紹介する論文
論文の要約
- 観測(入力)から行動(出力)を直接学習する方法を模倣学習(imitation learning)と呼ぶ
- 模倣学習は「観測から最適な行動が決まると仮定している」ため,なかなか実用的な性能になりえない(実際この様な仮定は基本的には成り立たない)
- もう少し条件(右左折や直進などの行動という情報)を加えて学習を行う**条件付き模倣学習(conditional imitation learning)**を提案する
- 行動に従って使用するネットワークを変えることで,性能が上がることを検証した
はじめに
模倣学習(imitation learning)という言葉が最近良く使われています.カメラ画像など(入力)から行動(出力)を学習していくというものです(End-to-End学習でロボットを動かすというニュアンスで使われると思いますが,最近の言葉で定義が曖昧な気がするので,確かではありません).この模倣学習は観測から最適な行動が決定されると仮定しています.なぜなら,観測値のみを入力として使い行動を予測するからです.しかし,実際このような仮定が成り立つことはあまりありえません.例えば自動運転の文脈で考えた場合,交差点に近づいたとき,その際のカメラの画像だけから直進するか右左折するかなどは判断できません.なぜなら,「向かいたい目的地に到達するための行動(直進や右左折などの情報)を知らないから」です.なお論文では以下の様に問題提起されています.
Why has imitation learning not scaled up to fully autonomous urban driving? One limitation is in the assumption that the optimal action can be inferred from the perceptual input alone. This assumption often does not hold in practice: for instance, when a car approaches an intersection, the camera input is not sufficient to predict whether the car should turn left, right, or go straight.
(訳)
なぜ模倣学習が市街地での完全自動までスケールアップできないのか?模倣学習の限界は,ある瞬間における最適な行動を視覚的な入力だけで決定できるという仮定に基づいているために発生する.当然,この仮定は常に正しいとは限らず,例えば交差点に近づいている際のカメラからの映像だけを見ても,右折すべきか,左折すべきか,もしくは直進すべきかは判断できない.
そこで本論文では,もう少し条件を加えて模倣学習を行う**条件付き模倣学習(conditional imitation learning)**を提案します.
条件付き模倣学習(conditional imitation learning)
模倣学習は,時刻$t$におけるある観測${\bf o}{t}$に対する行動${\bf a}{t}$をマッピングするためのモデルを学習します.特に,熟練者(expert)の行動を模倣する,というニュアンスで使われるので,模倣学習と言われます.模倣学習は以下の最適化問題を解くことで実行されます(論文中式1).
\mathop{\rm minimize}\limits_{\boldsymbol{\theta}}\sum_{i}l(F({\bf o}_{i};\boldsymbol{\theta}),{\bf a}_{i})
ここで$F$は観測を行動へマッピングする関数であり,$\boldsymbol{\theta}$はそのパラメータ,$l$はマッピングされた値と実際の行動によって定義されるロスになります.この式は,熟練者の行動は観測のみからマッピングできることを仮定しているということを意味しています.
そこで本論文では,熟練者の内部状態(意図や目的地や事前知識など)を表現したベクトル${\bf h}$を導入し,上式のコスト関数を以下の様に修正します(論文中式2).
\mathop{\rm minimize}\limits_{\boldsymbol{\theta}}\sum_{i}l(F({\bf o}_{i};\boldsymbol{\theta}),E({\bf o}_{i},{\bf h}_{i}))
ここで$E$は,観測と内部状態から行動をマッピングする関数です.
しかし,実際に熟練者の内部状態を正確に取得することは困難です.そこで本論文では,新たな制御入力${\bf c}={\bf c}({\bf h})$を加えることとしています.${\bf c}$はデシジョンメイキングに相当し,${\rm continue}$,${\rm left}$,${\rm straight}$,${\rm right}$といった行動の指示を与えます.そして,実際に最適化するコスト関数を以下の様にしています(論文中式3).
\mathop{\rm minimize}\limits_{\boldsymbol{\theta}}\sum_{i}l(F({\bf o}_{i}, {\bf c}_{i};\boldsymbol{\theta}),{\bf a}_{i})
おそらくオンラインのテスト時には,トポロジカルな位置推定(あまり精度の高くない位置推定)を行い,予め指定した経路を追従するための入力${\bf c}$を求めているのだと思います.
ネットワーク構造
上述の行動のマッピング関数を深層学習によりモデル化します.本論文では,以下に示す2種類のネットワークが提案されています(論文中図3).なお,Image ${\bf i}$とMeasurements ${\bf m}$が観測${\bf o}_{t}$に,Command ${\bf c}$が制御入力${\bf c}$にそれぞれ相当しています.
