はじめに
この記事では、AWSのサービスを使用して自然言語からSQLクエリを生成するサービスを構築する手順を紹介します。
近年、Text-to-SQLにより、自然言語での質問からSQLクエリを生成するサービスが増えてきています。
しかし、これらを実際の業務で用いる場合、複数のテーブルにまたがる複雑なクエリが必要なケースや、テーブル名やカラム名だけではデータの内容をが想定できないケースでは、回答精度が低くなってしまうなどの課題が存在します。
そこで、この記事ではAWSの Bedrock Flows と Bedrock Knowledge Base 構造化データ を用いてこれらの課題を解決する回答精度の高いシステムの構築方法を紹介します。
ステップ0: データの確認
このハンズオンを進めるために、以下のテスト用データを用意しておきます。
実際の業務で使われるような、複数のテーブルかつ、設計書が無いと内容を把握しづらいデータです。
1. テーブルデータ
trx(トランザクション)
t_id,p_ref,c_ref,d_ref,amt,disc
1,1001,2001,3001,1200.50,50.00
2,1002,2002,3002,800.00,0.00
3,1001,2003,3003,1500.00,100.00
4,1003,2001,3004,2000.00,150.00
5,1002,2004,3005,950.75,0.00
prd(製品)
p_ref,p_desc,grp,prc
1001,'Item Alpha',10,400.00
1002,'Item Beta',20,300.00
1003,'Item Gamma',10,600.00
1004,'Item Delta',30,750.00
cust(顧客)
c_ref,c_nm,loc,lvl
2001,'Corp A',1,'H'
2002,'Corp B',2,'M'
2003,'Corp C',1,'L'
2004,'Corp D',3,'H'
dt(日付)
d_ref,dt_val,yr,mth,qtr
3001,'2023-01-10',2023,1,1
