はじめに
現在EC2上で動いているサービスのログを解析することになり、方法を調べた結果AWS上のサービスを使用してする方法がベストだと考え実装した。これらのサービスは比較的に最近できた(たぶん)のであまりこの方法で紹介している日本語の記事がなかった。今でもログ解析といえば、fluentd + Elasticsearch + Kibanaが圧倒的に王道みたいだがわざわざAWSが色々と提供してくれているのでそちらを使う。以下、EC2でサーバーが動きログファイルがあることを前提にしています。インフラの人でもなんでもないので間違いがあれば、優しくご指導ください。
参考資料
この記事で詰まった際は下記を参照ください。また私は下記の資料を通して実装しました。
AWS公式 ログ解析のチュートリアル
AWS Kinesis Firehose
AWS Kinesis Analytics
AWS Elastic Search
Amazon Kinesis Agent
全体図
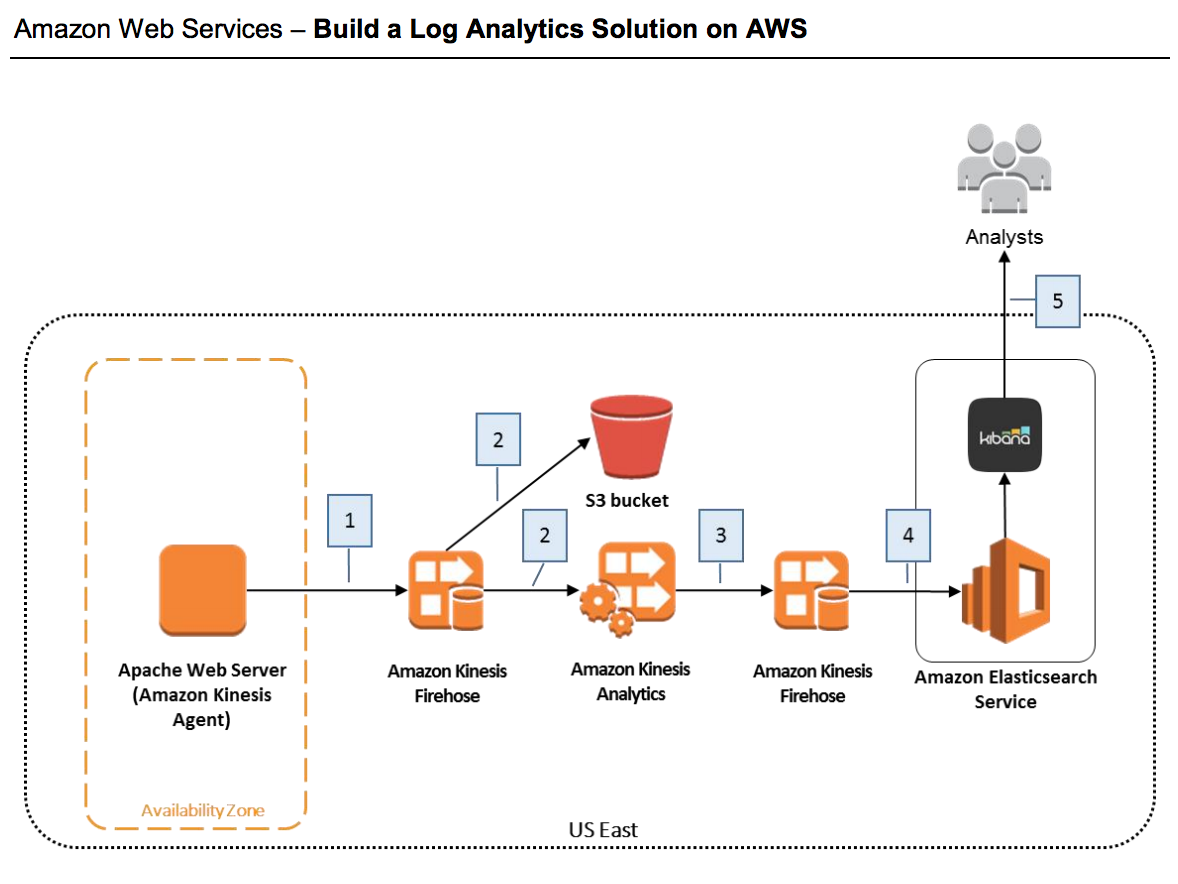
全体的な図は上記のようになります。画像ではインスタンスで走っているサーバーがApacheとなっていますが、Nginxや他のサーバーを使用でも設定次第で問題にはなりません。
全体の流れ
システムを構築している時、記述通りしているつもりでも簡単な間違いで動かなくなることが多々あります。そんなときに全体の流れ、繋がりをしっかりと理解することによりデバックが容易になります。
- EC2インスタンスから、サービスとサービスをつなげる役割を持つAmazon Kinesis Firehose(以Firehose)にログを流す。
- このFirehoseはS3 Bucketにデータを流す先としている。
- 次に、Amazon Kinesis AnalyticsはFirehoseからS3 Bucketに流れているログデータを解析し、解析後のデータを他のFirehoseに渡す。
- 解析後のログを渡されたFirehoseはAmazon Elasticsearch Service(以下Elasticsearch)にデータを受け流す。
- Elasticsearchに保存されたデータはkibinaを通じデータを可視化し、ユーザーにたどり着く。
注意: ヘッダーの右上からRegionをN.Virginiaにしてから以下を進めてください。(N.Virginia を含む特定のRegionでしかここで使用するAmazon Elasticsearch Serviceがないためです。)
ステップ1:一つ目のFirehoseを作成
EC2インスタンスとS3へログを流すFirehoseを作成します。
-
Amazon Kinesis へアクセスします。
