利用環境
データベース:Oracle Autonomous Data Warehouse 容量(1OPCU)
BIサービス:Oracle Analytics Cloud 機能セット(Enterprise Analytics) 、容量(2OPCU)
用意したデータについて
アパレル事業の店舗POS売上明細データ: ID付きPOSデータなので、会員ID付きの売上データです。商品属性(カラーコード、サイズ)、ブランドなどは、連結済み
会員マスタデータ:会員の基本属性データですが、ポイント増減に関する情報も、連結済みのデータ
Analytics Cloudを活用したPOSデータ分析:商品クラスター分析②(Cluster関数の活用)
前回は、ビジュアライゼーションの拡張分析機能のクラスタリングを利用した商品クラスタリングを行う方法について御紹介しました。マウスを使った簡単な操作で、高度なクラスタ分析をおこなうことが出来るので便利な機能ですが、商品に割り振られたクラスタコードや名前をデータとして取得できないので、クラスタリングした結果を利用する際に課題がありました。
今回は、Analytics Cloudの関数ライブラリに用意されているCluster関数を使って、自分で計算項目(カラム)を作成する方法について御紹介します。
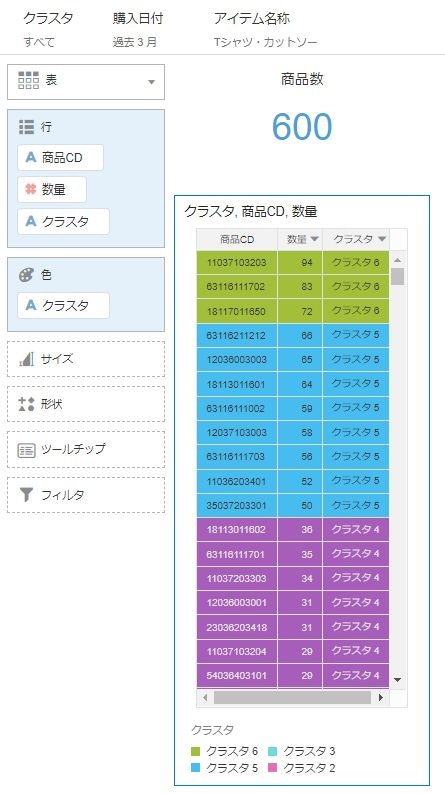
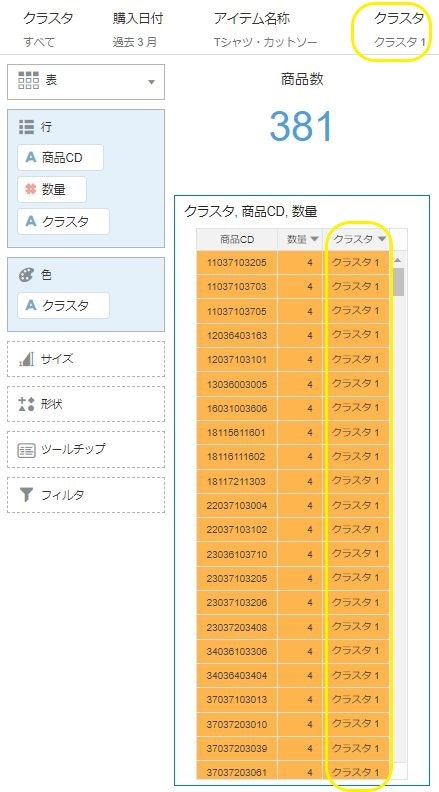
完成形イメージ
商品クラスター(直近90日のTシャツ・カットソー売上数量ベース)
Cluster関数の作成
まず、”マイ計算”を右クリックして計算エディタを開きます。
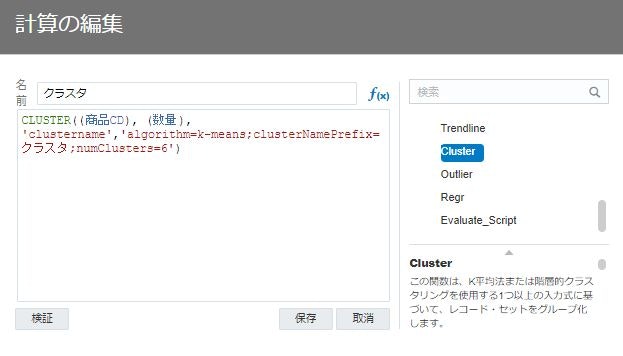
クラスタ関数をエディタ右側の関数ライブラリから選択して、エディタ上で任意のプロパティを設定して、念のため”検証”をクリックして、式が正しいことを確認してから、”保存”をクリックして式を保存します。
クラスタ(Cluster)関数の構文は、下記のとおりです
構文
CLUSTER((dimension_expr1 , ... dimension_exprN), (expr1, .. exprN), output_column_name, options, [runtime_binded_options])
dimension_expr:クラスタリングの対象とするディメンション(商品CDや顧客CDなど)のリストを指定
Expr:クラスタリングするために使用するメジャーカラム(売上数量や金額など))の組み合わせ、またはディメンション属性を指定
output_column_name:クラスター計算の結果カラムに出力する項目を指定
options:セミコロン(;)で区切られた、option nameとvaluesの組み合わせリスト。Valueについては、%1…%Nの形式で指定することが可能。(実際の値は、”runtime_binded_options”にバインド・リストとして指定)
runtime_binded_options:カンマ(,)で区切られた、カラムまたはオプションのリスト
Output_column_nameの指定項目
| Output Columns | Description |
|---|---|
| clusterID | クラスター番号またはID |
| clusterName | clusterIDに対応するクラスター名称 |
| clusterDescription | クラスターに関するデスクリプション |
| clusterSize | クラスターのエレメント数 |
| distanceFromCenter | クラスターの中心からの距離 |
| centers | クラスターの中心 |
Output_Column_nameでは、最低限、clusterNameを指定するようにしましょう
Optionsの指定項目
| Option | Description | Values |
|---|---|---|
| algorithm | クラスタリングのアルゴリズム | “k-mean”(分割最適化手法)または”h-clustering”(階層的手法) |
