Amazon EMR を活用したデータエンジニアリング
昨今、ITエンジニアのスキルは多様化しています。その中で最も顕著な分野とされるのが、データ処理の分野です。通信量の増加により、データ処理の需要は年々右肩上がりです。
そのため、データエンジニアリングが専門外のエンジニアでも、将来的なデータ処理量の増加を考えてシステム設計をしないといけなくなりました。
また、プロジェクトによっては、データ処理を専門に担当する人も増えてきているように思えます。大規模なバッチ処理を行うプロジェクトも多くなってきています。
以上のことから、備忘録もかねて、データエンジニアリングをハンズオンで行うための記事を上げました。
なお、このハンズオンの記事には、AWSソリューションアーキテクトアソシエイト以上の知識と経験がある方に向けています。
まずは概念を把握し、ハンズオンに進んでいきましょう。いきなりハンズオンにはいかないように!(無駄な料金がかかってしまいます)
※最低限の構成でハンズオンを実施していますが、少し料金がかかります
1. Amazon EMRとは?
Amazon EMR(Elastic MapReduce)は、AWS 上で動作するビッグデータ処理のためのマネージドクラスタープラットフォームです。Apache Hadoop のエコシステムを活用し、大規模なデータ処理や機械学習のトレーニングを効率的に行うことができます。
EMR は特に Apache Spark を中心に利用されることが多く、データのスケーラブルな処理やストリーム処理が可能です。また、AWS の他のサービスと密接に統合されており、データの保存や管理が容易になります。また、実務上では、Apache Sparkを単体で使うことはなく、Hadoopはストレージ & リソース管理、Sparkはデータ処理のエンジンとして機能するのが一般的です。つまり、互いのカバー範囲を補完しあっているといえます。
HadoopとSparkの関係性を分かりやすく整理した表を作成しました。
HadoopとSparkの比較表
| 項目 | Hadoop(MapReduce) | Apache Spark |
|---|---|---|
| 目的 | 分散バッチ処理 | 分散データ処理(バッチ & ストリーミング) |
| データ処理方式 | バッチ処理(MapReduce) | バッチ + ストリーミング処理(リアルタイム処理) |
| スピード | ディスクI/Oベースの処理で遅い | メモリベースの処理で高速 |
| データストレージ | HDFS(Hadoop Distributed File System) | HDFS, S3, Cassandra, HBase, JDBCなど |
| プログラミングモデル | Java(MapReduce) | Scala, Java, Python, R |
| リアルタイム処理 | 不向き | Spark Streamingで対応可 |
| 機械学習 | Mahout(やや遅い) | MLlib(高速な機械学習ライブラリ) |
| 適用範囲 | 大規模バッチ処理 | バッチ + リアルタイム分析、機械学習、データ分析 |
| 使いやすさ | コードが複雑 | シンプルなAPI(RDD, DataFrame, Dataset) |
| ストレージ依存 | HDFS必須 | HDFS以外のストレージとも連携可能 |
| エコシステムとの連携 | Hive, HBase, Pig, Oozie | Hive, HBase, Cassandra, Kafka |
| 耐障害性 | 高い(HDFSのレプリケーション) | 高い(RDDの耐障害性) |
HadoopとSparkの関係性
-
SparkはHadoopの代替ではなく、補完関係にある
- SparkはHadoopのHDFSをデータストレージとして使用できる
