はじめに
Lambdaを実行できる時間は15分までに制限されている。大量データの処理にはLambdaではなくtimeoutの設定がより長い時間設定できるGlueを選択することも多いが、オンライン処理のように処理速度が求められるシステムの場合やAWSのコストを抑えたい場合などの理由からLambdaを選択されるケースもあります。
システムの非機能要件には将来予想される処理対象のデータ量を要求された時間内に処理できることが求められることが多いですが、予想される時間が15分以上だからという理由でLambdaを諦めるのはもったいないです。
今回の記事ではStepFunctionsを組み合わせた方法でLambda単独で15分以上かかる処理を15分以内で完了させる方法について記載しました。
使うAWSサービス
・AWS Lambda
・AWS Step Functions
実現方法
実現方法①順次処理を並行で処理を行う(Parallel tate)
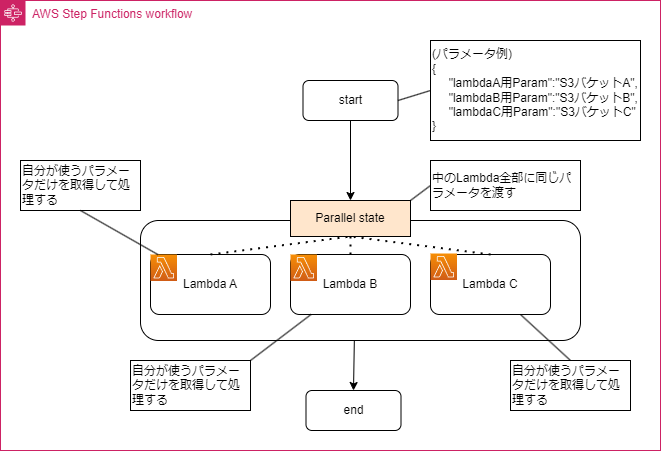
<ポイント>
・Lambdaが処理するデータが多いがそのデータがいくつかの種類に分類できる場合は並列処理が可能。この場合ではParallel tateを利用する
・順次に処理を行うと処理A → 処理B → 処理Cと流れるので全体の処理時間は3つの処理時間の合計になるが、並行処理を行うことで一番時間のかかる処理時間が全体処理の処理時間にできる。そのため、全体で15分以上かかる処理であってもLambdaで処理できる。
・ParallelState内のLambdaはすべての処理のコードが入った同じLambdaを使って渡されるパラメータを制御して実行される処理を分けるのも悪くはないが、私の好みとしては各処理ごとにLambdaを分けるほうが良い気がする(その処理を他に流用する処理ではないかや実装工数など、条件にもよるが・・・)
実現方法②同じ種類の大量のデータに対する同じ処理を並列化する(Map State)
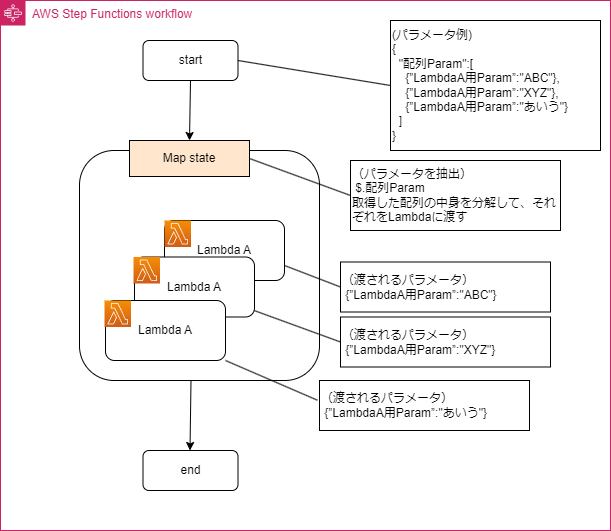
<ポイント>
・大量のデータがあり、そのそれぞれに対して同じ処理をするLambbdaである場合、MapStateを使って並列処理を実現することで処理時間を短縮できます。
・渡すデータをJson配列にして渡すことでMap内のLambdaに並列にデータを分けて同時実行されます
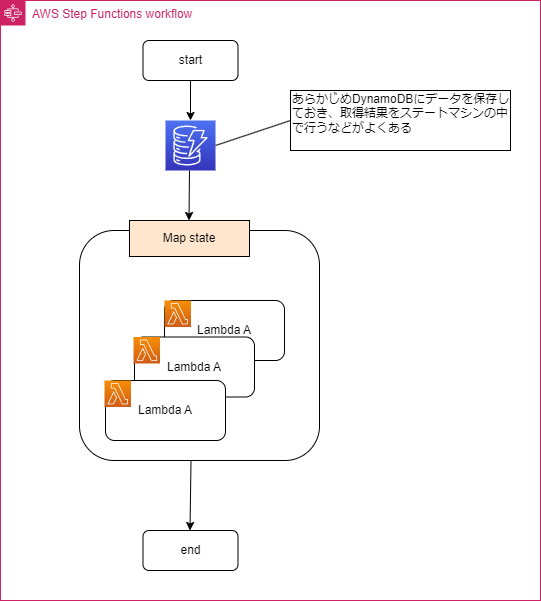
・Json配列にすることが大変だと思われるかもしれないが、例えばあらかじめデータをDynamoDBに保存しておきそのDynamoDBからデータを取得してMapに渡すなどすればJson配列にする手間は省けるので検討してみてください。
(DynamoDBと組み合わせた構成)
さいごに
GlueとLambdaはどちらも同じようなことができるのでどちらを選んでシステムを構成するのか迷うこともあります。様々な要因があるので一概にこれが正解とはいえませんが、簡単な判断材料としてユーザが処理結果をすぐ確認したいオンライン処理はLambda、日次バッチのような多少時間がかかってもよい処理はGlueを使うようにしています。
そのため、単独のLambdaで処理するとデータ量に比例してユーザを待たせてしまうよう課題(例えば大量のデータを画面からアップロードするなど)の場合は今回紹介したようなStepFunctionsと組み合わせた構成をお勧めします。
並列/並行実行に適さないデータの場合は、データにデータのカテゴリ分けするなど必要に応じてデータの管理方法も再検討してみて下さい。