〜AIが名曲を生み出す〜
この音楽を聴いてみてください。
See the Pen MusicTransformerDemo by NayuSato (@nayusato) on CodePen.
[埋め込みが見られない場合はここ](https://magenta.tensorflow.org/assets/piano_transformer/clair_de_lune_continuation.mp3)これはGoogleの自動作曲Music Transformerが生み出した曲の1つです。
入力は、最初の6秒だけ。
クラシックのドビュッシー「月の光」の冒頭6秒だけを与えて、その続きを全て作らせるというタスクを行わせています。
十分聴き入って感動できるような曲に仕上がっています。
ケチをつけられる点がないとは言わないけれど、「人の作った曲です」と言われても識別できないほどの精度になっています。
「Music Transformer」
2018年Googleが発表した自動作曲のAI。
自然言語処理のアルゴリズムであるTransformerを音楽に適用することにより、それ以前とははるかに違う性能の音楽生成が可能となりました。
2019年には、OpenAIのMuseNetもGPT-2(自然言語処理のネットワーク)を用いる形で追随しました。
この記事では、Music Transformerのアルゴリズムと、それがどのように既存の課題を解決したかを説明します。
Music Transformerの解説
イメージだけつかみたいです!という方のための3行説明
- Music Transformerは、前の音を元に次の音を逐次的に生成していく
- この際、
Attention重みによって適切に前の音を参照しながら生成する - そのため、繰り返し構造が生まれやすくなっている
自然言語処理におけるAttention機構・Transformer
前提として、自然言語処理のTransformerを解説します。
Google翻訳にも使われている技術です。
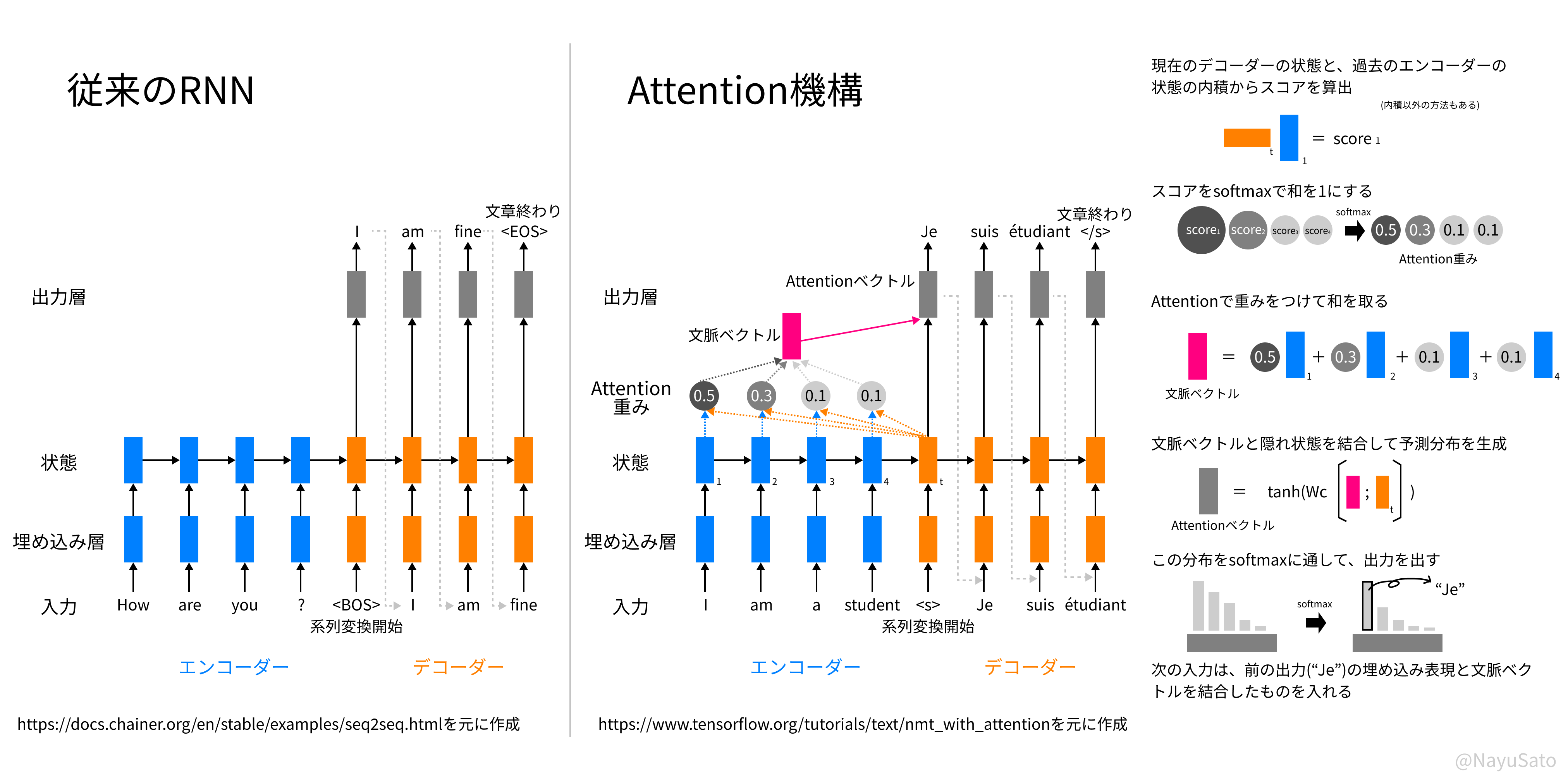