- SparkはHadoop YARNをリソース管理として利用できる
- HadoopのMapReduceの代わりにSparkを利用すると処理が高速化される
- Hadoop(MapReduce)はバッチ処理向きだが、Sparkはバッチ & リアルタイム処理が可能
- 最近のビッグデータ処理ではHadoop + Sparkの組み合わせが一般的
役割
| 目的 | 推奨 |
|---|---|
| 大規模なバッチ処理(ログ解析、レポート生成) | Hadoop(MapReduce) |
| 高速データ処理 & リアルタイム分析 | Spark |
| データレイクとしての分散ストレージ | HDFS(Hadoop) |
| 機械学習・AIモデルのトレーニング | Spark MLlib |
| ストリーミングデータの処理(IoT, SNSデータ) | Spark Streaming |
といえると思います。
2. なぜ Amazon EMR を学ぶべきなのか?
フリーランスとしても、大型案件のシステム設計の面接で頻繁に「大量のデータをどのように処理するか?」という質問を、しばしば受けます。その時、どの企業も何らかのビッグデータツールを導入していることに気が付きました。
データエンジニアリングの分野では、Python や SQL の知識だけでなく、ビッグデータフレームワークを扱えるスキル が求められています。
そのため、EMR を活用することで、大規模データの処理や ETL パイプラインの構築など、より高度なスキルを身につけることができると思います。
3. Amazon EMR の特徴
3.1. EMR のクラスタ管理
EMR は YARN(Yet Another Resource Negotiator) を使用し、クラスタのリソース管理を行います。
補足: なお、YARNとは、クラスタリソースを管理するための仕組みであり、「リソースマネージャー」 と 「ノードマネージャー」 で構成されています。
EMRのクラスタには、以下の 3 つのノードが存在します。
-
プライマリノード(マスターノード)
- クラスタ全体を管理し、タスクを分配
- クラスタの状態を監視
-
コアノード(ワーカーノード)
- 実際にジョブを処理し、HDFS にデータを保存
-
タスクノード(オプション)
- ワーカーノードと同じく処理を行うが、HDFS にはデータを保存しない
3.2. 他の AWS サービスとの統合
EMR の大きな強みは、AWS の以下のサービスと連携できる点です。
- Amazon S3:データの永続的なストレージとして利用。EMRFS(EMR File System)を通じて S3 に保存・読み取りが可能
- Amazon EC2:クラスタのワーカーノードをプロビジョニング
- Amazon VPC:安全なネットワーク環境を構築
4. EMR のスケーリングとパフォーマンス管理
EMR はスケーラブルなクラスタ管理が可能で、手動または EMR マネージドスケーリング によって、ジョブの負荷に応じたスケールアップ・ダウンを自動化できます。
例えば、ピーク時にはノードを増やし、アイドル時にはコスト削減のために縮小することができます。これは、企業にとって非常に大きなメリットとなります。もちろん、機会損失とコスト削減がクラウドコンピューティングを使用する最大の目的なので、外せないメリットにはなります。
5. Amazon EMR を活用した実践例
では、ここからハンズオンに移りましょう!AWS CLIでも実践は可能ですが、GUIで実施する際のスクリーンショットを用いて、ハンズオンで紹介します。
まず、ハンズオンの手順としては以下の通り。
5.1. EMR クラスタの作成
- S3 にデータを保存するためのバケットを作成
- 「バケットを作成」をクリック

