応用情報技術者試験の出題範囲内の AI 技術の概要と実装

はじめに
はじめまして。私は現在、応用情報技術者試験の合格に向けて勉強をしている者です。
この記事では、応用情報技術者試験の出題範囲内の AI 技術の概要の説明と Python で(特に、ディープラーニングの技術について)実装をしたいと思います。また、ChatGPT を使った実験も行います。
シラバスに登場している用語について、概要と実装をしましたが、ここまで細かく出ないと思います。気軽に読んでください。
ちなみに、タイトルの下に載せた画像は、拡散モデルにこの記事のタイトルを入れたら生成された画像です。技術の進歩に驚きますね。
この記事が、応用情報技術者の AI 技術を学習する人の参考になれば幸いです。
環境
Google Colaboratory と ChatGPT を使います。
フレームワーク
使用するフレームワークは、PyTorch を使用します。
PyTorch とは?
PyTorch は、オープンソースのディープラーニングライブラリで、主に自然言語処理やコンピュータビジョンなどの機械学習アプリケーションで使用されます。
-
動的計算グラフ:PyTorch は動的計算グラフを採用しており、これによりネットワークの各ステップで計算グラフを動的に生成します。これにより、デバッグや開発がより直感的かつ柔軟になります。
-
Python との統合:PyTorch は Python と密接に統合されており、使いやすさと読みやすさが重視されています。Pythonの既存のエコシステムとシームレスに連携します。
-
GPU サポート:PyTorch は NVIDIA の CUDA を利用して、GPU での高速な計算をサポートします。これにより、大規模なニューラルネットワークのトレーニングが効率的に行えます。
-
豊富なライブラリとツール:PyTorch には、トレーニングと評価のためのさまざまなツールやライブラリが含まれています。
-
コミュニティとサポート:PyTorch は広範なユーザーコミュニティを持ち、活発な開発とサポートが行われています。オンラインフォーラムや公式ドキュメント、チュートリアルなどが豊富に提供されています。
チュートリアル
AI 技術の概要
AI の基本的な考え方
知識工学
知識工学とは、AI や情報システムの分野において、人間の知識を形式化し、コンピュータシステムで利用できる形にするための学問です。
学習理論
学習理論は、機械学習アルゴリズムの性能を理解し、評価し、改良するための理論的枠組みです。この分野は、数学、統計、計算理論の技術を駆使して、アルゴリズムがどのように学習し、どのように一般化するかを研究します。
汎化
汎化とは、モデルが学習データで学んだパターンや知識を、見たことのない新しいデータにも適用できる能力のことを指します。
エキスパートシステム
エキスパートシステムは、特定の専門分野における人間の専門家の知識と判断を模倣するために設計された AI の一種です。これらのシステムは、特定の問題に対する推論を行い、アドバイスや診断を提供するために使用されます。
解析型問題
解析型問題は、数理的または統計的手法を用いてデータを解析し、洞察や予測を導き出す問題を指します。
合成型問題
合成型問題とは、AI や機械学習の分野において複数の異なる部分問題を組み合わせて解決する問題のことを指します。これらの問題は、個別のサブタスクやモジュールが協力して全体の解を導くことが必要です。
知識ベース
知識ベースとは、AI の研究と応用において使用されるデータと情報の集まりを指します。
推論エンジン
推論エンジンとは、AI システムにおいて知識を活用して推論を行い、意思決定や問題解決を支援するソフトウェアコンポーネントのことを指します。
機械学習
機械学習は、データを用いてアルゴリズムを訓練し、予測や分類を行う技術です。機械学習のアルゴリズムは、与えられたデータに基づいてモデルを作成し、そのモデルを使って新しいデータに対する予測を行います。
教師あり学習
教師あり学習は、入力データとそれに対応する正解ラベル(出力)を用いてモデルを訓練する方法です。モデルは訓練データから学習し、新しい入力データに対する予測を行います。
回帰
回帰は、連続値の予測を目的とした手法です。入力データに基づいて数値を予測するために使われます。回帰モデルの目標は、入力変数(特徴量)と連続値の出力変数(ターゲット)との関係を見つけることです。
分類
分類は、カテゴリ(ラベル)を予測することを目的とした手法です。入力データに基づいてデータがどのカテゴリに属するかを予測します。分類モデルの目標は、入力変数(特徴量)とカテゴリカルな出力変数(ターゲット)との関係を見つけることです。
教師なし学習
教師なし学習は、入力データに対する正解ラベルがない場合に使用される方法です。データのパターンや構造を見つけ出すことを目的としています。
クラスタリング
クラスタリングは、データを類似したグループ(クラスター)に分ける手法です。各クラスター内のデータポイントは互いに似ており、異なるクラスターのデータポイントとは異なると見なされます。
次元削減
次元削減は、高次元のデータをより低次元に変換することで、データの構造を保持しながら計算の効率を上げる手法です。
半教師あり学習
半教師あり学習は、少量のラベル付きデータと大量のラベルなしデータを組み合わせて学習を行う機械学習の手法です。完全にラベル付きデータを使用する教師あり学習と、全くラベルを使用しない教師なし学習の中間に位置します。
強化学習
強化学習は、エージェントが環境と相互作用しながら報酬を最大化するための行動方策を学ぶ機械学習の一分野です。
線形回帰
線形回帰は、$1$ つまたは複数の独立変数(説明変数)を用いて、従属変数(目的変数)を予測します。従属変数は連続値です。
ロジスティック回帰
ロジスティック回帰は、$1$ つまたは複数の独立変数を用いて、従属変数が特定のクラスに属する確率を予測します。従属変数は $0$ または $1$ の二値です。
決定木
決定木は、機械学習アルゴリズムの一種であり、分類や回帰の問題を解決するために使用されます。決定木は、木のような構造を持つモデルで、入力データを条件に従って分割していくことで予測を行います。
-
特徴量の選択:各ノードで、データを最もよく分割する特徴量を選びます。
-
データの分割:選ばれた特徴量の値に基づいてデータを分割します。分割後、各サブセットに対して再帰的に分割を行います。
-
停止条件:データがこれ以上分割できない場合や、最大深さに達した場合、または他の停止条件に基づいて、分割を終了します。
ランダムフォレスト
ランダムフォレストは、機械学習のアンサンブル学習の一つで、決定木の集合を用いて予測を行います。
-
元のデータセットからブートストラップサンプリングを行い、複数のサブデータセットを作成します。
-
各サブデータセットについて、ランダムに選ばれた特徴量のサブセットを使って決定木を構築します。
サポートベクトルマシン
「サポートベクトルマシン」は、「SVM」とも言います。
サポートベクトルマシンは、機械学習の中でも特に分類問題においてよく使用される手法です。サポートベクトルマシンは、データポイントを異なるクラスに分類するための超平面を見つけることを目的としています。
-
学習:学習データセットを用いて、最も近いデータポイント(サポートベクトル)と超平面を見つけるための最適化問題を解きます。これにより、モデルが構築されます。
-
予測:新しいデータポイントが与えられた場合、構築された超平面を基にそのデータポイントがどのクラスに属するかを予測します。
主成分分析
主成分分析は次元削減手法の一つで、データの情報をできるだけ失わずに次元を減らすことを目的としています。高次元データを低次元の空間に変換することで、データの可視化や処理を容易にします。
-
データの中心化:データセットの各変数の平均を引いて中心化します。
-
共分散行列の計算:中心化したデータの共分散行列を計算します。
-
固有ベクトルと固有値の計算:共分散行列の固有ベクトルと固有値を計算します。
-
次元削減:固有値が大きい順に対応する固有ベクトルを選び、新しい低次元空間を構築します。選ばれた固有ベクトルは「主成分」と呼ばれます。
k-means 法
k-means 法はクラスタリング手法の一つで、データを $k$ 個のクラスタに分けることを目的としています。各クラスタは、クラスタ中心(センチロイド)に最も近いデータポイントで構成されます。
-
初期化:データセット内からk個の初期クラスタ中心をランダムに選びます。
-
クラスタ割り当て:各データポイントを最も近いクラスタ中心に割り当てます。
-
クラスタ中心の更新:各クラスタの中心を、そのクラスタに属するデータポイントの平均に更新します。
-
収束判定:クラスタ中心が変化しなくなるまで、上二つのステップを繰り返します。
Q 学習
Q 学習は、強化学習の一種で、エージェントが環境と相互作用しながら最適な行動方策を学習するアルゴリズムです。
-
初期化:Q 値を任意の値(通常は $0$)で初期化します。
-
行動選択:エージェントは現在の状態において、最も高い Q 値を持つ行動を選択します(または探索を行うためにランダムに行動を選択することもあります)。
-
行動実行と観察:エージェントは選択した行動を実行し、新しい状態と報酬を観察します。
-
Q 値の更新:Q 値は以下の式に基づいて更新されます。ここで、$\alpha$ は学習率、$\gamma$ は割引率、$r$ は現在の報酬、$s^\prime$ は新しい状態、$\overset{}{\underset{a^\prime}{\max}} Q(s^\prime, a^\prime)$ は新しい状態での最大の Q 値です。
Q(s, a) \leftarrow Q(s, a) + \alpha [r + \gamma \overset{}{\underset{a^\prime}{\max}} Q(s^\prime, a^\prime) - Q(s, a)]
- 反復:上記のステップを繰り返し行い、最適な行動方策を学習します。
方策勾配法
方策勾配法は、強化学習における主要な手法の一つで、方策を直接最適化する方法です。方策勾配法は、方策をパラメータ化し、そのパラメータを更新することで方策を改善していきます。
-
方策のパラメータ化:方策は通常、パラメータ $\theta$ を持つ確率分布 $\pi_\theta(a|s)$ として表現されます。ここで $a$ は行動、$s$ は状態を表します。
-
目的関数の定義:方策の性能を評価するための目的関数 $J(\theta)$ を定義します。これは通常、期待累積報酬の形をとります。
