入社すると、そこは Active Record だった
2015年夏に、ある AI 系のスタートアップに入社した。5年ぶりくらいのまともな開発だった。
使用しているのは Python Django (のちにPython の Google App Engine も)。Rails とよく似たフレームワークである。7年くらい前にRails をさわったことがあった。なので、フレームワークの考え方にはついていけた。
ほとばしる無能、ほとばしるアンチパターン
しかし実際に運用されているコードはひどいものだった。そして1ヶ月ほど前に入社したサーバエンジニアのコードにはメダパニの呪文が内蔵されていた。
以下、目についた症状をリストアップする。
- Smart UI
- API View にロジックを詰め込みすぎ
- Smart バッチインターフェース
- Smart UI 同様にロジックを詰め込みすぎ。引数パラメータをパースした後、具体的な処理を実行する別のクラスに移譲すべきじゃね?
- 役割と責任がわからない Model
- 重複するが View にもロジックが入っていて、Model と View の間の役割と責任の分担が不明
- ある Model が、他の Model をつかって、データを結合・加工している
- 「くさいものに蓋」な機械学習アルゴリズム
- 命名規則がめちゃくちゃ。インターンが書いたコードをコピペしているだけ。
- 無駄なクエリを発行していて後にパフォーマンスに問題が…
- 負荷テストをやりたいと言うだけで、実際にやった経験がない
- 後日一部については、自分が JMeter でテストした
- 負荷テストをやりたいと言うだけで、実際にやった経験がない
- ってゆーか、データをこねこねする AI 系の要件で Active Record っておかしくね?
- 自由度が高い Flask + SQL Alchemy が正解だった気がする
- まぁ、リリース当初は情報がなかったらしいが
- そして引き返すことが難しい…
- 自由度が高い Flask + SQL Alchemy が正解だった気がする
私は混乱した。
なんでこんなことになった
原因を考えてみた。
原因1
そもそも設計・分析ができない
- 「あとで変わるから」といってまったくドキュメントがない
- 引き継ぐ人に不親切な思想
- システム基本設計すらない
- せめてバッチ系のデータフロー、主要な画面遷移くらいはほしかった
- クソエンジニア認定初段の「コードを読めばわかる」発言
- 設計ドキュメントがあっても粒度が粗すぎる
- UML とか見たことがない
- サーバサイドで重要なのはテーブル設計とデータフローなんだが、「何それ、おいしいの?」と言わんばかり
- テーブル、クラス、メソッド、変数の命名規則が常識なさすぎてつらい
- Model クラスの名前に Set とか List とか使うのはやめてほしい
- メソッドの名前が動詞から始まってない
原因2
エンタープライズアプリケーションアーキテクチャパターンを知らない
- Rails だけでアーキテクチャを知っている気になっていたクソエンジニアがいた
- いや、Rails にいいエンジニアがいるのも知ってるんですけどね。。。
- 最低限、マイクロサービスアーキテクチャかドメイン駆動設計くらいは知らないと、アーキテクチャの実装はきつい
- AI のコードがあったのだが、それについてはインターンのコードをコピペし、utils ファイルに貼り付けるだけ
- 企業がリリースするアプリ・サービスなら、レビューしないとダメだろう。。。
原因3
経営者が営業系で、IT のプロダクト作り・モノづくりについて無知すぎる。営業経営者がテック事業をよく理解しないまま始めるのはスタートアップ・アンチパターンのひとつ。
- プロダクト管理の素人すぎる
- 創業時から CTO/プロダクトマネージャがいないときつい(CTO が入って、苦戦しながら改善中)
- ユーザインタビューはスキルがない人たちにアサインされた
- CEO が営業系。コードを書かないのに、インタビューにも行かず、マスコミの取材を受けたり、イベントに登壇する。
- 一度だけインタビューしたことがあったが説明・説得していた。いやいや、ユーザがかかえている問題を聞いて深掘りすることが目的だろうに。。。
- 資金を集めるのに必要なこともあると思うが、もっとも説得力を持つのはプレゼン資料ではなく、プロダクトである。その品質をあげる活動をしないで、どうするのだろう。。。
- COO が営業系。あるプロダクトを改善する前提で作ったが、スケールしようとしている。
- 問題仮説、ソリューション仮説、プロダクト仮説、スケール仮説のうち、いろいろステップと検証をすっとばしてスケールしようとしている
- アントレプレナーの教科書とかInspiredをもとに見解を述べても、高速 PDCA とごっちゃにされる
- プロジェクト管理の素人すぎる
- 「開発期間は1ヶ月」と聞いた時には残り3週間
- 別のタスクを終わらせて残り2週間で開発開始、と思ったら顧客プレゼンがあった。実質残り1週間。
- 3日前の全社 MTG で開発最終日が顧客プレゼンの日と知った。マイルストーンを開発期間に含めるとかありえん。。。開発日程、残り2日に前倒し。
- そのことを全社 MTG で指摘したら、「サーバサイドはDBを見るだけ」と言われた。その時点で AI のコードを受領しておらず、データ構造含め、どうなるか不明。
- 結局、AI との繋ぎこみとGCE 環境を徹夜して間に合わせた
- プロダクトの品質が軽視される
- 納期優先、とりあえずリリースしとけ的な進め方
- 工数を告げても、結局交渉力でリリース日が前倒しされる
- 週末作業と徹夜でリカバリするハメに
- 体調を崩すと「勤怠がわるい」「バリューを出してない」と言われる
- 社内の交渉力で仕様が決定される
- プロセス改善のために対策を決めても、守られたことがない
対策
原因1 は ICONIX プロセスの勉強会をやってみた。参考にした本はコチラ。
原因2 の解決策について述べてみる。
Active Record パターンについて補足
誤解が多いように思うが、Active Record パターンは Rails から始まったわけではない。ファウラーのエンタープライズ・アプリケーション・アーキテクチャ・パターンに記述されている。
