TransformerのEncoder部分から出力されるベクトルを使用して文を評価できないのだろうか?
今まで気になっていたことを色々試してみたのですが、どこにも見せる場がないので、ここに記そうと思います。
コードはGitHubにあります。
https://github.com/NeoSolleil/metrics.git
どういうこと??
文評価系のタスクを行うときに文のベクトル同士のコサイン類似度でどれぐらいMT訳(翻訳文)が正しいかを判定することがあるんですよ。
そこで、TransformerのEncoder部分から出力されるベクトルを使えば、それなりに良い文評価ができるのかなと思ったので、やってみました。(学習をしていない文には正しいベクトルが出力されないと思うので、学習を行った文しか文評価はできません)

なぜやろうと思ったのか
nlpではよく自動評価法BLEUを使用して翻訳文を評価しているが、表層的なn-gram一致率に基づいているため意味的な情報が反映されていない。

問題点:表層的な単語一致率に基づくため意味的な情報が反映されない(例:“北海道”と“道内”は全く異なる単語と認識される)
そこで、TransformerのEncoderを用いて文を「意味表現」に変換することで翻訳文の評価を行えるのではないかと考えた。
文を意味表現に変換することで、表層的なn-gram一致率ではなく、文の意味を使用して評価を行えるのではないかと考えた。
自動評価とは (自動評価法の概要)
機械翻訳システムの訳文(MT訳)をスコア化することでシステムの優劣をつけるというものである。
自動評価法ではMT訳(翻訳文)と参照訳(正解訳)を入力とし、2つを比較することでスコアを出力する。

Transformerとは
Transformerとは、機械学習の分野で特に自然言語処理のタスクにおいて非常に成功したモデルの一つである。このモデルは、Attention(注意機構)メカニズムを導入し、シーケンス間の依存関係をモデル化するために設計されている。 Transformerは、Googleによって提案され、2017年に"Attention is All You Need"という論文で初めて発表された。
左側がEncoderとなっており、右側がDecoderとなっている

Transformerは、EncoderとDecoderの2つの主要なコンポーネントで構成されている。Encoderは入力を処理し、Decoderは出力を生成する。
提案手法
- 原文と参照訳のペアを入力し、Transformerのモデルを生成 (以下の図は英日のMTシステムを評価する場合の図となっている)

- 生成されたモデルのEncoderを用いて参照訳とMT訳をそれぞれの文ベクトルを計算
- 参照訳の文ベクトルとMT訳の文ベクトル間の類似度をスコアに使用

しかし、ベクトルを得る時に未知語が存在した場合、正確な文ベクトルが得られないため、参照訳に存在しないMT訳の単語を含む新たな文を作成し学習データに付与したうえで学習を行う必要がある
(詳細は次のセクションで説明)
処理過程
学習データの付与
- 参照訳に存在しないMT訳中の単語を検索する(分かち書きされていない文を使用する場合はMeCab等を使用して分かち書きする必要がある)
- MT訳中の単語と参照訳中の全単語との類似度を単語分散表現モデルのfastTextを用いて取得し、最も類似度の高い参照訳中の単語とMT訳中の単語を置換することで文を新たに作成する

対応する原文と新たに生成された参照訳を学習データに付与する

モデルの生成
増加された学習データを用いてTransformerのモデルを生成する
エポック数:100 学習率:1e-4 (=0.0001)
文ベクトルの計算
生成されたTransformerモデルのEncoderを用いて参照訳とMT訳の文ベクトルを出力し、ベクトル間のコサイン類似度をスコアに使用する。
コサイン類似度を計算するにはベクトルの次元数が同じである必要がある。
しかし、Encoderから出力されるものは1単語が128次元のベクトルが出力されるので、文によって単語数が異なるので、計算を行うことができない。
そこで、出力された全単語のベクトルを要素ごとに足すことで128次元のベクトルにすることで計算を行う。
出力される全単語のベクトルを足すので、意味表現を取得していることになる。
MT訳も同様にベクトルの出力を行う。


128次元になるように計算を行った参照訳とMT訳のベクトルのコサイン類似度を計算する。
このコサイン類似度をスコアとして使用する。
性能評価実験
- 実験データ
- 国際会議WMT20のMetricsタスクから提供されているデータ
- 英日:原文と参照訳の組1,000ペア、11MTのMT訳11,000文
- 日英:原文と参照訳の組993ペア、10MTのMT訳9,930文
- 全MT訳に対する人手評価
- 国際会議WMT20のMetricsタスクから提供されているデータ
- 実験方法
- 提案手法とBLEUを用いてMT訳に対する評価スコアを算出
- MTシステム単位のスコア(システムレベル)
- 文単位のスコア(セグメントレベル)
- 提案手法のシステムレベルのスコアはセグメントレベルのスコアの平均を使用
- 提案手法とBLEUを用いてMT訳に対する評価スコアを算出
- 評価方法
- 提案手法とBLEUそれぞれと人手評価との相関係数を算出
実験結果
- システムレベルの相関係数
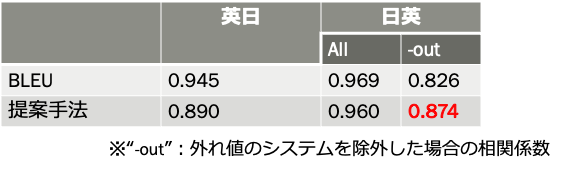
- セグメントレベルの相関係数

考察
- 全てのMTシステムを対象とした場合、提案手法の評価精度はBLEUよりも低い結果となった
- しかし、外れ値のMTシステムを除いた場合、日英において相関係数はBLEUよりも高い数値が得られた。したがって、翻訳精度の低いMTシステムが混在していなければ提案手法はBLEUより有効と考えられる
- 提案手法、BLEUともにセグメントレベルでは評価精度は不十分
感想
本当に少ししか変わりませんでしたね...(T ^ T)(悪くなったところには目を瞑ってください)
ぶっちゃけいいスコアが出るとは思ってはいなかったですが、ここまで低いとは思ってなかったです。
Transformerのモデルを生成する時にモデルが出力している翻訳文が表示されていたのですが、その時の翻訳文は精度良かったのですがね。
今回は、学習率:1e-4 で学習を行いましたが、最初これよりも低い学習率に設定してて学習が上手くいきませんでした。
似ている文が多いので、仕方ないのかもですが...。まあ最適なハイパラは何回もやってわかるものですしね。
TransformerはEncoderとDecoderが揃っていなきゃダメね!!
今回は参照訳を使用して学習などを行い、文の評価をしましたが、私は参照訳を使用しないで文を評価する研究をしています。
上手くいかないと思ってもこれをやる時は100%上手くいくと思ってやってました。(心に嘘をついてもモチベが大事)
余談
これを書いているのは2024/2/22なんですけど、OpenAI社が「Sora」というText-To-Videoモデルを数日前に公開したのですが、めちゃくちゃやばいですね。
ChatGPTが出た時もこれはやばいと思ったのですが、今回の「Sora」はあの時の比較にならないぐらいの衝撃を受けましたね。笑
もう本物の映像かと思うぐらいにグラフィックも綺麗でびっくりですね。
結構複雑なものも入力ができるようですね。
映像を見て思ったのは「文字」はまだ上手く生成できないのかと思いました。印象としては文字が文字として成立していない感じでした。でも、看板などがあればそこに文字を生成するというのはすべての映像に共通していたので、看板には文字という学習はできているのだと感じました。
公開した映像は東京っぽいのが多かったのはちょい嬉しかったですね。笑
ここまで読んでいただきありがとうございます。
また書こうと思います。
また逢う日まで。