pythonでpipインストールできるStanfordNLPには係り受け構造を描画する機能がありません。というわけで、Graphvizを使って木構造を描いてみました。コードはGithubにもあります。間違いなどありましたら、ご指摘いただければ幸いです。
完成品
ご指摘いただき修正しました!ありがとうございます!
修正内容:ラベルを付けました(ただしコメント欄のモデルのほうはroot、品詞タグ付き+文の構成が一目してわかるリッチな良プロダクト)。
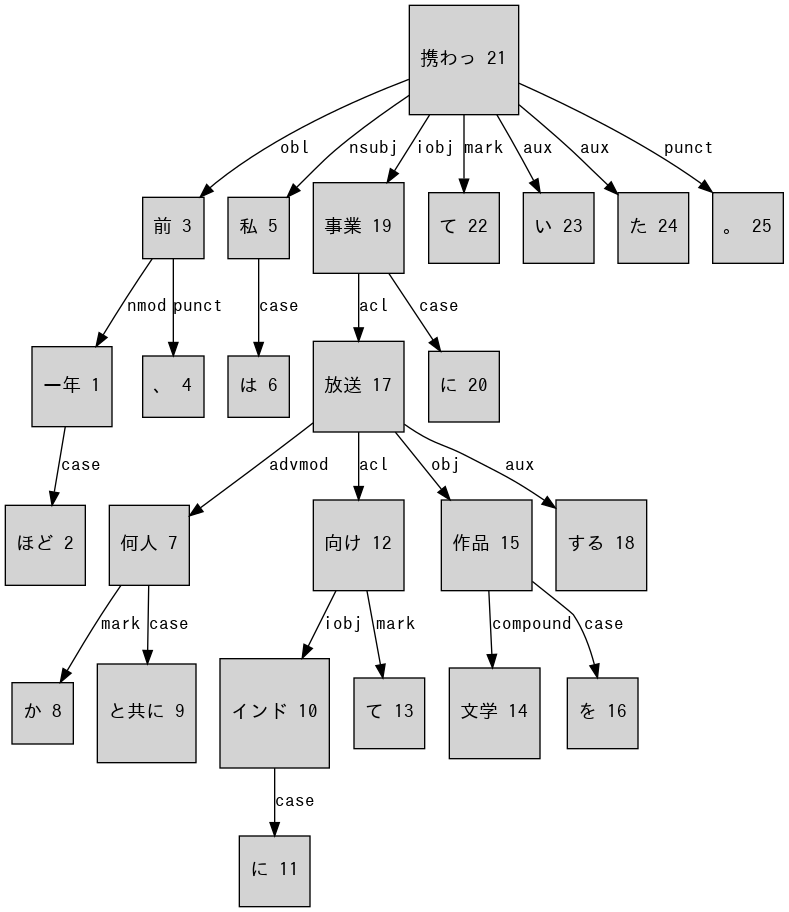
描画した構造のファイルはこんな感じです。数字はindexで、同じ単語だけど違うindexのワードを混同しないためのものです('て 22''て 13'など)。
準備
StanfordNLPの使い方や、今回使う文章は前回の記事通りです。
GraphvizとStanfordNLPのpipインストールと、日本語対応フォントのインストールを行います。
pip install stanfordnlp
pip install graphviz
apt-get -y install fonts-ipafont-gothic
日本語言語モデルをダウンロードし、テキストを指定。
import stanfordnlp
stanfordnlp.download('ja')
nlp = stanfordnlp.Pipeline(processors= 'tokenize,mwt,pos,lemma,depparse', lang='ja')
doc = nlp('一年ほど前、私は何人かと共にインドに向けて文学作品を放送する事業に携わっていた。種々のものをとりあげた中で、かなりの部分が現代ないしそれに近い時代の英国作家の韻文だった――例えばエリオット、ハーバート・リード、オーデン、スペンダー、ディラン・トーマス、ヘンリー・トリース、アレックス・コンフォート、ロバート・ブリッジズ、エドムンド・ブルンデン、D・H・ローレンス。詩の実作者に参加してもらえる場合はいつでもそうしていた。何故にこういう特殊な番組(ラジオ戦争における遠方からのささやかな側面攻撃だ)が始められることになったかは改めて説明するまでもないが、インド人聴衆に向けた放送である、という事実によって、我々の技法がある程度まで規定されていたという点には触れる必要があるだろう。要点はこうだ。我々の文芸番組はインド大学の学生たちをターゲットにしていた。彼らは少数かつ敵対的な聴衆で、英国のプロパガンダと表現しうるものは一つとして届かなかった。あらかじめ、聴取者は多めに見積もっても数千人を越すことはないだろうということがわかっていた。これが通常オンエアできる範囲を超えて「ハイブロウ」な番組を作るための口実になったのだ。')
コード
i=0を先頭に置き、1プラスしていくのは一文ごとに個別のファイルを作り、番号付けするためです。
追記:ラベルを追加するよう修正(label=f'{wrd[1]}')
from graphviz import Digraph
def dependency_visualized(doc):
i = 0 # to name file, including dependency in a sentence
for sent in doc.sentences:
dot = Digraph(format='png', filename=f'test/graphs{i}')
dot.attr('node', shape='square', style='filled', fontname="IPAGothic")
for wrd in sent.dependencies:
if wrd[0].text != 'ROOT':
dot.edge(f'{wrd[0].text} {wrd[0].index}', f'{wrd[2].text} {wrd[2].index}',label=f'{wrd[1]}', fontname="IPAGothic")
# specify index because there is the same word(like 'で、。') but with different indexes
else:
pass
dot.render()
i += 1
dependency_visualized(doc)
利用したテキスト
利用したテキストは青空文庫にあるオーウェルの『詩とマイクロホン』の冒頭です。
The Creative CATさんによる翻訳。感謝。

この 作品 は クリエイティブ・コモンズ 表示 3.0 非移植 ライセンスの下に提供されています。