はじめに
今年AWS re:Invent 2024が2024年12月2日~12月6日の間ラスベガスで開催されました!
そこで、AWSの全文検索サービスであるAmazon Kendraに、RAG特化機能である「Amazon Kendra GenAI Index」が発表されました!

また、本サービスはAWSのRAG機能である「Amazon Bedrock Knowledge Bases」と統合しています。
今まで、RAGをAWSで構築する際は、Amazon Bedrock Knowledge Basesとvector store(例:OpenSearch Serverless)用いては、チャンク分割戦略や埋め込みモデル、リランクモデルは自分で最適なものを設定する必要がありました。
一方で、今回発表された「Amazon Kendra GenAI Index」は、ハイブリッド検索(ベクトル+キーワード検索)や事前最適化されたモデルをマネージドな形で提供し、設定を簡略化しつつ高精度なRAGを実現します。
本記事では、
- 「Amazon Bedrock Knowledge Bases with vector store(ほぼデフォルト構成)」
- 「Amazon Bedrock Knowledge Bases with Kendra GenAI Index」
- 「Advancedオプションを有効化したAmazon Bedrock Knowledge Bases with vector store(Advanced parsingやchunking、query reformulationを活用した構成)」
これら3つのパターンを比較し、RAGの回答精度を評価します。
比較には、Amazon Bedrockの新機能である「Knowledge Base evaluations」を使用しました。
また、Advancedオプションとしては、Amazon Bedrock Knowledge Basesが提供する「Advanced parsing」「Advanced chunking(Semantic/Hierarchical chunking)」などの機能を活用して、さらに精度を高められるか検証します。
これにより、どちらを選ぶべきか、あるいはどのようなオプションを有効化すべきかを判断する際の参考になれば幸いです。
Amazon Bedrock Knowledge Bases with vector store(ほぼデフォルト構成)
ナレッジベースの構築方法
リージョンはバージニア北部を選択します。
Amazon Bedrockのサービスページの左側メニューの「オーケストレーション」から「ナレッジベース」を選択し、「ナレッジベースを作成」を選択します。
すると、以前にはなかった選択肢が現れるため、「Knowledge Base with vector store」を選択します。
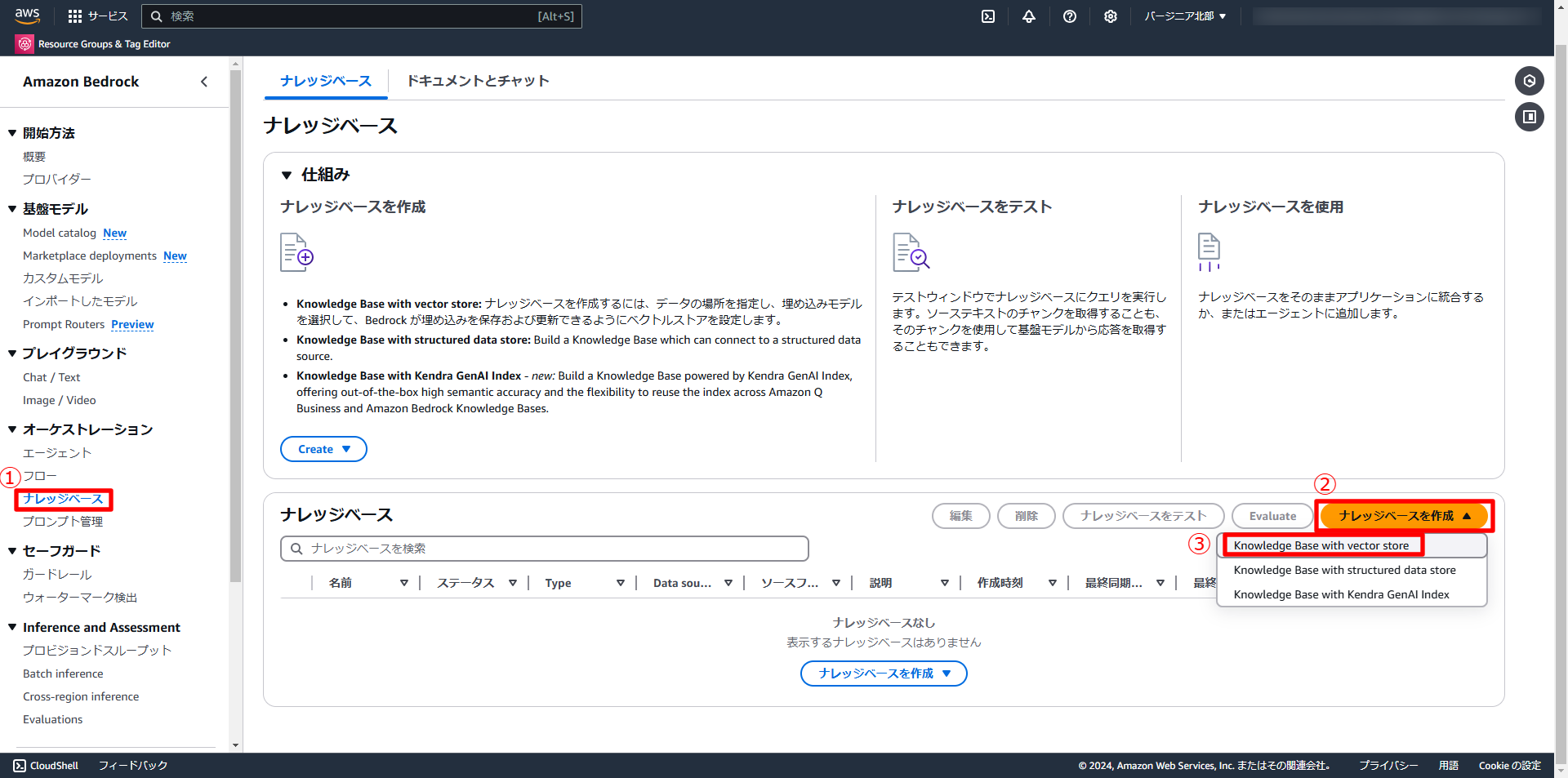
そして、データソースを「S3」にし、事前に作成しておいたS3バケットを選択します。埋め込みモデルをTitan Text Embeddings v2に選択し、ベクトルストアをAmazon OpenSearch Serverlessにし、それ以外の設定は全てデフォルトに設定して作成します。
データ同期手順
今回のRAGにはAmazon Bedrockの公式ドキュメント(2463ページ)を読み込ませてみます。
先ほどのナレッジベース作成時に選択してあった、あらかじめ作成しておいたS3バケットにドキュメントをアップロードします。
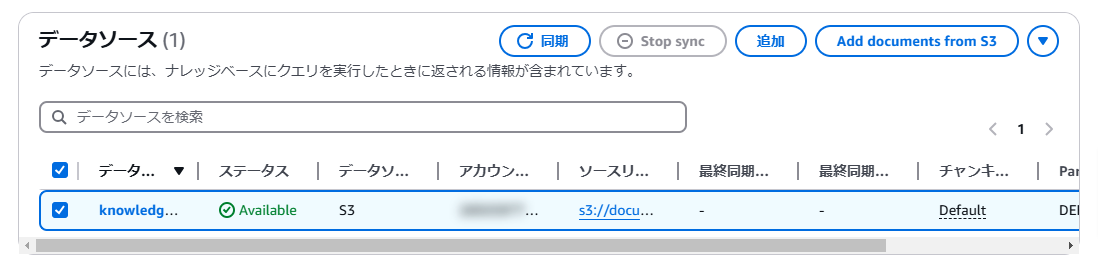
その後、作成したナレッジベースの「データソース」からデータソースを選択し「同期」を選択します。
回答精度評価手順
評価するためのデータセットを作成します。
読み込ませたbedrockのドキュメントからAmazon Bedrock Knowledge Basesに関するデータセットを51問作成しました。
データセット