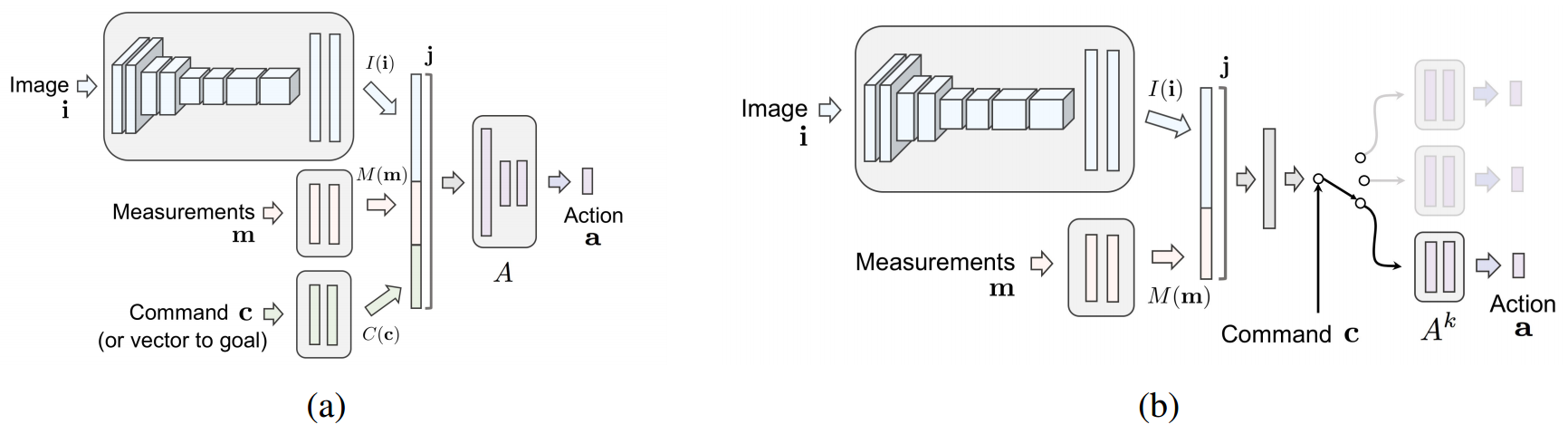
(a)のネットワークでは,すべての値が入力として用いれ,1つのネットワークで行動${\bf a}{t}$を出力します.一方(b)のネットワークでは,Commandがスイッチの様に用いられます.すなわち,Command毎に行動を出力するネットワークの学習を行います.なお行動${\bf a}{t}$は,ステアリング角$s_{t}$とアクセル$a_{t}$で構成されています.
実験
実験はCARLAを用いたシミュレーション実験と,実車と比べて1/5スケールのラジコン(Traxxas Maxx)を用いた実環境実験を行っています.
まずシミュレーション結果が以下の様になっています(論文中表1).
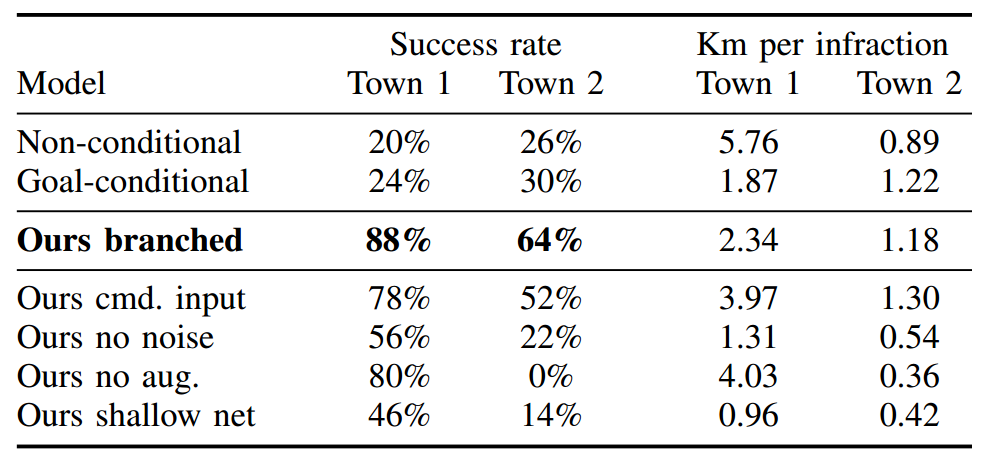
「1km走行するあたりの交通違反率」を指標とし,Commandによって使用するネットワークを変更する方法(Ours branched)が最も良い性能となっています.
また実環境実験の結果は以下の様になっています(論文中表2).

「右左折の失敗割合」,「平均介入回数」,および「走行時間」で評価されており,これにおいても提案法(Ours branched)が最も良い結果となっています.
感想
「模倣学習は観測から最適な行動が推定できると仮定している」というのは,改めて聞くとその通りだと思いました.そしてそれでうまくナビゲーションができないのもその通りだと思いました.やはり「End-to-End」ではなく,「最低限必要な情報はあるよな」と思えました.