3002,'2023-02-15',2023,2,1
3003,'2023-03-20',2023,3,1
3004,'2023-04-05',2023,4,2
3005,'2023-05-30',2023,5,2
2. 設計書
Table Name,Field Name,Data Type,Description,Constraints,Relationships
trx,t_id,integer,トランザクションID,primary key,
trx,p_ref,integer,製品参照,foreign key,prd(p_ref)
trx,c_ref,integer,顧客参照,foreign key,cust(c_ref)
trx,d_ref,integer,日付参照,foreign key,dt(d_ref)
trx,amt,decimal,トランザクション金額,,
trx,disc,decimal,割引額,,
prd,p_ref,integer,製品参照,primary key,
prd,p_desc,string,製品説明,,
prd,grp,integer,製品グループ番号,foreign key,grp_table(grp_id)
prd,prc,decimal,標準価格,,
cust,c_ref,integer,顧客参照,primary key,
cust,c_nm,string,顧客名,,
cust,loc,integer,場所ID,foreign key,loc_table(loc_id)
cust,lvl,string,顧客レベル(H=高/M=中/L=低),,
dt,d_ref,integer,日付参照,primary key,
dt,dt_val,date,日付値,,
dt,yr,integer,年,,
dt,mth,integer,月,,
dt,qtr,integer,四半期,,
ステップ1: VPCの設定
まず、VPCを作成します。サービスメニューから「VPC」を選択し、「VPCを作成」から「VPCのみ」を選択します。プライベートサブネットが1つのVPCを作成し、CIDRは10.0.0.0/24を設定して作成します。