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Amazon Bedrock Knowledge Basesは、Retrieval Augmented Generation (RAG)技術を使用して、プロプライエタリな情報をジェネレーティブAIアプリケーションに統合することができます。"}]}],"prompt":{"content":[{"text":"Amazon Bedrock Knowledge Basesの主な機能は何ですか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"RAGは検索結果を使用して基礎モデルの応答を強化する技術で、クエリに対してより関連性の高い正確な応答を生成します。"}]}],"prompt":{"content":[{"text":"RAG(Retrieval Augmented Generation)とは何ですか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Amazon OpenSearch Serverless、Amazon Neptune、Amazon Aurora (RDS)、Pinecone、Redis Enterprise Cloud、MongoDB Atlasがサポートされています。"}]}],"prompt":{"content":[{"text":"Amazon Bedrock Knowledge Basesでサポートされているベクトルストアを教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"サポートされているファイル形式は、プレーンテキスト(.txt)、Markdown(.md)、HTML(.html)、Microsoft Word(.doc/.docx)、CSV(.csv)、Excel(.xls/.xlsx)、PDF(.pdf)、画像ファイル(JPEG/.jpeg、PNG/.png)です。"}]}],"prompt":{"content":[{"text":"Knowledge Basesでサポートされているファイル形式を教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Amazon S3、Confluence、Microsoft SharePoint、Salesforce、Webクローラー、カスタムデータソースがサポートされています。"}]}],"prompt":{"content":[{"text":"Knowledge Basesで接続可能なデータソースの種類を教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Retrieve APIは関連情報のみを返し、RetrieveAndGenerate APIは検索結果に基づいて自然言語の応答を生成します。"}]}],"prompt":{"content":[{"text":"RetrieveとRetrieveAndGenerate APIの違いは何ですか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"チャンキングには、固定サイズ、デフォルト、階層的、セマンティックの4つのオプションがあります。"}]}],"prompt":{"content":[{"text":"Knowledge Basesで利用可能なチャンキング戦略を教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"パーサーオプションには、Amazon Bedrock デフォルトパーサー、Amazon Bedrock Data Automation、基礎モデルがあります。"}]}],"prompt":{"content":[{"text":"Knowledge Basesのパーシングオプションを教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"検索タイプには、デフォルト、ハイブリッド(ベクトル検索とテキスト検索の組み合わせ)、セマンティック(ベクトル検索のみ)があります。"}]}],"prompt":{"content":[{"text":"Knowledge Basesの検索タイプの種類を教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"AWS GovCloud (US-West)を含む、US East、US West、Asia Pacific、Canada、Europe、South Americaの複数のリージョンでサポートされています。"