- 画面の通りにオプションの選択・入力をし、バケットを作成



- 画像の通りにバケットの中に以下のフォルダーツリー(例)を構成
# s3://<yourname-mmdd>
labor-force-in-Hokkaido
│── input/ # 元データを格納するディレクトリ
│ │── 01.csv # 労働力データのCSVファイル
│
│── output/ # 処理後のデータを格納するディレクトリ
│ ├── _SUCCESS # 処理成功のマーカー
│ ├── _SUCCESS.crc # CRC チェックサムファイル
│ ├── .part-00000-xxxxxx.snappy.parquet.crc # データパーティションのチェックサム
│ ├── part-00000-xxxxxx.snappy.parquet # Parquet 形式の出力データ
│
│── logs/ # ジョブのログデータ
│ ├── some.log/ # EMR の実行ログ
│
│── main.py # Sparkのスクリプト



- VPC(仮想ネットワーク)を作成
- 画像の通りにVPCの作成


- EMR クラスタを起動
- 画像の通りにEMRクラスタを作成し、起動

- 最低限HadoopとSparkのみを選択

- クラスター設定にて、ユニフォームインスタンスグループを選択し、プライマリとコアのインスタンスタイプをm5.largeに設定

- インスタンスグループは不要なので、削除すること


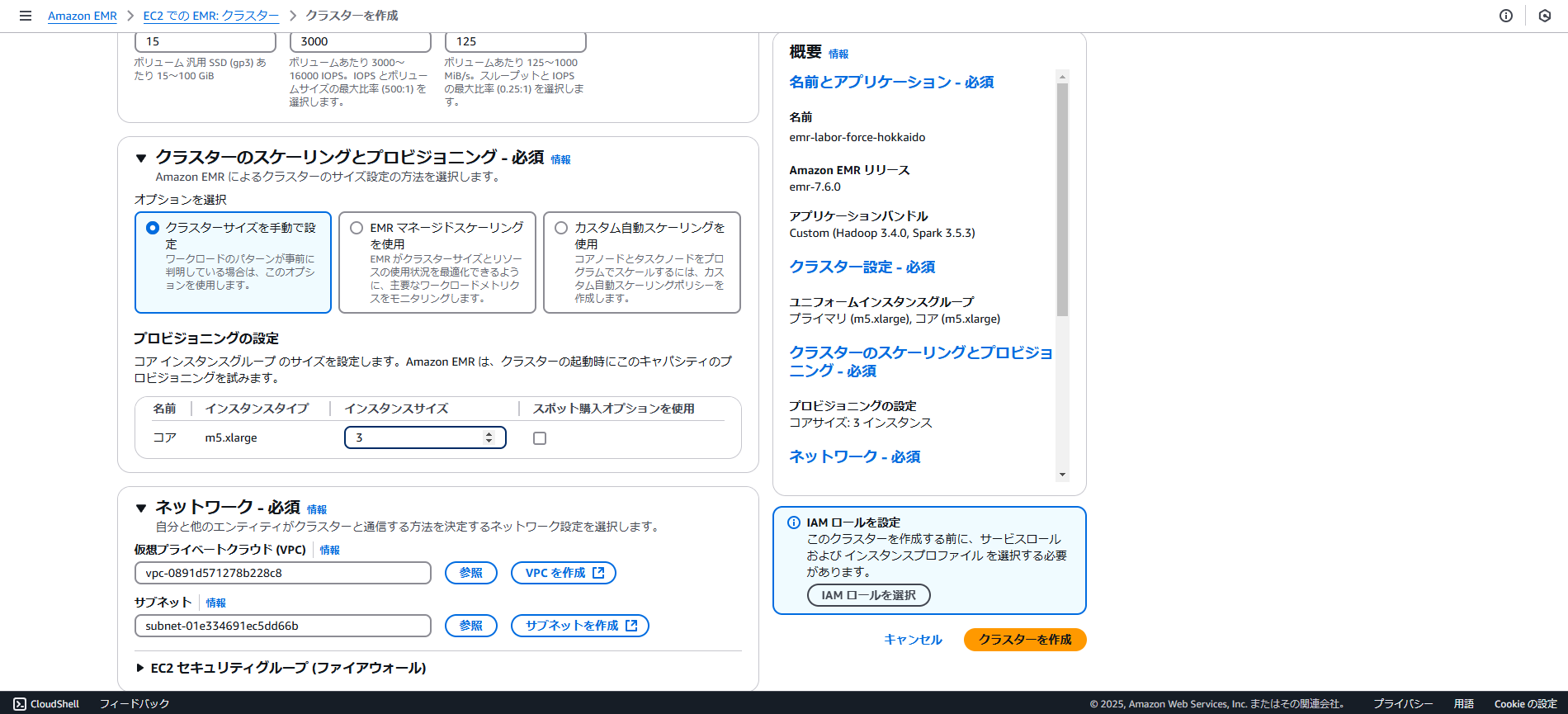



** アイドル時間はハンズオンがちょうど終わる時間を逆算して設定してください **

- ログの配置場所を、先ほど作ったBucketの中のフォルダーに設定します


- EC2キーペアは事前に取得したものを使ってください

- EMRサービスロールは新規で作成し、デフォルト設定で

- EMR EC2インスタンスプロファイルを作成(!重要!: バケットアクセスを読み取りおよび書き込みのアクセス権を持つに設定することを推奨)