従来のRNNでは、データを入力した後の出力をもう一度入力層につなぐことで系列を処理します。
しかしこれには、過去の情報が薄まってしまうという欠点があります。
この性質をカバーするため、忘却ゲートをもうけた、LSTM(Long Short-Term Memory)が考案されてきましたが、これによって性能は向上したものの、長い系列をうまく学習し生成するには不十分でした1。
そこで出てきたのが、過去の系列のどこを参照するかのパラメータAttention重みさえも学習してしまおうという考え方です。2
直接、過去の入力の情報を参照するようにすることで、長い系列であっても過去の情報が失われなくなります。
このAttentionという機構を用いた自然言語処理モデルをTransformerと呼びます。
1単語前を0.1、2単語前を0.1、3単語前を0.3…、のように重みをつけて合算します。
どの単語を参照するかは文脈によって変わってきます。
前の単語の参照の強さまでを学習してしまうことにより、文脈によって柔軟に参照先を変えながら、文章の翻訳や続きの生成ができます。
図の詳しい説明はここを開く
・単語をエンコーダーに1つずつ入力する ・変換開始を表す`分かりやすい例: 文脈が異なった時の指示語のAttention重み
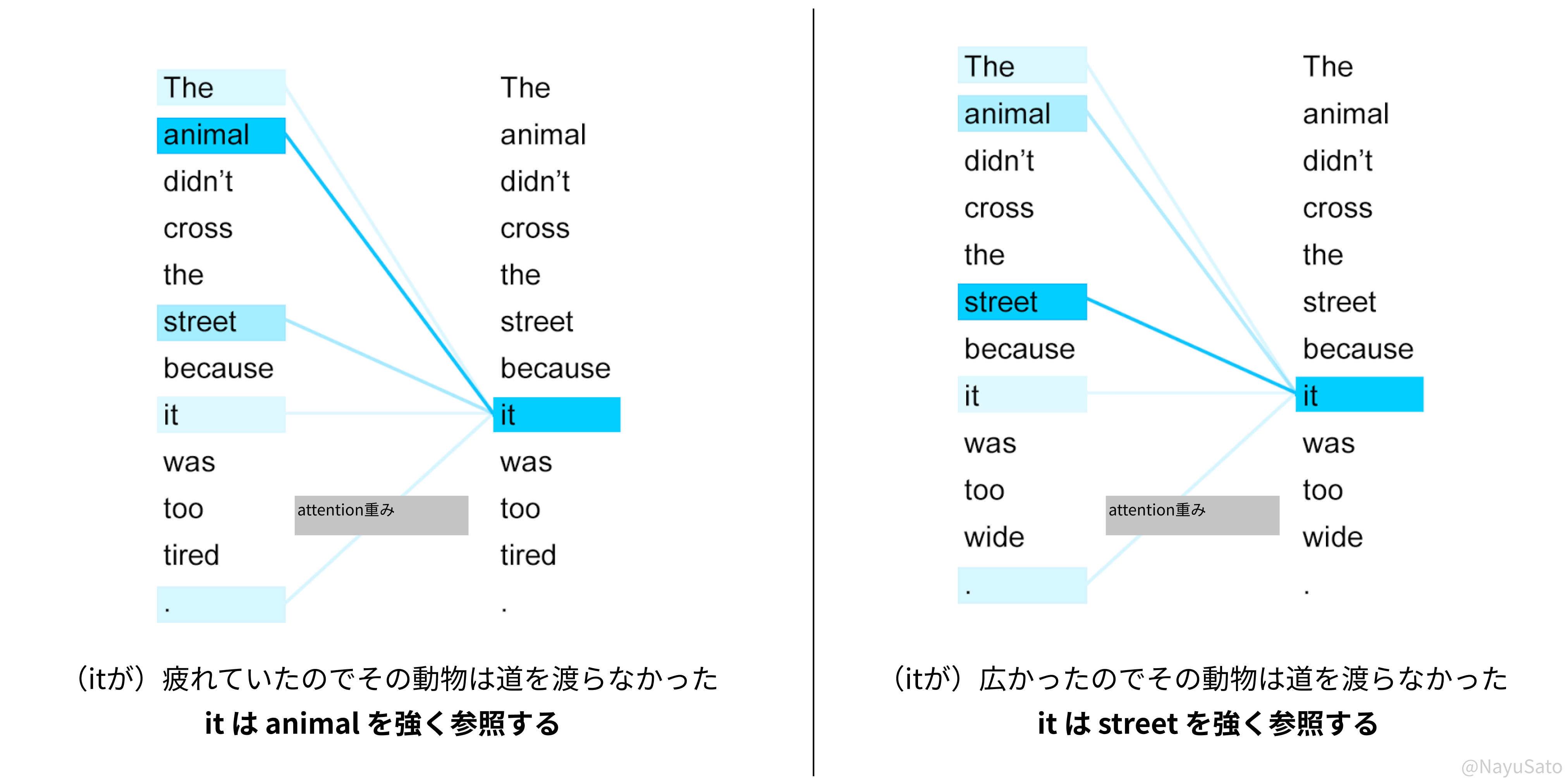
Attention機構では、どのような語が前にエンコードされるかによって隠れ状態が変わってきます。そのため、計算されるAttention重みも文脈の影響を受けて変わります。
単語"it"の意味と文脈は単語単独では決まらず、その前後の入力によって決定されます。
(図はGoogle AI Blogを元に作成)
Transformerの事前学習においては、
- マスクされた1単語を予測させる
- 与えられた2つの文が隣接する2文かどうかを判断させる
などが使われます。
Attention自体には教師データがないですが、出力結果の誤差を少なくするように学習が進むことで、Transformerは文脈を獲得します。
大規模なデータの用意
Transformerの学習のためには、大規模かつ質の良いデータが必要となります。
