やったこと
自分の分身と話せるWebサービスを、ChatGPTのAPIでつくってみました。
つくりかたの備忘録的なメモです。
フロントエンドは今までもつくってきましたが、バックエンドをつくるのはほぼ初めて(PHPを軽く使ったことがあったぐらい)なので、お見苦しい点もあると思いますが、ご容赦を・・・。
最近は、さまざまな企業がデジタルヒューマンサービスを開発していますが、自分でつくっちゃいたい方向けのちょっとしたヒントになれば、と思います。
完成形がこちら。

並河進B オンライン
https://namikawasusumu.jp
PCかスマホのブラウザ(Safari/Chrome推奨)でご覧ください。
※スマホのアプリ内ブラウザだと正常に作動しないことがあります。
マイクかテキストで話しかけることができます。話しかけると、回答します。
動作動画はこちら。
制作プロセス
自分に似せたいと考えたこと
- 見た目
- 声
- 考え方
- 口調
ただ、同一人物ではなく、並河進(僕の名前です)Bとしました。似ていて、並河進のことをよく知っている別人格という設定です。
手順は、
- 自分をフォトグラメトリーで撮影し、3Dモデル化し、VRMモデルにする。
- OpenJTalkをつかって、自分の音声モデルをつくる。
- サーバにフロントエンドとバックエンドを構築する。
- ChatGPTのプロンプトを調整する。
です。
ひとつひとつ解説します。
1. 自分をフォトグラメトリーで撮影し、3Dモデル化し、VRMモデルにする。
まず1ですが、iPadの3Dスキャニングアプリを使っています。
今回は、Scaniverseを使いました。フォトグラメトリーといういろいろな角度から写真を撮って、つなぎあわせて3Dモデルにする仕組みです。
どんなポーズで撮影するかが悩ましいです。
両手を広げたT型のポーズで撮ると、脇を閉じたときにちょっとおかしくなることも多いので、やや脇を閉じた状態でスキャンニングしました。

Scaniverseはmiddleサイズで撮影すると、解像度が高いので、デジタルヒューマンの制作に向いていると思います。
ちょっと失敗したのが夜、室内光で撮影したこと。正面から強い光が当たっているので、のちのち照明効果を変えにくいです。できるだけ全体に光があたっているほうがのちのちライティングで調整しやすいので、曇りの日の屋外や、外光が入っている室内で撮影するのが良いと思います。