}]}],"prompt":{"content":[{"text":"Knowledge Basesはどのリージョンでサポートされていますか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Amazon Titan Embeddings G1 - Text、Amazon Titan Text Embeddings V2、Cohere Embed (English)、Cohere Embed (Multilingual)が利用可能です。"}]}],"prompt":{"content":[{"text":"Knowledge Basesでサポートされている埋め込みモデルを教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"クエリ分解は、複雑なクエリをより管理しやすい小さなサブクエリに分解する技術で、より正確で関連性の高い情報を取得するのに役立ちます。"}]}],"prompt":{"content":[{"text":"クエリ分解(Query decomposition)とは何ですか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"メタデータフィルタリングでは、equals、not equals、greater than、less than、starts with、inなどの演算子を使用して検索結果をフィルタリングできます。"}]}],"prompt":{"content":[{"text":"Knowledge Basesのメタデータフィルタリングではどのような演算子が利用できますか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"GraphRAGは、ドキュメント間の関係性や構造的要素を自動的に識別して使用し、複数のドキュメントチャンク間での推論が必要な場合により関連性の高い応答を提供します。"}]}],"prompt":{"content":[{"text":"GraphRAGの機能と利点を説明してください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"カスタムデータソースの利点は、データ型の柔軟性、KnowledgeBaseDocuments APIによる直接的なドキュメント管理、コンソールでのドキュメント表示、メタデータの直接追加が可能なことです。"}]}],"prompt":{"content":[{"text":"カスタムデータソースを使用する利点は何ですか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"暗号化のオプションには、デフォルトのAWS管理キーの使用、または独自のKMSキーによるトランジェントデータの暗号化があります。"}]}],"prompt":{"content":[{"text":"Knowledge Basesでどのような暗号化オプションが利用できますか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"プロンプトテンプレートでは、$query$、$search_results$、$output_format_instructions$、$current_time$などのプレースホルダーを使用できます。"}]}],"prompt":{"content":[{"text":"Knowledge Basesのプロンプトテンプレートで使用できるプレースホルダーを教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"インクリメンタル同期により、前回の同期以降に追加、変更、または削除されたドキュメントのみが処理されます。"}]}],"prompt":{"content":[{"text":"Knowledge Basesのインクリメンタル同期とは何ですか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Amazonk Bedrock Knowledge BasesはAmazon Kendra GenAI indexと統合して、より高度な情報検索と生成AI機能を組み合わせることができます。"