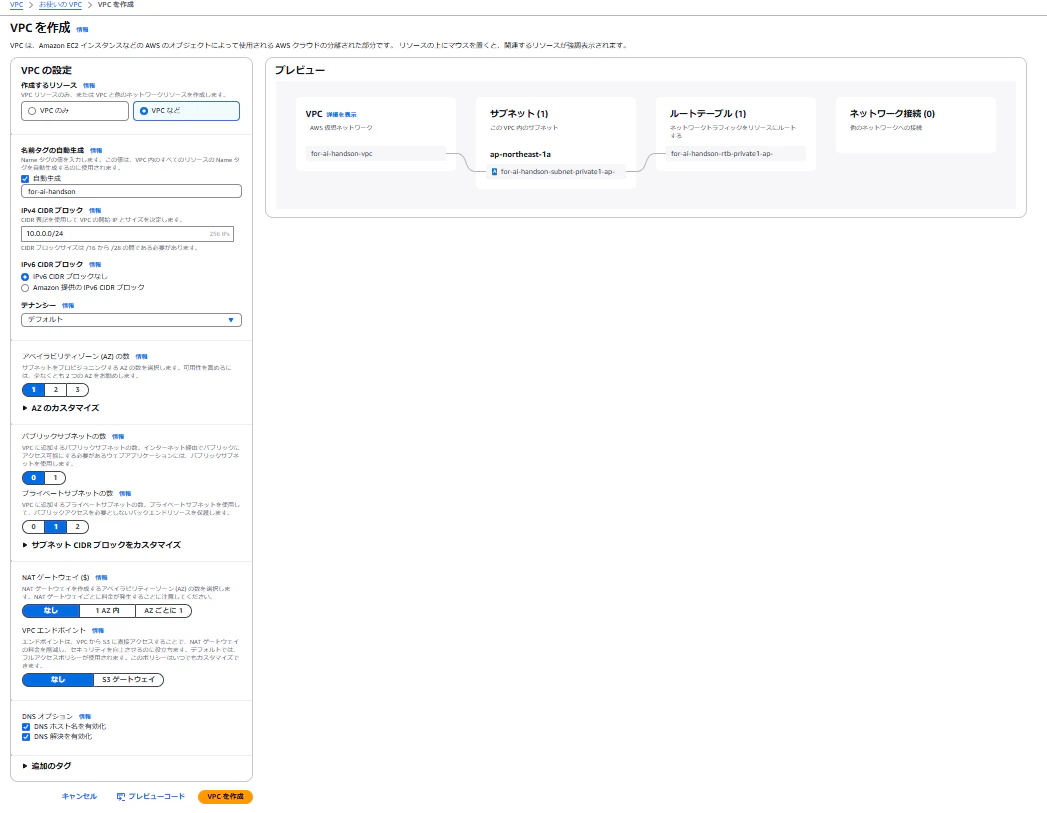
ステップ2: Redshiftの設定
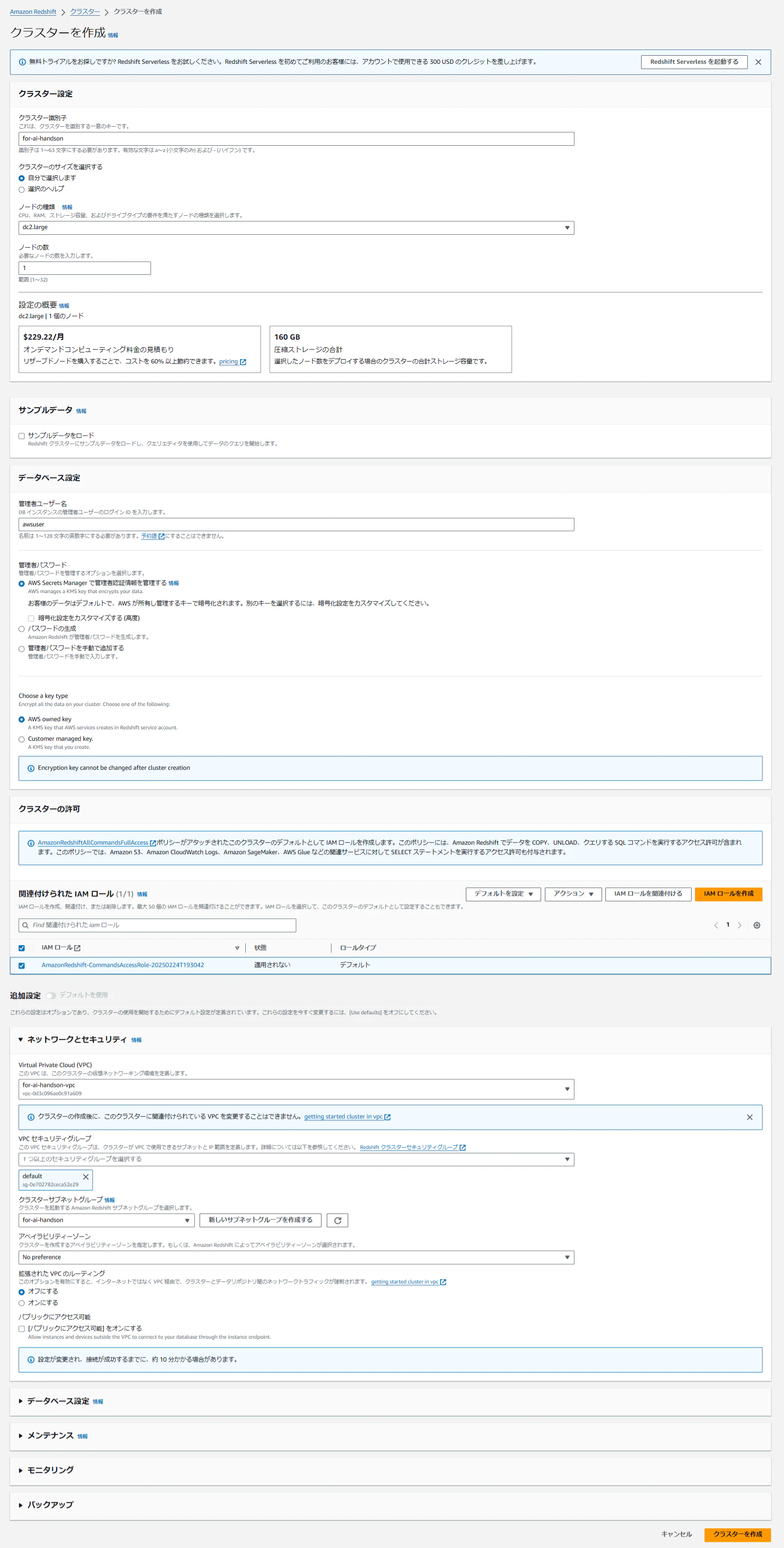
次に、Redshiftクラスターを作成します。サービスメニューから「Redshift」を選択し、「プロビジョニングされたクラスターダッシュボード」を開きます。「クラスターを作成」から以下の設定でクラスターを構築します。
- ノードの種類:
dc2.large - ノードの数:
1 - 「クラスターの許可」から「IAMロールを作成」を選択します。
- 「ネットワークとセキュリティ」から「クラスターサブネットグループ」の作成を選択し、「新しいサブネットグループを作成する」を選ぶ。先ほど作成したVPCとサブネットを指定して「クラスターサブネットグループの作成」を実行。
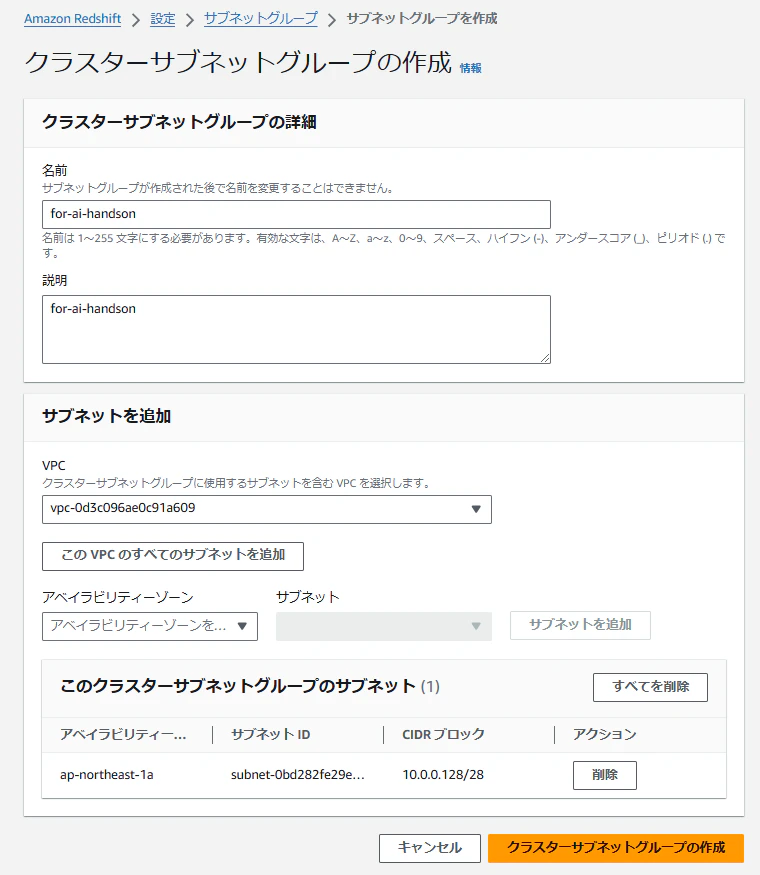
サブネットグループを登録し、最低料金でRedshiftクラスターを作成します。
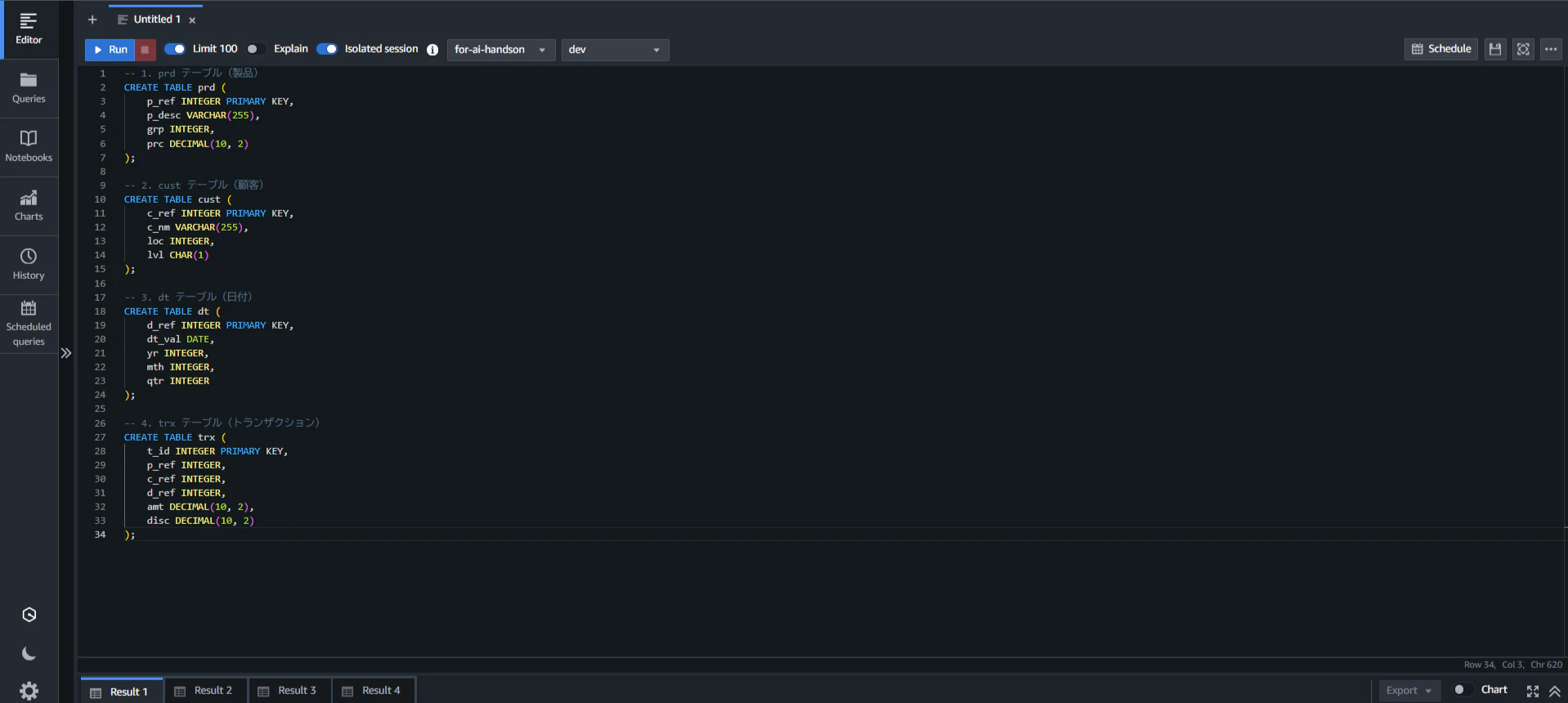
次に、Redshiftにデータを追加します。作成したクラスターからクエリエディタV2を開き、以下のコマンドを実行し、先ほど用意したテーブルデータをINSERTします。
テーブル作成コマンド
-- 1. prd テーブル(製品)
CREATE TABLE prd (
p_ref INTEGER PRIMARY KEY,
p_desc VARCHAR(255),
grp INTEGER,
prc DECIMAL(10, 2)
);
-- 2. cust テーブル(顧客)
CREATE TABLE cust (
c_ref INTEGER PRIMARY KEY,
c_nm VARCHAR(255),
loc INTEGER,
lvl CHAR(1)
);
-- 3. dt テーブル(日付)
CREATE TABLE dt (
d_ref INTEGER PRIMARY KEY,
dt_val DATE,
yr INTEGER,
mth INTEGER,
qtr INTEGER
);