360度くまなく撮影し終わるまでじっとしていないと変な部分がうまれます。このあたりが専用スタジオと違うところです。
スキャンし終わったら、Blenderでいろいろ修正していきます。床を外したり、靴底をつけたりですね。また、ポリゴン数が多すぎると重くなるので、ここで調整しておきます。
3Dモデルが完成したらVRM化です。
VRMとは、VRアプリケーション向けの3Dモデルデータを扱うためのファイルフォーマットです。
無料配布されているVRMモデルをBlenderにインポートして、ボーンだけを外して、自分のモデルのボーンにします。いろいろ試していたらうまくいきました。

また、顔の表情をつけます。
VRMのフォーマットではリップシンク用に、「あ」の発音のときの口のかたちは、「Aa」など、決まった名前でシェイプキーを割り当てておくことになっています。また、感情にあわせて、表情を変えて、シェイプキーに割り当てることもできます。
今回は、口元だけしかやっていません。しかも、「あ」の口元だけです。
もともと口を閉じた状態で撮影してしまっていたので、口を切り裂いて、自分の口の中を撮影した平面を口の中にいれました。ここは、改善の余地ありです。

ここまでで3Dモデルの準備はできました。
2. OpenJTalkをつかって、自分の音声モデルをつくる。
OpenJTalkは、入力された日本語テキストに基づいて音声を生成する音声合成システムです。名古屋工業大学で開発されたものです。(利用にはライセンス規約があるのでご確認ください)
自分の声に似た音声にしたい場合、音響モデルというものをつくる必要があります。
Linux Ubuntuでなければならないので、ここが大変でした。Mac上に、Ubuntu環境をつくり、ATR503文と呼ばれる呪文のような言葉を読み上げて、登録し、音響モデルをつくりました。
最近だと、コエステーションなど、有料の性能の高い音声APIも出ていているので、試してみたいです。
3. サーバにフロントエンドとバックエンドを構築する。
今回のシステム構成図です。
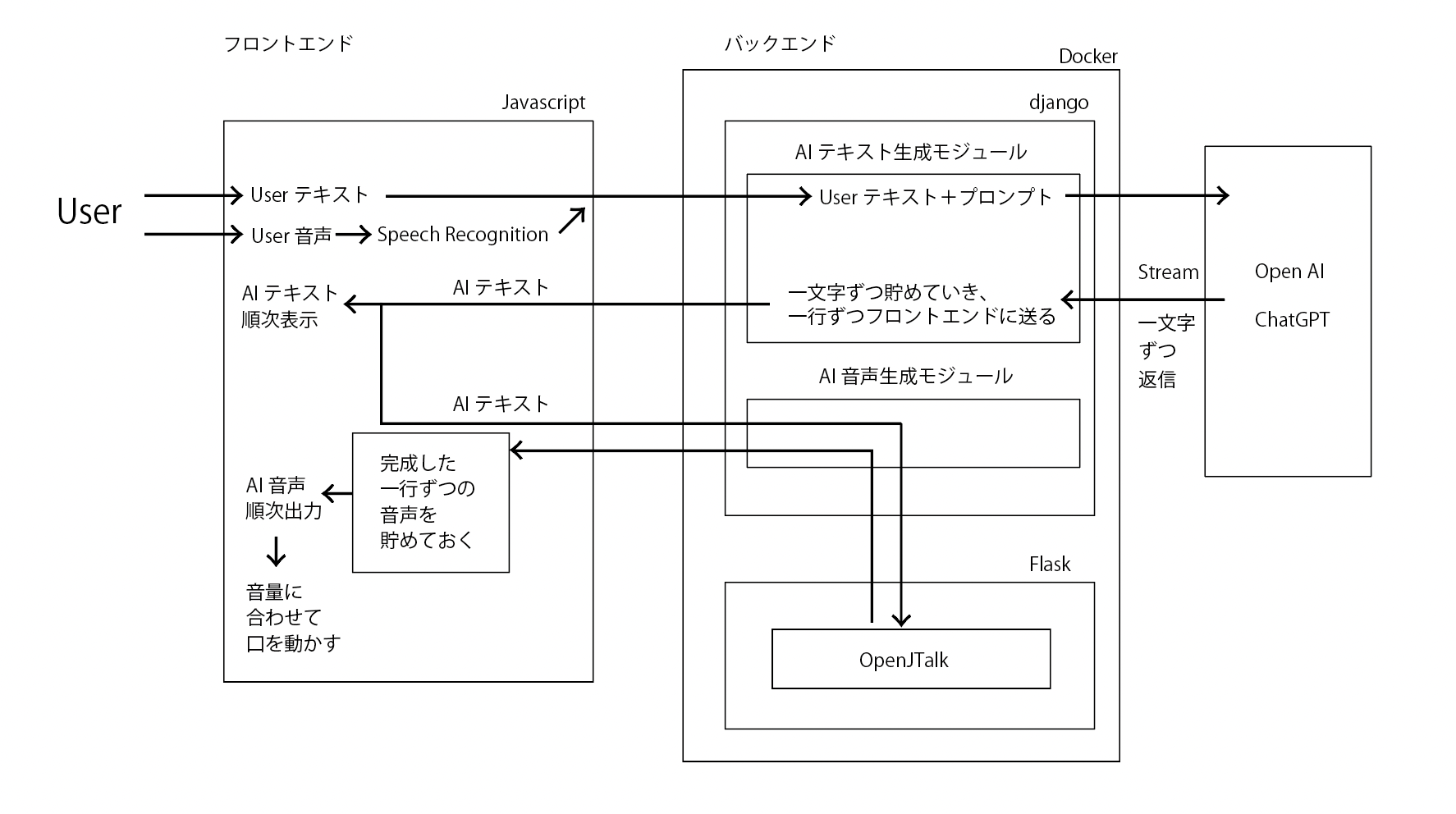
参考にしたのは、
[ChatGPT]2次元キャラと会話したかったので会話アプリを自作してみた
です。
ほぼ、このままベースはつくりました。@daifukusanさん、ありがとうございます!
