はじめに
初めまして。Neverと申します。JTC(Japanease-Traditional-Company)にてデータ分析を担当しております。
Twitter上でDataRobot(以下DR)のアドベントカレンダーについて知りましたので書いてみようと思います。
※初めてのQita投稿ですので心ともないですが、何卒ご容赦願います。
↓企画のリンク先
https://qiita.com/advent-calendar/2020/datarobot
アドベントカレンダーのお題:冬と言えば?
暖かい家の中でゴロゴロしてYoutubeをみる人が多いと思うのですが、YouTubeの視聴者数って気になりませんか?
私は結構気になる方で「この再生回数だと※円儲かったのかー」など計算してしまいます笑
この視聴者数が何と因果関係があるのか気になっていました。
話は変わって最近業務などで"DR良いよ"とよく聞くのですが、どんなところが良いのか気になっていました。
そこでタイミングよくアドベントカレンダーの話を聞いたので、DRを使ってYouTube視聴者数分析をやってみたいと思います!
この過程でDRはどんな人に向いているのか?も同時に見ていきたいと思います。
※アドベントカレンダーの趣旨から若干外れておりますが、許して頂けますと幸いですm(_ _)m
■"DR = 良いよ"を探すときの仮定
・想定ユーザー : DataScientist(以下DS)業務の経験が浅い人
・目的 : 上記ユーザーがDRを使うと何が良いのかを探す。
・検証方法 : 実際のコンペ題材を使ってDRでモデリングしてみる
・使用するDataRobot : 製品版を使用
対象の分析コンペ
分析コンペとはコンテスト主催者から課題(企業課題・研究課題)が与えられ、DSが機械学習を使って問題を解いてその性能を競うものです。
