fushimiです。
この記事は Wanoグループ Advent Calendar 2019 Advent Calendar 2019 の11日目の記事になります。
(英語)会議 is ...
最近プロジェクトではニューヨークのチームと英語での会議をする機会が多いです。基本リスニングも不得手なので、会議同席中も熱が入って速度が速い時はなかなか聞き取れないことがあります。
そこで会議の後など、勉強/議事録がてらAmazon Transcribeでの音声文字起こしを見てわからなかったところの文脈を追ってみたりしています。
今回はTranscribeの出力をmarkdown化するやつをwebアプリに起こしてみました。
制作物
リポジトリ:
wano/aws-transcribe-render
アプリケーションのページ:
https://wano.github.io/aws-transcribe-render/
Amazon Transcribe
いわゆる文字起こしサービスです。S3上の音声ファイルを解析してくれます。
最近日本語対応したり東京リージョンで使えるようになったりしました。
ただ文字起こしをする、ってだけではなく、**話者解析(誰がそのフレーズを喋っているか)**が取得できるのがなかなか面白いところかな、と思います。
Termは割と適当なんだけど、話者解析もあって文脈が追えるので復習にはいいかな...というステータスのサービスです。
ちょっとした文ならコンソール上で結果がプレビューできるのですが、ある程度の長さになると出力結果であるオリジナルのjsonを使うしかありません。