-
方策勾配定理:方策勾配法の基礎となる理論であり、目的関数 $J(\theta)$ の勾配 $\nabla_\theta J(\theta)$ を効率的に計算する方法を提供します。この勾配は、方策のパラメータを更新するために使用されます。ここで $Q^{\pi_\theta}(s, a)$ は行動価値関数です。
\nabla_\theta J(\theta) = \mathbb{E}_{\pi\_\theta} [\nabla\_\theta \log \pi\_\theta(a|s) Q^{\pi\_\theta}(s, a)]
- 勾配上昇法:勾配を使って方策のパラメータを更新します。ここで $\alpha$ は学習率です。
\theta \leftarrow \theta + \alpha \nabla_\theta J(\theta)
- サンプルベースの推定:実際の問題では、上記の期待値はモンテカルロサンプリングや時間差分法を使って近似されます。
価値反復法
価値反復法は、強化学習における動的計画法の一種で、特にマルコフ決定過程の最適な方策を求めるために使用されます。マルコフ決定過程は、状態、行動、遷移確率、および報酬から構成される数学的モデルであり、価値反復法はこれを用いて各状態の価値関数を反復的に計算し、最適な行動を導き出します。
-
初期化:すべての状態 $s$ の価値 $V(s)$ を任意の値(通常は $0$)に初期化します。
-
更新:各状態 $s$ に対して、以下の更新式を用いて価値関数 $V(s)$ を更新します。ここで、$a$ は行動、$P(s^\prime|s, a)$ は状態 $s$ から行動 $a$ を取ったときに次の状態 $s^\prime$ になる確率、$R(s, a, s^\prime)$ は状態 $s$ で行動 $a$ を取ったときに得られる報酬、$\gamma$ は割引率です。
V(s) \leftarrow \overset{}{\underset{a}{\max}} \sum_{s^\prime} P(s^\prime|s, a) [R(s, a, s^\prime) + \gamma V(s^\prime)]
-
収束判定:価値関数 $V(s)$ の変化が十分に小さくなるまで(あるいは一定の反復回数まで)更新を繰り返します。
-
方策の導出:価値関数 $V(s)$ が収束した後、最適な方策 $\pi(s)$ を以下のように導出します。
\pi(s) = \arg \overset{}{\underset{a}{\max}} \sum_{s^\prime} P(s^\prime|s, a) [R(s, a, s^\prime) + \gamma V(s^\prime)]
ハイパーパラメータ
ハイパーパラメータは、学習プロセスやモデルの構造に直接影響を与える設定値で、モデルの性能や訓練の効率を調整するために使用されます。ハイパーパラメータはモデルの訓練前に設定され、モデルのパラメータとは異なり、訓練中に学習されません。
ランダムサーチ
ランダムサーチは、ハイパーパラメータの最適化手法の一つです。機械学習モデルの性能を最大化するために、モデルにはさまざまなパラメータを適切に設定する必要があります。これらのパラメータを最適に選ぶことは、モデルのトレーニングや予測性能に大きな影響を与えます。
-
ランダムにサンプリング:ハイパーパラメータの範囲内からランダムにサンプリングを行います。
-
モデルの評価:各ハイパーパラメータの設定に基づいてモデルをトレーニングし、検証データセットを使用してモデルの性能を評価します。
グリッドサーチ
グリッドサーチは、機械学習モデルのハイパーパラメータの最適な組み合わせを見つけるための手法の一つです。
-
すべての組み合わせを試行:定義したすべてのハイパーパラメータの組み合わせを試行します。
-
モデルの評価:各ハイパーパラメータの組み合わせごとにモデルを学習し、性能を評価します。
-
最適な組み合わせの選択:評価結果に基づいて、最も良い性能を示したハイパーパラメータの組み合わせを選びます。
学習率
学習率は、機械学習アルゴリズムにおいて、各イテレーションまたはエポックでモデルのパラメータを更新する量を決定するハイパーパラメータです。
この記事では、学習率を lr としています。
学習データ
「学習データ」は、「訓練データ」とも言います。
学習データは、モデルがパターンや関係を学ぶために使用するデータセットです。モデルはこのデータを基にして、入力と出力の関係を学習します。学習データが多いほど、モデルはより正確に学習することができます。
この記事では、学習データを train_dataset としています。
検証データ
検証データは、学習データとは別に分けておくデータセットです。モデルが学習する際に過学習しないように、学習中にモデルの性能を評価し、ハイパーパラメータを調整するために使用されます。検証データの役割は、モデルが未知のデータに対してどの程度の性能を発揮するかを推測することです。
この記事では、検証データを val_dataset としています。
テストデータ
テストデータは、モデルの最終的な性能を評価するためのデータセットです。モデルのトレーニングやチューニングがすべて完了した後、このデータを使ってモデルの凡化性能を評価します。テストデータは、モデルのトレーニングや検証の過程では一切使用しないことが重要です。これにより、モデルの真の性能を測定することができます。
この記事では、テストデータを test_dataset としています。
凡化性能
凡化性能とは、機械学習モデルが未知のデータに対してどれだけうまく予測できるかを示す指標です。モデルが学習データだけでなく、実際の環境で新しいデータに対しても正確に予測できる能力を意味します。モデルが過学習していないことを確認するための重要な要素です。
凡化誤差
凡化誤差は、モデルが新しいデータに対してどれだけ誤差を生じるかを示します。凡化誤差が小さいほど、モデルは新しいデータに対しても良い予測を行えるといえます。
この記事では、凡化誤差を val_loss としています。
訓練誤差
訓練誤差は、モデルが学習データに対してどれだけ誤差を生じるかを示します。訓練誤差が小さいほど、モデルは学習データに対してうまくフィットしていることを意味します。しかし、訓練誤差が小さくても、必ずしも凡化性能が高いわけではありません。過学習の場合、訓練誤差は非常に小さくなりますが、凡化誤差は大きくなることがあります。
この記事では、訓練誤差を train_loss としています。
過学習
過学習とは、機械学習モデルが学習データに対して非常に高いパフォーマンスを示すが、未知のデータに対してはパフォーマンスが低下する現象を指します。これは、モデルが学習データのノイズや詳細なパターンまで学習してしまい、凡化性能が低下するために起こります。
バイアスとバリアンスのトレードオフ
「バイアスとバリアンスのトレードオフ」は、機械学習モデルの性能を理解し、改善する上で重要な概念です。
バイアスは、モデルの予測が実際の値からどれだけずれているかを示します。バイアスが高いモデルは、学習データに対して過学習することなく、全体的な傾向を捉えようとしますが、その結果、細部を無視してしまうことがあります。
バリアンスは、モデルが学習データの小さな変動に対してどれだけ敏感であるかを示します。バリアンスが高いモデルは、訓練データの細部に過剰に適合し、学習データでは高い精度を持つものの、新しいデータに対してはパフォーマンスが低下する可能性があります。
バイアスとバリアンスのトレードオフは、モデルがバイアスとバリアンスの間でバランスを取る必要があることを意味します。理想的なモデルは、バイアスとバリアンスのバランスが取れたモデルです。このバランスを見つけることが、機械学習モデルの性能を最大限に引き出すための鍵となります。
AI のロバスト性
AIのロバスト性は、モデルがさまざまな状況や入力データに対してどれだけ安定して正確なパフォーマンスを維持できるかを指します。
正則化
正則化は、モデルが過学習しないようにするための手法です。
アンサンブル学習
アンサンブル学習は、複数の機械学習モデルを組み合わせて予測精度を向上させる手法です。個々のモデルが持つ弱点を補完し合い、全体の性能を向上させることを目的としています。
交差検証
交差検証は、機械学習モデルの性能を評価するための方法の一つです。データを複数のサブセットに分割し、モデルの凡化性能をテストすることができます。
ホールドアウト検証
ホールドアウト検証は、機械学習モデルの評価手法の一つで、データセットを学習セットとテストセットに分割し、モデルの性能を評価する方法です。
-
データの分割:データセットをランダムに学習セットとテストセットに分けます。
-
モデルのトレーニング:学習セットを用いて機械学習モデルを訓練します。
-
モデルの評価:テストセットを用いて訓練したモデルの性能を評価します。このステップでモデルの凡化性能を確認します。
正解率
正解率は、全ての予測の中で正しく予測されたものの割合を示します。
\mathrm{正解率} = \frac{\mathrm{真陽性} + \mathrm{真陰性}}{\mathrm{真陽性} + \mathrm{偽陽性} + \mathrm{真陰性} + \mathrm{偽陰性}}
この記事では、学習データ、検証データに対する正解率をそれぞれ train_acc、val_acc としています。
適合率
適合率は、正と予測されたサンプルの中で実際に正であるサンプルの割合を示します。
\mathrm{適合率} = \frac{\mathrm{真陽性}}{\mathrm{真陽性} + \mathrm{偽陽性}}
再現率
再現率は、実際に正であるサンプルの中で正と予測されたサンプルの割合を示します。
\mathrm{再現率} = \frac{\mathrm{真陽性}}{\mathrm{真陽性} + \mathrm{偽陰性}}
F 値
F 値は、適合率と再現率の調和平均であり、両者のバランスをとった指標です。
\mathrm{F 値} = 2 \cdot \frac{\mathrm{適合率} \cdot \mathrm{再現率}}{\mathrm{適合率} + \mathrm{再現率}}
ROC 曲線
ROC 曲線は、分類モデルの性能を視覚的に評価するためのグラフです。横軸に偽陽性率、縦軸に真陽性率を取ります。
PR 曲線
PR 曲線は、特にデータが不均衡な場合にモデルの性能を評価するためのグラフです。横軸に再現率、縦軸に適合率を取ります。
AUC