代表的なものでいうとkaggle https://www.kaggle.com/ があります。
今回は少し前に開催された Probspace https://prob.space/ の"Youtube視聴者数予測コンペ"を題材にしたいと思います。
使用するデータの特徴
今回はCSV形式のデータになります。特徴量は下記の通りです
・video_id : id
・title : 題名
・publishedAt : 公開日
・channelId : チャンネルのid
・channelTitle : チャンネルのタイトル名
・categoryId : カテゴリーid
・collection_date : データを記録した日
・tags : 動画についているタグ
・likes : Likesの数
・dislikes : Dislikes数
・comment_count : コメント数
・thumbnail_link : 動画のリンク先
・comments_disabled : コメントが許可されているか否か
・ratings_disabled : レーティングが許可されているか否か
・description : 動画の説明
・y
パッと眺めた感じですと、"likes", "dislikes", "comment_count"が効きそうですね。
データをDataRobotに入れてみる
お待ちかねのDR登場!
Top画面はシンプルで使いやすそうな印象を受けました。
ここにデータをドラッグ&ドロップしてみます。
(余談ですが最初のローディング中はマスコットキャラがクルクルまわります。癒し…)

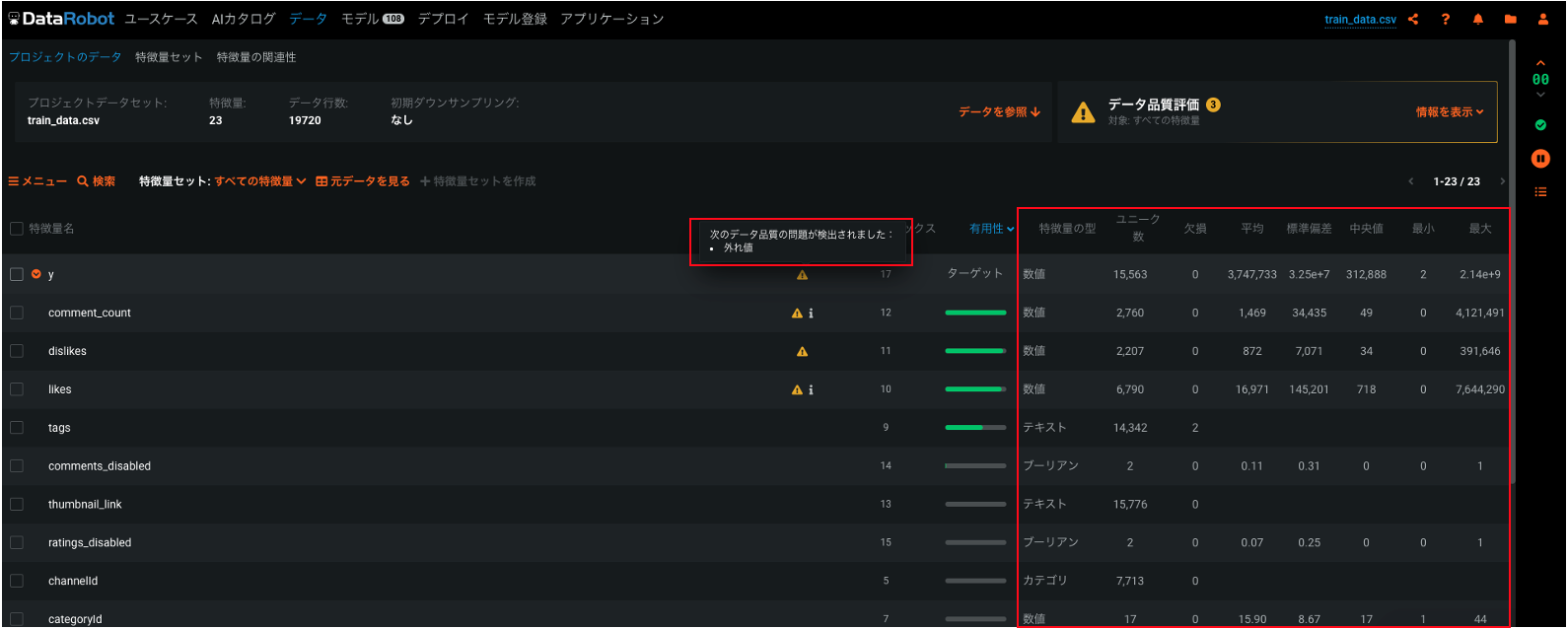
データの読み込みが終わるとEDAが始まります。
