概要
2013年7月の雑誌掲載論文。
(Article in Information Processing & Management· July 2013)
WEB上の記事から、最も有用な部分を抽出する手法を作成しようとしている。
抽出対象記事については、ヘッドライン、記事概要、記事内容という3つのセットを作成することを目標としている。
教師データの作成手法として、WEBページからHTML情報を取得し、最も有用と思われる情報について人手でラベル付けを行っている。(結果、ほとんどTDタグ、DIVタグが正解タグであった)
実現のために機械学習を利用してルールを作成して適用する手法を提案している。
DIVタグが入れ子になっている場合など、親タグ自身に情報がない場合、子タグから特徴量を作成するのがふさわしいとして、After Extractionという手法を提案している。
そのため特徴量を作成する際、単純にタグ内情報を使うのではなく、親タグは最も子タグの情報から特徴量を作成している。
特徴量の作成
タグ内の単語数、リンク数などから特徴量を作成している。
テキストに関して作成した特徴量
| 特徴量名称 | 説明(英語) | 説明(日本語) |
|---|---|---|
| (1) Word Frequency (WF) | The number of terms inside tags | タグ内の単語数 |
| (2) Density in HTML (D-HTML) | The ratio of the number of terms inside tags to the number of all terms inside the HTML document | タグ内の単語数の割合(HTML文書全体のうちの) |
| (3) Link Frequency (LF) | The count of A HREF links inside tags | タグ内のリンク数 |
| (4) Word Frequency in Links (WF-L) | The count of terms inside A HREF links placed tags | aタグ内の単語数 |
| (5) Average Word Frequency in Links (A-WF-L) | The ratio of the number of terms inside A HREF links placed inside tags to the number of links | aタグにおける平均的な単語数 |
| (6) Ratio of Word Frequency in Links to All Words(R-WF-L-AW) | The ratio of the number of terms inside A HREF links placed inside tags to all of the number ofterms inside tags. | 全タグの単語数に対するaタグ内の単語数比率 |
After Extraction(AE)による特徴量の作成
ラベル付けを行った結果、TD、DIVタグが最も有用な情報源であることが判明したが、
DIVタグが入れ子になっている場合など、囲んでいるだけのタグについては、特徴が取得できない。
そのため、特徴量を作成する際、単純にタグ内情報を使うのではなく、親タグは最も子タグの情報からも特徴量を作成している。「After Extraction」としており、研究の新規性であると示している。
テキストに関して作成した特徴量(After Extractionによる)
| 特徴量名称 | 説明 |
|---|---|
| (7) Word Frequency-AE (WF-AE) | AE評価を行なった単語数 |
| (8) Density in HTML-AE (D-HTML-AE) | AE評価を行なった、HTML文書全体のうちのタグ内の単語数の割合 |
| (9) Link Frequency-AE (LF-AE) | AE評価を行なった、タグ内のリンク数 |
| (10) Word Frequency in Links-AE (WF-L-AE) | AE評価を行なった、aタグ内の単語数 |
| (11) Average Word Frequency in Links-AE (AWF-L-AE) | AE評価を行なった、aタグにおける平均的な単語数 |
| (12) Ratio of Word Frequency in Links to All Number of Words-AE (R-WF-L-AW-AE) | AE評価を行なった、全タグの単語数に対するaタグ内の単語数比率 |
テキスト以外の特徴量
| 特徴量名称 | 説明(英語) | 説明(日本語) |
|---|---|---|
| (13) Tag Name (TN) | One of the tag name (TD, DIV, H1–H6, P, FONT, A HREF, SPAN, EM, UL, and LI) | タグ名 |
| (14) Contains Tag ID or CLASS (C-TC) | Whether the tag has an attribute of ID or CLASS | ID属性を持っているかCLASS属性を持っているか(※) |
| ※cssの構造上、class名は繰り返し出てくるがIDは一意なものが多いため特徴量にしていると思われる |
結論
ベイジアンやK近傍法など様々な手法を試したが、結果的に決定木のSub-tree Raisingモデル(部分木を上位と入れ替えたほうがいいならば入れ替えるアルゴリズム)を適用してルールを抽出した。
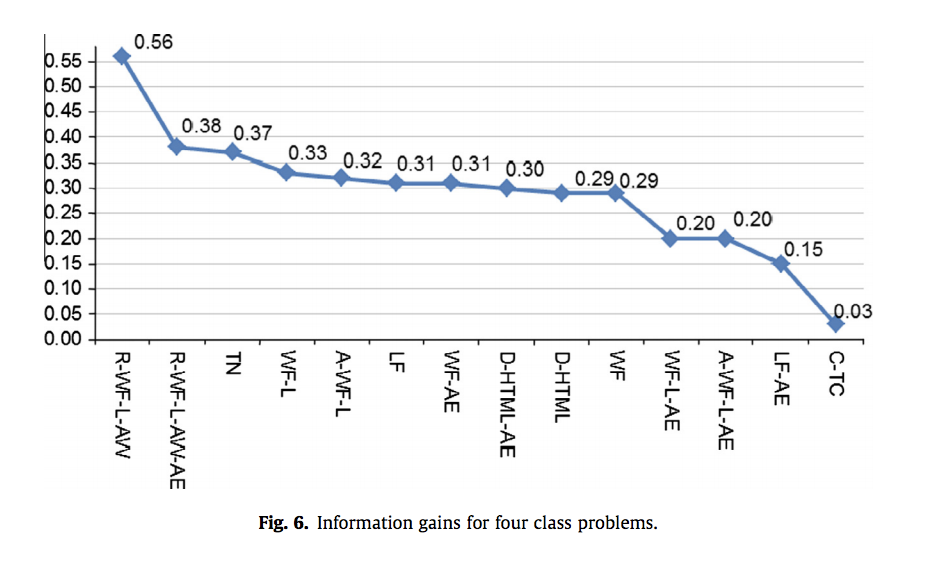
モデル構築時に最も役立った特徴量TOP3は以下のとおり
- (6) Ratio of Word Frequency in Links to All Words(R-WF-L-AW)
全タグの単語数に対するaタグ内の単語数比率 - (12) Ratio of Word Frequency in Links to All Number of Words-AE (R-WF-L-AW-AE)|AE評価を行なった、全タグの単語数に対するaタグ内の単語数比率
- (13) Tag Name (TN) タグ名
特徴量の貢献度. 論文より
ルールを適用することでRecall 96% Precision 96% F値 96%を実現できたとのことである。
原論文
A hybrid approach for extracting informative content from web pages