はじめに
今回はAWS上で実装できるRAGにおいて、回答精度を向上させる手法を調査、検証を行いました。
その際にたまったナレッジを共有いたします。
本記事では、①概要編として調査・検証した内容の概要を紹介いたします。
具体的な実装方法については②実装編として後日投稿予定です。
なお、本記事の内容は2月6日開催されたJr.Champions勉強会 -Top Engineers参観回で話した内容とほぼ同じなので、その際のスライドも共有します。
RAGとは何か?
RAGとは、LLMが外部のDBから情報を取得し回答を生成する仕組みのことで、
社内ナレッジに関する質問に回答できるAIチャットボットなどの用途として昨今注目されています。
RAGの回答生成までの流れ
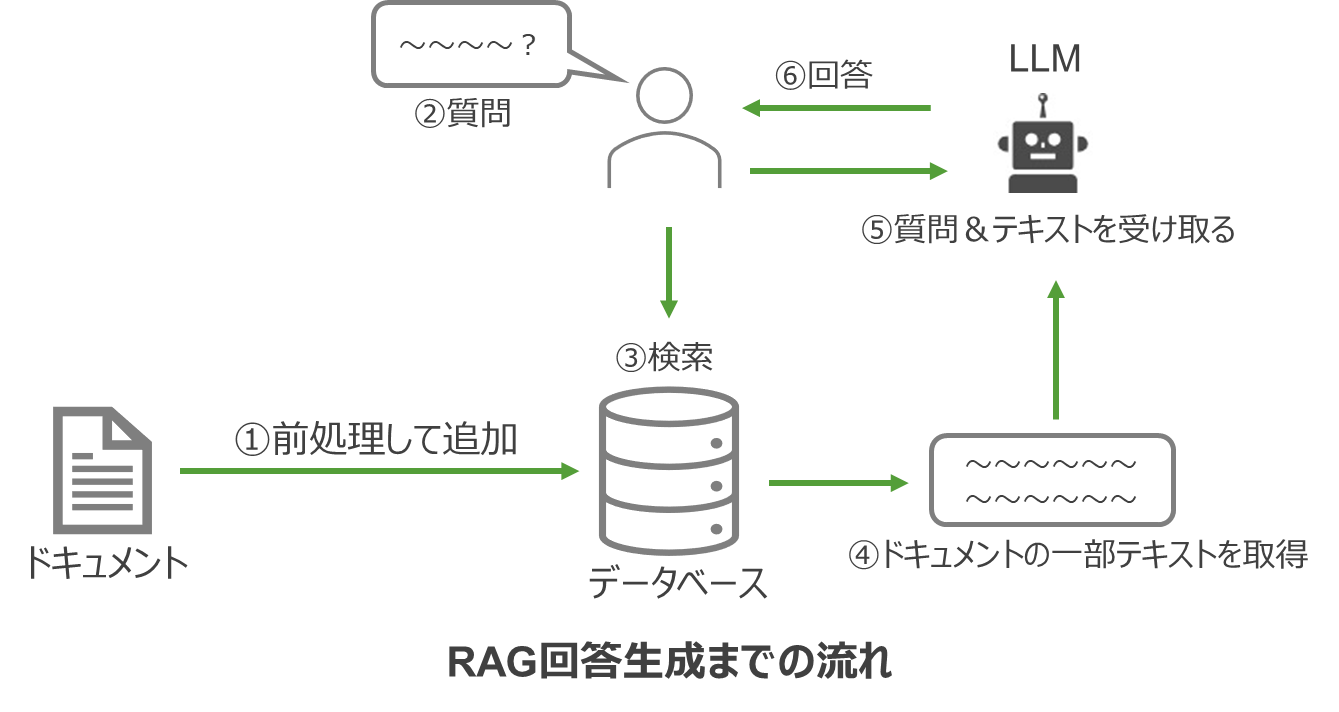
RAGによる回答生成の一般的な流れは以下の通りです:
①ドキュメントを前処理して追加
②ユーザーが質問
③質問内容を基に検索
④ドキュメントの一部を取得
⑤たドキュメントと質問をLLMに渡す
⑥回答生成
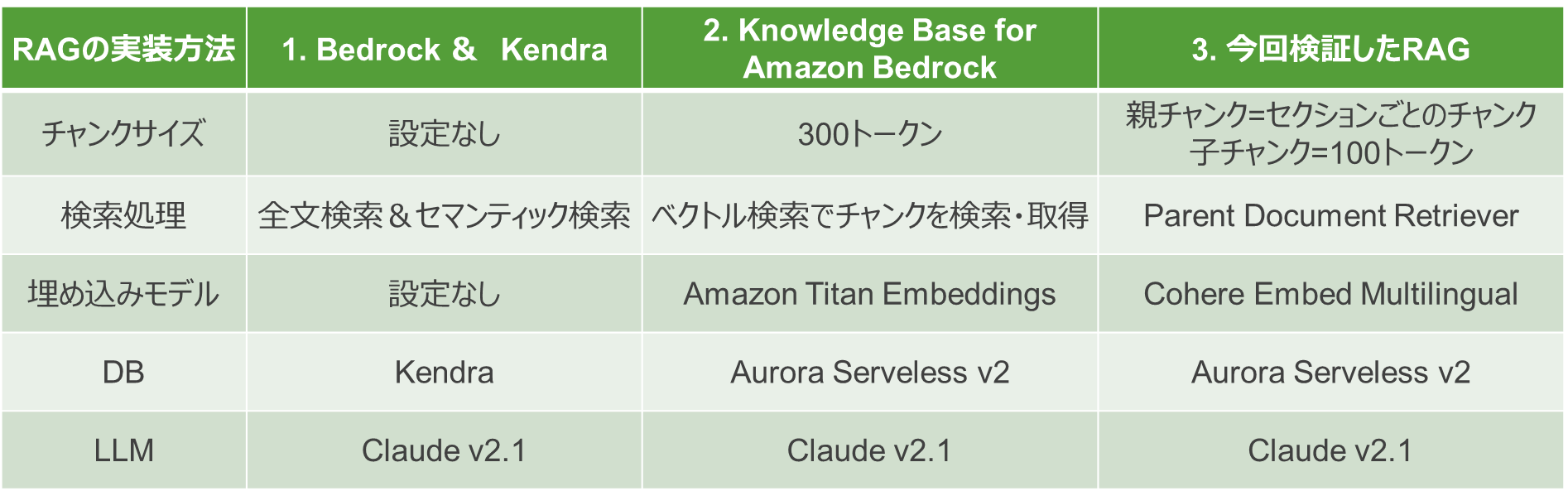
AWSでRAGを実装する方法3選
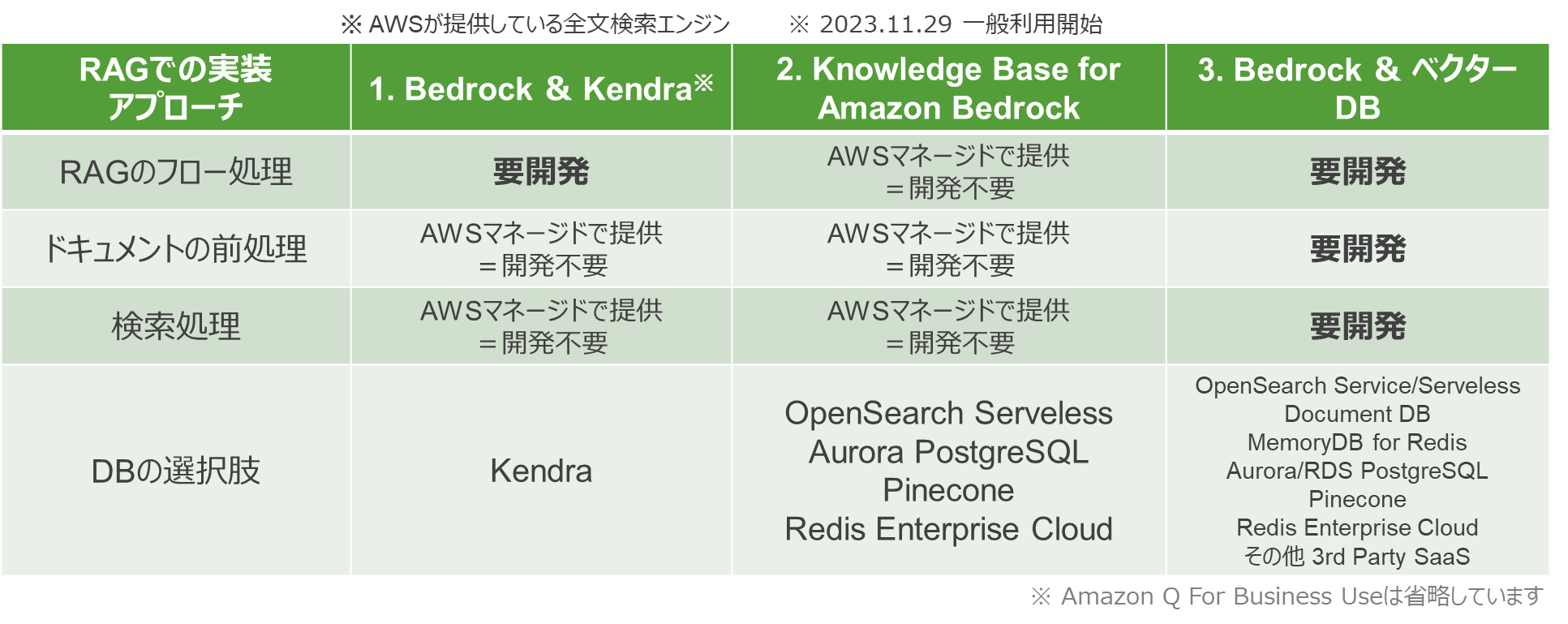
AWSはRAGを実装するための複数の方法を提供しています。