-- 4. trx テーブル(トランザクション)
CREATE TABLE trx (
t_id INTEGER PRIMARY KEY,
p_ref INTEGER,
c_ref INTEGER,
d_ref INTEGER,
amt DECIMAL(10, 2),
disc DECIMAL(10, 2)
);
INSERT文
-- 1. prd テーブル(製品)
INSERT INTO prd (p_ref, p_desc, grp, prc) VALUES
(1001, 'Item Alpha', 10, 400.00),
(1002, 'Item Beta', 20, 300.00),
(1003, 'Item Gamma', 10, 600.00),
(1004, 'Item Delta', 30, 750.00);
-- 2. cust テーブル(顧客)
INSERT INTO cust (c_ref, c_nm, loc, lvl) VALUES
(2001, 'Corp A', 1, 'H'),
(2002, 'Corp B', 2, 'M'),
(2003, 'Corp C', 1, 'L'),
(2004, 'Corp D', 3, 'H');
-- 3. dt テーブル(日付)
INSERT INTO dt (d_ref, dt_val, yr, mth, qtr) VALUES
(3001, '2023-01-10', 2023, 1, 1),
(3002, '2023-02-15', 2023, 2, 1),
(3003, '2023-03-20', 2023, 3, 1),
(3004, '2023-04-05', 2023, 4, 2),
(3005, '2023-05-30', 2023, 5, 2);
-- 4. trx テーブル(トランザクション)
INSERT INTO trx (t_id, p_ref, c_ref, d_ref, amt, disc) VALUES
(1, 1001, 2001, 3001, 1200.50, 50.00),
(2, 1002, 2002, 3002, 800.00, 0.00),