AUCは、「曲線下の面積」を意味し、ROC 曲線または PR 曲線の下の面積を表します。これにより、モデルの全体的な性能を一つの数値で評価できます。
ディープラーニング
「ディープラーニング」は、「深層学習」とも言います。
ディープラーニングは、ニューラルネットワークを使用してデータから複雑なパターンを学習する技術です。特に、複数の層を持つニューラルネットワークを使用します。ディープラーニングは、大量のデータと計算リソースを必要としますが、特定のタスクで非常に高い性能を発揮します。
ニューラルネットワーク
ニューラルネットワークは、生物の脳のニューロン(神経細胞)の働きを模倣した計算モデルです。基本的な構造としては、入力層、隠れ層(中間層)、出力層の $3$ つの層から成ります。各層には複数のノード(ニューロン)があり、これらのノードが互いに接続されています。
多層パーセプトロン
多層パーセプトロンは、ニューラルネットワークの一種で、複数の隠れ層を持つことで特徴付けられます。各層のノードは前の層のノードすべてに接続されています。
from torch import nn
import torch.nn.functional as F
class MLP(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, hidden_size)
self.fc3 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
バックプロパゲーション
「バックプロパゲーション」は、「誤差逆伝播法」とも言います。
バックプロパゲーションは、人工ニューラルネットワークの学習アルゴリズムの一つで、特に誤差を効率的に計算して重みを更新するために使用されます。
-
順伝播:入力データをネットワークに通し、各層の出力を計算します。最終的にネットワークの出力を得ます。
-
誤差の計算:出力と正解データ(ターゲット)との誤差を計算します。通常、損失関数を使用して誤差を定量化します。
-
逆伝播:出力層から開始し、誤差を逆方向に伝播させます。各ニューロンの誤差寄与度を計算し、それに基づいて重みの勾配を求めます。
-
重みの更新:勾配降下法を用いて、各重みを更新します。
この記事では、バックプロパゲーションを loss.backward() としています。
勾配消失問題
勾配消失問題とは、ニューラルネットワークの訓練において、特に深いネットワークで発生する問題です。最初の層の重みがほとんど更新されず、学習が遅くなったり、停止してしまうことがあります。
活性化関数
活性化関数は、ニューラルネットワークにおいて入力された信号に対して出力信号を変換するために使われる関数です。活性化関数は、ネットワークが学習する能力や問題を解く能力に大きく影響を与えます。
ReLU 関数

ReLU関数は非常にシンプルで、計算が高速です。特に大規模なニューラルネットワークにおいて、このシンプルさが重要です。
$$
f(x) = \max(0, x)
$$
import torch
from torch import nn
m = nn.ReLU()
input = torch.randn(2)
output = m(input)
ソフトマックス関数
ソフトマックス関数は入力ベクトルを確率分布に変換します。出力の各要素は $0$ から $1$ の間にあり、全体の和は $1$ になります。
f(x_i) = \frac{\exp(x_i)}{\sum_j \exp(x_j)}
import torch
from torch import nn
m = nn.Softmax(dim=1)
input = torch.randn(2, 3)
output = m(input)
tanh 関数
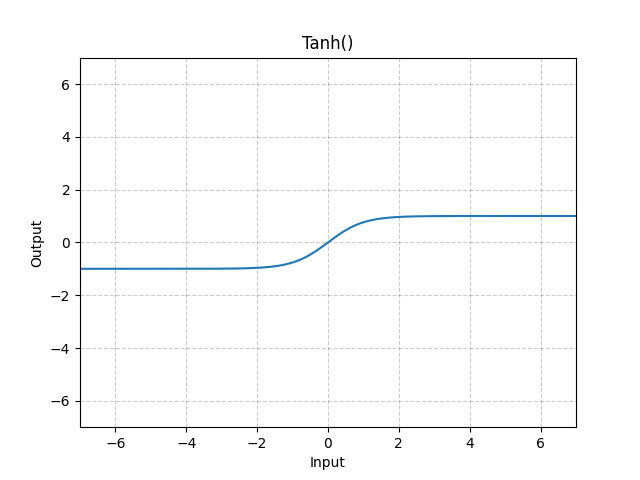
$-1$ から $1$ の間の値を取ります。
$$
f(x) = \tanh(x) = \frac{\exp(x) - \exp(-x)}{\exp(x) + \exp(-x)}
$$
import torch
from torch import nn
m = nn.Tanh()
input = torch.randn(2)
output = m(input)
ドロップアウト
ドロップアウト 1 は、ニューラルネットワークの学習中にランダムに選ばれたニューロン(ノード)を一時的に無効化する手法です。これにより、ネットワークの異なる部分が異なる学習を行うため、モデルの凡化性能が向上します。
- 学習時:各エポックでランダムに選ばれたニューロンが無効化されます。無効化されたニューロンは、そのエポックの間、重みの更新に寄与しません。
- 推論時:推論時にはすべてのニューロンが有効になります。ドロップアウトを適用した際のニューロンの数に応じて、ニューロンの出力をスケーリングします。
import torch
from torch import nn
m = nn.Dropout(p=0.2)
input = torch.randn(20, 16)
output = m(input)
事前学習
事前学習は、ある大規模なデータセットを使ってモデルを最初にトレーニングするプロセスです。この段階で、モデルは多くの一般的な特徴を学習します。
ファインチューニング
ファインチューニングは転移学習の一部であり、事前学習済みモデルの全体または一部を新しいタスクに対して再訓練するプロセスです。これにより、新しいタスクに特化した特徴をモデルに学習させます。
転移学習
転移学習は、あるタスクで学習したモデルやそのパラメータを別のタスクに応用する技術全般を指します。この方法は、元のタスクで得た知識を、新しいタスクに役立てることを目的としています。
バッチ学習
バッチ学習では、全ての学習データを一度に使ってモデルを学習します。つまり、$1$ エポックでモデルのパラメータを更新します。
ミニバッチ学習
ミニバッチ学習では、学習データをミニバッチに分けて、各ミニバッチごとにモデルを更新します。
オンライン学習
オンライン学習とは、データが連続的に到着する環境でモデルを逐次更新する手法です。データがバッチではなく、$1$ つずつまたは小さなチャンクでモデルに供給され、その都度モデルのパラメータが更新されます。
自然言語処理、音声・画像・動画の認識・合成・生成などへの応用
畳み込みニューラルネットワーク
畳み込みニューラルネットワーク 2 は、特に画像データに対して強力な性能を発揮するディープラーニングのアーキテクチャの一つです。
-
畳み込み層
- カーネル:画像の特徴を抽出するための小さな行列。カーネルは画像全体に対してスライドしながら畳み込み演算を行います。
- ストライド:カーネルをスライドさせるステップの大きさ。ストライドが大きいほど、出力のサイズは小さくなります。
- パディング:入力画像の縁に追加するピクセル。パディングを行うことで、出力のサイズを調整しやすくなります。
-
プーリング層
- マックスプーリング:各小領域内の最大値を取ることで、画像のサイズを縮小しつつ重要な情報を保持します。
- 平均プーリング: 各小領域内の平均値を取ります。
-
全結合層:畳み込み層とプーリング層で抽出された特徴をもとに、分類を行います。
-
活性化関数:畳み込み層や全結合層の出力に適用される非線形関数。
from torch import nn
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3)
self.conv2 = nn.Conv2d(32, 64, 3)
self.pool = nn.MaxPool2d(2)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 64 * 7 * 7)
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
リカレントニューラルネットワーク
リカレントニューラルネットワークは、特に時系列データやシーケンシャルデータの処理に優れたニューラルネットワークの一種です。リカレントニューラルネットワークの特徴は、入力データに対する過去の情報を利用できる点です。
h_t = \sigma(W_{hh} h_{t-1} + W_{xh} x_t + b_n)
y_t = \sigma(W_{hy} h_t + b_y)
ここで、$W_{hh}$ は隠れ状態から隠れ状態への重み行列、$W_{xh}$ は入力から隠れ状態への重み行列、$b_n$ はバイアスベクトル、$\sigma$ は活性化関数です。また、$W_{hy}$は隠れ状態から出力への重み行列、$b_y$はバイアスベクトルです。
import torch
from torch import nn
rnn = nn.RNN(10, 20, 2)
input = torch.randn(5, 3, 10)
h0 = torch.randn(2, 3, 20)
output, hn = rnn(input, h0)
LSTM
LSTM 3 は、リカレントニューラルネットワークの一種であり、特に時系列データやシーケンスデータの処理に優れています。LSTM は、通常のリカレントニューラルネットワークが持つ勾配消失問題を解決するために設計されました。
- 忘却ゲート:前のセルステート $C_{t-1}$ と現在の入力 $x_t$ を用いて、忘却ゲート $f_t$ を計算します。ここで、$W_f$ は重み、$b_f$ はバイアス、$\sigma$ はシグモイド関数です。
f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)
- 入力ゲート:現在の入力 $x_t$ と前の隠れ状態 $h_{t-1}$ を用いて、入力ゲート $i_t$ と新しいセルステートの候補 $\tilde{C}_t$ を計算します。
i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i)
\tilde{C}\_t = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C)
- セルステートの更新:セルステート $C_t$ を更新します。
C_t = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}_t
- 出力ゲート:現在の入力 $x_t$ と前の隠れ状態 $h_{t-1}$ を用いて、出力ゲート $o_t$ を計算し、現在の隠れ状態 $h_t$ を更新します。
o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o)