さすがはGoogle、YouTubeを使いました。
YouTubeの利用ライセンスのあるピアノ音源の動画を用いて、数十万もの音声データを用意。
このデータは音声データですが、Googleが別途開発した、音声データ→楽譜形式(正確にはMIDIのような形式)に変換する技術3を活用して、データを変換し、
1万時間もの質の良い学習データを作り出しました4。
音楽情報の簡略化
Transformerで学習させるためには、1単語1単語に対応するベクトル (one-hot vector) を用意し、それを入力として1単語ずつ逐次的に出力を行う必要があります。
音楽では同時に音が鳴ったり、テンポが一定でなかったりするので、これをそのまま音楽に適用することはできません。
Music Transformerでは新たな楽譜形式を使っています。
(MIDIという従来の楽譜データ形式が元になっている)
- 88段階の音程のNOTE_ON:音の始まりを表す
(最低音のラ~最高音のドの88段階) - 88段階の音程のNOTE_OFF:音の終わりを表す
- 10 ms刻みのTIME_SHIFT:時間軸を進めることを表す
(10, 20, 30, ... , 1000 ms) - 32段階のSET_VELOCITY:次の音の強さを表す
(4, 8, 12, ... , 128)
5
これを用いると、次の例のように「ドーミーソー(休)ファ」を離散のトークンの列として表すことができます。

(Huang et al., 2018より引用)
これで、メロディ・リズム・和音を全てベクトルの列として扱う準備ができました。
実際には、このトークンをone-hot vector6として入力することで学習・生成が行われます。
学習の際は、音楽データの系列から、続きのトークンを予測させることによって、教師あり学習を行います。
Music Transformerの生成方法
Music Transformerは逐次的に1トークンずつを生成します。
前に入力されたトークンによって決まる隠れ状態によって、Attention重みが決定します。