View と DB のテーブルが 1:1 にするものであり、その中間にある Model も含めれば、View: Model: Table が 1:1:1 になると私は理解している。シンプルな構成、シンプルなサービス、複雑な機能を追加しない場合に採用されるものである。
しかし、システムが複雑化してテーブルとモデルが成長すると大変なことになる。ぐちゃぐちゃになりやすい。
上記の症状と重複するが、その問題もいくつかのパターンに分類できると思う。以下に問題パターンと対応した内容を述べてみる。
問題パターン1: プレゼン層にロジックが入り込んでいる
ビューやバッチインターフェースのやることは三つだけにしぼった。
- request や引数のパラメータのバリデーション
- 入力バリデータを作成し、移譲することもあった
- しかし多すぎて直しきれず。。。
- request・引数のパラメータをパースして別のレイヤーに処理を移譲
- ビューの場合、戻ってきたオブジェクトを response に詰めなおす
問題パターン2: 他のモデルと結合する処理がある
サービス層の導入
ここではサービス指向アーキテクチャの言葉を使っている。よくあるこんなヤツ。
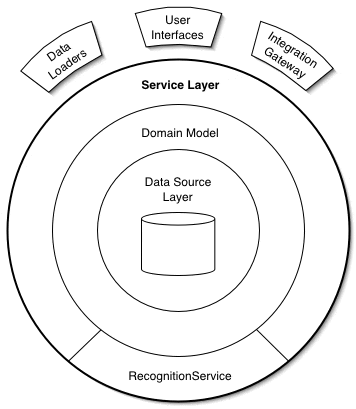
ビューやバッチインターフェースからサービス層のメソッドを実行するようにした。
用語の整理
ドメイン駆動設計だとアプリケーション・コントローラが該当する。ドメイン駆動設計でサービスとよんでいるものとは、違うので注意(Evans Classificationを参照)。
また、エンタープライズアプリケーションアーキテクチャパターンに Web プレゼンテーションパターンがあり、そこでもアプリケーションコントローラがある。
ああ、ややこしい。
命名規則
ビューにたいして粒度のあらい API を提供する。以下の2パターンで命名規則をわけた。
- ひとつのモデル (テーブル) のみで CRUD: XxxService
- 複数のモデル(テーブル)を結合して CRUD: YyyEngine
Singleton 化
ビューから呼び出すたびにインスタンスを生成するのも無駄になる。class デコレータで singleton 化するレシピを採用した。
カスタマイズした QuerySet
バッチ処理で JOIN した方が早い場合、結合した QuerySet で拡張したようなモデルで自由に使えるようにした。Foreign Key が貼られている場合について記述する。
想定される ER 図
item からあとから追加情報をもったモデルを作成することがあった。

これを JOIN したデータをひとつのモデルのようにあつかう。
基本的なモデル
大体こんな感じ。
class Item(models.Model):
name = models.CharField(max_length=128, blank=True)
description = models.CharField(max_length=1024, blank=True)
image = mdoels.ImageField(upload_to='hoge', blank=True, null=True)
class ItemFeature1(models.Model):
item = models.ForeignKey(Item)
feature_1 = models.TextField()
class ItemExtraInfo(models.Model):
item = models.ForeignKey(Item)
info = models.TextField()
結合用の QuerySet, Manager, Model
結合用 QuerySet はこんな感じ。select で join する前提で他は考慮しない。
class JoinedItemFeatureQuerySet(models.QuerySet):
def __iter__(self):
queryset = self.values(
'id', 'name', 'description', 'image',
'itemfeature1__feature_1',
'itemextrainfo__info')
results = list(queryset.iterator())
instances = []
for result in results:
item_feature = self.model(
result['id'],
result['name'],
result['description'],
result['image']
)
item_feature.feature_1 = result['itemfeature1__feature_1'] # モデルのプロパティを追加・詰めこむ
item_feature.info = result['itemextrainfo__info']
instances.append(item_feature)
return iter(instances) # iterator プロトコルに詰め直し
※ もっと他によいやり方がありそう。self._fetch_all() をオーバーライドして、self._result_cache に詰め込むほうがよかったかも。
class JoinedItemFeatureManager(models.Manager):
def get_queryset(self):
queryset = JoinedItemFeatureQuerySet(self.model, using=self._db)
queryset = queryset.filter(del_flg=False, itemfeature1__isnull=False, itemextrainfo__isnull=False) # null にならないように
return queryset
class JoinedItemFeatureDomain(Item):
objects = JoinedItemFeatureManager()