(3, 1001, 2003, 3003, 1500.00, 100.00),
(4, 1003, 2001, 3004, 2000.00, 150.00),
(5, 1002, 2004, 3005, 950.75, 0.00);
ステップ3: Bedrock Knowledge Base構造化データの設定
Bedrock Knowledge Base構造化データを設定し、Redshiftの構造化データに対して自然言語で質問できるようにします。
- AWSマネジメントコンソールでBedrockサービスに移動。
- メニューから「ナレッジベース」を選択。
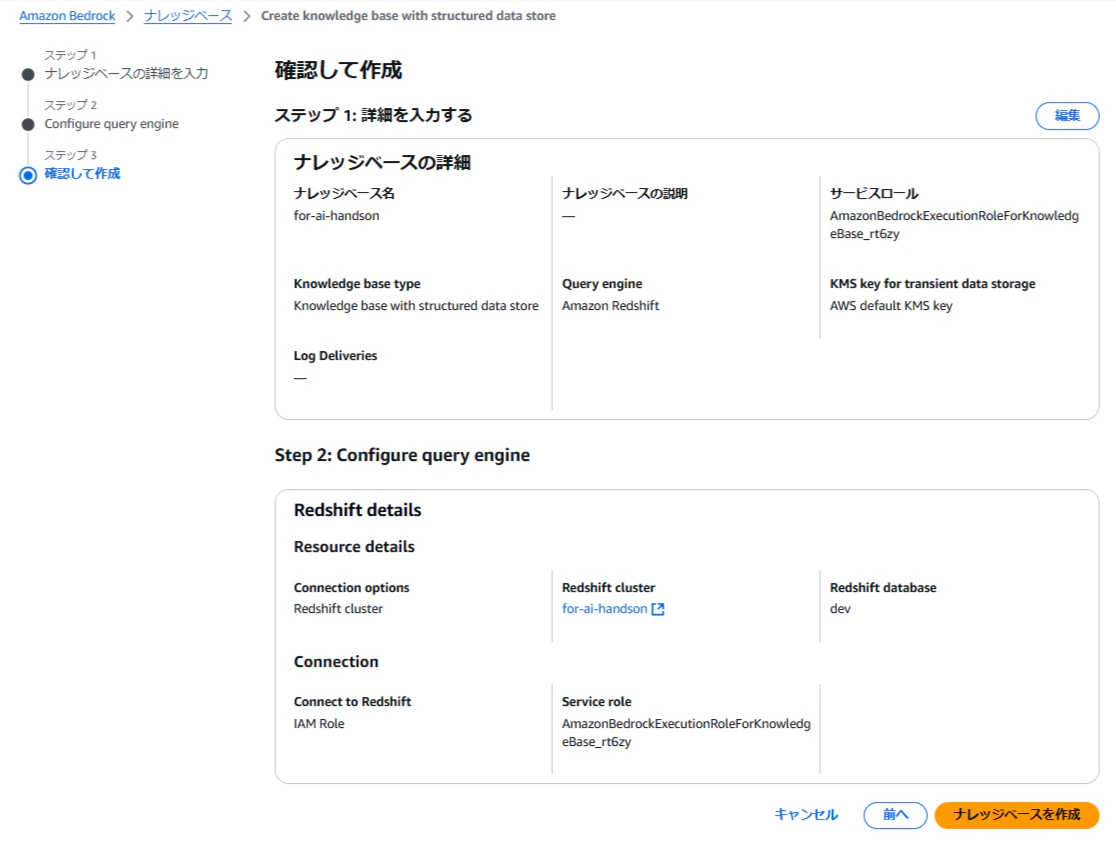
- 「ナレッジベースを作成」から「Knowledge Base with Structured Data Store」をクリックして新しいナレッジベースを作成。
- 名前を入力し、Connection Optionsで「Redshift Cluster」を指定。作成済みのRedshiftクラスターとデータベースを選択。
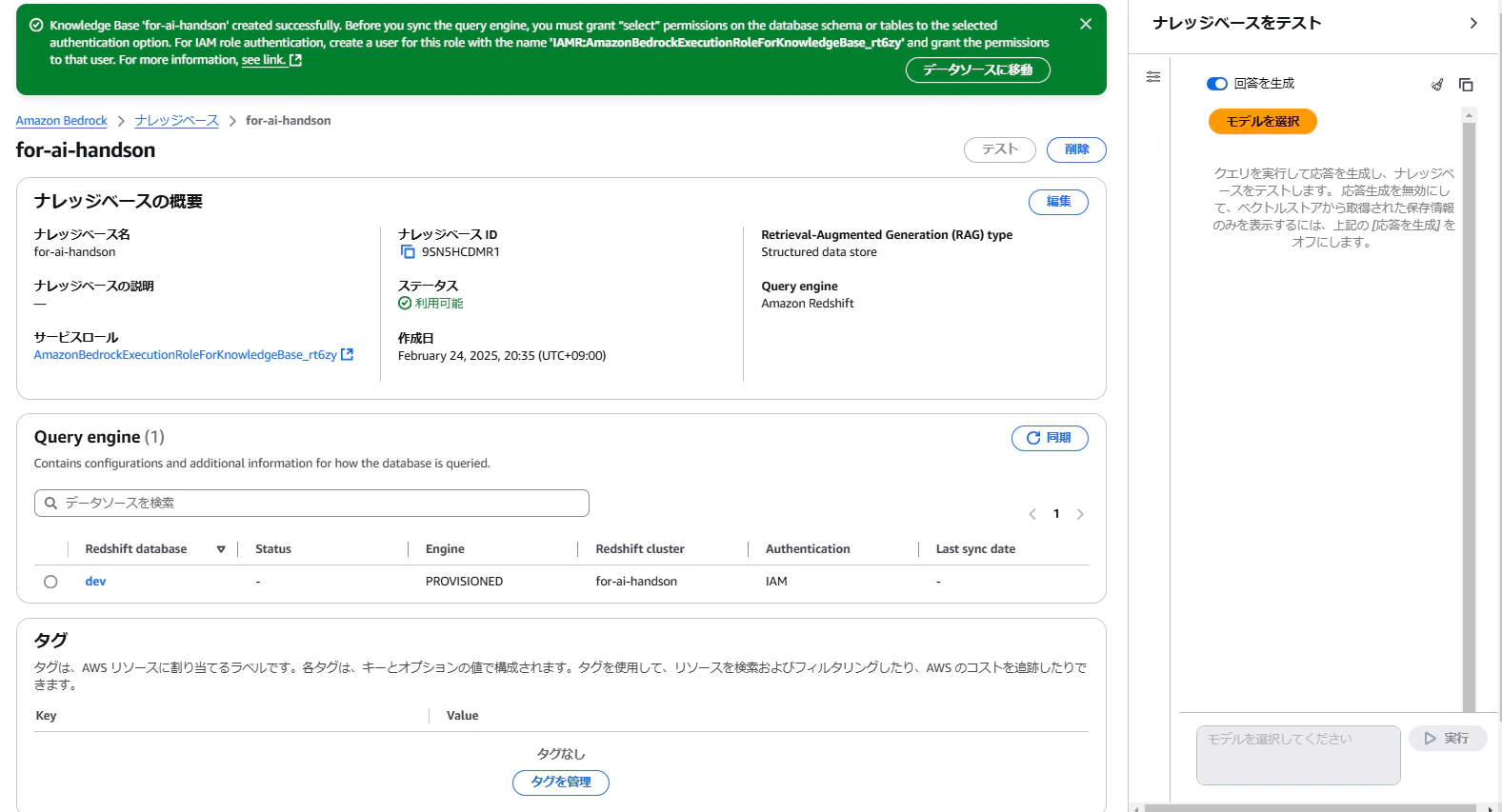
- ナレッジベースを作成。
次に、RedshiftのクエリエディタV2から以下のコマンドを実行し、ナレッジベースからRedshiftにクエリを実行できるように権限を付与します。
-- ナレッジベースにスキーマ使用権限を付与
GRANT USAGE ON SCHEMA public
TO "IAMR:AmazonBedrockExecutionRoleForKnowledgeBase_rt6zy";
-- ナレッジベースにテーブルへのSELECT権限を付与
GRANT SELECT ON prd
TO "IAMR:AmazonBedrockExecutionRoleForKnowledgeBase_rt6zy";
GRANT SELECT ON cust
TO "IAMR:AmazonBedrockExecutionRoleForKnowledgeBase_rt6zy";
GRANT SELECT ON dt