...
Can you see the seats? No option. Hello. It's not"}],"speaker_labels":{"speakers":8,"segments":[{"start_time":"1.44","speaker_label":"spk_4","end_time":"2.35","items":[{"start_time":"1.44","speaker_label":"spk_4","end_time":"1.81"},{"start_time":"1.94","speaker_label":"spk_4","end_time":"2.35"}]},{"start_time":"11.94","speaker_label":"spk_4","end_time":"12.45","items":[{"start_time":"11.94","speaker_label":"spk_4","end_time":"12.45"}]},{"start_time":"13.71","speaker_label":"spk_4","end_time":"14.16","items":[{"start_time":"13.71","speaker_label":"spk_4","end_time":"14.16"}]},{"start_time":"14.71","speaker_label":"spk_4","end_time":"15.38","items":[{"start_time":"14.71","speaker_label":"spk_4","end_time":"15.38"}]},{"start_time":"16.24","speaker_label":"spk_4","end_time":"16.91","items":[{"start_time":"16.24","speaker_label":"spk_4","end_time":"16.91"}]},{"start_time":"25.86","speaker_label":"spk_1","end_time":"26.97",
...
こういう感じ。なかなか辛い
初めはPHP製のパーサーaws-transcribe-transcriptを改変してコマンド叩いていたのですが、jsonパース/整形/改変くらいwebのクライアントサイドでサクッとやれるべきだよな...という感想があったので、今回のアドベントカレンダーを機にjsで書いてみました。
aws-transcribe-render
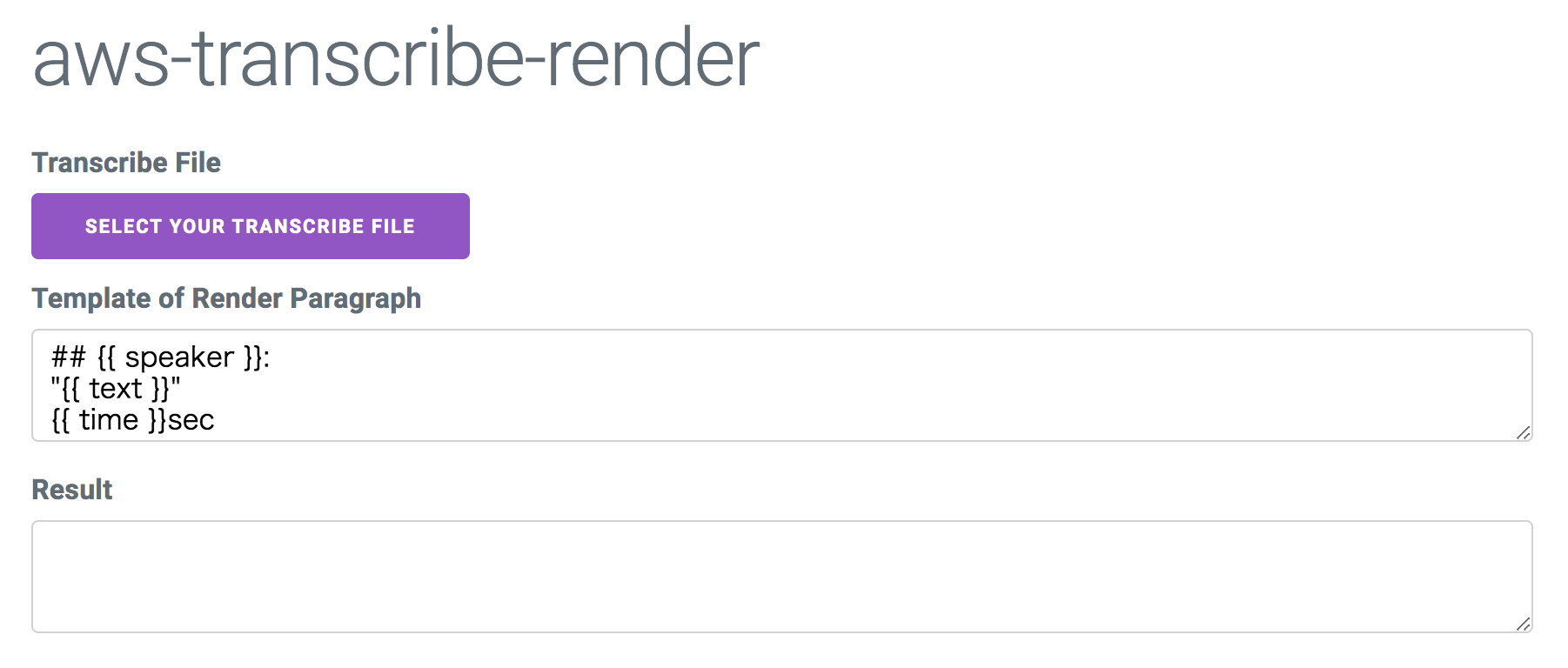
markdown化する、と書きましたが、mustache記法でテンプレを書いているだけなのでなんでもありといえばありです。
テンプレートの塊は、ある話者が話し始めてから終わるまでとなっています。
使い方
事前: まずは文字起こし
まず、会話/会議の音声データをs3に上げ、transcribeのコンソールからjson化しておきます。
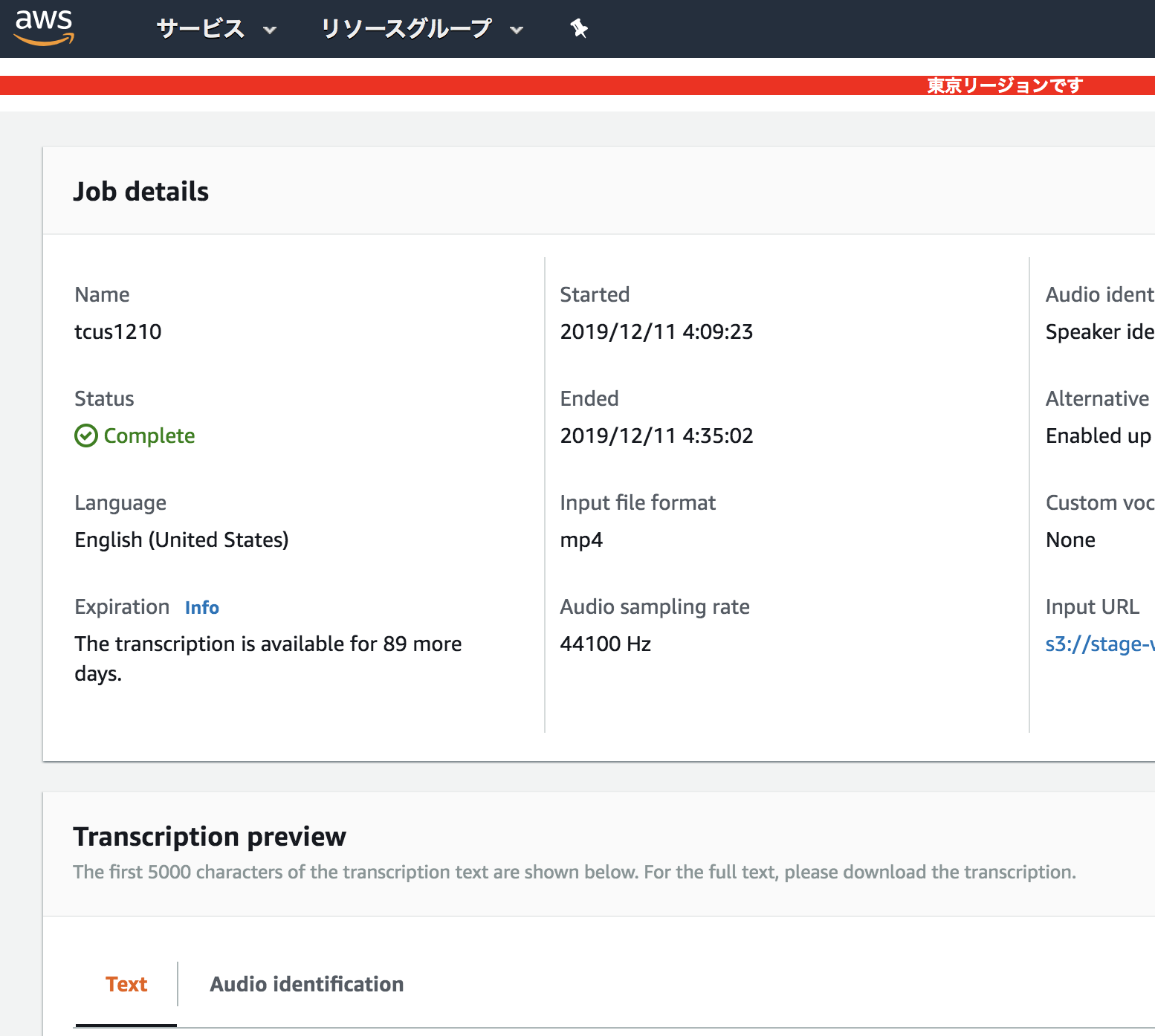
jsonをアプリに入力/テンプレート編集
