自己紹介
青山学院大学国際政治経済学部国際経済学科のNatsutoshi Sumita と申します!
普段は演習(ゼミ)の一環、かつスキルの勉強としてPythonを日々牛歩ながらやっています
自己紹介をここに書くのも書ききれないので、また別の記事にして書く予定ですのでそっちに丸投げしますね(適当)
はじめに
1. この分析は何をしようとしているのか?
経済学は理論が先行し、それを実証しつつまた理論を修正していくというサイクルが基本的なスタイルです。
そこで、国際貿易の観点から金科玉条のように言われている理論があります。これを検証し、本当にその理論が正しいかどうかを確かめることが大目的です。
2. 分析の対象
ゼミの指導教員の中川先生のページに、生データが載っているのでこちらを参照しました。
http://www.cc.aoyama.ac.jp/~nakagawa/IntlFinClassData1a.xls
year NEER REER Export Import GDP
0 1980 22.19 73.84 2938 3200 255736 NaN NaN
1 1981 25.22 78.93 3347 3146 274300 NaN NaN
2 1982 24.14 71.57 3443 3266 288331 NaN NaN
3 1983 27.26 77.50 3491 3001 301312 NaN NaN
4 1984 29.53 80.90 4033 3232 319516 NaN NaN
5 1985 31.42 82.92 4196 3108 340475 NaN NaN
6 1986 41.59 106.30 3529 2155 357473 NaN NaN
7 1987 45.97 111.97 3332 2174 373792 NaN NaN
8 1988 51.84 118.71 3394 2401 401650 NaN NaN
9 1989 50.91 108.80 3782 2898 430045 NaN NaN
10 1990 49.24 97.36 4146 3386 462837 NaN NaN
11 1991 54.81 103.95 4236 3190 492669 NaN NaN
12 1992 59.42 107.04 4301 2953 505128 NaN NaN
13 1993 74.06 125.30 4020 2683 505368 NaN NaN
14 1994 84.69 133.21 4050 2810 510916 NaN NaN
15 1995 90.37 135.39 4153 3155 521614 NaN NaN
16 1996 78.81 113.70 4473 3799 535562 NaN NaN
17 1997 74.95 106.98 5094 4096 543545 NaN NaN
18 1998 76.72 107.01 5065 3665 536497 NaN NaN
19 1999 87.07 118.90 4755 3527 528070 NaN NaN
20 2000 94.67 125.51 5165 4094 535418 NaN NaN
21 2001 87.01 111.77 4898 4242 531654 NaN NaN
22 2002 83.10 104.15 5211 4223 524479 NaN NaN
23 2003 85.67 105.04 5455 4436 523969 NaN NaN
...
39 2019 88.58 76.62 7693 7860 557911 NaN NaN
40 2020 90.70 77.31 6840 6801 539082 NaN NaN
41 2021 85.24 70.69 8309 8488 549379 NaN NaN
42 2022 75.59 60.98 9817 11814 556702 NaN NaN
このファイルには、以下の情報が含まれています。
・日本の年別の名目実効為替レート(円/米ドル):NEER
・日本の年別の実質実効為替レート(円/米ドル):REER
・輸出額(万円)
・輸入額(万円)
・GDP(万円)
この分析ではこのデータセットを使用します。なお、Pandas,Numpyで読んだ時にNaNとなってしまうデータ(7・8列目)は使用しません。
3.分析のゴール
この分析では、以下の問いに問いに解凍することをゴールとして分析していきます。
1.実質実効為替レートないしは名目実効為替レートと経常収支(貿易収支)の間における相関関係の有無を判断すること
2.1.の結果が有意であるかどうかを調べること
(注:この分析においては仮説検定の有意水準を5%と設定します。)
分析の過程
1.データフレームの読み込み
PandasとNumpyというライブラリ(カードゲームにおける拡張パックのようなもの、これら2つがないとそもそも表計算ができない)を落とします。どちらも先ほどのcsvファイルを読ませて直接使うので抜かりなく落とすように。
import pandas as pd
import numpy as np
これができたら、csvファイルを落とします。
なお、
as pd
as np
これらは、pandasやnumpyを呼び出して、コマンドを使うときに必要なのでわかりやすい名前で書いておきましょう。
x=pd.read_csv("IntlFinClassData1a.csv")
(注:csvファイルは文字として記述すること!)