主要な3つのアプローチを紹介します。
1. Bedrock & Kendra
このアプローチは、RAGのフロー処理(質問から回答生成までの流れ)は開発が必要なもの、ドキュメントの前処理や検索処理はKendraの機能として提供しているため、開発の負担は軽減されています。
2. Knowledge Base for Amazon Bedrock
このアプローチでは、表の3処理(RAGのフロー処理、ドキュメントの前処理、検索処理)全てをAWSサービスの機能として提供してくれるため、開発は不要です。
また、DBの選択肢も豊富でOpenSearch Serveless、Aurora Serveless、Pinecone、Redis Enterprise Cloudと4種類のベクターDBから選択が可能です。
3. Bedrock & ベクターDB
このアプローチは表の3処理全て開発が必要 すが、自由にカスタムで実装できるというメリットがあります。
また、ベクターDBの選択肢も最も豊富です。
今回は3番目のBedrockとベクターDBを組み合わせる手法を選択し、それぞれの処理をカスタム実装することで、精度の向上に挑戦しました。
また、ベクターDBは、最小コストが低いためスモールスタートしやすく、管理がしやすいAurora Servelessを選択しました。
ベクターDBを用いたRAGの処理と実装方法
精度向上手法の説明の前に、ベクターDBを用いたRAGの処理の流れとその実装方法の少し具体的な説明を補足します。
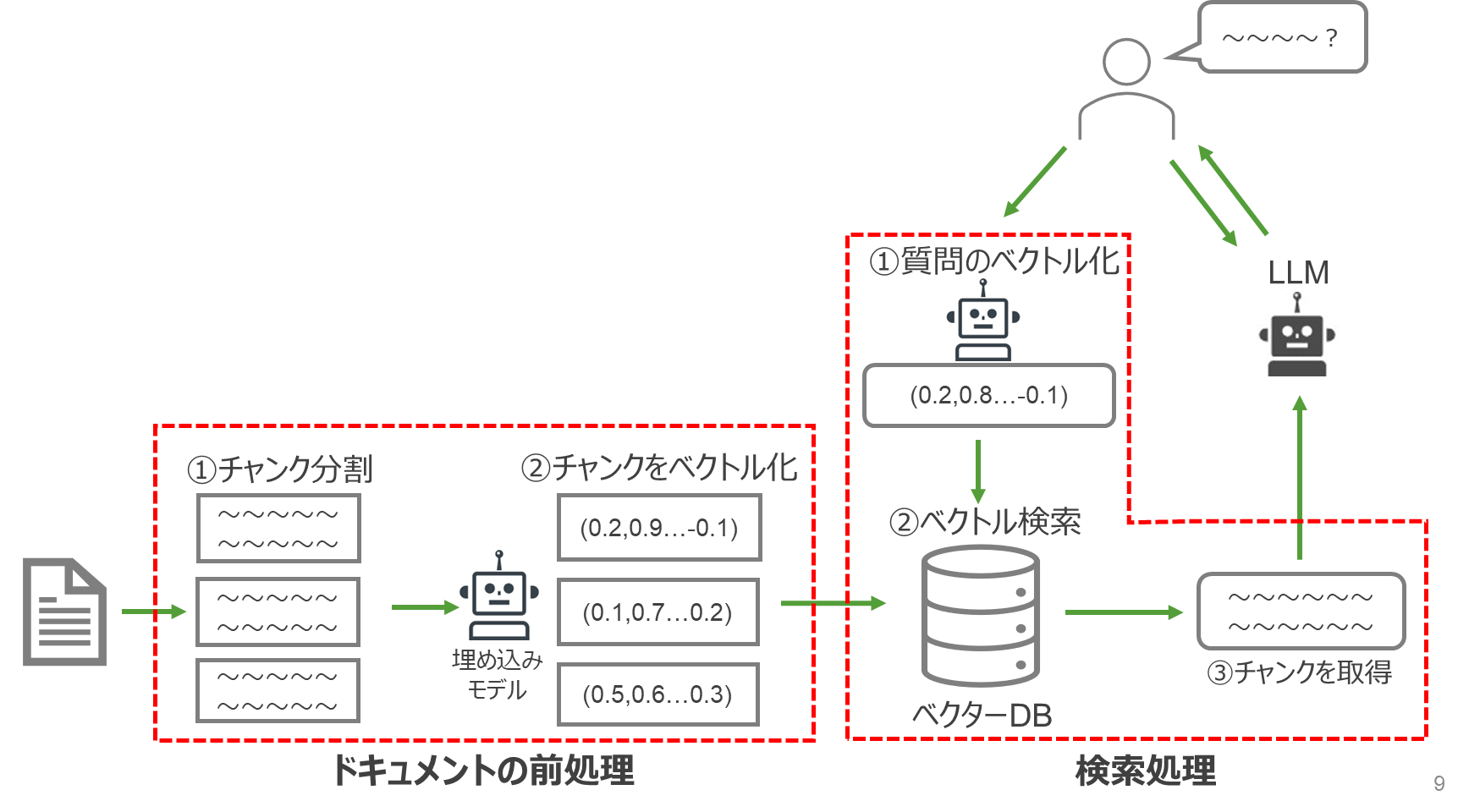
ベクターDBを用いた場合、ドキュメントはチャンクという単位で分割し、それぞれのチャンクを埋め込みモデルを用いてベクトル化します。質問内容も同様にベクトル化し、ベクトル検索を通じて関連するチャンクを取得します。

実装方法として、Knowledge Base for Amazon Bedrockは固定のチャンクサイズ、埋め込みモデルなどいくつか項目を設定するだけでRAGを構築できます。
Bedrock & ベクターDBではこれらの処理を自前で実装する必要があります。
検証した精度向上手法
今回の検証で構成したRAGの構成図です。
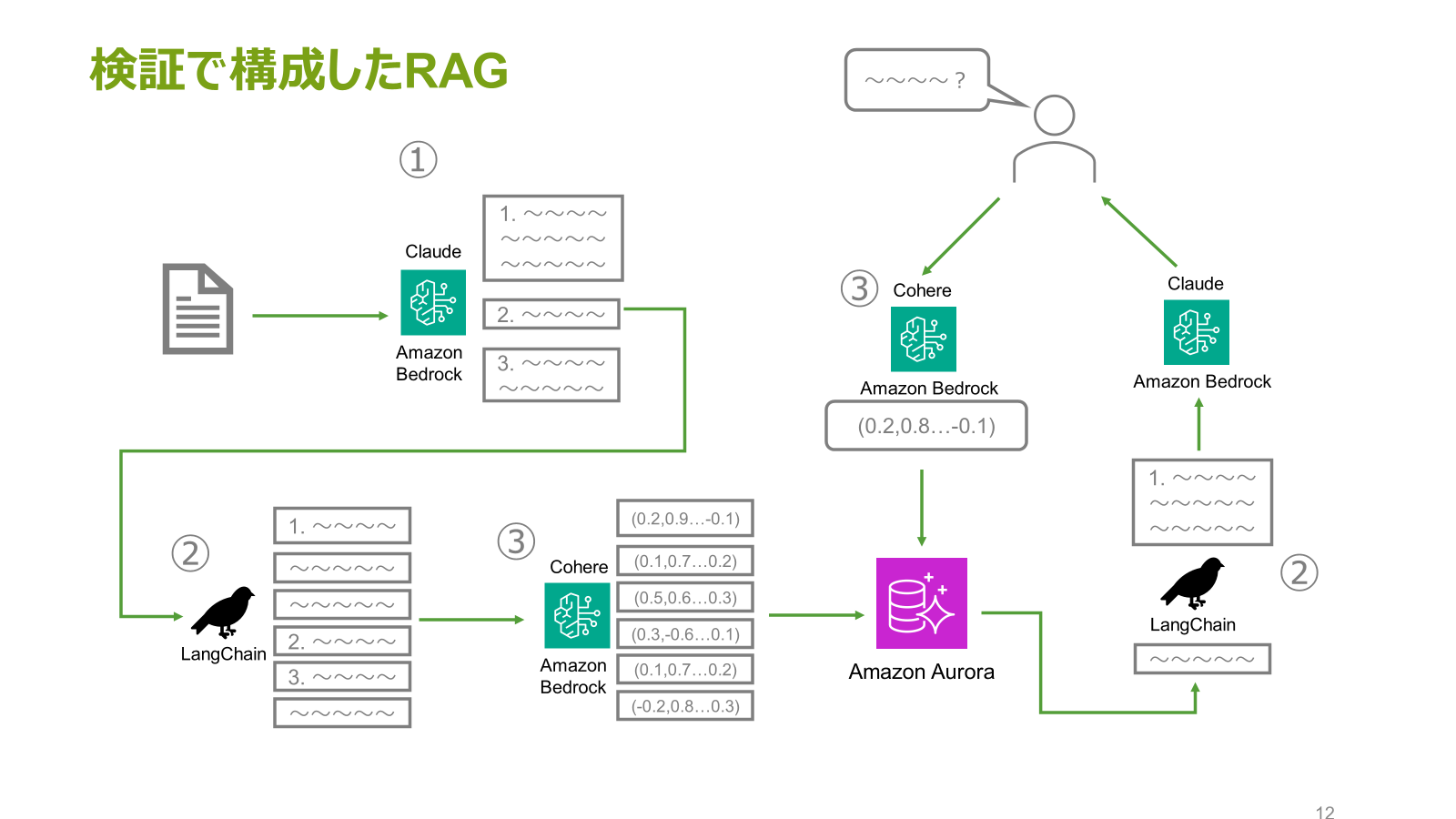
以下3つの精度手法を実施しました。
①Claudeによるチャンク分割
②LangChainの高度な検索機能
③高性能な埋め込みモデル
①Claudeによるチャンク分割
手法の説明の前にチャンク分割とRAGの回答精度への影響について話します。
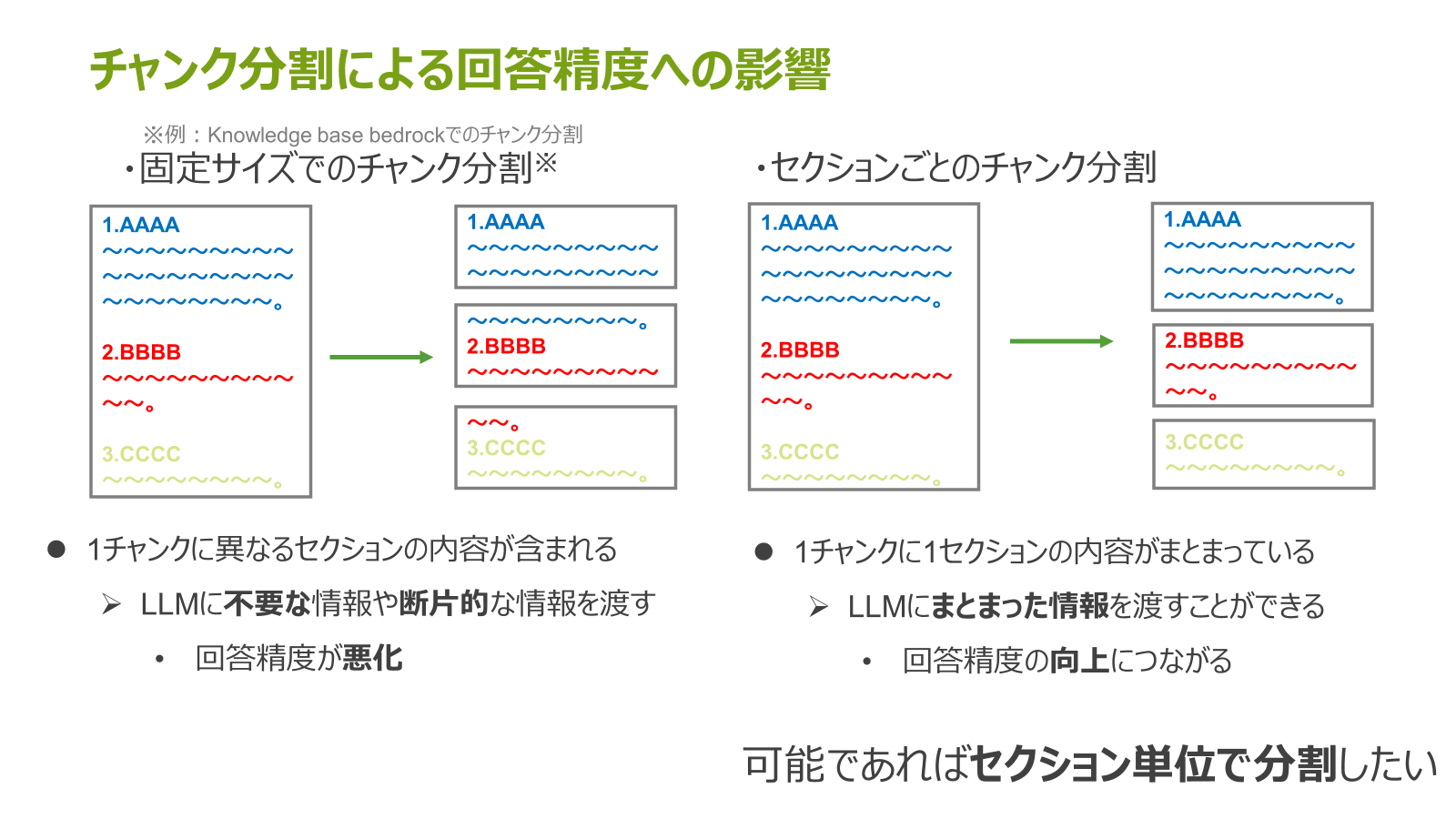
例えば、ドキュメントを固定サイズでチャンク分割する場合、1つのチャンクに異なるセクションの内容が含まれてしまい、回答精度が悪化してしまう可能性が考えられます。