- しばらく待つと。(経験則ですが、だいたい5分以内には作成が完了します)

これで、セットアップを完了!
5.2. EMR での Spark の実行
- CSV データを S3 からロード
- 以下のリンクからCSVをダウンロードし、任意の名前にリネームしてください(画像の例では、test_for_emr.csvにしています)
北海道オープンデータポータル

- ステップ作成前準備
スクリプトをステップで実行できるように配置します。
ステップとは、EMRクラスタ上で実行される一連のジョブやスクリプトのことです。ステップを利用することで、EMR クラスタ上で 自動的にデータ処理タスク を実行できます。
以下のようなステップを作成するとします。
データソースのETL処理 -> Parquet 形式で S3 に保存
この処理をスクリプトを用いて、実施します。
- スクリプト作成
主にETL処理を施しているスクリプトです。
引数から渡されたデータソースを処理します。データセット上で、日本のオープンデータ特有の邪魔な列の削除や日本語名のカラムが扱いづらいので、pysparkのモジュールで変換などを行います。必要なライブラリは随時インストールしてください。
また、スクリプトの最後には、引数から指定されるURI内に、ETL処理を施したデータセットをParquet形式で保存します。
スクリプトは以下の通り。
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
import argparse
def transform_data(data_source: str, output_uri: str) -> None:
"""
Transforms inspection data from a CSV file, removes unwanted rows,
sets the 3rd row as column names, filters out entries containing '計',
and saves the results as Parquet.
Args:
data_source (str): The S3 URI or local path to the input CSV file.
output_uri (str): The S3 URI or local path where the transformed data should be saved.
"""
# Initialize Spark session
with SparkSession.builder.appName("EMR Application").getOrCreate() as spark:
# Load CSV file into a DataFrame (without using first row as header)
df = (
spark.read.option("header", False) # Don't use first row as header
.option("encoding", "shift_jis")
.csv(data_source)
)
print("CSV file loaded.")
# Assign an index to each row
indexed_rdd = df.rdd.zipWithIndex()
# Extract the 3rd row (index 2) as column names
header_row = (
indexed_rdd.filter(lambda row: row[1] == 2)
.map(lambda row: row[0])
.collect()[0]
)
print(f"New header extracted: {header_row}")
# Remove the first six rows except for the 3rd (index 2)
rows_to_remove = {0, 1, 3, 4, 5}
filtered_rdd = indexed_rdd.filter(lambda row: row[1] not in rows_to_remove).map(
lambda row: row[0]
)
# Convert back to DataFrame using new column names
df = spark.createDataFrame(filtered_rdd, schema=header_row)
print("Header applied and selected rows removed successfully.")
# Remove rows containing "計" in the 市町村 (City or Town) column
df = df.filter((col("市町村").isNotNull()) & (~col("市町村").contains("計")))
print("Rows containing '計' removed successfully.")
# Rename columns
df = df.select(
col("振興局").alias("county"),
col("コード").alias("location_code"),
col("市町村").alias("city_or_town"),
col("区").alias("ward"),
col("A〜R全産業(S公務を除く)_事業所数").alias(
"workplaces_in_all_industries"
),
col("A〜R全産業(S公務を除く)_従業者数").alias(
"workers_in_all_industries"
),
col("A〜R全産業(S公務を除く)_従業者数_男(人)").alias(
"male_workers_in_all_industries"
),
col("A〜R全産業(S公務を除く)_従業者数_女(人)").alias(
"female_workers_in_all_industries"
),
col("A〜B農林漁業_事業所数").alias("workplaces_in_primary_industry"),
col("A〜B農林漁業_従業者数").alias("workers_in_primary_industry"),
col("A〜B農林漁業_従業者数_男(人)").alias(
"male_workers_in_primary_industry"
),
col("A〜B農林漁業_従業者数_女(人)").alias(
"female_workers_in_primary_industry"
),
)
# Register temporary SQL table
df.createOrReplaceTempView("labor_force_in_Hokkaido")
# SQL query to preview data
transformed_df = spark.sql("""
SELECT county,
SUM(workplaces_in_all_industries) AS total_workplaces,
SUM(workers_in_all_industries) AS total_workers,
SUM(male_workers_in_all_industries) AS total_male_workers,
SUM(female_workers_in_all_industries) AS total_female_workers,
SUM(workplaces_in_primary_industry) AS total_workplaces_primary_industries,
SUM(workers_in_primary_industry) AS total_workers_primary_industry
FROM labor_force_in_Hokkaido
GROUP BY county
""")
transformed_df.show(truncate=False)
# Log the number of rows
row_count = transformed_df.count()
print(f"Number of rows in transformed data: {row_count}")
# Save results in Parquet format
transformed_df.write.mode("overwrite").parquet(output_uri)
print(f"Data written to {output_uri}.")
if __name__ == "__main__":
"""
Parses command-line arguments and executes the transform_data function.
"""
parser = argparse.ArgumentParser(description="Transform inspection data.")
parser.add_argument(
"--data_source", required=True, help="Path to the input CSV file."
)
parser.add_argument(
"--output_uri",
required=True,
help="Path to the output directory for Parquet files.",
)
args = parser.parse_args()
# Execute the data transformation process
transform_data(args.data_source, args.output_uri)
- ステップで実行するスクリプトをS3に収納する