2. 散布図の描画の下準備
import matplotlib as matplotlib
import matplotlib.pyplot as plt
matplotlibというライブラリをインストールします。このときに、同じくpyplotという機能を単独で落としておくと便利です。(散布図の描画をするときに使います)
3. データ整理
使用するデータを使いやすくするために加工していきます。
print(x)
で、先ほど読ませたデータ(csvファイル)を一旦表示させましょう。
入れたcsvファイルに破損などがないかを確認してください。
im=x.iloc[:,4]
ex=x.iloc[:,3]
NEER=x.iloc[:,1]
REER=x.iloc[:,2]
2.までの過程をまとめると、csvファイルを読ませて、xという変数に格納するという作業をしているだけでした。なので、このままでは後の分析でデータが使える状態にはなっていません。
そこで、輸入・輸出・経常収支・NEER・REERの5つを変数として新たに作成します。
変数名=データフレーム.iloc[行,列]
という構文で、行や列を特定して変数に格納できます。なお、: は行を指定しないという意味です。(列のみのシリーズをここでは作っています。)
さらに、シリーズ同士での演算も可能なので、生データにはなかった経常収支も、輸入を輸出で割るという形で新たな変数として作っています。
x['balance']=im/ex
print(balance)
最後に、データフレームxに経常収支の列を追加して完成です。
4.散布図の描画
いよいよ本題の分析に入ります。
相関関係を把握するために、まずは視覚的に関係をとらえます。
散布図を描画していきましょう。
plt.scatter(NEER,balance)
plt.scatter(REER,balance)
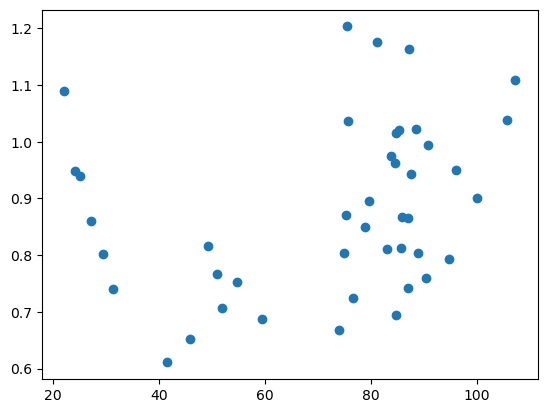
図1:NEERと経常収支の散布図
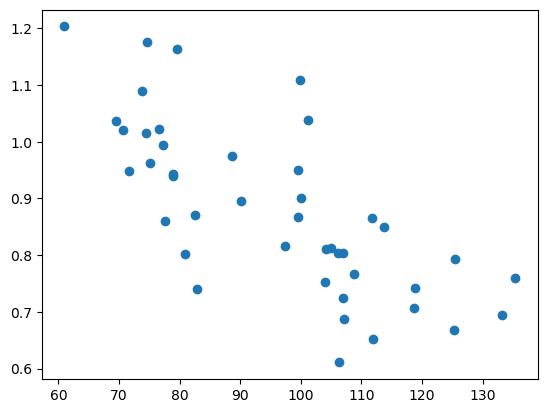
図2:REERと経常収支の散布図
NEERの方はしっちゃかめっちゃかな散布図ですが、REERははっきりとした負の相関が視覚的に見てとれます。
ただ、あくまでも視覚的(主観的)に見ているだけなので、相関係数の導出をしましょう。
5.相関係数の導出
df_corr=df_corr=x.corr()
print(df_corr)
データフレーム.corr()
で相関係数を導出することができます。その結果は以下の通りになりました。
year NEER REER Export Import GDP \
year 1.000000 0.801284 -0.359833 0.925800 0.899295 0.791651
NEER 0.801284 1.000000 0.226336 0.634056 0.547217 0.885611
REER -0.359833 0.226336 1.000000 -0.512636 -0.625294 0.159712
Export 0.925800 0.634056 -0.512636 1.000000 0.961300 0.692903
Import 0.899295 0.547217 -0.625294 0.961300 1.000000 0.564966
GDP 0.791651 0.885611 0.159712 0.692903 0.564966 1.000000
Unnamed: 6 NaN NaN NaN NaN NaN NaN
Unnamed: 7 NaN NaN NaN NaN NaN NaN
balance 0.633318 0.278188 -0.729497 0.657430 0.823180 0.172827
Unnamed: 6 Unnamed: 7 balance
year NaN NaN 0.633318
NEER NaN NaN 0.278188
REER NaN NaN -0.729497
Export NaN NaN 0.657430
Import NaN NaN 0.823180
GDP NaN NaN 0.172827
Unnamed: 6 NaN NaN NaN
Unnamed: 7 NaN NaN NaN
