_rkbn": "",
"s_btype": "",
"i_stock_sec": "",
"i_dom_flg": "1",
"i_exchange_code": "JPN",
"i_output_type": "0",
"exchange_code": "TKY",
"stock_sec_code_mul": str(ticker),
"ref_from": "1",
"ref_to": "20",
"wstm4130_sort_id": "",
"wstm4130_sort_kbn": "",
"qr_keyword": "",
"qr_suggest": "",
"qr_sort": ""
}
html = self.session.post(self.base_url, data=post)
html.encoding = html.apparent_encoding
return html
def get_fi_param(self, ticker):
html = self.financePage_html(ticker)
soup = BeautifulSoup(html.text, 'html.parser')
print(soup)
userIDとpassword,証券番号を引数に実行します。
ログインとページアクセスの処理はについては簡単に。
URLから取得したポスト情報とrequestsパッケージを使用してあーだこーだしてます。
ちゃんとアクセスできたかを確認するため、アクセス結果をBeautifulSoup(html.text, 'html.parser')関数を使用してテキスト出力してみました。
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html lang="ja">
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>
<meta content="text/css" http-equiv="Content-Style-Type"/>
<meta content="text/javascript" http-equiv="Content-Script-Type"/>
<meta content="IE=EmulateIE8" http-equiv="X-UA-Compatible"/><!--gethtmlコンテンツ開始-->
<!-- header_domestic_001.html/// -->
・
・
・
<h4 class="fm01"><em>投資指標</em> 20/09期(連)</h4>
</div>
</div>
<div class="mgt5" id="posElem_19-1">
<table border="0" cellpadding="0" cellspacing="0" class="tbl690" style="width: 295px;" summary="投資指標">
<col style="width:75px;"/>
<col style="width:70px;"/>
<col style="width:80px;"/>
<col style="width:65px;"/>
<tbody>
<tr>
<th><p class="fm01">予想PER</p></th>
<td><p class="fm01">23.86倍</p></td>
<th><p class="fm01">予想EPS</p></th>
<td><p class="fm01">83.9</p></td>
</tr>
<tr>
<th><p class="fm01">実績PBR</p></th>
<td><p class="fm01">5.92倍</p></td>
<th><p class="fm01">実績BPS</p></th>
<td><p class="fm01">338.33</p></td>
</tr>
<tr>
<th><p class="fm01">予想配当利</p></th>
<td><p class="fm01">0.45%</p></td>
<th><p class="fm01">予想1株配当</p></th>