-
ステップ作成




- ステップ作成完了を待ちます

完成!
5.3. SSH で EMR クラスタに接続
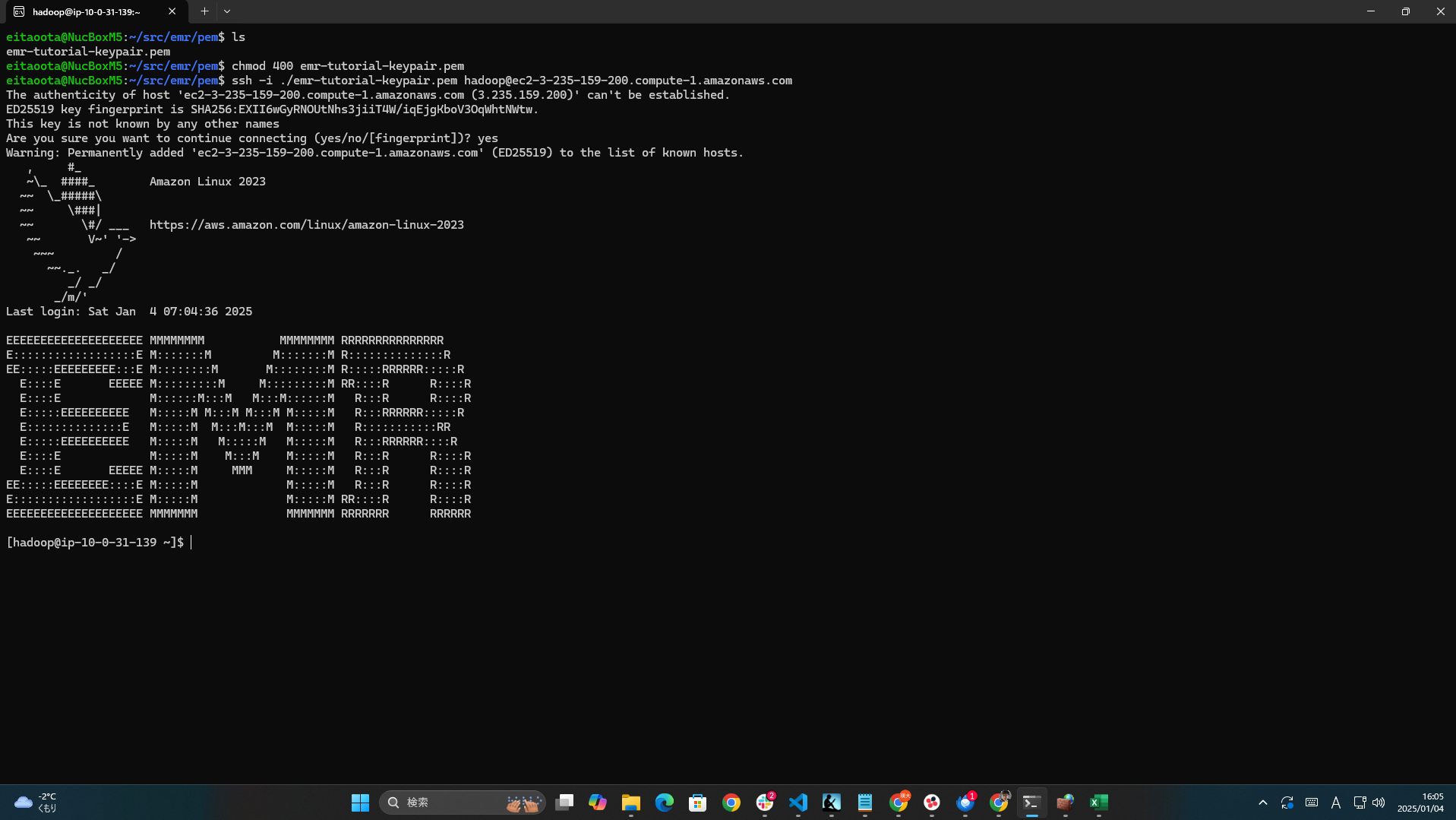
ちなみに、EMR のプライマリノードに SSH で接続し、手動で Spark スクリプトを実行できます。
そのためには、まずプライマリノードへのSSH接続を有効化してください。
-
SSH接続の有効化


-
SSH接続
pemキーなどの場所を指定し、プライマリノードに接続します。
ssh -i my-key.pem hadoop@ec2-xx-xx-xx-xx.compute-1.amazonaws.com
-
sparkコマンドで処理を実行
spark-submitコマンドを使って処理を実行します。
引数には、
--data_source [S3バケットinput内のデータソースのパス]
--output_uri [S3バケットoutputフォルダーのパス]
という風にオプションを入れます。

-
実行結果の確認

5.4. SSH で EMR クラスタのUIにアクセス
-
EMR UI アプリケーションのセットアップ
EMRのUIには、基本的にSSHトンネリングをセットアップし、アクセスするようにします。永続的なアプリケーションUIは、実務上特別な事由がない限りは選ばないと思います。アプリケーションのタグをクリックし、画像の通り選択してください。