TO "IAMR:AmazonBedrockExecutionRoleForKnowledgeBase_rt6zy";
GRANT SELECT ON trx
TO "IAMR:AmazonBedrockExecutionRoleForKnowledgeBase_rt6zy";
IAMRは作成したナレッジベースのIAMロール名です。
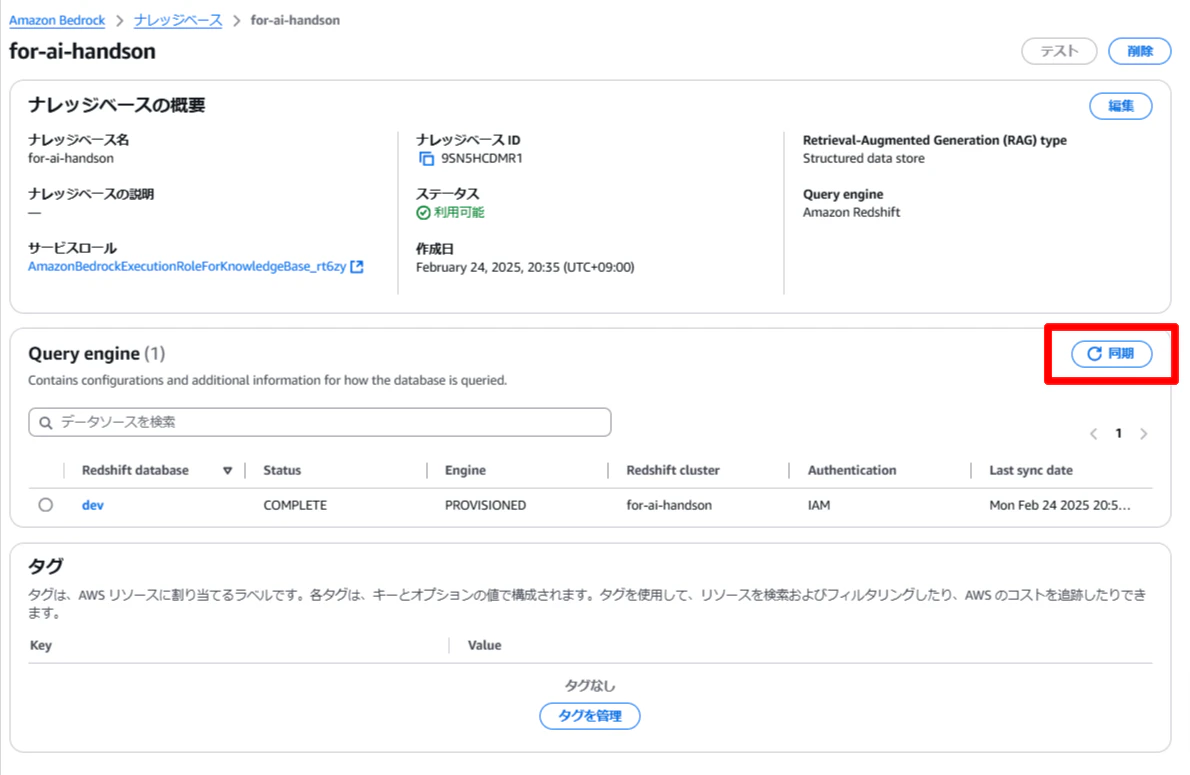
その後、ナレッジベースの「同期」を選択して同期を実行します。
ナレッジベース単体でのテスト
Bedrockのモデルアクセスを有効化し、Claude 3.5 Sonnet v2を有効にします。「ナレッジベースをテスト」からClaude 3.5 Sonnet v2を選択し、以下の質問を入力します。
製品グループごとの平均トランザクション金額を表示してください。
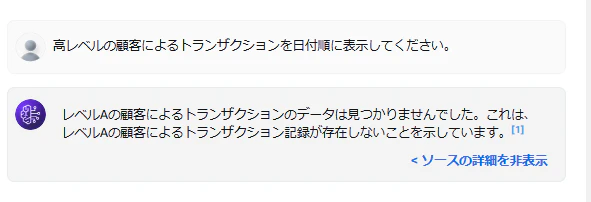
この時点では設計書データが提供されていないため、回答が得られないことが確認できます。
ステップ4: Bedrock Flowの設定
Bedrock Flowを使用して、設計書データの取得からSQL生成、結果取得までのワークフローを設計します。
- AWSマネジメントコンソールでBedrockサービスに移動し、「Bedrock Flow」セクションを選択。
- 「Create Flow」をクリックして新しいフローを作成。
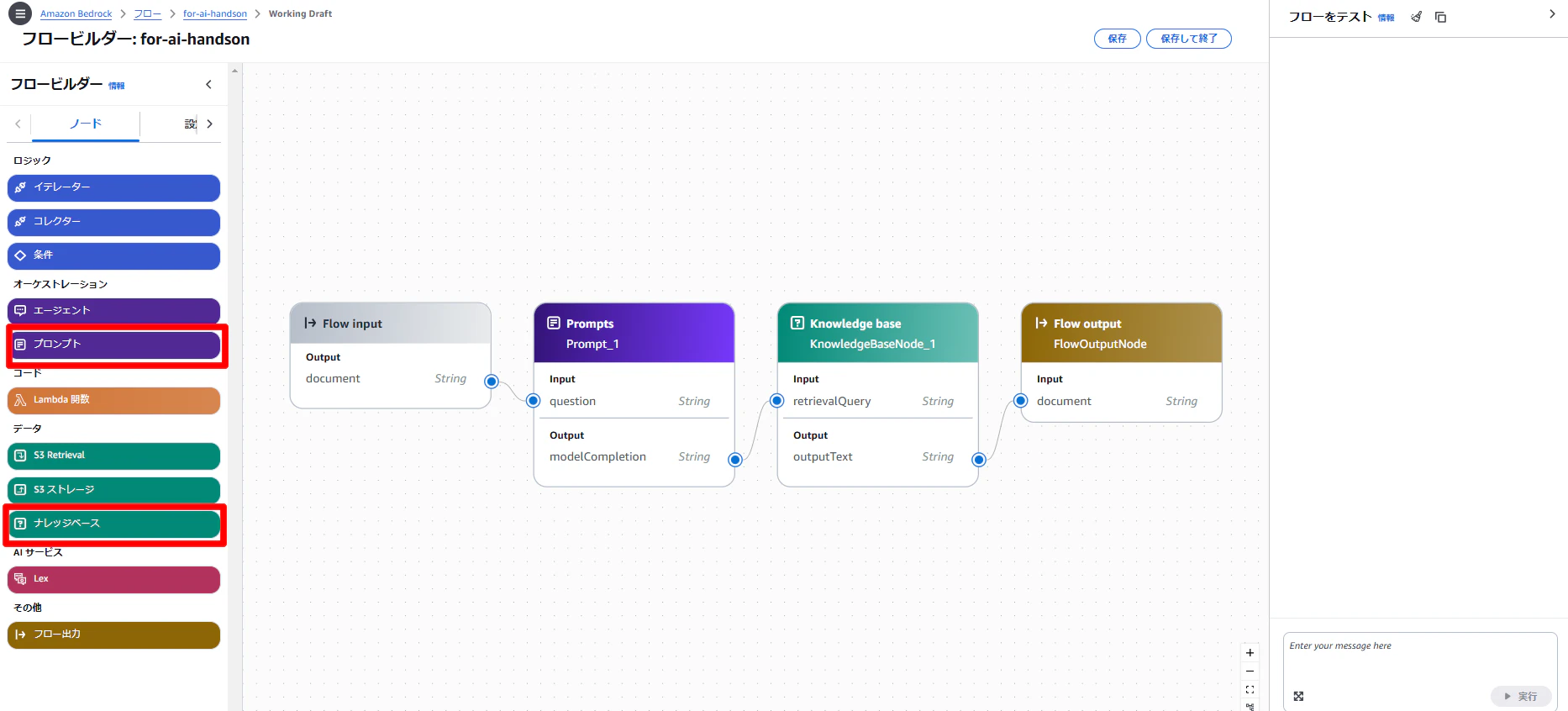
- ノード「Prompts」と「Knowledge Base」を選択し、以下のようにフローを接続:
Flow Input→Prompts→Knowledge Base→Flow Output
-
Promptsノードに以下のプロンプトを入力し、モデルを設定。
あなたは、データベースのテーブルの設計書と質問を受け取り、それに基づいて自然言語からSQLを生成する質問を生成するLLMエージェントです。
以下に、テーブルの設計書です。
<設計書>
Table Name,Field Name,Data Type,Description,Constraints,Relationships