もし、セクションごとにチャンク分割できれば、1チャンクに1セクションの内容がまとまっているため、回答精度の向上につなげることができます。
なので、ドキュメントはセクション単位でチャンク分割することが好ましいです。
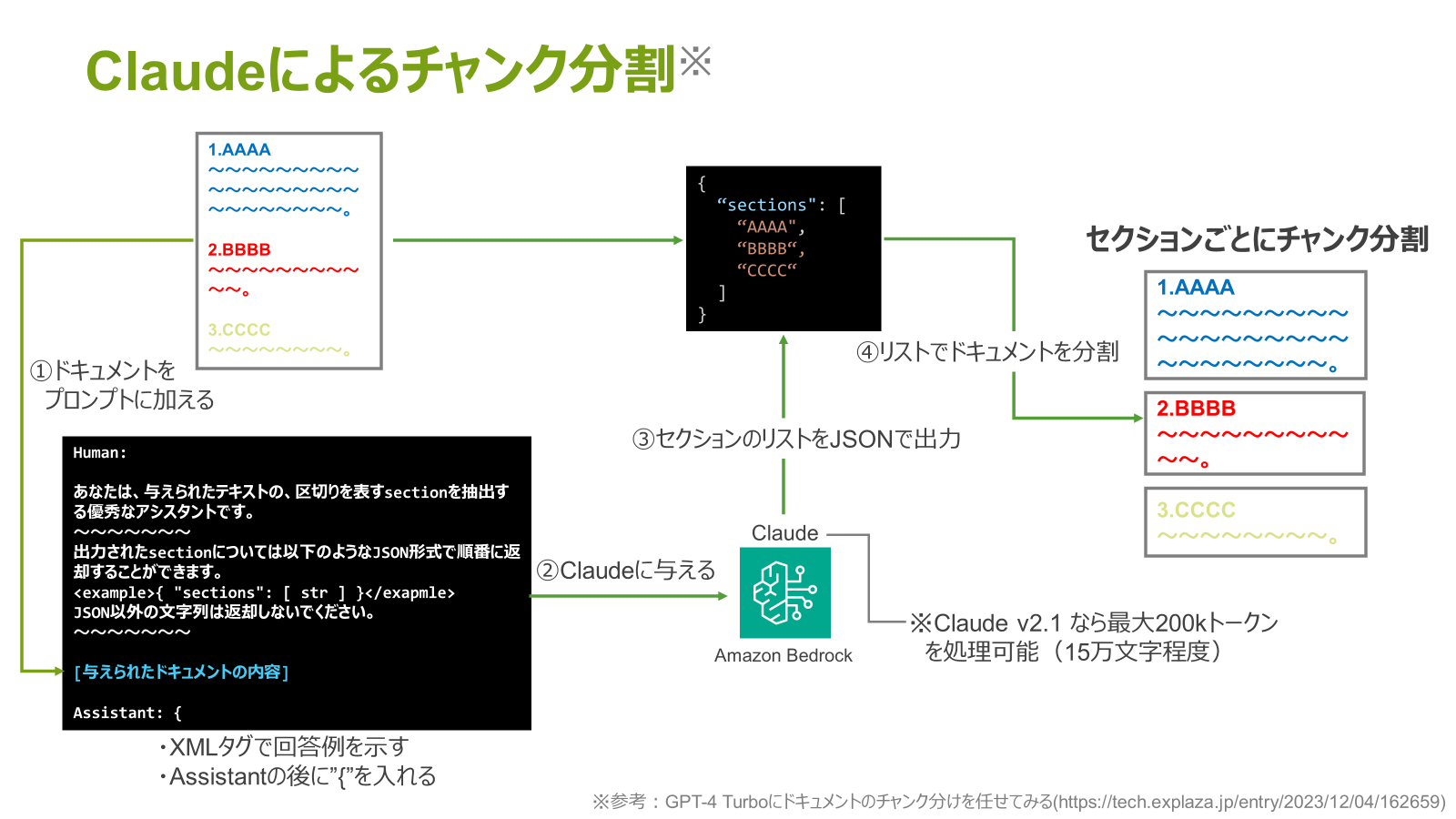
よって、セクションごとのチャンク分割するために、Claudeを用いたチャンク分割処理を実装しました。
分割処理では、まずドキュメント全体を含むプロンプトをClaudeに渡します。ここで、プロンプトには、セクション単位のJSONを出力するよう命令も追記します。
これにより、セクションのJSONリストを取得できるため、これを基に元のドキュメントを分割させます。
よって、セクションごとにチャンク分割させることができました。
②LangChainの高度な検索機能
手法の説明の前に、チャンクサイズとベクトル検索の精度の関係の説明をさせてください。
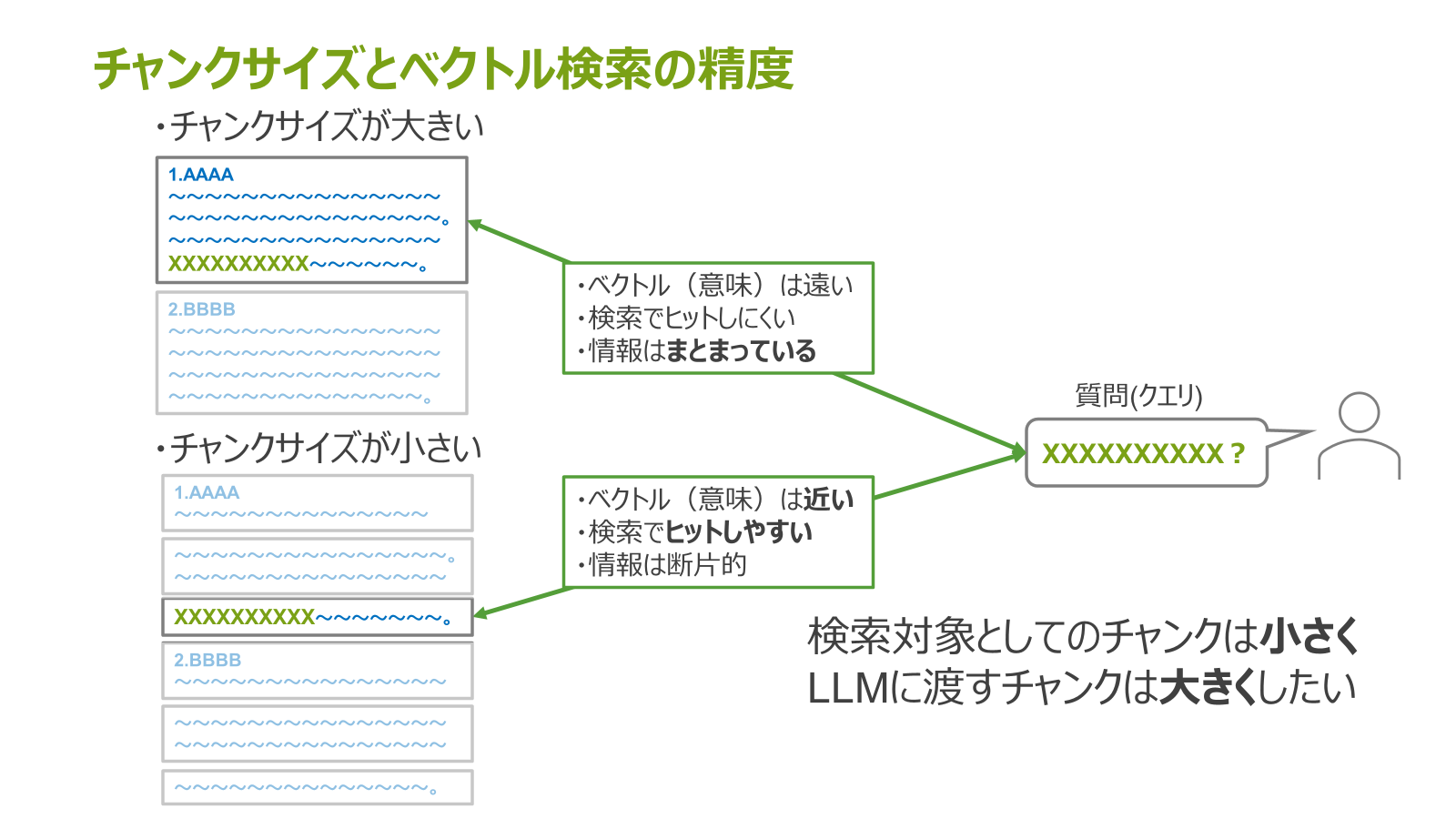
もし、あるクエリ(質問)と似た意味を持つチャンクが大きい(例:セクション単位のチャンク)場合、クエリとそのチャンク間のベクトルが遠くなる、つまり、ベクトル検索でヒットしにくくなってしまいます。