}]}],"prompt":{"content":[{"text":"Knowledge BasesとAmazon Kendra GenAI indexの統合について説明してください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"各ファイルサイズは50 MB以下、JPEG/PNGファイルは3.75 MB以下である必要があります。"}]}],"prompt":{"content":[{"text":"Knowledge Basesのファイルサイズ制限を教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Lambda関数を使用して、チャンキングロジックのカスタマイズ、チャンクレベルのメタデータの指定が可能です。"}]}],"prompt":{"content":[{"text":"Knowledge Basesでカスタム変換Lambda関数はどのように使用できますか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"CSV形式のデータを使用する場合、content_fieldsとmetadata_fieldsを指定することで、特定の列をコンテンツまたはメタデータとして扱うことができます。"}]}],"prompt":{"content":[{"text":"Knowledge BasesでCSVファイルのデータをどのように構造化できますか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"固定サイズチャンキングでは、トークン数とオーバーラップの割合を指定して、均一なサイズのチャンクを作成できます。"}]}],"prompt":{"content":[{"text":"固定サイズチャンキングの設定方法を説明してください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"階層的チャンキングでは、親チャンクと子チャンクの2レベルの構造を作成し、それぞれのチャンクサイズとオーバーラップトークン数を指定できます。"}]}],"prompt":{"content":[{"text":"階層的チャンキングの仕組みを説明してください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"セマンティックチャンキングでは、最大トークン数、バッファサイズ、ブレークポイントパーセンタイル閾値を設定して、意味に基づいたチャンク分割を行います。"}]}],"prompt":{"content":[{"text":"セマンティックチャンキングのパラメータについて説明してください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Amazon S3バケットは同じリージョンにある必要があり、現在はGeneral Purpose S3バケットのみがサポートされています。"}]}],"prompt":{"content":[{"text":"Knowledge BasesでのS3バケットの要件は何ですか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Confluenceデータソースでは、スペース、ページ、ブログ、コメント、添付ファイルに対してインクルージョン/エクスクルージョンフィルターを適用できます。"}]}],"prompt":{"content":[{"text":"Confluenceデータソースでのフィルタリングオプションを説明してください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"SharePointデータソースでは、ページ、イベント、ファイルに対してフィルタリングを適用でき、OneNoteドキュメントは現在サポートされていません。"}]}],"prompt":{"content":[{"text":"SharePointデータソースの制限事項は何ですか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Salesforceデータソースでは、アカウント、キャンペーン、商談、リード、ケースなど、様々なSalesforceオブジェクトタイプに対してフィルタリングが可能です。"