1.TensorFlow
■演習 ・constant
・placeholder

・variables
 !
!
・線形回帰

・非線形回帰

・分類1層 (mnist)

・分類3層 (mnist)

・分類CNN (mnist)

2.強化学習
・強化学習 長期的に報酬を最大化できるように環境のなかで行動を 選択できるエージェントを作ることを目標とする機械学習の一分野 →行動の結果として与えられる利益(報酬)をもとに、 行動を決定する原理を改善していく仕組み。・探索と利用のトレードオフ
探索が足りない状態
過去のデータで、ベストとされる行動のみを常に取り続ければ
他にもっとベストな行動を見つけることはできない。
↕︎トレードオフの関係性
利用が足りない状態
未知の行動のみを常に取り続ければ、過去の経験が活かせない。
・強化学習と教師なしあり学習の違い
目標が異なる
教師なしあり学習
データに含まれるパターンを見つけ出すおよびそのデータから予測することが目標
強化学習
優れた方策を見つけることが目標
・強化学習の歴史
計算速度の進展により大規模な状態をもつ場合の強化学習を可能としつつある。
関数近似法とQ学習を組み合わせる手法の登場
Q学習
行動価値関数を行動する毎に更新することにより学習を進める方法
関数近似法
価値関数や方策関数を関数近似する手法のこと
・行動価値関数
価値を表す関数としては、状態価値関数と行動価値関数の2種類がある
状態価値関数
ある状態の価値に注目する
行動価値関数
状態と価値を組み合わせた価値に注目する
・方策関数
方策ベースの強化学習手法において、
ある状態でどのような行動を採るのかの確率を与える関数のこと
・方策反復法
方策をモデル化して最適化する手法
定義方法
平均報酬
割引報酬和
3.Keras
・線形回帰
・単純パーセプトロン

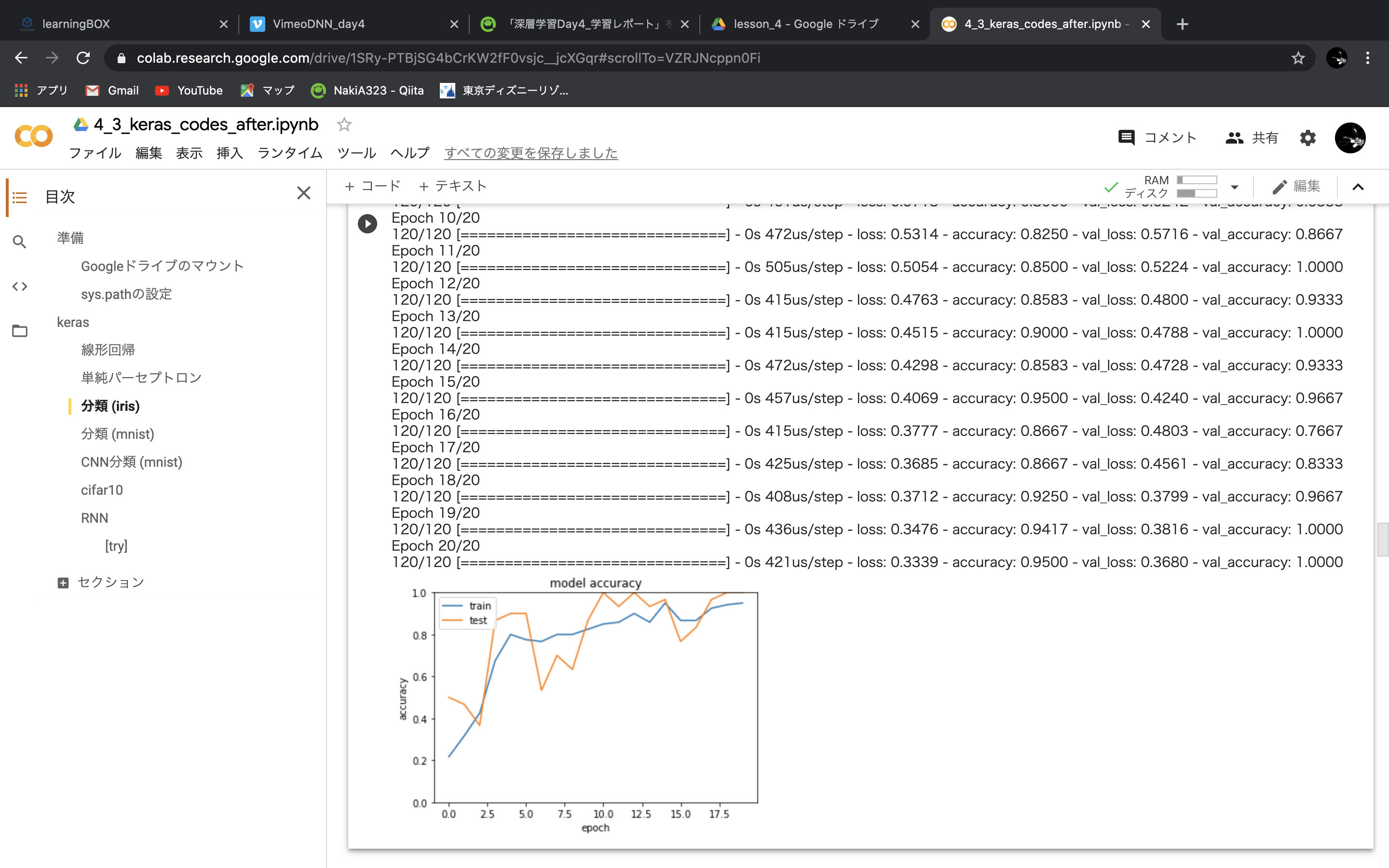
・分類 (iris)
・cifr10

・RNN