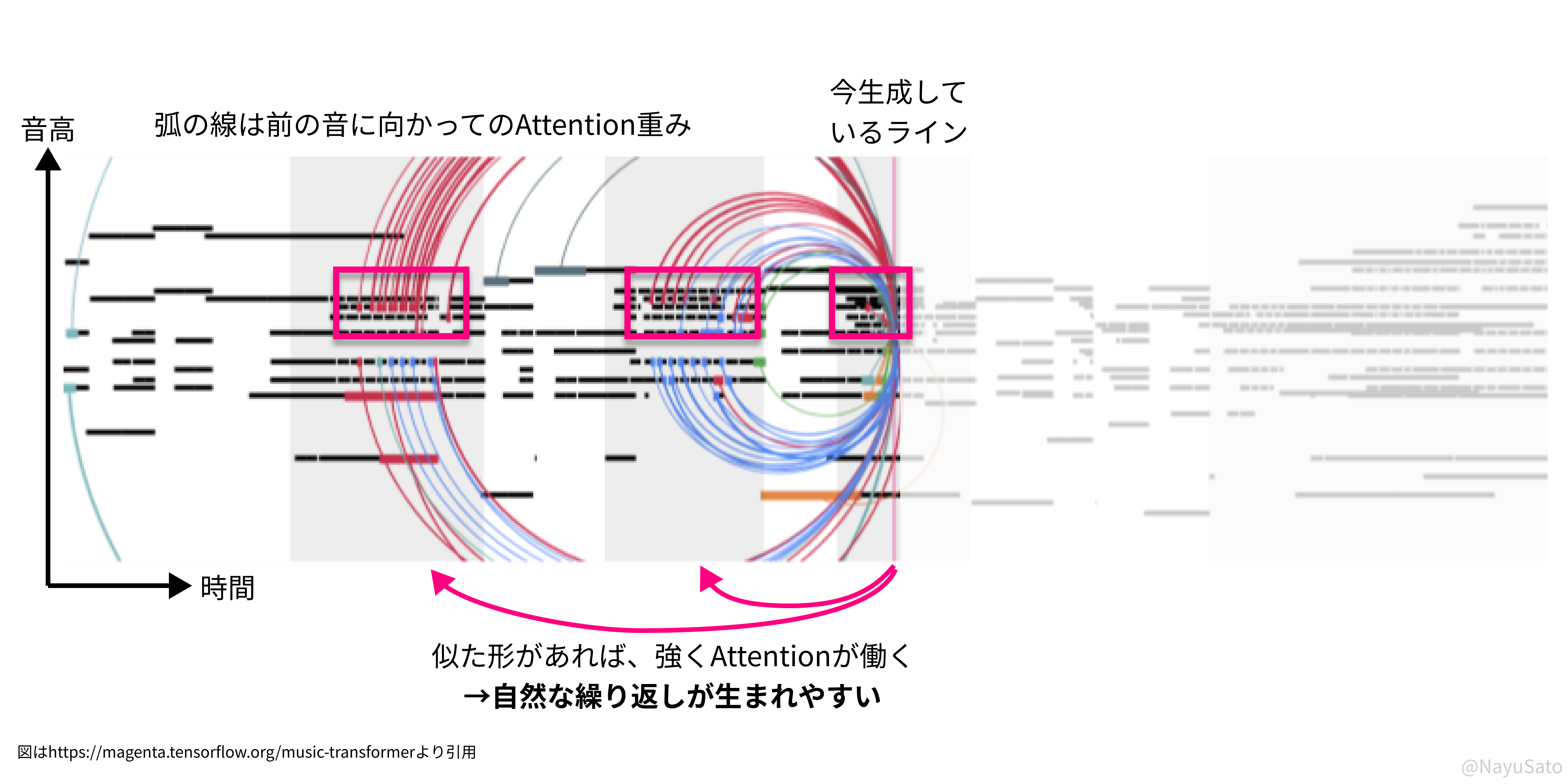
Attention重みを可視化したのが、この図。弧がAttention重みを表しています。
前の音に似た形の音が入力されれば、前の音を強く参照するため、繰り返しが生まれてきやすくなります。
例えば、「ドレミファ」という音が事前に入力された後に、また「ドレ」という音が入力されると、
Attention重みは時間を隔てた「ドレミファ」に強く働くようになります。
そのため、「ドレミファ」という音がまた繰り返されやすくなります。
実際には、次の音の予測は分布として表されます。この場合だと「ドレ」の次には「ミ」が最も来やすいが、「ド」の可能性もある、といった形です。
最後に、出力された分布をsoftmax関数に通し、確率的に1つの音を決定します。
確率が高い音は選ばれやすいですが、確率の低い音もたまに選ぶため、生成するたびに多様な音楽が出力されます。
Music Transformerを使ってみよう
Google公式のColab:
https://colab.research.google.com/notebooks/magenta/piano_transformer/piano_transformer.ipynb
実際に生成してみた曲がこれ。
See the Pen GeneratedMusic by NayuSato (@nayusato) on CodePen.
なんちゅう悲しい曲になってしまったんだ……月の光が見えない深い夜になってしまいました。
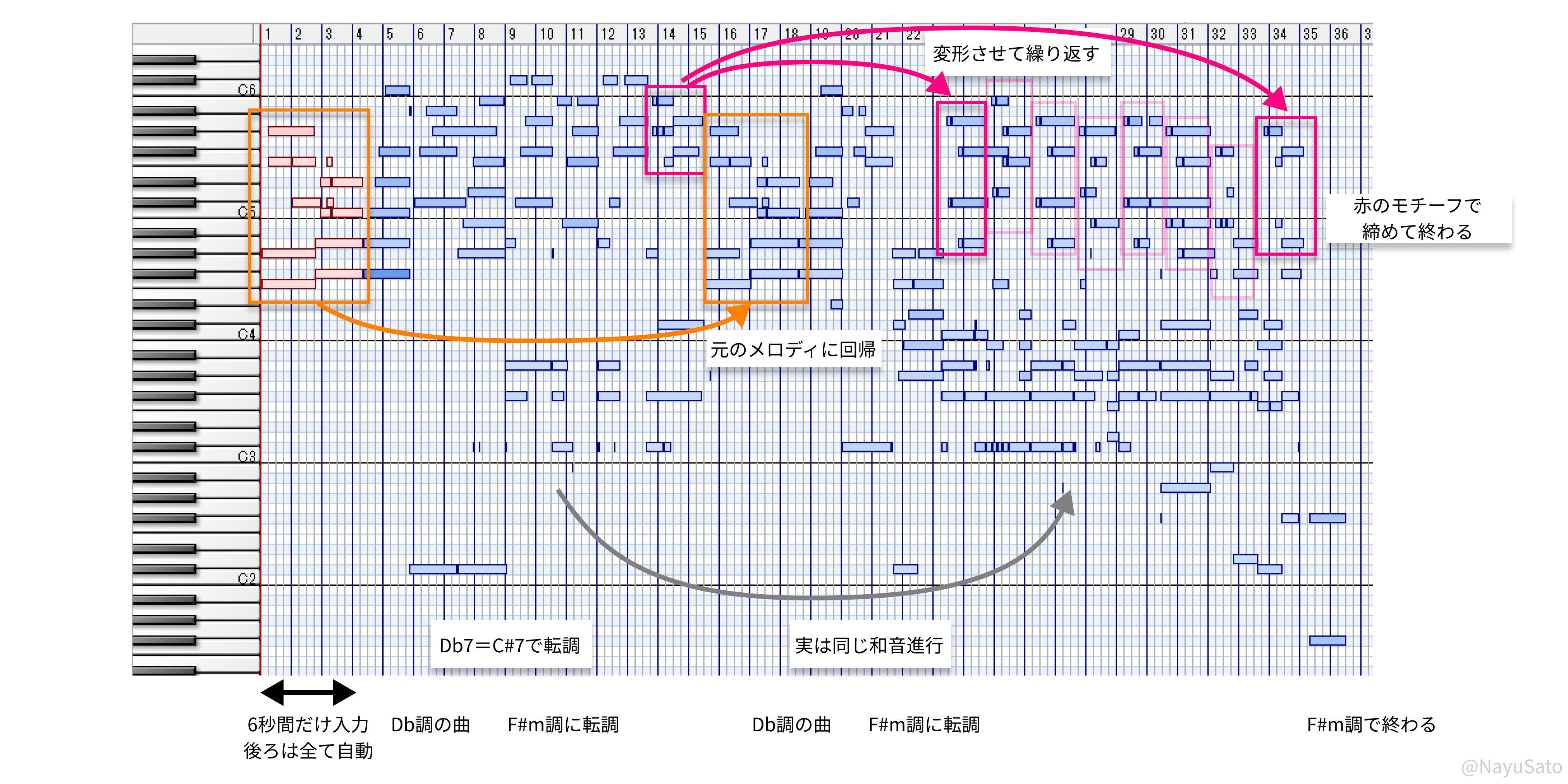
せっかくなので音楽理論的に分析してみました。
- 音楽理論的には、冒頭のD♭調からD♭7をドミナントのC#7として捉えて、暗いF#m調に転調している
- 途中で冒頭のメロディに戻ってきている
- 後半はもう一度転調した後、同じモチーフを変形させて何回も繰り返している
…みたいに深読みできるくらいにはちゃんとした曲に仕上がっています。
Mucic Transformerが解決した2つの課題
上記の説明にもある繰り返しを自然に作れるというのはすごい技術革新だったのです。