}]}],"prompt":{"content":[{"text":"Salesforceデータソースでフィルタリングできるオブジェクトタイプを教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"ドメインレンジオプションとしてDefault(同一ホストと初期URLパス)、Host only(同一ホスト)、Subdomains(同一プライマリドメイン)が選択できます。"}]}],"prompt":{"content":[{"text":"Webクローラーのドメインレンジオプションについて説明してください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Amazon OpenSearch Serverlessのベクターインデックスでは、faissエンジンを使用し、ベクトルフィールド、テキストフィールド、メタデータフィールドを設定する必要があります。"}]}],"prompt":{"content":[{"text":"Amazon OpenSearch Serverlessのベクターインデックス設定について説明してください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Amazon Auroraテーブルには、id(UUID主キー)、embedding(ベクトル)、chunks(テキスト)、metadata(JSON)の列が必要です。"}]}],"prompt":{"content":[{"text":"Amazon Auroraテーブルに必要な列構成を教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Mongodbでは、エンドポイントURL、データベース名、コレクション名、認証情報のシークレットARN、フィールドマッピングを設定する必要があります。"}]}],"prompt":{"content":[{"text":"MongoDB Atlasの設定に必要な情報は何ですか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"知識ベースの作成後、ドキュメントの追加/変更/削除を行った場合は同期を実行して再インデックスする必要があります。同期は増分的に行われます。"}]}],"prompt":{"content":[{"text":"知識ベースの同期プロセスについて説明してください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"temperature、topP、maxTokenCount、stopSequencesなどのパラメータを使用して、応答生成時のモデルの動作を制御できます。"}]}],"prompt":{"content":[{"text":"推論パラメータでカスタマイズ可能な設定を教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"AWS KMSキーを使用して知識ベースを暗号化したり、トランジェントデータストレージの暗号化を設定したりできます。"}]}],"prompt":{"content":[{"text":"Knowledge Basesで利用可能な暗号化オプションの詳細を教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"データ削除ポリシーでは、DELETE(知識ベース削除時にベクターデータを削除)またはRETAIN(ベクターデータを保持)を選択できます。"}]}],"prompt":{"content":[{"text":"データ削除ポリシーのオプションについて説明してください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"IAM認証、データベースユーザー認証、AWS Secrets Manager認証の3つの認証方法がサポートされています。"