<td><p class="fm01">9〜10</p></td>
・
・
・
</script>
<script language="JavaScript" type="text/javascript">_satellite.pageBottom();</script></body>
</html>
うまく対象画面にアクセスし、そのHTMLをテキストとして取得する事ができました。
HTMLからブロックごとに取得
HTMLをテキストとして取得する事はできましたが、今のままではタグやらCSSやらがたくさん入っています。
そこで、必要な部分を順番に抽出していこうと思います。
まずは投資指標が含まれるブロックを取得してみます。
BeautifulSoupのfind_all()関数を使用して特定のブロックを取得します。
投資指標は画面上だと以下のブロックに含まれます。
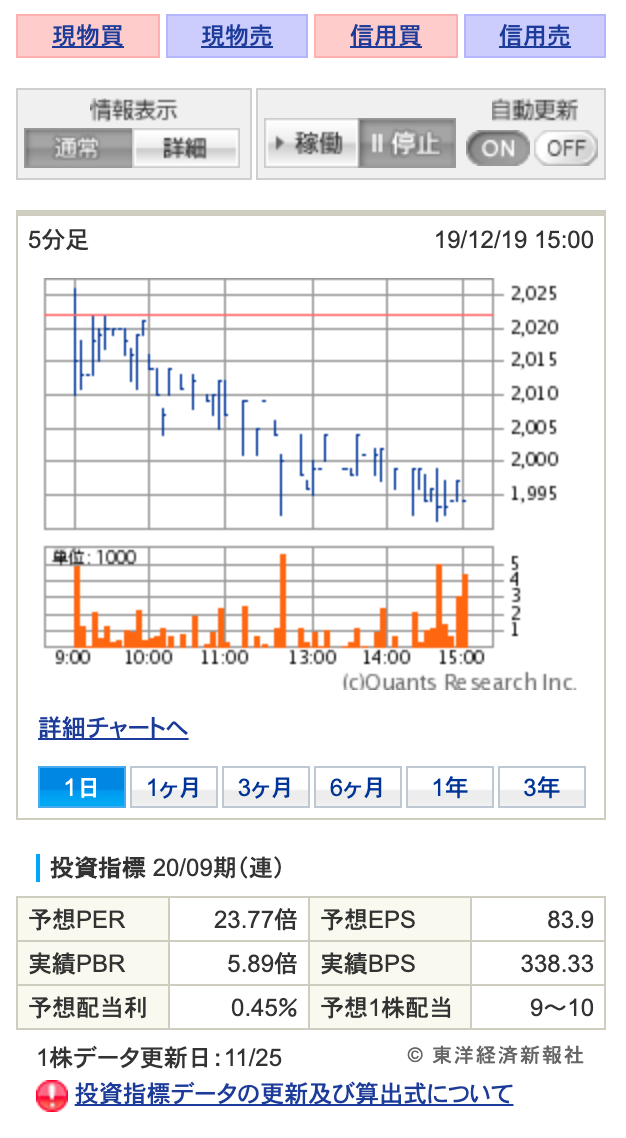
このブロックはHTML上だと<div id="clmSubArea">内になります。
では、find_all()関数に<div id="clmSubArea">を指定してみます。
def get_fi_param(self, ticker):
dict_ = {}
html = self.financePage_html(ticker)
soup = BeautifulSoup(html.text, 'html.parser')
div_clmsubarea = soup.find_all('div', {'id': 'clmSubArea'})[0]
print(div_clmsubarea)
これを実行すると
<div id="clmSubArea">
<div class="mgt10">
<table border="0" cellpadding="0" cellspacing="0" class="tbl02" summary="layout">
<tbody>
・
・
・
<h4 class="fm01"><em>投資指標</em> 20/09期(連)</h4>
</div>
</div>
<div class="mgt5" id="posElem_19-1">
・
・
・
</tr>
</tbody>
</table>
</div>
という具合に目的のブロックを取得する事ができました。
文字列の取得
ここまでくれば、あとは目的の文字列を取得するまで同じ作業の繰り返しです。
一気にやってしまいましょう。
def get_fi_param(self, ticker):
dict_ = {}
html = self.financePage_html(ticker)
soup = BeautifulSoup(html.text, 'html.parser')
div_clmsubarea = soup.find_all('div', {'id': 'clmSubArea'})[0]
table = div_clmsubarea.find_all('table')[1]
p_list = table.tbody.find_all('p', {'class': 'fm01'})
per = p_list[1].string.replace('\n', '')
print('予想PER:' + per)
投資指標の<table>ブロックを取得し、その中の<p class="fm01">を全て取得してきます。
最後に<p class="fm01">内の文字列を取得してくれば処理終了です。
$ python -m unittest tests.test -v
test_lambda_handler (tests.test.TestHandlerCase) ... 予想PER:23.86倍
できました。
あとは取得できた文字列をJSONなどに加工してあげればより使い勝手がよくなるでしょう。
終わりに
クローリングを使うと結構簡単に欲しい情報をサイト上から取得してこられました。
用法容量をきちんと守れば、色々と役に立つ技術だと思います。
今回のコードは複数証券コードに対応できるようにして、HTML上に一覧表示するところまで作り込もうと思います。
その過程でアウトプットできる事があればまた別の機会に記載したいと思います。