しかし、LLMに与えたいチャンクは、前述の通りセクションごとに意味がまとまっているのが好ましいです。
逆に、上記のチャンクをさらに細かくした場合、質問とそのチャンクのベクトル距離が近くなり、検索で見つけやすくなります。
しかし、チャンクを細かくしてしまうと、提供される情報が断片的になってしまいます。
このことから、検索対象としてのチャンクは小さく、LLMに渡すチャンクは大きくすることが好ましいです。
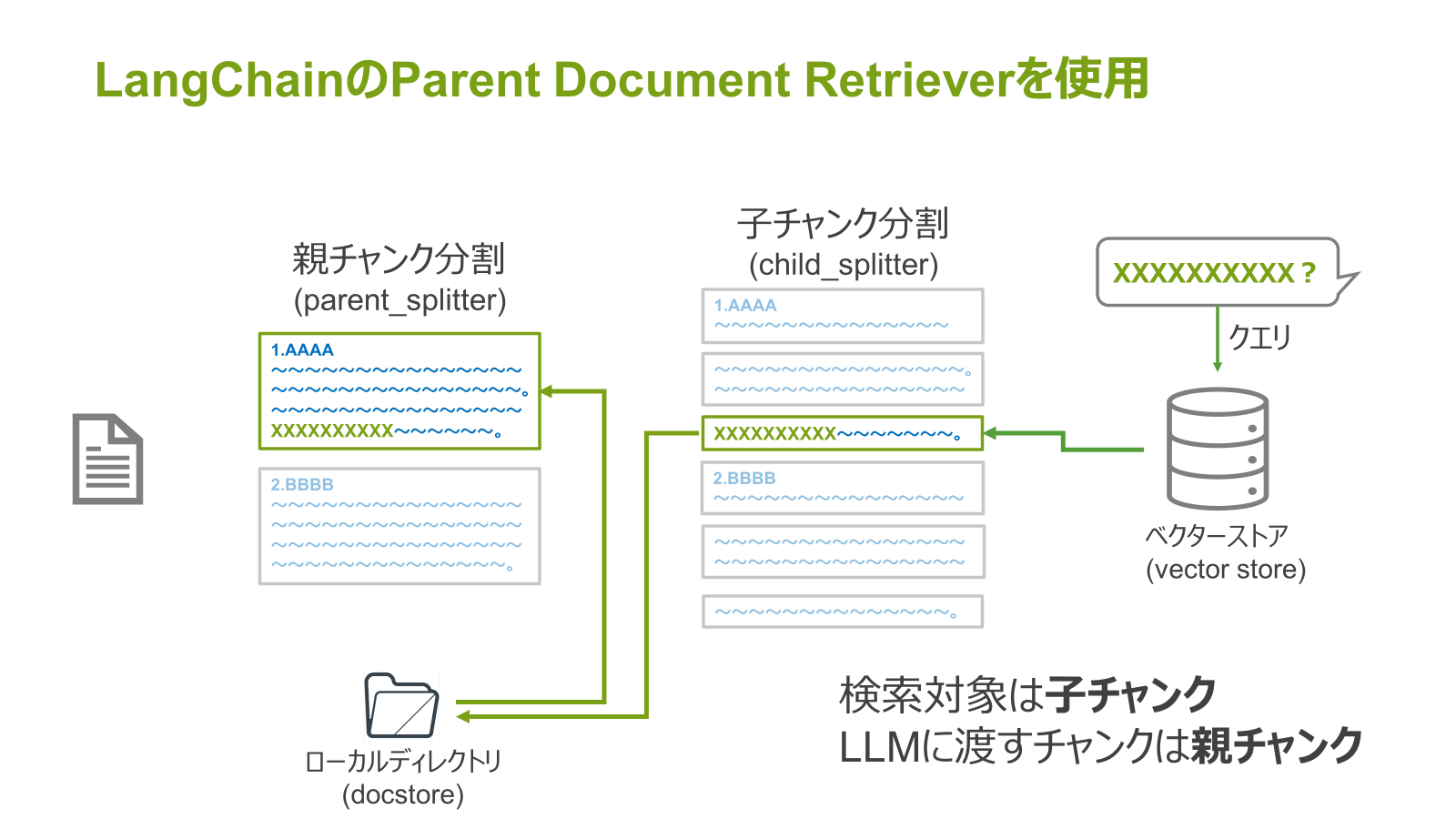
これを実現してくれるのがLangChainのParent Document Retrieverです。
Parent Document Retrieverはドキュメントを2段階で分割します。まず1段階目は親チャンク、2段階目はそれをさらに分割した子チャンクとします。
そして、親チャンクとそのIDをローカルディレクトリに、子チャンクとそれの元の親チャンクのIDをベクターストアに保存します。
そして、そのベクターストアに対してクエリを行うと、検索対象を子チャンクにしつつ、さそこからさらに紐づく親チャンクを取得することができます。
③高性能な埋め込みモデル

埋め込みモデルは、Amazon Bedrockで利用可能なCohere Embed Multilingualを採用しました。
理由は単純で、埋め込みモデルのベンチマークであるMTEBの評価が高いためです。