左の赤枠部では"外れ値"があることを示しており、右の赤枠部では"データの型", "各統計量"を示しています。
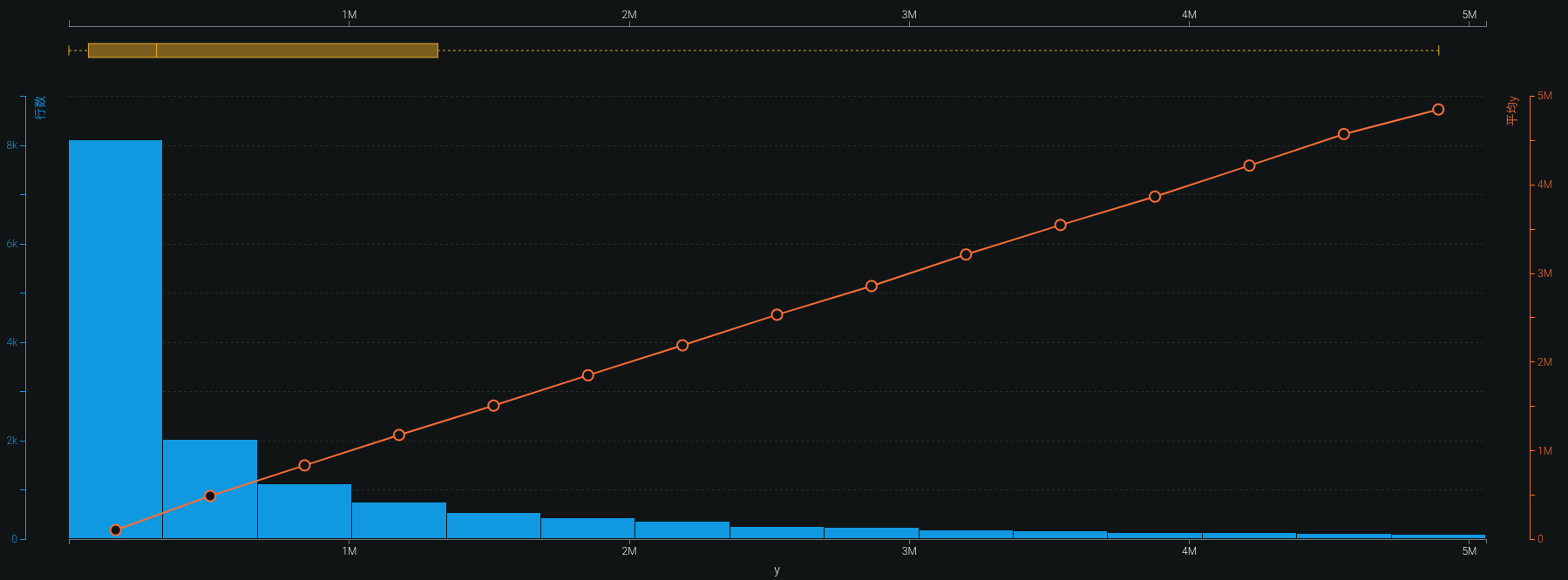
まずは目的変数の分布を見てみます。
Youtubeは様々な動画がありますので視聴者数が少ないところに多く集中しており、メガヒット動画もあるので裾が長い分布になっていますね。
次にチャンネルタイトルの特徴量を見てみましょう。
こちらは"大きさで頻度", "色で再生回数との相関"を表しています。"official"も"公式"も同じ意味合いだと思うのですが、"official"の方が視聴者数と相関がありそうです。つまり国内規模の公式動画かグローバル規模の公式動画か?といった点も特徴量の一つになりそうですね。
あとは中心付近にいる"kids"も重要で子供向け動画は世界中で需要があるみたいです。
この辺りの機能はDS経験が浅い方に貢献してくれそうですね。

モデリングをやってみる
お待ちかねのモデリングです。目的変数yに選択を入れてまずは"クイック"で実行してみましょう。
この辺りは他のDR記事にたくさん書かれていますので割愛しますね。
クイック実行はこんな感じでした。
・約1Hrほどで50程度のモデル作成
・ほぼ10クリックくらいでクイックが実行可能(楽すぎる)
・作成完了時はメールでお知らせしてくれる機能あり
・一番良かったのはXGBoostモデル(Submitした結果はあとで)
クイックで実行した後に"精度を高める"ボタンが出てきますのでこちらを実行します。
こちらは結構時間がかかり、さらに2Hrほど時間がかかった印象です。
一番良かったモデルはXGBoostでした。ゴリゴリMLPなどとアンサンブルするかと思いきや今回のデフォルト設定では行われませんでした。