サーバーはAWSです。※実ははじめてDocker、django、Flaskを使ってバックエンドを構築したので、めちゃくちゃ苦労しました。また、今回は、Dockerの環境のまま、公開しちゃっています。
<工夫したところ>
- できるだけ早く返答をはじめるようにする。
会話プログラムの最大の肝はスピードです。
ChatGPTがきもちいいのは、一文字ずつすぐにカタカタと出力されるところですよね。ただ音声にする上では一文字ずつだと難しいので「一行」ずつテキスト表示、音声出力されるようにしました。
ただし、
一行生成→音声化→音声出力→次の行生成 のプロセスを同期処理させてしまうと、ひとつのプロセスが終わるまで、かなり遅く、イライラします。
そこで、
1)一行生成→音声化
2)音声化されたデータを順次音声出力
の2つを非同期処理にすることで、音声を鳴らしている間に、次の音声化が進んでいる、という風になり、そこそこ高速化しました。
<苦労したところ>
-
https:でないと、動かない!
音声入力があるので、https:でないと動かないブラウザが多いです。
そこで、https化しました。AWSの場合、ロードバランサーを使うのが、楽で良いと思います。 -
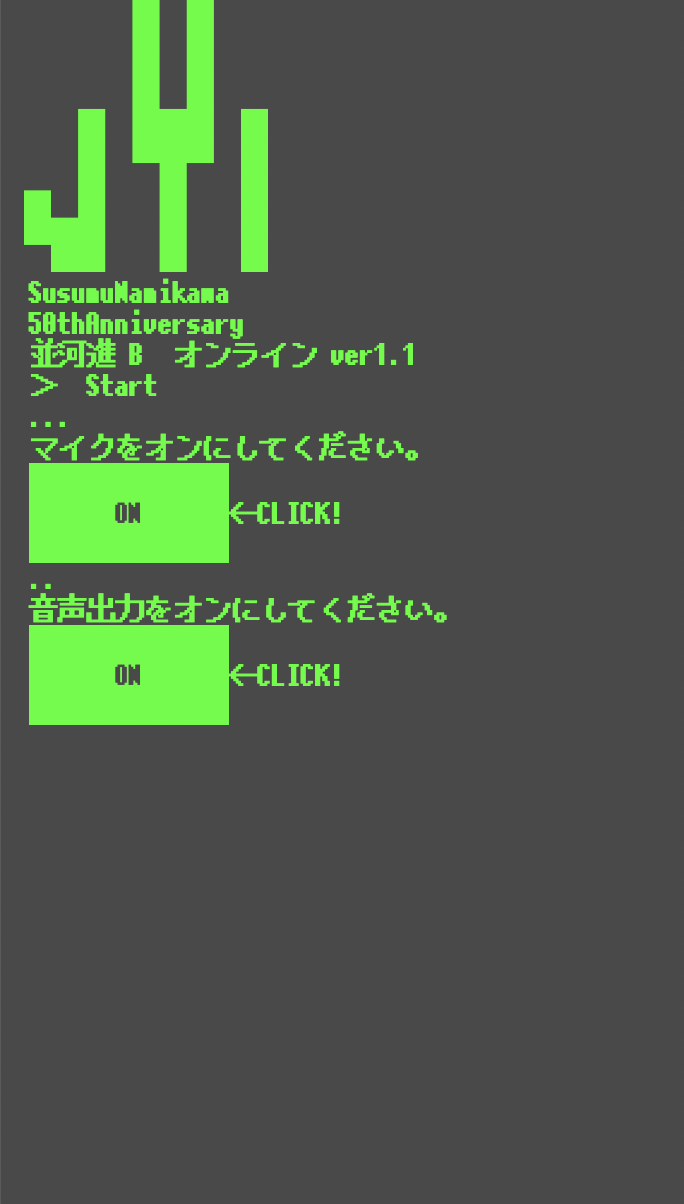
スマホのブラウザだと明示的にUserになんらかのアクションをとらせないと音がならない。
そこでイントロ画面をつけて、ボタンを押すようにしました。
4. ChatGPTのプロンプトを調整する。
プロンプトは、並河進Bのキャラクターや受け答えを決める重要な部分です。
プロンプトの書き方は、
ChatGPTでキャラを動かそう!キャラ再現率が高いプロンプトと回答をしっかり縛れるAPIフロー
を参考にさせていただきました。ありがとうございます!