trx,t_id,integer,トランザクションID,primary key,
trx,p_ref,integer,製品参照,foreign key,prd(p_ref)
trx,c_ref,integer,顧客参照,foreign key,cust(c_ref)
trx,d_ref,integer,日付参照,foreign key,dt(d_ref)
trx,amt,decimal,トランザクション金額,,
trx,disc,decimal,割引額,,
prd,p_ref,integer,製品参照,primary key,
prd,p_desc,string,製品説明,,
prd,grp,integer,製品グループ番号,foreign key,grp_table(grp_id)
prd,prc,decimal,標準価格,,
cust,c_ref,integer,顧客参照,primary key,
cust,c_nm,string,顧客名,,
cust,loc,integer,場所ID,foreign key,loc_table(loc_id)
cust,lvl,string,顧客レベル(H=高/M=中/L=低),,
dt,d_ref,integer,日付参照,primary key,
dt,dt_val,date,日付値,,
dt,yr,integer,年,,
dt,mth,integer,月,,
dt,qtr,integer,四半期,,
</設計書>
また、質問が{{question}}として与えられます。
あなたのタスクは、与えられたテーブルの設計書と質問に基づいて、適切なSQLクエリを生成するための質問を考えることです。生成された質問は、自然言語からSQLを生成するためのものである必要があります。
質問を生成する際には、テーブルの設計書に含まれるテーブルの構造や関係性を考慮し、質問がSQLクエリを生成するのに十分な情報を含むようにしてください。
<重要>
質問のみを生成してください。追加の説明や文言は不要です。生成された質問は、自然言語からSQLを生成するためのものである必要があります。
</重要>