特に弄らずモデリングを行うと"Gamma"で最適化していましたがRMSLEのスコアも表示できます。
せっかくなので最後にProbspaceにてLatesubしてみましょう。
モデルを解釈してみる
DRはモデルの解釈機能がとても充実しています。順に見ていきます。
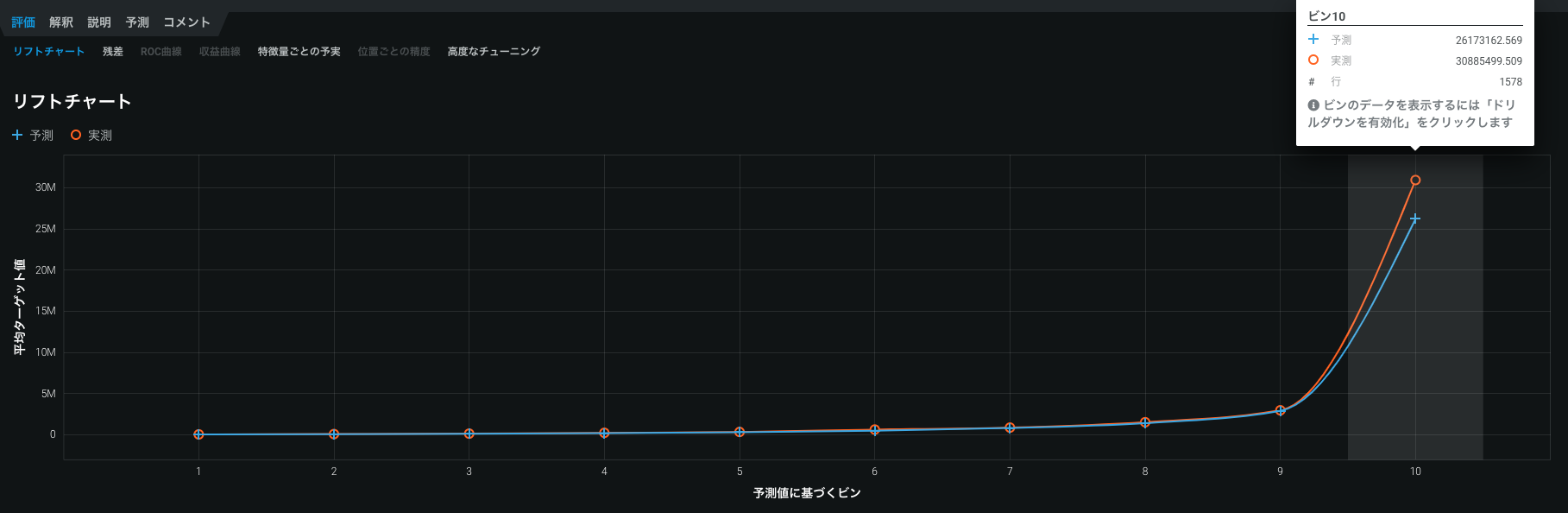
まずは"リフトチャート"です。(詳細はこちら https://www.datarobot.com/jp/blog/2018-02-07-liftchart/)
恥ずかしながらリフトチャートは知らなかったのですが、予測と実測をある区間でビンをとってそこの平均を出すイメージで下図の場合、視聴者数が多い動画に対しては誤差が広がることを示しています。
次に特徴量とモデル関係を見てみましょう。
DR内では"特徴量ごとの予実", "特徴量ごとの作用"の2機能があります。
前者はEDA時に視聴者数と相関があった特徴量との関係が見れて、後者ではモデルが算出した特徴量インパクトの高い特徴量と視聴者数の関係が見れます。
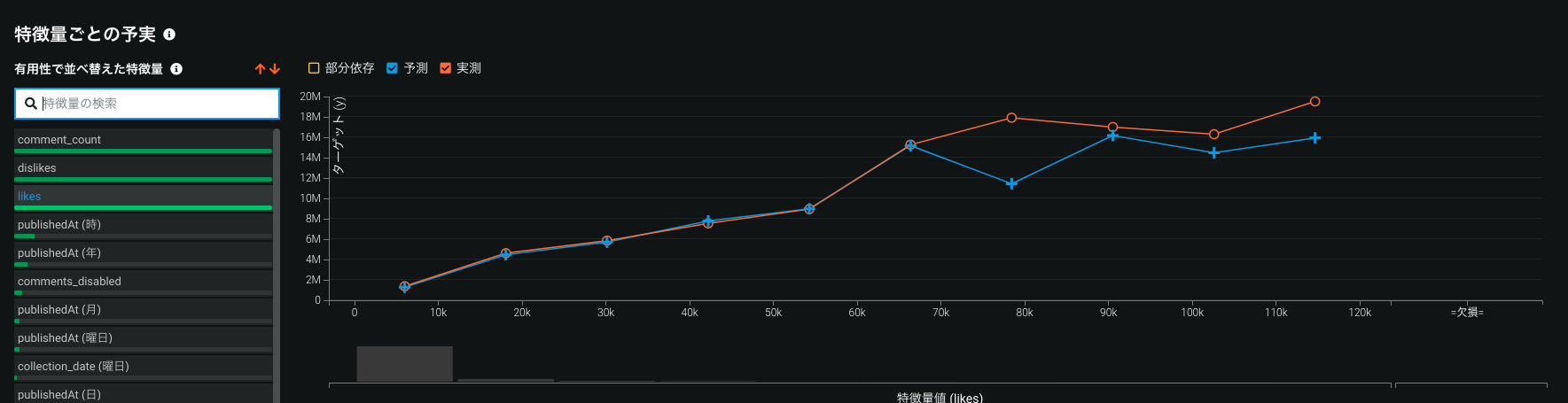
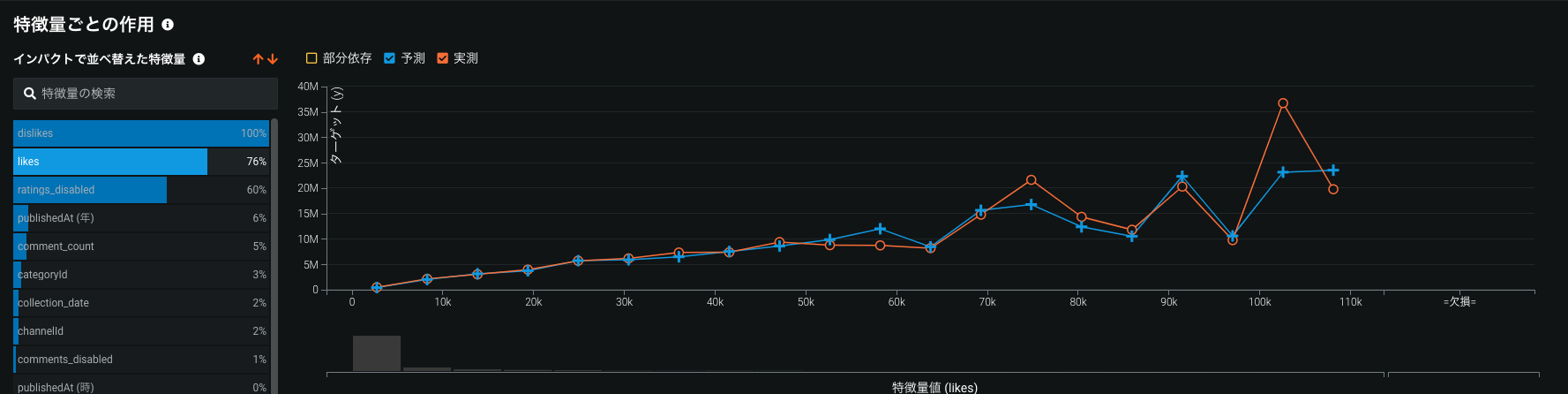
EDAでは"Comment_Count", "dislekes", "likes"の順で有用性があると判断され、モデル上の特徴量インパクトは"dislikes", "likes", "rating_disabled"の順になるみたいです。"rating_disabled"は"とてもヒットしているがratingを許可していない"動画があるのかなーと思ったりしました(x-yプロットは同じになると思っていたのですが同じではない…?)