他のモデルとの比較すると、Amazon Titan Embeddingsや、text-embedding-ada-002よりベンチマークの数値が高いこと分かります。
この埋め込みモデルの特徴として、一度に埋め込みできる最大サイズが512トークンと小さめです。
しかしながらParent Document Retrieverと組み合わせることで、埋め込むチャンクが小さくても、大きなチャンクをLLMに渡すことができ、両者の弱点を補う構成にすることができました。
検証したRAGの評価について
今回検証したRAGの評価方法ですが、Databricks社の記事を参考にアレンジを加えました。
回答の正しさ、包括性(必要な情報を網羅しているか)、読みやすさを評価項目とし、それぞれに重みづけ(正しさ60% 、包括性20% 、読みやすさ20% )をして、総合評価点を算出しました。
評価のための比較として、冒頭に紹介した3つのRAGの回答精度を比較しました。
評価に用いたドキュメント
Amazon Bedrockユーザーガイドにおけるページの一部を使用しました。
評価に用いたドキュメントは2024年1月23日時点のものです。現在は更新され内容が変更されています。
RAGへの質問
公式HPのFAQやドキュメントから質問を以下8つ用意しました。
Q1. Amazon Bedrock ではどの モデルが利用できますか?
Q2. Amazon Bedrockにおいてプロヴィジョニングされたスループットで利用できるモデルを教えてください。
Q3. Amazon Bedrockではどのような機能を利用することが出来ますか?
Q4. Amazon Bedrock の使用を開始するにはどうすればよいですか?
Q5. Amazon Bedrock Chat Playground とは何ですか?
Q6. Amazon Bedrock はどの AWS リージョンで利用できますか?
Q7. Amazon Bedrock の料金体系について教えてください
Q8. Amazon Bedrockへのアクセス権を付与するにはどのような方法がありますか?
評価結果

結果として、今回検証したRAGが点満点のうち平均2.98点と、最も点数が高くなりました。
Knowledge Base for Amazon Bedrockに関してはドキュメントと関連しない回答が2つありました。
Bedrock & Kendraは包括性が低い回答が見受けられました。
苦戦したこと
今回の検証で苦戦したことを紹介します。

ClaudeからセクションJSONを出力させる処理に大苦戦しました。
苦戦した理由を3つ紹介します。
1つめ、LangChainでBedrockのClaudeを呼び出そうとしたところ、JSONが途中で途切れてしまうケースが頻出したことに苦戦しました。
よって、こちらはboto3を使用してClaudeは呼び出しました。
2つめ、Claude v2.1からセクションJSONを出力させると、JSONの後に余計な文章(例えば「依頼通りセクションJSONを出力しました。」)が付いてしまうことに苦戦しました。
こちらは、Claude instant v1を使用した場合、確実にJSONのみを出力ささせることができました。
しかし、セクションの抽出精度ではClaude v2.1が優れていたため、生成された回答からJSONを抜き出す処理を追加しました。
3つめ、「Amazon Bedrockユーザーガイド」の特定のページからはセクションを正確に抽出できないという問題に苦戦しました。
調べてみた結果、このドキュメントには “\n\nHuman: \n\nAssistant:”という文字列が多く含まれているため、Claudeが混乱してしまい適切に動作しないことが原因であることが判明しました。
よって、今回の検証ではドキュメントのうち一部のページのみを使用しました。
まとめ
今回検証した手法でRAGの精度を向上できました。改善手法としては以下の通りです。
①Claudeによるチャンク分割
②Langchainのparentdocumentretriever
③埋め込みモデルにcohere embed multinguals
みなさんもぜひ検証してください。
参考文献