| method | 各アルゴリズムで使用するメソッド | “k-means“アルゴリズム: Hartigan-Wong, Lloyd, Forgy, MacQueen “h-clustering”アルゴリズム: ward.D, ward.D2, single, complete, average, mcquitty, median, centroid |
| numClusters | クラスターの数 | 数値 |
| attributeNames | クラスタリングする際の属性 | arg1,arg2,arg3,arg4,arg5,arg6,arg7,arg8,arg9,arg10 |
| maxIter | クラスタリングする際のイテレーションの回数(反復回数) | 数値 |
| normalizedDist | TRUEを設定した場合、距離を0から100の間で正規化する | TRUEまたはFALSE |
| useRandomSeed | デフォルト設定値はTRUE。クラスタの中心の初期値(seed)をランダムに指定する。本番環境では基本的にTRUEを指定。FALSEはQA/テスト環境の場合に指定。FALSEを指定する場合は、合わせて”initialSeed”オプションを再現性のために指定すること。 | TRUEまたはFALSE |
| initialSeed | “useRandomSeed” オプションをFALSEにセットしている場合にのみ指定。デフォルト設定値は250 | 数値 |
| clusterNamePrefix | クラスター名称の前につけるprefix (デフォルト値はnull) | 文字列 |
| clusterNameSuffix | クラスター名称の後につけるsuffix (デフォルト値はnull) | 文字列 |
Optionsに関しては、 algorithmだけは必ず指定するようにしましょう。明示的に指定しないと、何故か、関数を実行した時にk-meansかh-clusteringを指定しなさいというエラーが返ってきます。各アルゴリズムでさらに、メソッドも細かく指定する際は、methodを指定することになります。あとは、クラスターの数(numClusters)や、出力されたクラスタ名の前後につける文字(clusterNamePrefixとclusterNameSuffix )を指定することがあると思います。
このOutput_column_nameやOptionsに指定する項目に関する記述が、エディタの説明やAnalytics Cloudの製品ドキュメントには詳しく記載されていないので、何を指定すればわからないのが困りものです。
オンプレミス版の製品ドキュメントの方に比較的詳しく説明されているので、そちらのクラスタ関数の章を見ていただく事をお勧めします。
今回は、
- 商品CDについて、数量(枚数)でクラスタリングを行う
- clusternameをアウトプットする
- クラスタリングのアルゴリズムはk-meansを活用
- クラスタの数は6
- クラスタ名の接頭詞には、”クラスタ”をつける
ということで、計算式は下記の通りになります
CLUSTER( (商品CD"), (数量), 'clustername','algorithm=k-means;clusterNamePrefix=クラスタ;numClusters=6')
”マイ計算”で作成した、計算項目を使ってビジュアライズ(例えば表)を作成すると、このように商品CDごとの、クラスタ名を明示的に出力することが出来ます。
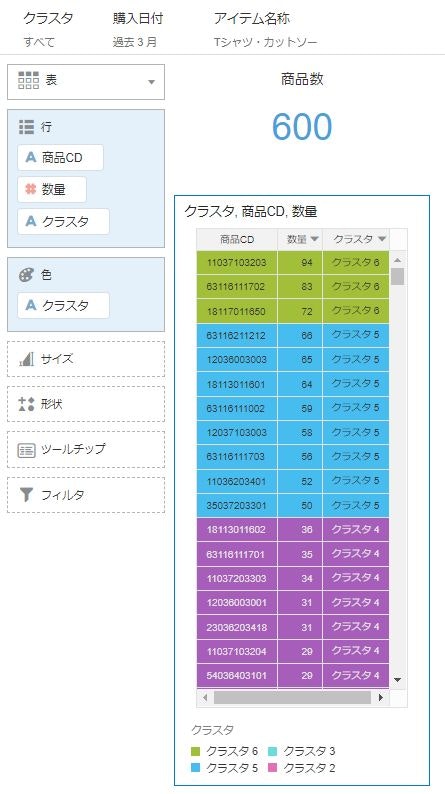
計算項目は、もちろんフィルタにも、使うことことが出来ますから、特定のクラスターに絞り込むことで、例えば、死に筋商品だけ抽出するような作業も容易に行うことが出来るようになります。実務上はこのような使い方の方が多いのではないでしょうか。
まとめ
-
クラスタ関数を使って、より細かいパラメタを指定しながらクラスタ分析をおこなうことが出来る
-
クラスタ名などを明示的に出力できるので、クラスタリングの結果をビジュアライズするだけでなく、業務に活かしていく場合には、クラスタ関数を使う必要性がありそう