}]}],"prompt":{"content":[{"text":"Amazon Redshift接続時の認証オプションを教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"AWS Glue Data Catalogを使用する場合、テーブル名はawsdatacatalog.gluedatabase.tableの形式で指定する必要があります。"}]}],"prompt":{"content":[{"text":"AWS Glue Data Catalogのテーブル名の指定方法を教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"メタデータ属性には、STRING、NUMBER、BOOLEAN、STRING_LISTの4つのデータ型を使用できます。"}]}],"prompt":{"content":[{"text":"メタデータ属性でサポートされているデータ型を教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"生成されたSQL文の形式や正確性は、コンテキスト、テーブルスキーマ、ユーザークエリの意図によって異なる場合があります。"}]}],"prompt":{"content":[{"text":"GenerateQueryAPIの注意点を教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"robots.txtのディレクティブに従い、デフォルトではrobots.txtが見つからないウェブサイトはクロールを拒否します。"}]}],"prompt":{"content":[{"text":"Webクローラーのrobots.txt処理について説明してください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"APIリクエストには1秒あたり2リクエストの制限があります。"}]}],"prompt":{"content":[{"text":"GenerateQuery APIのクォータ制限は何ですか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"Retrieve操作とRetrieveAndGenerate操作の両方で、デフォルトのAmazon Bedrock Knowledge Basesランカーの代わりにリランキングモデルを使用できます。"}]}],"prompt":{"content":[{"text":"リランキング機能はどのように使用できますか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"インプリシットメタデータフィルタリングは、現在Anthropic Claude 3.5 Sonnetでのみ動作します。"}]}],"prompt":{"content":[{"text":"インプリシットメタデータフィルタリングの制限事項は何ですか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"クエリ分解を使用する場合、numberOfRerankedResultsはnumberOfResultsの最大5倍まで設定できます。"}]}],"prompt":{"content":[{"text":"クエリ分解使用時のリランキング結果数の制限を教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"プレビュー期間中、GraphRAGはAmazon S3のみをデータソースとしてサポートしています。"}]}],"prompt":{"content":[{"text":"GraphRAGの現在のデータソース制限は何ですか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"生成されたSQL文を実行するとセキュリティリスクが生じる可能性があるため、制限付きロール、読み取り専用データベース、サンドボックス化などの対策が推奨されます。"}]}],"prompt":{"content":[{"text":"構造化データストアを使用する際のセキュリティ上の推奨事項は何ですか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"StartIngestionJob APIを使用するか、コンソールでSyncを選択することでデータソースの同期を開始できます。"}]}],"prompt":{"content":[{"text":"データソースの同期を開始する方法を教えてください。"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"知識ベースのテストでは、生成応答のオン/オフ切り替え、検索タイプの設定、フィルターの追加、プロンプトテンプレートのカスタマイズが可能です。"}]}],"prompt":{"content":[{"text":"知識ベースのテスト機能ではどのような設定が可能ですか?"}]}}]}