h_t = o_t \cdot \tanh(C_t)
import torch
from torch import nn
rnn = nn.LSTM(10, 20, 2)
input = torch.randn(5, 3, 10)
h0 = torch.randn(2, 3, 20)
c0 = torch.randn(2, 3, 20)
output, (hn, cn) = rnn(input, (h0, c0))
生成モデル
生成モデルは、データから新しいデータを生成することを目的としたモデルです。これらのモデルは、特に画像生成、テキスト生成、音声生成などで広く利用されています。
オートエンコーダ
オートエンコーダは、自己教師あり学習を用いたニューラルネットワークの一種で、データの効率的なエンコーディングとデコーディングを目的としています。
-
損失関数:通常、再構成誤差が使用されます。
-
最適化:勾配降下法やその変種を用いて、損失関数を最小化するようにネットワークのパラメータを更新します。
敵対的生成ネットワーク

 $\cdots$
$\cdots$ 
敵対的生成ネットワーク 4 は、ディープラーニングの一種です。敵対的生成ネットワークは、生成器と識別器が互いに競い合うことで、高品質なデータを生成することを目指します。
-
生成器の学習:生成器は、ランダムなノイズベクトルを入力として受け取り、それを元にデータを生成します。この生成データを識別器に渡し、識別器がそのデータを本物と判断するように生成器のパラメータを更新します。
-
識別器の学習:本物のデータと生成器が作った偽のデータを識別器に入力し、識別器が正確に区別できるように識別器のパラメータを更新します。
from torch import nn
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.network = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 1024),
nn.ReLU(),
nn.Linear(1024, 28*28),
nn.Tanh()
)
def forward(self, x):
return self.network(x).view(-1, 1, 28, 28)
from torch import nn
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.network = nn.Sequential(
nn.Linear(28*28, 1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.network(x.view(-1, 28*28))
深層強化学習
深層強化学習は、強化学習とディープラーニングを組み合わせた手法です。これにより、エージェント(学習するプログラム)が環境との相互作用を通じて行動を学習し、その行動が環境に与える影響をもとに報酬を最大化することを目指します。
基盤モデル
基盤モデルとは、特定のタスクに対してトレーニングされていない、汎用的な構造を持つニューラルネットワークモデルのことを指します。これらのモデルは、さまざまなデータセットやタスクに適用できるように設計されており、多くの場合、非常に大規模なデータセットで事前にトレーニングされています。
拡散モデル
拡散モデルは、ディープラーニングの一種です。これらのモデルは、高次元データの分布を学習し、新しいデータを生成する能力を持ちます。
-
拡散プロセス:元のデータにノイズを徐々に追加していき、最終的に純粋なノイズに変換します。拡散の各ステップでは、データが少しずつ劣化し、ノイズが増えていきます。
-
逆拡散プロセス:ノイズから元のデータを再構築する逆方向のプロセスです。これは生成のステップに相当します。ノイズから少しずつノイズを取り除いていくことで、最終的に元のデータを再構築します。
言語モデル
言語モデルは、自然言語処理において、特定の言語でのテキストのパターンや統計を学習し、次に来る単語やフレーズを予測するために使用されるモデルです。
大規模言語モデル
大規模言語モデルは、非常に大規模なデータセットでトレーニングされた言語モデルです。これらのモデルは、数十億から数千億のパラメータを持ちます。
Transformer

Transformer 5 は、ディープラーニングモデルの一つで、特に機械翻訳やテキスト生成などで高い性能を発揮します。
- エンコーダ:入力シーケンスを受け取り、その特徴を抽出します。それぞれが自己注意機構と順伝播型ニューラルネットワークを持っています。
- デコーダ:エンコーダから得られた特徴を基に、出力シーケンスを生成します。複数のデコーダー層で構成され、エンコーダと同様に自己注意機構と順伝播型ニューラルネットワークを持ちます。また、デコーダにはエンコーダの出力に対する注意機構も含まれています。
import torch
from torch import nn
transformer_model = nn.Transformer(nhead=16, num_encoder_layers=12)
src = torch.rand((10, 32, 512))
tgt = torch.rand((20, 32, 512))
out = transformer_model(src, tgt)
自己注意機構
自己注意機構は、特に自然言語処理や画像処理の分野で重要な役割を果たしています。
-
入力エンコーディング:入力シーケンスが埋め込みベクトルに変換されます。
-
クエリ、キー、バリューの生成:各入力ベクトルからクエリ、キー、バリューの $3$ つのベクトルが生成されます。これらは通常異なる重み行列を使って生成されます。ここで、$X$ は入力シーケンスの埋め込み行列、$W_Q$、$W_K$、$W_V$ は学習可能な重み行列です。
Q = X W_Q, \quad K = X W_K, \quad V = X W_V
-
注意スコアの計算:各クエリベクトルと他の全てのキーとの内積を計算し、スコアを生成します。このスコアはクエリが特定のキーにどれだけ注意を払うべきかを示します。ここで、$d_k$ はキーの次元数で、スコアをスケーリングするために使われます。
-
ソフトマックス適用:得られたスコアにソフトマックス関数を適用し、注意重みを計算します。これにより、スコアが確率的な重みに変換されます。
-
加重平均:バリューベクトルに注意重みを掛け合わせ、これらの加重平均を取ります。この加重平均が、最終的な出力ベクトルとなります。
\mathrm{Attention}(Q, K, V) = \mathrm{softmax}(\frac{Q K^T}{\sqrt{d_k}}) V
自己教師あり学習
自己教師あり学習は、データにラベルが付けられていない状態で機械学習モデルを訓練する方法の一つです。ディープラーニングにおいて、自己教師あり学習は特に有用であり、大量の未ラベルデータを活用して強力な表現を学習するために使用されます。
アラインメント
アラインメントとは、AI システムが人間の意図や目標と一致した動作をするように設計・調整するプロセスを指します。
人間のフィードバックによる強化学習

人間のフィードバックによる強化学習 67 とは、モデルがタスクを実行する際に人間の評価を取り入れて学習することを目的としています。
- 初期モデルの訓練:通常の教師あり学習などの方法で初期モデルを訓練します。このモデルは、タスクをある程度実行できるようにします。
- フィードバックの収集:モデルがタスクを実行した結果に対して、人間がフィードバックを提供します。このフィードバックは、報酬信号として使用されます。
- 報酬モデルの訓練:人間のフィードバックを基に、報酬モデルを訓練します。この報酬モデルは、モデルの出力に対してどれだけ良いか悪いかを評価するものです。
- 強化学習:訓練された報酬モデルを用いて、強化学習を実行します。モデルは、報酬を最大化するように自己調整します。
- 反復プロセス:フィードバックの収集と強化学習を繰り返し行うことで、モデルの性能を徐々に向上させます。
ゼロショット学習
ゼロショット学習は、モデルが一度も見たことのないクラスに対して予測を行う能力を指します。
フューショット学習
フューショット学習は、新しいクラスに対して非常に少ない学習データでモデルを適応させる方法です。ゼロショット学習とは異なり、新しいクラスに関する少量のラベル付きデータが提供されます。
インストラクションチューニング
インストラクションチューニングは、モデルが与えられたタスクをより効率的かつ効果的に学習するための手法です。この手法は、特に自然言語処理の分野で使用され、モデルが特定の指示に基づいて動作するように調整されます。
-
データ収集:各タスクに対するインストラクションと対応する出力を含む多様なデータセットを収集します。
-
データ前処理:データセットを適切にフォーマットし、モデルが効率的に学習できるようにします。これには、インストラクションと出力のペアの整形が含まれます。
-
モデルの選択:インストラクションチューニングに適したモデルアーキテクチャを選択します。Transformer 5 ベースのモデルが一般的に使用されます。
-
トレーニング:モデルをインストラクションデータセットでトレーニングします。これには、モデルが指示に従って正確に出力を生成するように調整するためのマルチタスク学習が含まれます。
-
評価:トレーニング後、モデルの性能を評価します。これには、各タスクに対するモデルの応答が期待通りであるかを確認するための評価指標が使用されます。
-
ファインチューニング:必要に応じて、モデルのパフォーマンスをさらに向上させるためにファインチューニングを行います。
プロンプトエンジニアリング
- プロンプトエンジニアリングは、AI モデル(特に自然言語処理モデル)に対して効果的な入力を設計・作成するプロセスを指します。プロンプトエンジニアリングの目的は、AI が望ましい応答を生成するように誘導することです。
モデル圧縮
モデル圧縮とは、大規模なニューラルネットワークモデルを小さく、効率的にするための手法です。これにより、モデルの計算コストやメモリ使用量が削減され、特にモバイルデバイスや組み込みシステムなどリソースが限られた環境での実装が容易になります。
蒸留
蒸留は、大規模で複雑なモデル(教師モデル)から知識を抽出し、それをより小さなモデル(生徒モデル)に移す手法です。これにより、生徒モデルは教師モデルのパフォーマンスに近い精度を維持しながら、計算リソースを大幅に削減できます。