Music Transformer以前にも自動作曲の技術は多くありましたが、主に2つの課題がありました。
課題1:繰り返しが作れない
音楽には時間的構造があります。
米津玄師の「Lemon」を例に取ると、
「♪あの日の悲しみさえ」:主題の提示
「♪あの日の苦しみさえ」:同じ主題の繰り返し
こういう隣接した繰り返しもあれば、
「♪どこかであなたが今」:2番でもう一度繰り返し
のように、1番と2番のように離れたところでの繰り返しもあります。
このような様々な時間スケールにおける繰り返しが存在しています。
クラシックにおいても、
提示部(主題の提示)・展開部(違うことする)・再現部(最初の主題に戻ってくる)
となっていて、長い時間スケールにおける繰り返しが存在しています。
時間的に、前のものに依存しながら生成するアルゴリズムとしては、RNN (Recurrent Neural Network)がありますが、繰り返しをうまく生めていない点が課題でした。
(RNN:出力層を入力層に繋ぐことによって、時系列データを生成する手法)
RNNを用いた手法としては、GoogleのPerformance RNN(2017年)があります。
それっぽい雰囲気の曲は作れるものの、RNNだと生成を続けるほどに時間的に古い情報が薄まっていくので、長期的な時間的構造を持たすには向いていません。
結果、繰り返しがなく、とりとめもない曲が生み出されてしまいます。
繰り返しのない音列は音楽とは言いがたい。
人は、音楽を聴きながら「次の音は何かな?」と予測し、その予測が当たったり外れたりすることによって感情が動かされていると考えられています。7
この繰り返しをうまく作れないと、聴きやすい音楽にはなりません。
この観点で最初の音源をもう一度聴いてもらうと、39秒のところで冒頭のメロディに戻ってきています。
勝手に繰り返しが作れています。(しかもちょっとアレンジが入る)
情報が薄まってしまう従来手法ではこれはなし得なかったことです。
課題2:文脈の影響をうまく表現できない
音楽には文脈性があります。
前に来たものによって、調が決まり、スケールが決まり、またリズムとメロディと和音も相互に絡み合っています。