-
sshのトンネリングを実行
ローカルマシンの8157ポートを、ユーザー名hadoopでEMRクラスタの8088に転送するようにします。

-
UI にアクセス
ブラウザでlocalhost:8157にアクセスし、HadoopのUIを確認
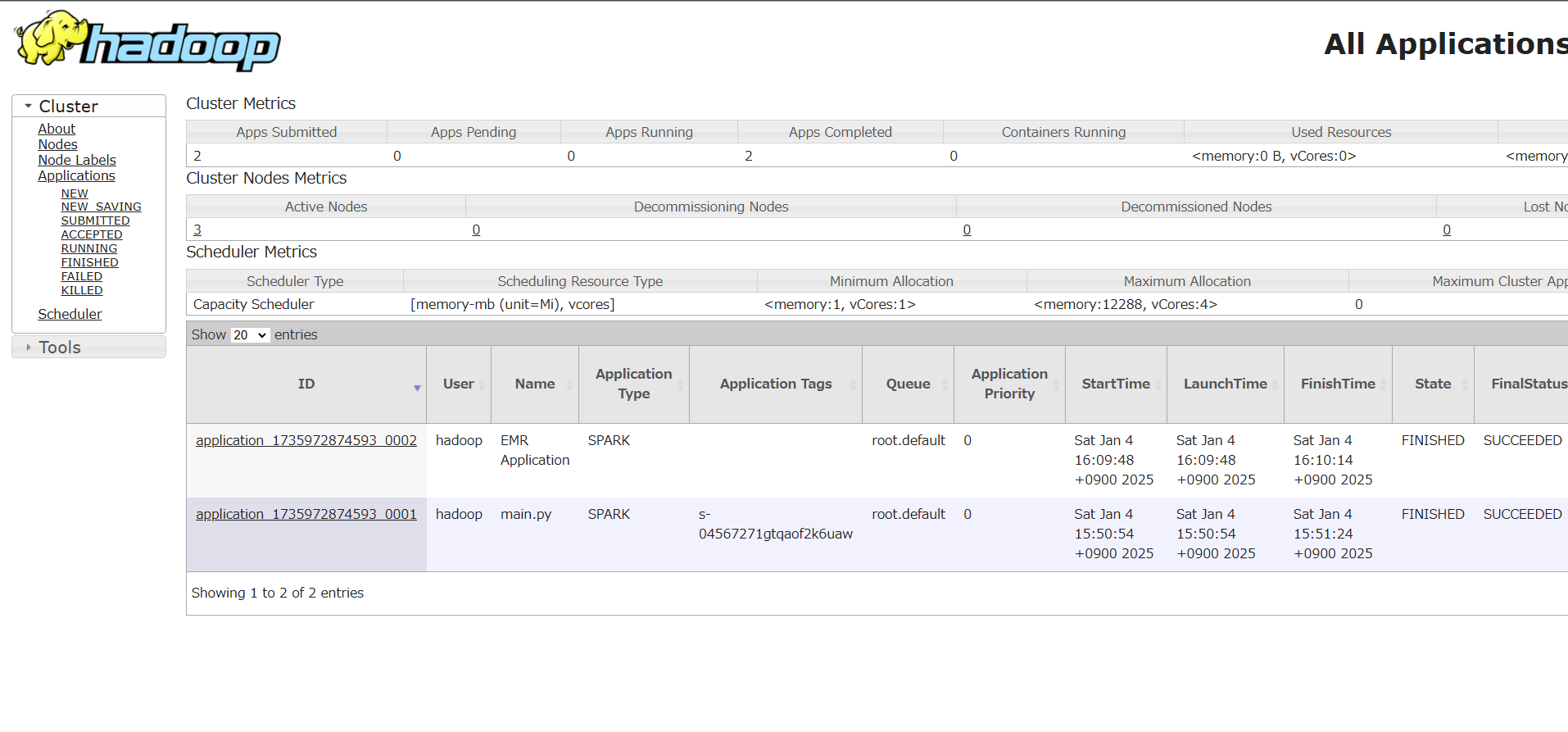
よく見てみると、ノードの数(現在はプライマリとセカンダリのみ)だけ、アプリケーションIDが発行されています。
6. Amazon EMR の課題と対策
6.1. ログのデバッグが難しい
EMR は強力なツールですが、ログのデバッグが非常に難しい という課題があります。特に、ジョブの失敗時にエラーログの特定が難しいため、適切な監視ツールを活用することが重要です。
というのは、Amazon EMRを使うと、Spark/Hadoopのアプリケーションログ、EMRシステムログ、CloudWatchに送信されるログの3種類が生成されます。レイヤーごとに使う監視ツールを連携させないといけないのが難しい部分となります。
6.2. コストの最適化
EMR はオンデマンドで利用できますが、適切にスケーリングしないとコストが増加 します。コストを最適化するために、スポットインスタンス や EMR マネージドスケーリング を活用することを推奨します。
7. まとめ
データエンジニアリングのスキルを向上させるために、Amazon EMR を活用して 大規模データの処理 を学びましょう。
✅ 本記事のポイント
✔️ EMR は AWS 上のビッグデータ処理のためのマネージドサービス
✔️ Apache Spark を活用してデータ処理が可能
✔️ Amazon S3, EC2, VPC との統合がスムーズ
✔️ スケーラブルなクラスタ管理が可能
✔️ ログのデバッグやコスト管理が課題となる
なお、後日、HadoopとSparkを組み合わせてUIでどのように操作するかを解説する記事をアップしていきます。(余裕があれば)
ぜひ、データエンジニアリングのスキルを強化していきましょう!
参考文献・公式ドキュメント
Amazon EMR
-
Amazon EMR 公式ドキュメント
- Amazon EMR
- AWSのEMRに関する公式ガイド。基本概念や構成方法、チュートリアルが記載されています
-
AWS EMR Best Practices
- Amazon EMR Best Practices Guide
- Amazon EMRを最適に利用するためのガイドライン
-
Amazon EMR での Apache Spark の利用
- Running Spark on Amazon EMR
- Amazon EMR上でSparkを実行するための公式ガイド
-
AWS Big Data Blog - Amazon EMR
- AWS Big Data Blog