-
教師モデルを訓練します。
-
教師モデルの出力を生徒モデルの訓練データとして使用します。
-
生徒モデルを訓練し、教師モデルの知識を模倣します。
量子化
量子化は、モデルの重みやアクティベーションをより低いビット幅に変換する手法です。通常のモデルは $32$ ビット浮動小数点数を使用しますが、量子化により、$16$ ビット浮動小数点数や $8$ ビット整数などの形式に変換します。これにより、メモリ使用量と計算コストを削減できますが、精度の損失が発生することがあります。
プルーニング
プルーニングは、モデルの不要な部分(パラメータやニューロン)を削除する手法です。これにより、モデルのサイズを小さくし、推論速度を向上させることができます。プルーニングには、構造的プルーニング(ネットワークの特定の部分を削除)と非構造的プルーニング(個々の重みを削除)の $2$ 種類があります。
-
重要度の低いパラメータやニューロンを識別します。
-
それらを削除し、モデルを再訓練します。
import torch
from torch import nn
from torch.nn.utils import prune
m = prune.l1_unstructured(nn.Linear(2, 3), 'weight', amount=0.2)
m.state_dict().keys()
import torch
from torch import nn
from torch.nn.utils import prune
m = prune.random_unstructured(nn.Linear(2, 3), 'weight', amount=1)
torch.sum(m.weight_mask == 0)
from torch import nn
from torch.nn.utils import prune
m = prune.ln_structured(
nn.Conv2d(5, 3, 2), 'weight', amount=0.3, dim=1, n=float('-inf')
)
import torch
from torch import nn
from torch.nn.utils import prune, parameters_to_vector
from collections import OrderedDict
net = nn.Sequential(OrderedDict([
('first', nn.Linear(10, 4)),
('second', nn.Linear(4, 1)),
]))
parameters_to_prune = (
(net.first, 'weight'),
(net.second, 'weight'),
)
prune.global_unstructured(
parameters_to_prune,
pruning_method=prune.L1Unstructured,
amount=10,
)
print(sum(parameters_to_vector(net.buffers()) == 0))
実装
「糖尿病」の進行状況の予測
表形式データを用いて、回帰モデルを作成します。
-
データセット:scikit-learn の「糖尿病」のデータセット
-
活性化関数:恒等関数
-
損失関数:最小二乗誤差
-
最適化関数:確率的勾配降下法
-
- 学習率:$1 \times 10^{-5}$
- エポック数:$1024$
- バッチサイズ:$32$
- 隠れ層の数とサイズ:$1$ と $16$
-
検証方法:ホールドアウト検証
-
評価指標:決定係数
-
ハードウェア
- T4 GPU
- CPU
import numpy as np
import pandas as pd
from tqdm import tqdm
from sklearn.datasets import load_diabetes
from sklearn.metrics import r2_score
import torch
from torch import nn, optim
from torch.utils.data import DataLoader, TensorDataset, random_split
dataset = load_diabetes()
data = pd.DataFrame(dataset.data, columns=dataset.feature_names)
target = pd.DataFrame(dataset.target, columns=["target"])
data = torch.tensor(data.values, dtype=torch.float32)
target = torch.tensor(target.values, dtype=torch.float32).view(-1, 1)
dataset = TensorDataset(data, target)
n_train = int(len(dataset) * 0.8)
n_val = int(len(dataset) * 0.1)
n_test = len(dataset) - n_train - n_val
train_dataset, val_dataset, test_dataset = random_split(dataset, [n_train, n_val, n_test])
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size)
class MODEL(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(MODEL, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
input_size = data.shape[1]
output_size = target.shape[1]
hidden_size = 16
lr = 1e-5
model = MODEL(input_size, hidden_size, output_size)
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=lr)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
epochs = 1024
result_df = pd.DataFrame(columns=["Train Loss", "Train R2", "Val Loss", "Val R2"])
for epoch in tqdm(range(epochs)):
model.train()
train_loss = 0
train_targets_list = []
train_outputs_list = []
for train_data, train_target in train_loader:
train_data, train_target = train_data.to(device), train_target.to(device)
optimizer.zero_grad()
output = model(train_data)
loss = criterion(output, train_target)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_targets_list.append(train_target.cpu().numpy())
train_outputs_list.append(output.cpu().detach().numpy())
train_loss /= len(train_loader)
train_targets = np.concatenate(train_targets_list, axis=0)
train_outputs = np.concatenate(train_outputs_list, axis=0)
train_r2 = r2_score(train_targets, train_outputs)
model.eval()
val_loss = 0
val_targets_list = []
val_outputs_list = []
with torch.no_grad():
for val_data, val_target in val_loader:
val_data, val_target = val_data.to(device), val_target.to(device)
output = model(val_data)
loss = criterion(output, val_target)
val_loss += loss.item()
val_targets_list.append(val_target.cpu().numpy())
val_outputs_list.append(output.cpu().detach().numpy())
val_loss /= len(val_loader)
val_targets = np.concatenate(val_targets_list, axis=0)
val_outputs = np.concatenate(val_outputs_list, axis=0)
val_r2 = r2_score(val_targets, val_outputs)
result_df.loc[epoch, "Train Loss"] = train_loss
result_df.loc[epoch, "Train R2"] = train_r2
result_df.loc[epoch, "Val Loss"] = val_loss
result_df.loc[epoch, "Val R2"] = val_r2
import matplotlib.pyplot as plt
plt.plot(result_df.index, result_df["Train Loss"], label="Train")
plt.plot(result_df.index, result_df["Val Loss"], label="Validation")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.show()
import matplotlib.pyplot as plt
plt.plot(result_df.index, result_df["Train R2"], label="Train")