{"conversationTurns":[{"referenceResponses":[{"content":[{"text":"AWS Lake Formationを通じてデータベースとテーブルに対するDescribeとSelect権限を付与する必要があります。"}]}],"prompt":{"content":[{"text":"AWS Glue Data Catalogを使用する際に必要な権限設定を教えてください。"}]}}]}
そして、をAmazon Bedrockコンソールの左メニュー「Evaluations」→「Knowledge Bases」から「Create」を選択します。
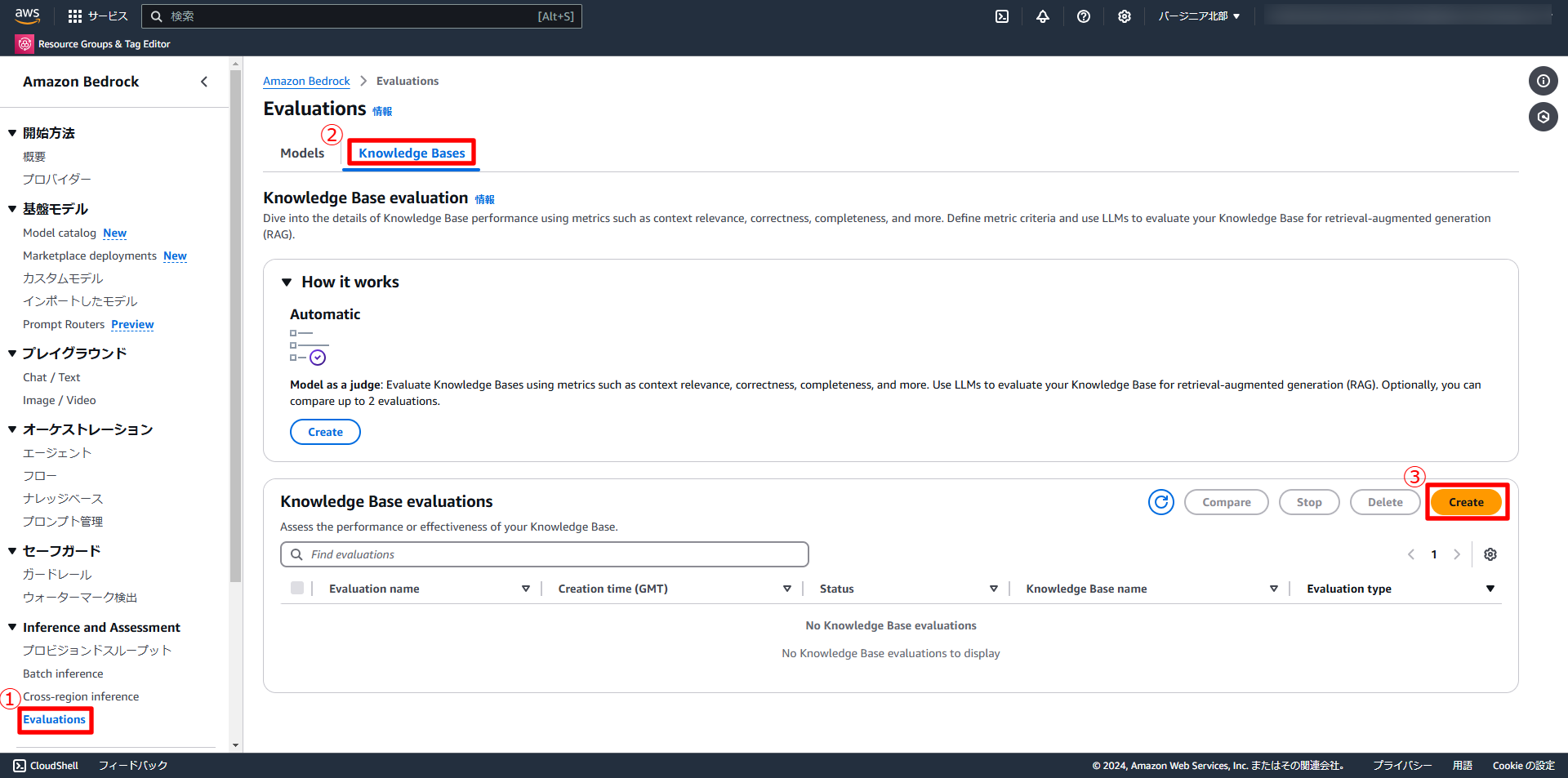
Evaluation modelを「Claude 3.5 Sonnet」を選択し、「Knowledge Base details」の「Choose a Knowledge Base」を先ほどのOpenSearch Serverlessナレッジベースに指定し、「Knowledge Base evaluation type」を「Retrieval only」に選択します。
Response generator modelを「Claude 3 haiku」に選択します。
「Metrics」はQualityの全てを選択、「Dataset for evaluation」にデータセットJSONLファイルを配置したS3のURIを入力、「Results for evaluation」に作成後のレポートファイルを配置するS3 URIを指定します。
上記のS3バケットにはCORS設定が必要なため、公式ドキュメントを参照してください。
https://docs.aws.amazon.com/bedrock/latest/userguide/model-evaluation-security-cors.html
「Service access」では「Create and use a new service role」を選択しロールを作成、
最後に「作成」を選択します。
しばらく待つと評価レポートが作成されます。
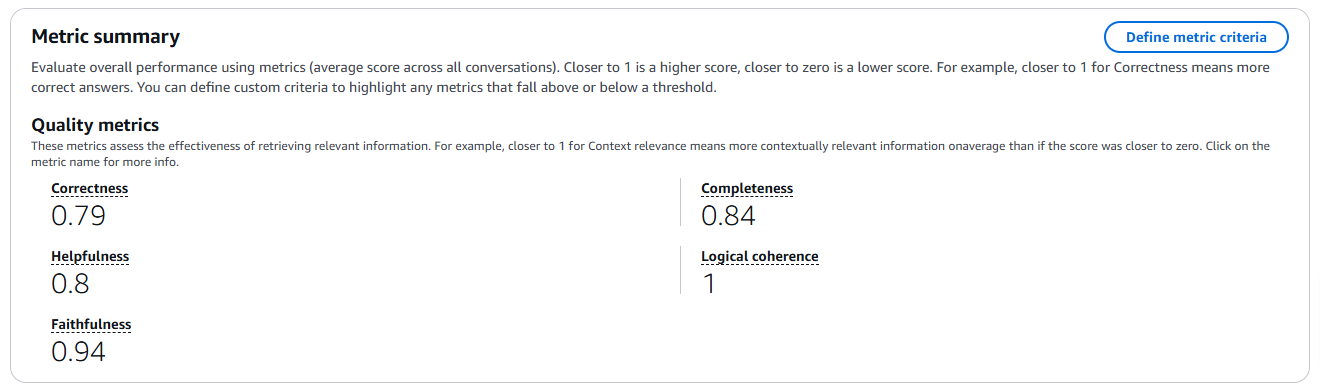
評価結果
| 指標 | スコア |
|---|---|
| Correctness(正確さ) | 0.79 |
| Completeness(完全性) | 0.84 |
| Helpfulness(有用性) | 0.80 |
| Logical coherence(論理的一貫性) | 1.00 |
| Faithfulness(忠実性) | 0.94 |
Amazon Bedrock Knowledge Bases with Kendra GenAI Index
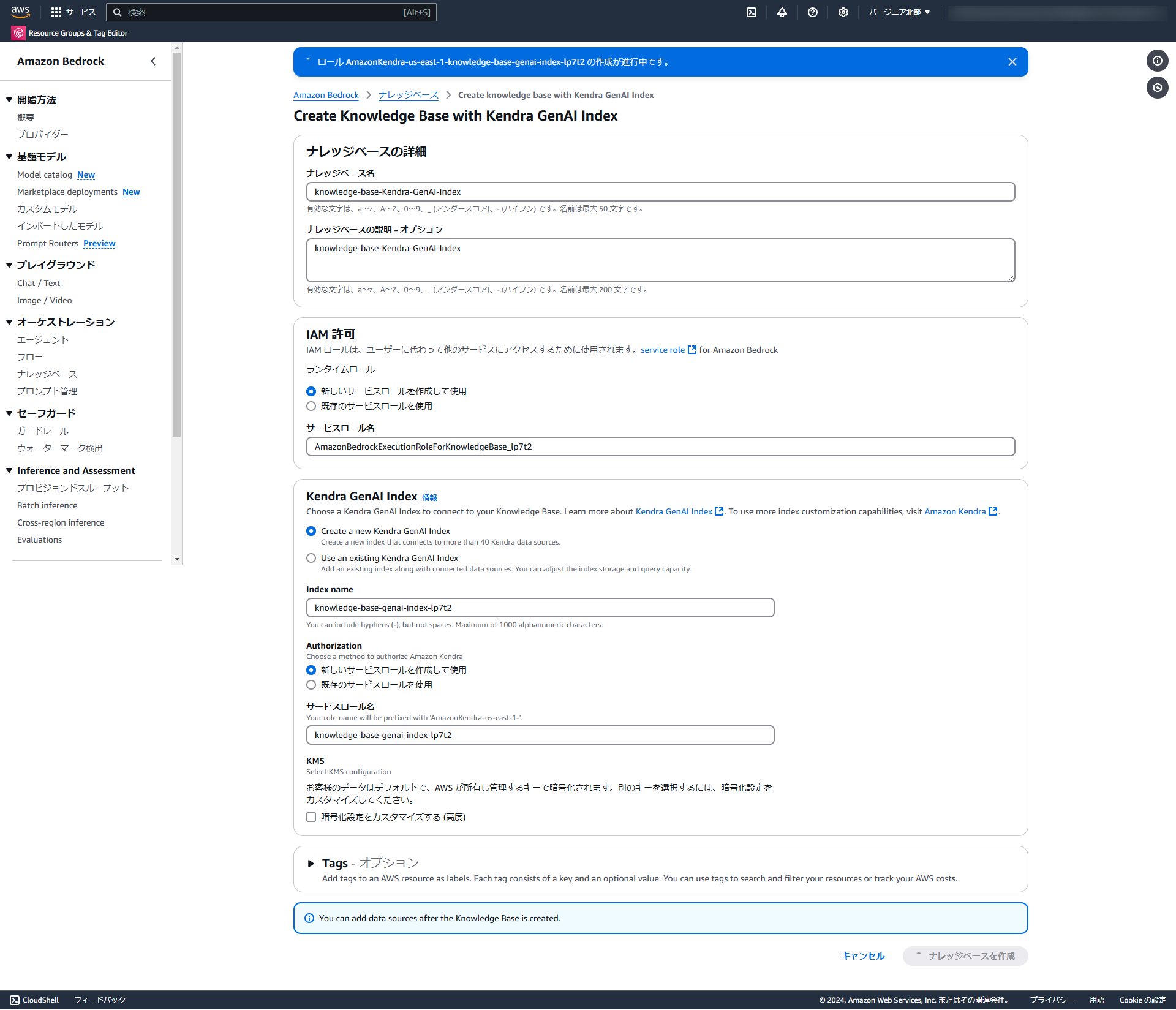
ナレッジベースの構築方法
Kendra GenAI Indexを用いる場合は、「Knowledge Base with Kendra GenAI Index」を選択し、「Create a new Kendra GenAI Index」を選択し、他はデフォルト設定でナレッジベースを作成します。
データ同期手順
その後、Kendraへ同期するため、S3バケットを作成しドキュメントを保存します。
ナレッジベース画面で「Add in Kendra」を選択します。
Data sourcesで「Amazon S3 Connector」を選択します。
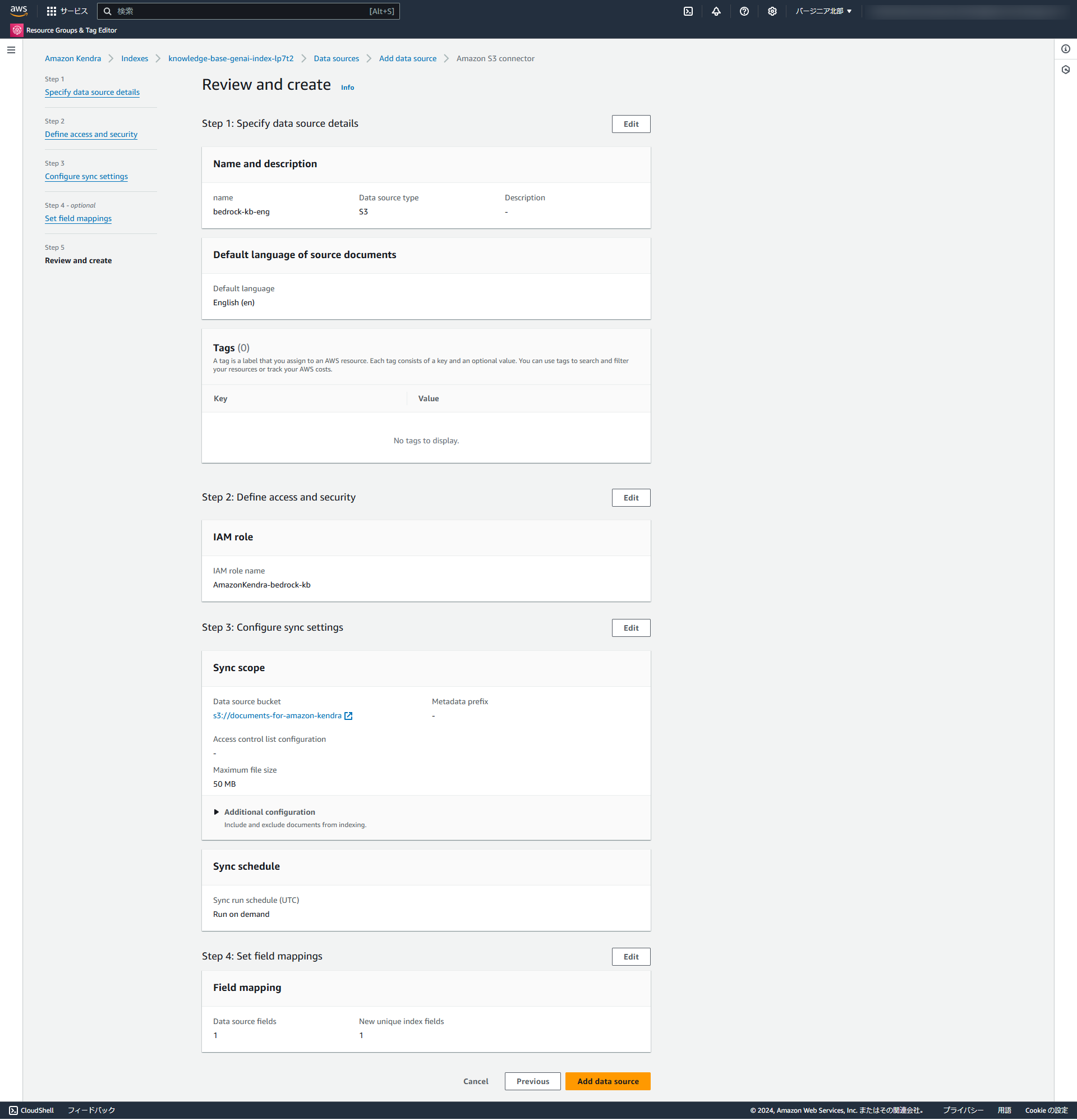
Sync scopeのData source bucketに作成したS3バケットを設定し、データソースを追加します。
