ディープラーニングの勉強を開始したが、大学レベルの数学知識が必要のため、ついていけなかった人も多いのではないでしょうか。
まずは、理論抜きで実装から入って仕組みを理解できないかと考えています。
はじめに
機械学習は、黒魔術とも言われています。なぜか分からないが結果が出ると。
「それなら理論はわからなくても、まずは、実践してみましょう。」ということで、実装から開始したいと思います。実装により何か得られればと考えています。
MNISTの確認
機械学習の実験用データとしてMNISTが一般的に利用されているようです。0~9までの手書きの数字の画像です。当面、このデータを利用しますので、まずこのデータの読み込みからはじめましょう。
ホームページより、データをダウンロードします。データは、学習用の画像 60,000枚とテスト用の画像 10,000枚を含んでいます。
- train-images-idx3-ubyte.gz: 学習用画像
- train-labels-idx1-ubyte.gz: 学習用正解ラベル
- t10k-images-idx3-ubyte.gz: テスト用画像
- t10k-labels-idx1-ubyte.gz: テスト用正解ラベル
実装には、Pythonを利用います。私は、Anacondaを利用しています。多次元配列や数値関数をサポートするnumpyも含まれています。今後、numpyを多用することになります。実行には、ブラウザ上からPythonを実行できるJupyter Notebookを利用します。こちらもAnacondaに含まれています。
画像データの読み込み
ファイルの先頭に件数、縦横のピクセル数などの情報が格納されているようです。形式の詳細は、MNISTのページを参照してください。ビッグエンディアンで格納されているので変換しています。
ファイルは、"c:\mnist"フォルダに格納されているとします。
import gzip
import numpy as np
mnist_path = 'c:\\mnist\\'
with gzip.open(mnist_path + 'train-images-idx3-ubyte.gz', 'rb') as f:
buffer = f.read()
size = np.frombuffer(buffer, np.dtype('>i4'), 1, offset=4)
rows = np.frombuffer(buffer, np.dtype('>i4'), 1, offset=8)
columns = np.frombuffer(buffer, np.dtype('>i4'), 1, offset=12)
data = np.frombuffer(buffer, np.uint8, offset=16)
print(size[0])
print(rows[0])
print(columns[0])
60000
28
28
60,000画像、28×28ピクセルであることが確認できます。
次に画像データを確認してみましょう。データを6000:28:28の配列に変換します。1枚目のデータを表示します。
data = np.reshape(data, (60000,28,28)) # 60000:28:28の配列に変換
print(data[0]) # 1枚目の画像データ表示
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136 175 26 166 255 247 127 0 0 0 0]
[ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253 225 172 253 242 195 64 0 0 0 0]
[ 0 0 0 0 0 0 0 49 238 253 253 253 253 253 253 253 253 251 93 82 82 56 39 0 0 0 0 0]
[ 0 0 0 0 0 0 0 18 219 253 253 253 253 253 198 182 247 241 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 80 156 107 253 253 205 11 0 43 154 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 14 1 154 253 90 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 139 253 190 2 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 11 190 253 70 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 35 241 225 160 108 1 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 81 240 253 253 119 25 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 186 253 253 150 27 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 93 252 253 187 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 249 253 249 64 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 46 130 183 253 253 207 2 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 39 148 229 253 253 253 250 182 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 24 114 221 253 253 253 253 201 78 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 23 66 213 253 253 253 253 198 81 2 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 18 171 219 253 253 253 253 195 80 9 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 55 172 226 253 253 253 253 244 133 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 136 253 253 253 212 135 132 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
0~255のグレースケールで画像が格納されています。
matplotlibを利用し、実際に画像を表示してみましょう。
import matplotlib.pyplot as plt
plt.imshow(data[0], 'gray')
plt.show()
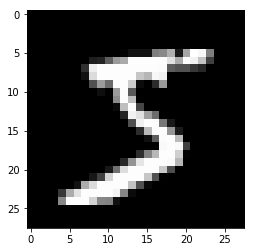
5のような画像が表示されました。
正解ラベルの読み込み
では、正解を見てみましょう。60,000画像分の正解データがあります。
with gzip.open(mnist_path + 'train-labels-idx1-ubyte.gz', 'rb') as f:
buffer = f.read()
size = np.frombuffer(buffer, np.dtype('>i4'), 1, offset=4)
data = np.frombuffer(buffer, np.uint8, offset=8)
print(size[0])
60000
1枚目の正解は?
print(data[0])
5
やはり、正解は5でした。
NMISTは、欧米人の書いたデータなのか、日本の数字の書き方とは微妙に異なっているようです。
今後の学習で利用しやすいように、0~9を表す10個の配列とし、正解を1、不正解を0としてデータを格納します。
t = np.zeros((data.size, 10))
for i in range(data.size):
t[i, data[i]] = 1
print(t[0])
[ 0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
MNISTデータの準備
画像データは、表示用に28×28に変換しましたが、学習データとしては、1画像、784個のデータとみなします。また、データは実数型に変換します。
最後に、MNISTデータの読み込み部分を関数化
def load_mnist( mnist_path ) :
return _load_image(mnist_path + 'train-images-idx3-ubyte.gz'), \
_load_label(mnist_path + 'train-labels-idx1-ubyte.gz'), \
_load_image(mnist_path + 't10k-images-idx3-ubyte.gz'), \
_load_label(mnist_path + 't10k-labels-idx1-ubyte.gz')
def _load_image( image_path ) :
# 画像データの読み込み
with gzip.open(image_path, 'rb') as f:
buffer = f.read()
size = np.frombuffer(buffer, np.dtype('>i4'), 1, offset=4)
rows = np.frombuffer(buffer, np.dtype('>i4'), 1, offset=8)
columns = np.frombuffer(buffer, np.dtype('>i4'), 1, offset=12)
data = np.frombuffer(buffer, np.uint8, offset=16)
image = np.reshape(data, (size[0], rows[0]*columns[0]))
image = image.astype(np.float32)
return image
def _load_label( label_path ) :
# 正解データ読み込み
with gzip.open(label_path, 'rb') as f:
buffer = f.read()
size = np.frombuffer(buffer, np.dtype('>i4'), 1, offset=4)
data = np.frombuffer(buffer, np.uint8, offset=8)
label = np.zeros((size[0], 10))
for i in range(size[0]):
label[i, data[i]] = 1
return label
これで、ディープラーニングを行うためのデータの準備ができました。