plt.plot(result_df.index, result_df["Val R2"], label="Validation")
plt.xlabel("Epoch")
plt.ylabel("R^2")
plt.legend()
plt.show()
「アヤメ」の品種分け
表形式データを用いて、分類モデルを作成します。
-
データセット:scikit-learn の「アヤメ」のデータセット
-
損失関数:交差エントロピー誤差
-
最適化関数:モーメンタム
-
検証方法:ホールドアウト検証
-
評価指標:正解率
-
- 方法:パラメータのL1ノルムに基づいたプルーニング
- 対象:モデル全体のパラメータ
- 割合:$0.1$
-
ハードウェア
- T4 GPU
- CPU
※PyTorch の交差エントロピー誤差 torch.nn.CrossEntropyLoss() の内部にソフトマックス関数が含まれています。そのため、ここでは、torch.nn.Softmax(dim=1) は書きません。
import pandas as pd
from tqdm import tqdm
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
import torch
from torch import nn, optim
from torch.utils.data import DataLoader, TensorDataset, random_split
dataset = load_iris()
n_labels = len(dataset.target_names)
data = pd.DataFrame(dataset.data, columns=dataset.feature_names)
target = pd.DataFrame(dataset.target, columns=["target"])
data = torch.tensor(data.values, dtype=torch.float32)
target = torch.tensor(target.values, dtype=torch.long).view(-1)
dataset = TensorDataset(data, target)
n_train = int(len(dataset) * 0.8)
n_val = int(len(dataset) * 0.1)
n_test = len(dataset) - n_train - n_val
train_dataset, val_dataset, test_dataset = random_split(dataset, [n_train, n_val, n_test])
batch_size = 8
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size)
class MODEL(nn.Module):
def __init__(self, input_size, hidden_size, output_size, dropout_prob=0.5):
super(MODEL, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=dropout_prob)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
return x
input_size = data.shape[1]
output_size = n_labels
hidden_size = 16
lr = 1e-5
model = MODEL(input_size, hidden_size, output_size)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.9)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
epochs = 1024
result_df = pd.DataFrame(columns=["Train Loss", "Train Acc", "Val Loss", "Val Acc"])
for epoch in tqdm(range(epochs)):
model.train()
train_loss = 0
all_train_targets = []
all_train_predictions = []
for train_data, train_target in train_loader:
train_data, train_target = train_data.to(device), train_target.to(device)
optimizer.zero_grad()
output = model(train_data)
loss = criterion(output, train_target)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = torch.max(output, 1)
all_train_targets.extend(train_target.cpu().numpy())
all_train_predictions.extend(predicted.cpu().numpy())
train_loss /= len(train_loader)
train_acc = accuracy_score(all_train_targets, all_train_predictions)
model.eval()
val_loss = 0
all_val_targets = []
all_val_predictions = []
with torch.no_grad():
for val_data, val_target in val_loader:
val_data, val_target = val_data.to(device), val_target.to(device)
output = model(val_data)
loss = criterion(output, val_target)
val_loss += loss.item()
_, predicted = torch.max(output, 1)
all_val_targets.extend(val_target.cpu().numpy())
all_val_predictions.extend(predicted.cpu().numpy())
val_loss /= len(val_loader)
val_acc = accuracy_score(all_val_targets, all_val_predictions)
result_df.loc[epoch, "Train Loss"] = train_loss
result_df.loc[epoch, "Train Acc"] = train_acc.item()
result_df.loc[epoch, "Val Loss"] = val_loss
result_df.loc[epoch, "Val Acc"] = val_acc.item()
import matplotlib.pyplot as plt
plt.plot(result_df.index, result_df["Train Loss"], label="Train")
plt.plot(result_df.index, result_df["Val Loss"], label="Validation")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.show()
import matplotlib.pyplot as plt
plt.plot(result_df.index, result_df["Train Acc"], label="Train")
plt.plot(result_df.index, result_df["Val Acc"], label="Validation")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
from torch.nn.utils import prune
parameters_to_prune = (
(model.fc1, "weight"),
(model.fc2, "weight"),
)
prune.global_unstructured(
parameters_to_prune,
pruning_method=prune.L1Unstructured,
amount=0.1,
)
for module, name in parameters_to_prune:
prune.remove(module, name)
ノイズベクトルから手書き数字を生成
敵対的生成ネットワークを使って、ランダムなノイズベクトルから手書き数字を生成します。
import pandas as pd
from tqdm import tqdm
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST('.', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('.', train=False, download=True, transform=transform)
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.network = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 1024),
nn.ReLU(),
nn.Linear(1024, 28*28),
nn.Tanh()
)
def forward(self, x):
return self.network(x).view(-1, 1, 28, 28)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.network = nn.Sequential(
nn.Linear(28*28, 1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.network(x.view(-1, 28*28))
gen_model = Generator()