- Amazon EMRやビッグデータ関連の実践記事が掲載されているブログ
Hadoop
-
Apache Hadoop 公式ドキュメント
- Apache Hadoop
- Hadoopの基本構成やMapReduce、HDFSの詳細情報が掲載されています
-
HDFS(Hadoop Distributed File System)
- HDFS Architecture Guide
- HDFSのデータ保存、分散システム、レプリケーションに関する詳細な解説
-
Hadoop vs. Sparkの違い
- Hadoop vs. Spark: Understanding the Differences
- HadoopのMapReduceとSparkの違いを詳しく解説した記事
Apache Spark
-
Apache Spark 公式ドキュメント
- Apache Spark
- Sparkの基本概念、RDD、DataFrame、Spark Streaming、MLlibに関する詳細な公式情報
-
Spark Performance Tuning Guide
- Tuning Spark
- Sparkのパフォーマンスを最適化するための公式ガイド
-
SparkとHadoopの違いに関する詳細な記事
- Spark vs Hadoop: Key Differences
- DatabricksによるHadoop MapReduceとSparkの違いの解説
AWS CLI & S3
- AWS CLI コマンドリファレンス
- AWS CLI Command Reference
- AWS CLIを使ってEMRやS3を操作する際のコマンドリスト
- Amazon S3 の公式ドキュメント
- Amazon S3
- Amazon S3のデータ保存と管理についての公式ガイド
データセット
- 北海道オープンデータポータル(本記事のデータソース)
- 北海道オープンデータポータル
- 労働力データなどの公的なオープンデータセットを提供
- UCI Machine Learning Repository(追加データ参考)
- UCI ML Repository
- 機械学習用のオープンデータセットを多数提供
追加資料(実務的な記事)
- AWS EMRを活用したデータ処理の実践
- AWS Black Belt Online Seminar – Amazon EMR
- AWSの公式ウェビナーでEMRの活用事例を学べる
- Hadoop/Sparkを活用したビッグデータ分析の実践
- Big Data Processing with Hadoop and Spark
- 実際のビッグデータ処理ワークフローを解説
- AWS EMRのコスト最適化ガイド
- How to Optimize Amazon EMR Costs
- EMRのコスト管理とスポットインスタンス活用方法