class Meta:
proxy = True # テーブルを作成しない。
joined_item_features = JoinedItemFeatureDomain.objects.filter(...) で自由にデータを使えるようになる。。。ハズ。
問題パターン3: モデルの処理が多すぎ・複雑すぎる
再利用できそうなメソッドは適度に抽象化(機械学習系とか)
strategy として切り出したり、計算専用クラスとして再利用できるようにした
- あとで使い回せそうだったり、企業の固有ライブラリにできそうなモノが対象
- 機械学習系の学習済みmodelはサイズが大きい。なんども load したくないので一部 singleton 化した。
- 計算途中の変数メモリが残っていたかも
- pickle.dump で predict するパラメータのみを保存することもあった
Model はテーブルと対応づけるのみにして、処理はサブクラスで実装
Django だと proxy model という方法があって、サブクラスでその設定をした。
以下、個人プロジェクトのコードを抜粋しておく。
from django.contrib.auth.models import User
from django.db import models
class AbstractModel(models.Model):
registered_at = models.DateTimeField(auto_created=True)
registered_by = models.ForeignKey(User, related_name='%(class)s_registered_by')
updated_at = models.DateTimeField(auto_now_add=True)
updated_by = models.ForeignKey(User, related_name='%(class)s_updated_by')
class Meta:
abstract = True
from django.contrib.auth.models import User
from intro.models.abstract_model import AbstractModel
class Article(AbstractModel):
title = models.CharField(max_length=128)
description = models.CharField(max_length=2048)
author = models.ForeignKey(Author) # Author クラスの記述は省略
categories = models.ForeignKey(Category, null=True, blank=True) # Category クラスの記述は省略
url = models.URLField()
from intro.models.article import Article
from intro.consts import DEFAULT_MECAB_PATH
class ArticleDomain(Article):
class Meta:
proxy = True
def __init__(self, *args, **kwargs):
# Do initialize...
def __call__(self, mecab_path=None):
if not mecab_path:
self.mecab_path = DEFAULT_MECAB_PATH
def parse_morpheme(self):
# Do morpheme analysis
@classmethod
def train(cls, filter_params)
authors = filter_params.get('author')
articles = None
if authors and articles:
articles = Articles.objects.filter(authors__in=authors)
# Do some extraction
# Do training
def predict(self, texts)
# Do prediction
テストコードの導入
リファクタリングしつつ、from django.test import TestCase で単体テストを作成
当たり前だけど、コードの見通しがめちゃくちゃよくなった
(カスタマイズした QuerySet で)データ抽出条件をかえたサブクラスの実装
CustomManager クラスで get_queryset の中でデータ抽出条件を変え、その CustomManager を proxy クラスで保持するようにした。
バッチ用に複雑化したドメインモデルで威力を発揮した。
Email 送信/外部サービス連携はヘキサゴナル・アーキテクチャを採用
モデルの中で email の送信実装を書いたり、外部サービスへの連携のために urllib2 をベタに描くのは流石にカッコわるい。
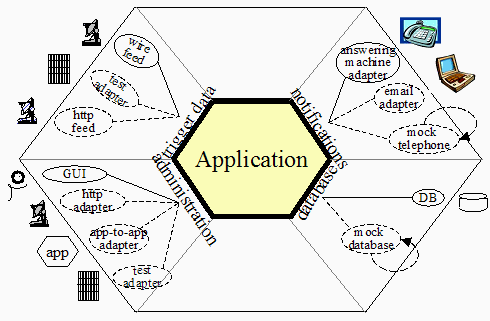
外部連携用の Gateway クラス(上記の図では adapter と書いている)をつくって、ドメインモデルクラスかモデルクラス(上記の図では Application と書いている)で Gateway クラスを継承して使用するようにした。
通常、モデルクラスはお便利メソッドをスーパークラスから継承して使用している。それにならって、Gateway クラスを継承してお便利メソッドを使用する形にした。
最後に
原因3については、経営者に見切りをつけて転職することにした(CTO だけまともだが)。
時間をかければもっと会社をよくすることはできたかもしれない。しかし人が変わることにかかる時間、技術が進歩する速度、他の企業からの条件を検討すると、残った場合は自分の時間・人生を無駄にすると思った。そういう無駄を許容できるほど、私はもう若くないのである。独りよがりな他人の思い出作りに付き合うほど、私はもう若くないのである。
スタートアップにかぎらないが、経営者は超重要と認識したのだった。