そのjsonをこちらのアプリに入力します。
- speaker
- text
- time
がテンプレート変数として渡ってくるので、markdownでもhtmlでもお好みのフォーマットで出力できます。
話者名の上書き機能
Transcribeのデフォルトの話者名を上書きすることもできます。
spk_0 という身も蓋もないラベリングになってたりするので、多少記憶を掘り起こし話者の名前を書きましょう。
結果
ここまでの結果が以下のような感じです。
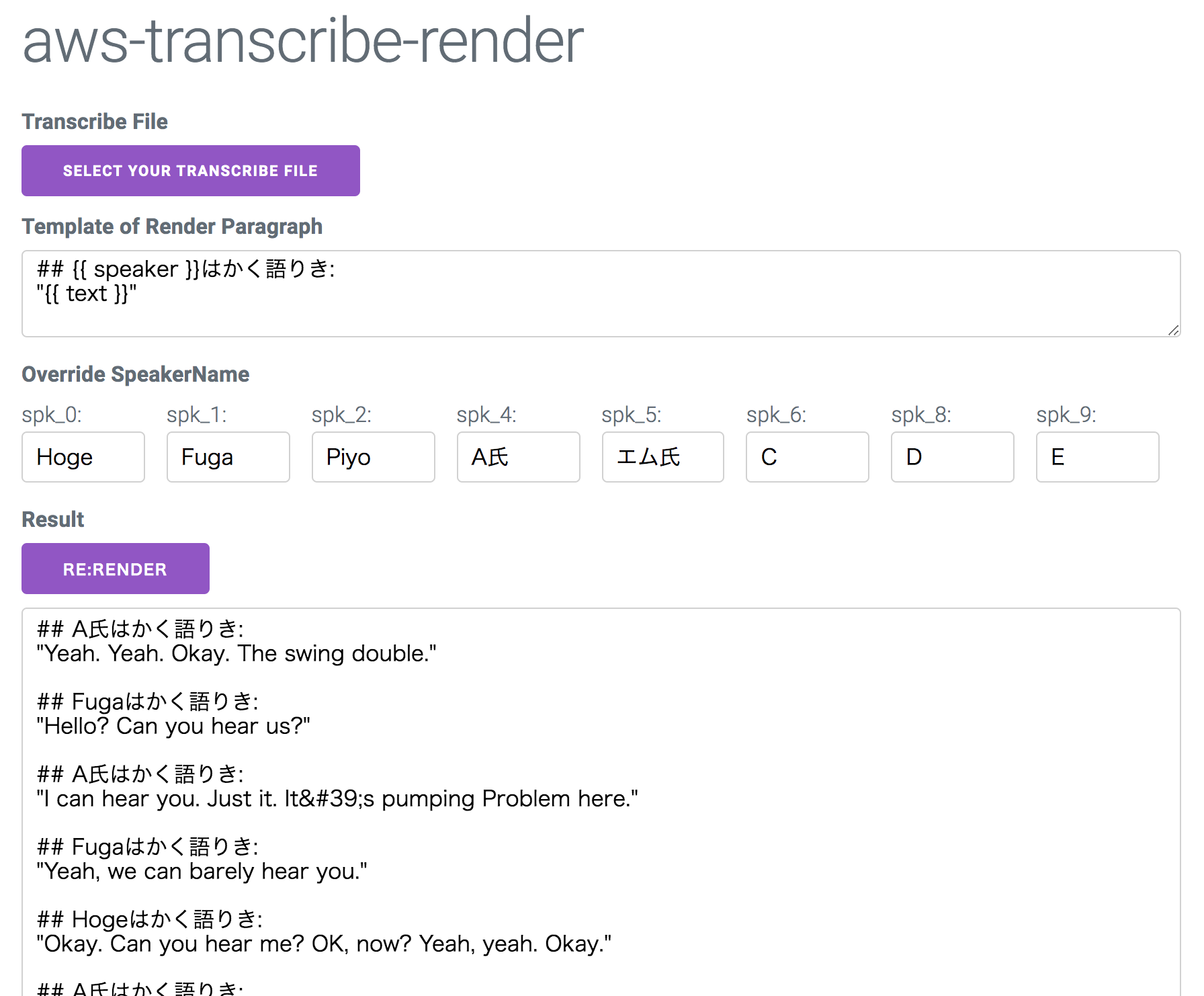
あとはコピーして議事録に貼り付けるなど。
まとめ
これで、出力結果をinputするだけでさっくりと編集する機能ができました。
英語で行われるミーティングでまた試す予定ですが、そういえば日本語会話でTranscribeを試したことがないので、そちらの精度も気になりますね。
課題
- 外に出しても差し支えないような会話でアプリにサンプルを載っけたかったんだけど、著作権フリーな「会話音声データ」ってなかなか見つからないですね....
- GUIと関係ないコア部分のロジックは切り離されていますが、肝心のnpmモジュール化とかはまだしていません。
1年以上ぶりくらいにReactを触ったら「useStateすげー!」「useEffectすげー!」ってなってたりしたのでそっちで時間が溶けました。 - XSS対策真面目にやっていません。mustacheのテンプレをそのまま出しています。どこか永続化するサイトに使うわけでもないのでどうということはないのですが。