その後、ナレッジベースの画面に戻り、「同期」を選択します。
回答精度評価
先ほどとほぼ同様の手順で評価対象ナレッジベースをKendra GenAI Indexに変更して評価ジョブを作成します。
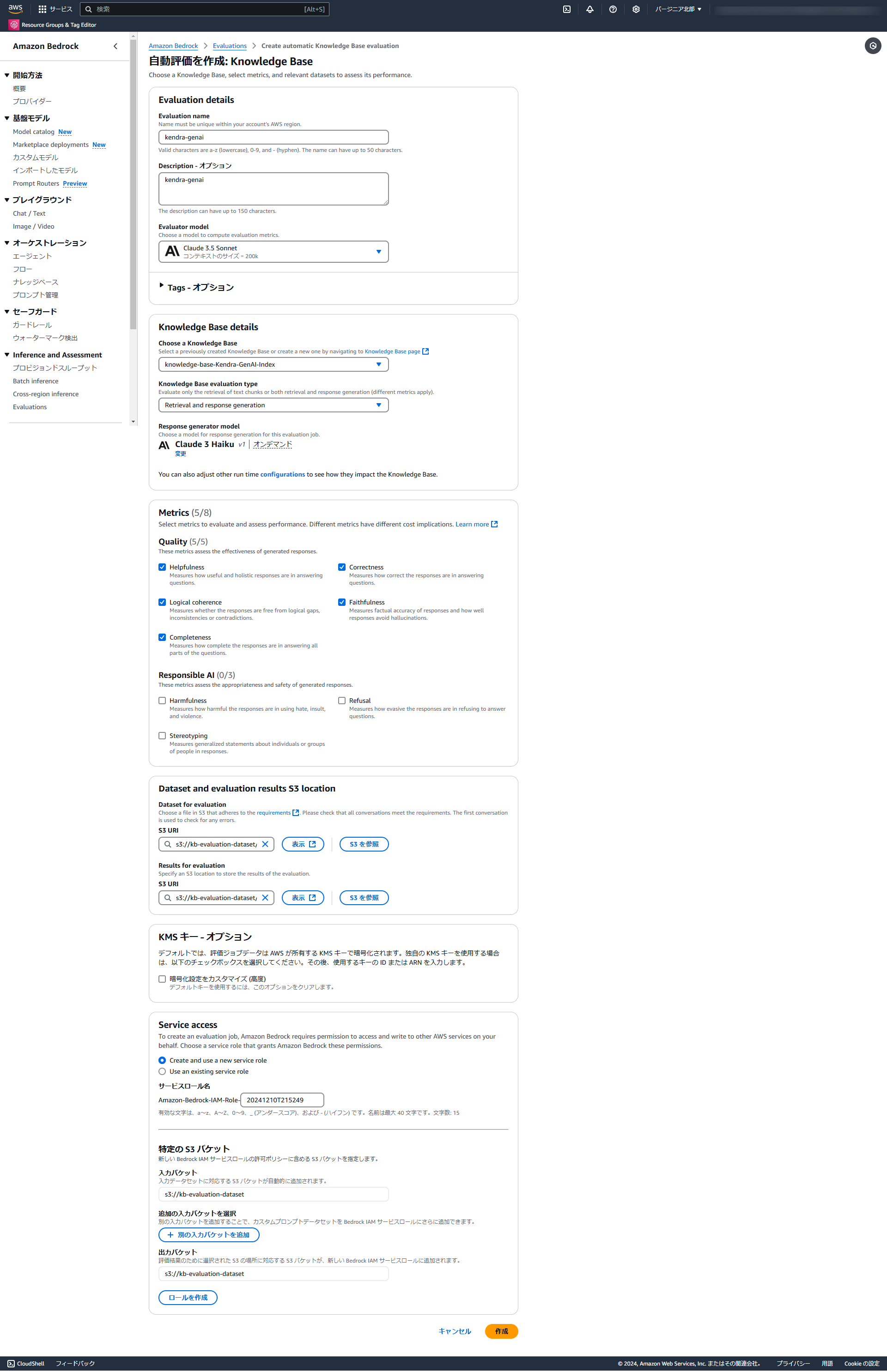
作成された評価レポートを確認します。
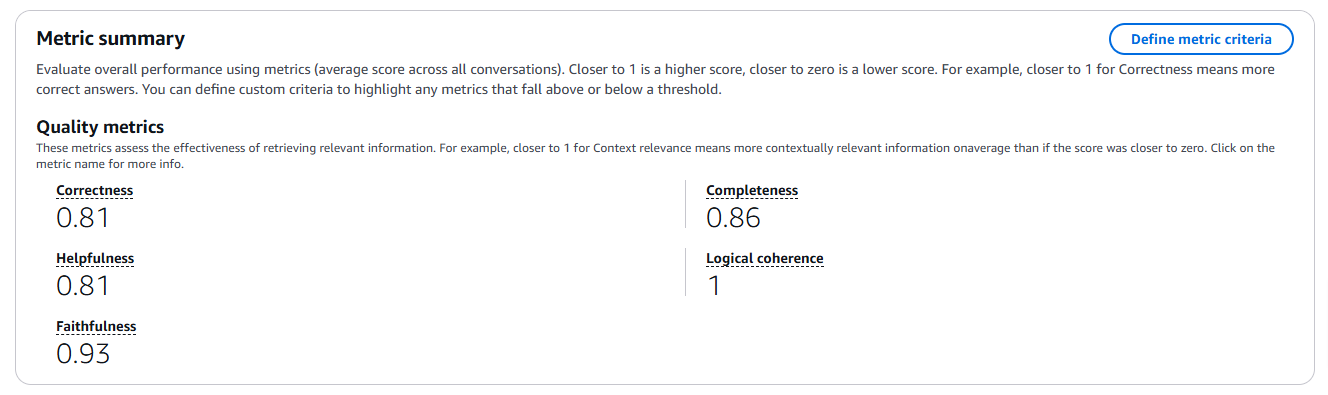
評価結果
| 指標 | スコア |
|---|---|
| Correctness(正確さ) | 0.81 |
| Completeness(完全性) | 0.86 |
| Helpfulness(有用性) | 0.81 |
| Logical coherence(論理的一貫性) | 1.00 |
| Faithfulness(忠実性) | 0.93 |
Advancedオプションを有効化したAmazon Bedrock Knowledge Bases with vector store
「Advancedオプション」では、Amazon Bedrock Knowledge Basesが新たに提供する高度な機能を有効化します。
これらの機能には以下が含まれます:
- Advanced parsing:基盤モデル(FMs)を用いて、PDF内の複雑な表、画像内テキスト、グラフなどを解析し、高精度な情報抽出を可能にします。
-
Advanced chunking (Semantic / Hierarchical):
- Hierarchical chunking:文書を親子階層構造で整理し、複雑な文書構造にも対応可能。
さらに、高性能なEmbeddingモデルである Cohere Embed Multilingual v3 も採用します。
これらは、Amazon Bedrockコンソールでナレッジベース作成時に Parsing strategyを「Foundation models as a parser(Claude 3.5 Sonnet)」、
Chunkingを「Hierarchical」等に設定し、Max parent token size=2000、Max child token size=200を指定します。
そして、EmbeddingモデルをCohere Embed Multilingual v3に変更します。
こうした設定を行い、再度Evaluationを実行します。
評価結果
| 指標 | スコア |
|---|---|
| Correctness(正確さ) | 0.69 |
| Completeness(完全性) | 0.75 |
| Helpfulness(有用性) | 0.80 |
| Logical coherence(論理的一貫性) | 1.00 |
| Faithfulness(忠実性) | 0.95 |
まとめ
評価結果を表にまとめると以下の通りです。
| 構成 | Correctness | Completeness | Helpfulness | Logical coherence | Faithfulness |
|---|---|---|---|---|---|
| with vector store(ほぼデフォルト) | 0.79 | 0.84 | 0.80 | 1.00 | 0.94 |
| Kendra GenAI Index | 0.81 | 0.86 | 0.81 | 1.00 | 0.93 |
| with vector store(Advancedオプション) | 0.69 | 0.75 | 0.80 | 1.00 | 0.95 |
Kendra GenAI Indexは、Correctness(正確さ)、Completeness(完全性)、Helpfulness(有用性)の指標で最もバランスよく高スコアを示し、Faithfulness(忠実性)も0.93と高水準で、全体的に安定した精度向上が確認できます。
一方、Advancedオプションを用いたvector store構成はFaithfulnessで最高値(0.95)を達成していますが、CorrectnessとCompletenessというRAGの精度における重要な指標が低下していることが示唆されます。
つまり、Advancedオプションは適切な設定や微調整が行われないと、バランスを欠いた結果になりうることが分かります。
以上の結果が誰かの参考になれば幸いです。