balance NaN NaN 1.000000
少し表が汚いので、必要な部分だけを抽出して解説します。
REERと経常収支の相関係数は-0.729497と、強めの負の相関が現れていました。
しかし、NEERと経常収支の相関係数は0.27と、相関関係をみるという点では非常に弱い値しか返してくれませんでした。
したがって、「実質実効為替レートないしは名目実効為替レートと経常収支(貿易収支)の間における相関関係の有無を判断すること」という問いについての回答は、
「強めの負の相関が検出された」 ということになります。
6.仮説検定
まず、適当な思い込みから、「実効為替レートも経常収支もまあ正規分布には従ってくれるやろ」と呑気に構えて、t検定 を試してみることにしました。
plt.hist(REER,bins=20)
で、ヒストグラムを出力して、正規性のチェックを行います。この時も、pltでライブラリを呼び出しています。
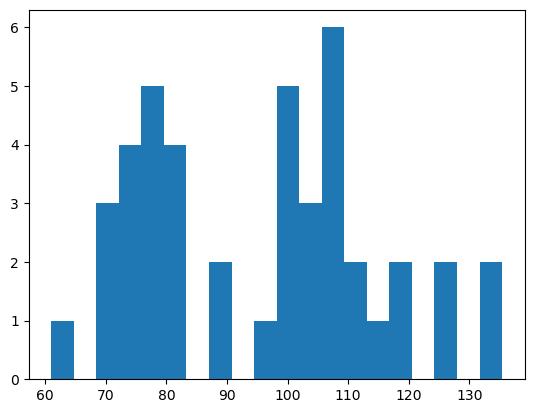
俺 「キモッ」
という声が出るぐらい気持ち悪いヒストグラムが出てきてしまいました。
この結果から、t検定の使用は諦め、ノンパラメトリック(正規分布に従う前提を必要としない)分析に移行しました。
次は、カイ2乗検定 を試します。
クロス集計表を作成するので、pandasのcrosstabというコマンドを使って作成してみます。
crossbalance=pd.crosstab(REER,balance)
print(crossbalance)
この集計表はprintで出力してもしなくても構いません。
import scipy as sp
import scipy.stats
x2, p, dof, expected = sp.stats.chi2_contingency(crossbalance)
print("カイ二乗値は %(x2)s" %locals() )
print("確率は %(p)s" %locals() )
print("自由度は %(dof)s" %locals() )
print( expected )
if p < 0.05:
print("有意な差があります")
else:
print("有意な差がありません")
scipyというライブラリで計算を行います。最後に条件分岐で有意差の有無を表示する関数を作ってあります。
(参照:https://qiita.com/ynakayama/items/67ddb321a8ce5b07274c)
そして、その結果がこちらになります。
カイ二乗値は 1806.0
確率は 0.23799292638735034
自由度は 1764
[[0.02325581 0.02325581 0.02325581 ... 0.02325581 0.02325581 0.02325581]
[0.02325581 0.02325581 0.02325581 ... 0.02325581 0.02325581 0.02325581]
[0.02325581 0.02325581 0.02325581 ... 0.02325581 0.02325581 0.02325581]
...
[0.02325581 0.02325581 0.02325581 ... 0.02325581 0.02325581 0.02325581]
[0.02325581 0.02325581 0.02325581 ... 0.02325581 0.02325581 0.02325581]
[0.02325581 0.02325581 0.02325581 ... 0.02325581 0.02325581 0.02325581]]
有意な差がありません
有意差なし!
この相関分析に有意な差は認められませんでした。
結論
まとめると、
1.実質実効為替レートないしは名目実効為替レートと経常収支(貿易収支)の間における相関関係の有無を判断すること
2.1.の結果が有意であるかどうかを調べること
(注:この分析においては仮説検定の有意水準を5%と設定します。)
という問いに対して、
1. 相関関係は認められる
2. 有意ではない
という回答が得られました!
こういった感じで、課題でおこなった分析や自分の興味のある分析を載せていこうと思います。
ご一読いただきありがとうございました!