dis_model = Discriminator()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
gen_model = gen_model.to(device)
dis_model = dis_model.to(device)
lr = 1e-4
criterion = nn.BCELoss()
gen_optimizer = optim.Adam(gen_model.parameters(), lr=lr)
dis_optimizer = optim.Adam(dis_model.parameters(), lr=lr)
epochs = 10
result_df = pd.DataFrame(columns=[
"Train Discriminator Real Loss", "Train Discriminator Fake Loss", "Train Discriminator Loss", "Train Generator Loss",
"Val Discriminator Real Loss", "Val Discriminator Fake Loss", "Val Discriminator Loss", "Val Generator Loss"
])
for epoch in tqdm(range(epochs)):
gen_model.train()
dis_model.train()
dis_train_real_loss = 0
dis_train_fake_loss = 0
gen_train_loss = 0
for i, (train_data, _) in enumerate(train_loader):
real_imgs = train_data.to(device)
real_labels = torch.ones(real_imgs.size(0), 1).to(device)
fake_labels = torch.zeros(real_imgs.size(0), 1).to(device)
dis_optimizer.zero_grad()
outputs = dis_model(real_imgs)
dis_real_loss = criterion(outputs, real_labels)
dis_real_loss.backward()
dis_train_real_loss += dis_real_loss.item()
z = torch.randn(real_imgs.size(0), 100).to(device)
fake_imgs = gen_model(z)
outputs = dis_model(fake_imgs.detach())
dis_fake_loss = criterion(outputs, fake_labels)
dis_fake_loss.backward()
dis_train_fake_loss += dis_fake_loss.item()
dis_optimizer.step()
gen_optimizer.zero_grad()
outputs = dis_model(fake_imgs)
gen_loss = criterion(outputs, real_labels)
gen_loss.backward()
gen_optimizer.step()
gen_train_loss += gen_loss.item()
dis_train_real_loss /= len(train_loader)
dis_train_fake_loss /= len(train_loader)
dis_train_loss = dis_train_real_loss + dis_train_fake_loss
gen_train_loss /= len(train_loader)
dis_eval_real_loss = 0
dis_eval_fake_loss = 0
gen_eval_loss = 0
gen_model.eval()
dis_model.eval()
with torch.no_grad():
for i, (test_data, _) in enumerate(test_loader):
real_imgs = test_data.to(device)
real_labels = torch.ones(real_imgs.size(0), 1).to(device)
fake_labels = torch.zeros(real_imgs.size(0), 1).to(device)
outputs = dis_model(real_imgs)
dis_real_loss = criterion(outputs, real_labels)
dis_eval_real_loss += dis_real_loss.item()
z = torch.randn(real_imgs.size(0), 100).to(device)
fake_imgs = gen_model(z)
outputs = dis_model(fake_imgs.detach())
dis_fake_loss = criterion(outputs, fake_labels)
dis_eval_fake_loss += dis_fake_loss.item()
outputs = dis_model(fake_imgs)
gen_loss = criterion(outputs, real_labels)
gen_eval_loss += gen_loss.item()
dis_eval_real_loss /= len(test_loader)
dis_eval_fake_loss /= len(test_loader)
dis_eval_loss = dis_eval_real_loss + dis_eval_fake_loss
gen_eval_loss /= len(test_loader)
result_df.loc[epoch, "Train Discriminator Real Loss"] = dis_train_real_loss
result_df.loc[epoch, "Train Discriminator Fake Loss"] = dis_train_fake_loss
result_df.loc[epoch, "Train Discriminator Loss"] = dis_train_loss
result_df.loc[epoch, "Train Generator Loss"] = gen_train_loss
result_df.loc[epoch, "Val Discriminator Real Loss"] = dis_eval_real_loss
result_df.loc[epoch, "Val Discriminator Fake Loss"] = dis_eval_fake_loss
result_df.loc[epoch, "Val Discriminator Loss"] = dis_eval_loss
result_df.loc[epoch, "Val Generator Loss"] = gen_eval_loss
import matplotlib.pyplot as plt
plt.plot(result_df.index, result_df["Train Discriminator Loss"], label="Train")
plt.plot(result_df.index, result_df["Val Discriminator Loss"], label="Validation")
plt.xlabel("Epoch")
plt.ylabel("Discriminator Loss")
plt.legend()
plt.show()
import matplotlib.pyplot as plt
plt.plot(result_df.index, result_df["Train Generator Loss"], label="Train")
plt.plot(result_df.index, result_df["Val Generator Loss"], label="Validation")
plt.xlabel("Epoch")
plt.ylabel("Generator Loss")
plt.legend()
plt.show()
import matplotlib.pyplot as plt
import torch
gen_model.eval()
num_images = 16
z = torch.randn(num_images, 100).to(device)
with torch.no_grad():
fake_images = gen_model(z)
fake_images = fake_images.cpu().numpy()
fake_images = (fake_images + 1) / 2
fig, axes = plt.subplots(4, 4, figsize=(8, 8))
for i, ax in enumerate(axes.flatten()):
ax.imshow(fake_images[i, 0], cmap='gray')
ax.axis('off')
plt.tight_layout()
plt.show()
映画レビューの感情分類
事前学習済みモデルをファインチューニングして特定のタスクにモデルを特化させます。
ファインチューニングのためのコードは基本的に上記のコードとさほど変わらないので、Hugging Face の Trainer を使って実装します。
事前学習済みモデルは、Hugging Face に多く公開されています。
正解率などを可視化するためには、TensorBoard や WandB などの設定が必要になります。
-
データセット:GLUE の SST-2 10 11 12
-
事前学習済みモデル:bert-base-uncased 13
-
最適化関数:AdamW 14
-
- 学習率:$1 \times 10^{-6}$
- エポック数:$3$
- バッチサイズ:$32$
- 正則化パラメータ
- 重み減衰:$1 \times 10^{-2}$
-
ハードウェア
- T4 GPU
- CPU
!pip install datasets
from sklearn.metrics import accuracy_score, f1_score, precision_score, recall_score