最後に実際にProbSpaceでLatesubしてみる
やはりコンペ題材からとってきたので精度性能の検証はコンペでやってみたいと思います。
"精度を高める"で構築したモデルをサブミットしてみました。
結果としてはPublicよりもPrivateの方がはるかに精度が良かったです。
Public < Privateで精度が良い ≒ 母集団の分布を捉えられているのではないでしょうか(ロバスト性を重視)
あと交差検定のスコアともビタビタだったので、デプロイ後の実用性を真面目に考えていると思います。
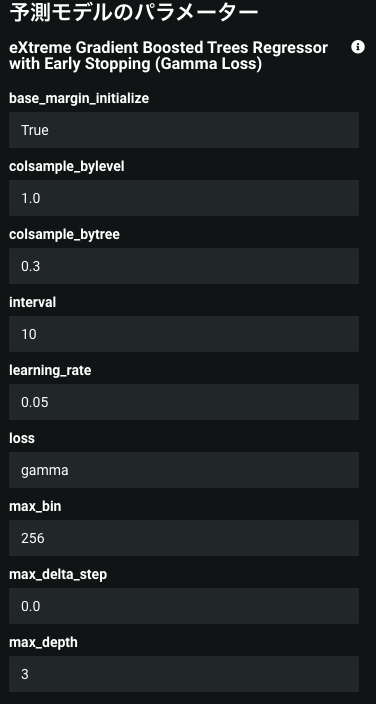
DRではモデルのハイパーパラメータも確認できます。
max_depth:3と浅い木の構造になっていますね(colsample_bytree:0.3の意図が気になる)
まとめ
■視聴者数と各特徴量の関係性
・EDAよりチャンネルタイトルの"official", "kids"など視聴者数と相関が高いタイトル名あり。
・EDAでは"Comment_Count", "dislekes", "likes"の順で有用性があると判断。
・モデル上の特徴量インパクトは"dislikes", "likes", "rating_disabled"の順で効いていると判断。
→基本的には"likes", "dislikes"が重要な特徴量であり、"rating_disabled"によるratingのOK/NGも視聴者数に効いている。
"official"などがチャンネル名にあるものは視聴者数が高い(officialがある=英語の有名コンテンツの可能性が高いことを指していると思います)
■DRの良い点・注意点
・DRはモデル作成までが数クリックで非常に楽である。
・解釈性機能が豊富でモデルの説明が容易だが、各用語の意味などを理解しないと間違った解釈をしそう。
→ DS経験が浅い人がDRを使ってモデリングを行うのは良いと思うが、DRを使用しないでモデリング技術を磨くことも必要であると考える。
逆に一定のスキルがある人は特徴量エンジニアリングが済んだあとはDRに投げるだけでだいぶ楽できると思う。
DRは非常に高速なモデリングが可能でありでまだまだ面白そうな機能があるので強力なツールだと思います。
特徴量エンジニアリングに集中してモデリングはDRの世界はもうすぐですね
(ゆくゆくは特徴量エンジニアリングもDRに負けそう)
引き続きマニュアルを読みながら勉強したいと思います。また勉強した際は記事を投稿しようかと思います。
最後まで読んでいただきありがとうございました!!