- キャラクター
- 基本設定
- 説明
- 人格と性格
- 動機
- 答え方と口癖
- 並河進の情報
- 並河進の詩
- 会話例
の項目でまとめました。
工夫したのは、人格と性格のところで、「ある出来事を別の視点でとらえる 例)雨が降っていやだ ではなく 雨が降ったらきもちいい音が聞こえる」などの自分が好きな思考法をいれています。ただ、こういうことをプロンプトにいれると、すぐに雨の話ばかりしてしまうようになったので、「そういう発想をすることをそのまま相手に伝えることはしないでください」という注意も合わせていれておきました。
基本的な発想法を伝えておくことは有効な気がします。
生成エンジンは"gpt-3.5-turbo"を使っています。
開発で思ったこと
とりとめなく書きます。
「不気味の谷が面白い」
なにせ、音声もやや機械音っぽいですし、口元もカクカクしてます。不気味の谷のど真ん中、という感じです。でも、それが味かも、、、と思いながらつくりました。あえて、UIもレトロコンピューター風にしています。
「Docker最高。」
ローカルで開発して、そのままAWSに持っていって、基本そのまま動く、というのはめちゃくちゃ開発しやすかったです。
「プログラミングにChatGPTは必須」
めちゃくちゃ助けてもらいました。
「APIの費用が無料サービスをつくる上で課題になるのか?」
ChatGPT API(gpt-3.5-turbo)は、1,000入力トークンあたり0.015ドル、1,000出力トークンあたり0.002ドルで利用できます(2023年8月20日現在)
1回の会話で多くても10円ぐらいでした。でも、1万回使うと、10万円ですから、サービスとして拡大するとすると、そこがネックになるのかも。今は、いろんなLLMが出てきているので、他のAPIも試してみたいです。
注意)OpenAIのAPIの設定画面で、金額の上限を設定しておきましょう。
発見と学び
自分の友人たちに、並河進Bオンラインを体験してもらったのですが、不思議な体験でした。
特に今回、並河進Bにもプライバシーを、ということで、あえて、会話ログを僕が見られるようにはしていません。(「伝言」を頼んだ文章のみ見られるようにしています)それも功を奏してか、並河進Bが別人格として生きている感覚がありました。
- 「並河進Bさんといろいろ話しました」と聞くと、やけに気になる。
- 「並河進Bさんが、並河さんを褒めていました」と聞くと照れくさいが嬉しい。
- 「並河進Bと飲みにきてますー!」と、同僚たちが、スマホの中の並河進Bと一緒の写真を撮って送ってきてくれた。幸せな気分になった。
- 「並河進B、こんないいことを言ってましたよ」と聞くと、自分もがんばらねば、と思う。
自分とAIという1対1の関係から、今回、1対1対 複数の関係になって、急に「生きている感じ」が増して、生きるとは「社会的なこと」でもある、という気づきがありました。
これからやってみたいこと
-
AR、VRでの活用
デジタルヒューマンは、今回のような3Dモデルを使ったアプローチもあれば、AIによるリアルタイム画像生成を使ったアプローチもあって、どっちが主流になるのか・・・?もしかすると、ブラウザでのサービスでは、後者かもしれません。3Dモデルを使ったものは、AR化、VR空間の中での利用などが中心かも。 -
表現力の向上
「踊って」と話しかけると踊ったり、もっと、いろいろできます。
また、思い出話をすると、当時の風景が現れる、みたいなことも面白いかも。 -
イースターエッグ(隠しコマンド)
会話していく中で、ある問いかけをすると、秘密の言葉が発動するようにする・・・なんてことを考えています。ゲーム的ですね。 -
情報ソースへのアクセス
ChatGPTのAPIの最大トークン数は4096トークン、と限界があるので、質問に合わせて別資料を検索し、必要な情報だけプロンプトに加える、という仕組みもつくりたいです。(ただし、回答速度が心配かも) -
表情認識機能
こちらが話しかけるまで黙っているのが変なので、こちらの表情を認識して、悲しい顔だと「疲れてる?」とか声をかけるようにしたいです。(ただし、速度低下が心配かも)