文脈性を遷移確率として扱う手法としては、遷移確率を用いた方法があります。
ドの次にレに行く確率は0.4、ドの次にド#に行く確率は0.1などのように、音から音への遷移を確率的に扱い、それに沿って音をサンプリングし生成していく手法。
学習データから遷移確率(≒出現頻度)を算出して、それを基に生成すれば、学習データと似た構造の音楽を作ることができます。
例えば、「ドの次にドレミファソラシの音は来やすいが、ド#などの半音は来づらい」などのような音楽構造を数式的に定義することができます。
ただ、これには欠点が2つあります。
-
長い時系列になるほど扱いにくい
例えば、ド→レ→ミ→ファ→ソの遷移が起きやすいことを表そうとすると、4次の遷移確率まで定義する必要がある。実際上無限の次数を定義することは難しく、遷移確率の学習をするのも難しい。 -
メロディ・リズム・和音を統一的に扱うのは難しく、その相互作用を表せない
この3要素は互いに絡み合っていて、和音が決まることでメロディに制約がかかったり、メロディによって次に起こりそうなリズムが決まったりする。これを扱うためには、メロディ・和音・リズムのそれぞれの遷移確率を定義した上で、その相互作用の定式化までせねばならず現実的ではない。
この観点で冒頭の音源を聴いてみると、冒頭から途中までD♭調の和音とスケールで、リズムも4拍子になっていて、1つの文脈が引き継がれています。
これらは指定しておらずたった6秒の冒頭を与えただけなのに。
これらの課題を自然言語処理アルゴリズムと大規模なデータとで打ち破ったのがMusic Transformerでした。
ぜひMusic Transformerを触って作曲してみてください。
参考文献
- Music TransformerのGoogleの元記事
Music Transformer: Generating Music with Long-Term Structure - Googleの記事の第2弾
Generating Piano Music with Transformer - 論文