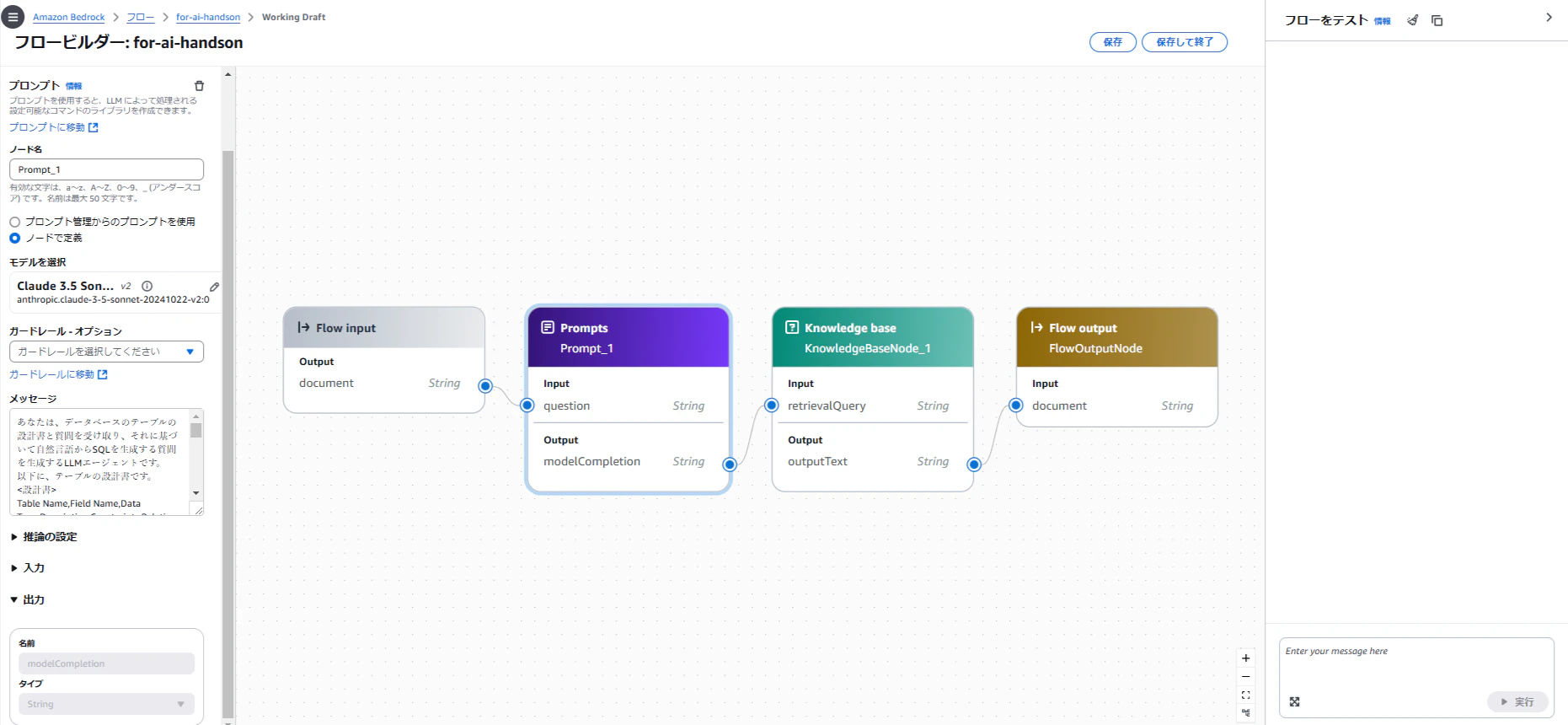
-
Knowledge Baseノードに、作成したナレッジベースを設定。
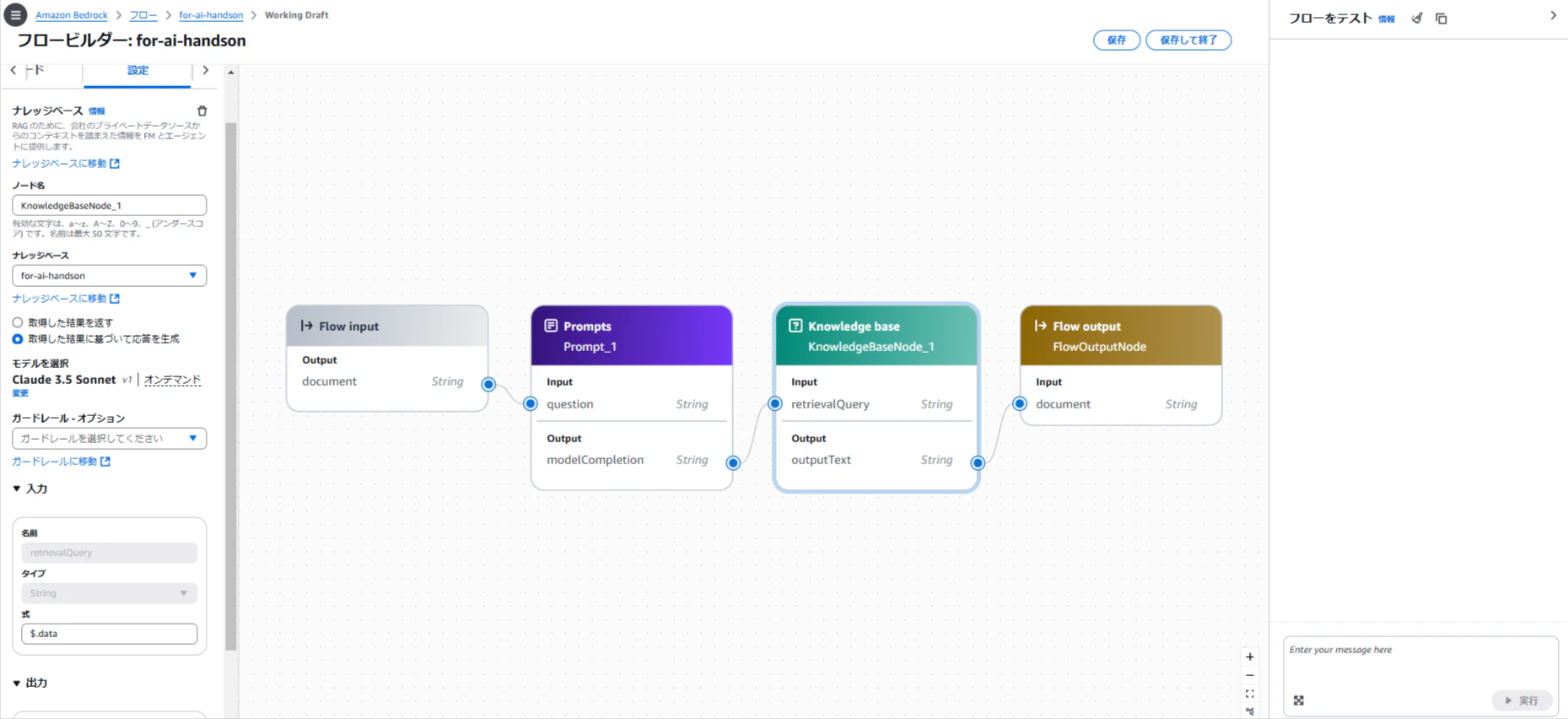
- フローを保存。
ステップ5: Bedrock Flowsのテスト
設定したサービスが正しく動作するか確認します。右端のテスト画面から、先ほど回答できなかった質問でテストします。
-
自然言語クエリ:
「高レベルの顧客によるトランザクションを日付順に表示してください。」 -
期待される回答:
t_id=1, amt=1200.50, dt_val=2023-01-10 t_id=4, amt=2000.00, dt_val=2023-04-05 t_id=5, amt=950.75, dt_val=2023-05-30 -
取得した回答:
顧客レベルが'H'(高)の顧客によるトランザクションは3件ありました。最も古いトランザクションは2023年1月10日にCorp Aが行った1,200.50の取引です。次に、同じくCorp Aが2023年4月5日に2,000.00の取引を行いました。最後に、Corp Dが2023年5月30日に950.75の取引を行いました。これらのトランザクションは日付順に並べられており、すべて高レベルの顧客によるものです。
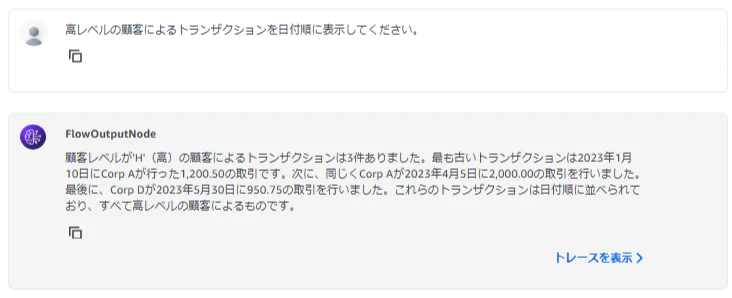
設計書データを活用することで、先ほど回答できなかった質問にも正確に回答できていることが確認できます。
まとめ
このハンズオンでは、Bedrock Flowsを使用してワークフローを定義し、設計書データからクエリを生成することで、複雑なテーブルデータに対しても自然言語でデータベースをクエリする仕組みを構築しました。
今回は設計書データをプロンプトに直接入力しましたが、S3 Retrievalノード を使用してS3から設計書を取得したり、ナレッジベースノード を用いてベクトル検索を行うことで、より大規模なデータにも対応できます。
また、個人的な感想ですがBedrock Flowsに変数を集約できるノードがあると嬉しいなと思いました。
参考にした情報