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
train_dataset = load_dataset("nyu-mll/glue", "sst2", split="train")
val_dataset = load_dataset("nyu-mll/glue", "sst2", split="validation")
test_dataset = load_dataset("nyu-mll/glue", "sst2", split="test")
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-uncased")
def preprocess(data):
sentence = tokenizer(data["sentence"], truncation=True, add_special_tokens=True, padding=True)
sentence["labels"] = data["label"]
sentence["input_ids"] = sentence["input_ids"]
sentence["attention_mask"] = sentence["attention_mask"]
return sentence
train_dataset = train_dataset.map(preprocess, remove_columns=train_dataset.column_names)
val_dataset = val_dataset.map(preprocess, remove_columns=val_dataset.column_names)
def compute_metrics(pred):
predictions = pred.predictions.argmax(axis=1)
labels = pred.label_ids
return {
"Accuracy" : accuracy_score(predictions, labels),
"Precision" : precision_score(predictions, labels),
"Recall" : recall_score(predictions, labels),
"F1" : f1_score(predictions, labels)
}
training_args = TrainingArguments(
output_dir = "./outputs",
evaluation_strategy='epoch',
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
learning_rate=1e-6,
weight_decay=1e-2,
num_train_epochs=3
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
言語生成モデルによる質問応答
事前学習済みモデルは、Hugging Face に多く公開されています。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" if torch.cuda.is_available() else 'cpu'
tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
model = model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2").to(device)
with torch.no_grad():
input_text = "What kind of technology is artificial intelligence?"
tokenized_input_text = tokenizer(input_text, return_tensors="pt").to(model.device)
tokenized_output_text_list = model.generate(**tokenized_input_text)
output_text_list = [tokenizer.decode(tokenized_output_text, skip_special_tokens=True) for tokenized_output_text in tokenized_output_text_list]
拡散モデルによる画像生成
拡散モデルを使って、自然言語から画像を生成します。
事前学習済みモデルは、Hugging Face に多く公開されています。
-
事前学習済みモデル:stable-diffusion-v1-5 15
-
ハードウェア
- T4 GPU
- CPU
!pip install diffusers
import torch
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", use_safetensors=True)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
pipeline = pipeline.to(device)
image = pipeline("What kind of technology is artificial intelligence?").images[0]
ゼロショット学習とフューショット学習
ゼロショット学習
ChatGPT を、ゼロショット学習で漢字を合成できるようにします。
次の漢字を合成して、一つの漢字を答えてください。
水 + 可 =
フューショット学習
ChatGPT を、フューショット学習で漢字を合成できるようにします。
木 + 白 = 柏
魚 + 参 = 鯵
人 + 放 = 倣
士 + 心 = 志
水 + 可 =
次の漢字を合成して、一つの漢字を答えてください。
木 + 白 = 柏
魚 + 参 = 鯵
人 + 放 = 倣
士 + 心 = 志
水 + 可 =
おわりに
この記事では、応用情報技術者試験の出題範囲内の AI 技術の概要の説明と Python で実装をしました。
この記事が、応用情報技術者の AI 技術を学習する人に貢献できれば幸いです。
参考文献
-
Nitish Srivastava, Geoffrey E. Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res., 2014. ↩
-
Yann LeCun, Bernhard E. Boser, John S. Denker, Donnie Henderson, Richard E. Howard, Wayne E. Hubbard, and Lawrence D. Jackel. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput., 1989. ↩
-
Sepp Hochreiter and Jürgen Schmidhuber. Long Short-Term Memory. Neural Comput., 1997. ↩
-
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27, 2014. ↩
-
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, L ukasz Kaiser, and Illia Polosukhin. Attention is All you Need. In Advances in Neural Information Processing Systems 30, 2017. ↩ ↩2
-
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep Reinforcement Learning from Human Preferences. In Advances in Neural Information Processing Systems 30, 2017. ↩
-
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems 35, 2022. ↩
-
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proc. IEEE, 1998. ↩
-
Diederik P. Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimization. In 3rd International Conference on Learning Representations, 2015. ↩
-
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Y. Ng, and Christopher Potts. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 2013. ↩
-
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the Workshop: Analyzing and Interpreting Neural Networks for NLP, 2018. ↩
-
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In 7th International Conference on Learning Representations, 2019. ↩
-
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, 2019. ↩
-
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization. In 7th International Conference on Learning Representations, 2019. ↩
-
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-Resolution Image Synthesis with Latent Diffusion Models. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022. ↩