Huang et al. (2018) Music Transformer: Generating Music with Long-term Structure - Pop音楽に適用した例
Pop Music Transformer: Beat-based Modeling and Generation of Expressive Pop Piano Compositions - 中山光樹(2020) 「機械学習・深層学習による自然言語処理入門」
この記事を読んで「面白かった」「学びがあった」と思っていただけた方、よろしければ Twitter や facebook、はてなブックマークにてコメントをお願いします!
また DeNA 公式 Twitter アカウント @DeNAxTech では、 Blog記事だけでなく色々な勉強会での登壇資料も発信してます。ぜひフォローして下さい!
Follow @DeNAxTech
-
LSTMを用いた作曲の例はこれなど。How to Generate Music using a LSTM Neural Network in Keras ↩
-
Attentionはあくまで用語であり、心理学・神経科学におけるAttentionが同じ機構であることを意味しません(似た構造で時間情報処理をしていたらとっても面白いけど)。 ↩
-
そう簡単には他社や研究機関が追随できるデータ量ではない。サービスを行いながら研究活動をする企業が研究も強いのだなぁと思う。 ↩
-
加えて、paddingとeos(終了符)が存在する ↩
-
n次元ベクトルの中の1箇所だけが1で、他が全て0となるベクトル。例えば、事前に{ド、レ、ミ}と表すように決めておけば、「ド」={1,0,0}、「レ」={0,1,0}と表すことができる。 ↩
-
神経科学においては近年、音楽において快感情を感じるのは、予測が確実に立つ中での大きな予測のズレ(Surprise)の瞬間であることが示唆されている(Cheung et al., 2019)。繰り返しがない場合、予測が立たず、それゆえズレも生まれず、「なにこの曲…」となってしまう。程よく繰り返して、程よくはずす程度の、繰り返しと変化が音楽には必要である。 ↩