- Firehoseへ行き、 Create Deliver Stream(デリバリーストリームを作成) ボタンを押し作成します。
-
Delivery stream nameを入力しますが、ここはこのFirehoseの名前なのでなんでも構いません。何を入力すればよいかわからない方は 「log-ingestion-stream」としましょう。
- 次に情報元をDirect PUT or other sources(直接のPUTまたは他の情報源)に選択します。
先にお話したとおりFirehoseは情報を一つの場所からもう一つの場所へ移行させる役割を持ちます。ここでは*Kinesis Stream*または*Direct PUT or other sources*の選択肢があり、Kinesis Streamを情報元にしている場合は*Kinesis Stream*からそれ以外は*Direct PUT or other sources*を選択します。今回の情報源はEC2なので**Direct PUT or other sources**となります。
5. 一番下まで行き、Nextボタンを押します。押した後、次の選択肢はデフォルトの**Disabled**を選択します。Firehoseではただ情報を受け渡すだけではなく、AWS Lambdaを使用して情報に変更を加えてから渡すことができるようです。ここではそれの選択肢として、Disable(しない)とEnable(する)があります。私は使用したことがないのでこれ以上の解説はできません。
6. Nextボタンを押し、次は送り先(Destination)をAmazon S3に選択します。一つ目はEC2からS3へ情報(データ)を送ります。
7. S3のバケットとして、ログの保管する場所を指定します。ここではCreate Newボタンを押してバケットの名前をなんでも構いませんのでつけてください。何にすればいいかわからない方は「log-bucket」としてください。8. Nextボタンを押し、一番したまで行けば、IAM roleをしていするフォームがありますので、Create new or Chooseボタンを押しましょう。
9. タブが開けば、Create new IAM roleを選択したまま他はデフォルトで右下のAllowを押します。
10. 完了すればNextを押し確認に問題がないようでしたらCreate delivery streamボタンを押し、作成します。
ステップ2:Amazon Kinesis AgentをEC2にインストール
先程作成した、firehoseにEC2からログデータを送るために、AWSが公式に開発しているJAVA製のEC2からFirehoseにリアルタイムでファイル情報を送ってくれるAmazon Kinesis Agentをインストールしましょう。ここが最も間違いが起きやすいところかと思います。
1. ダウンロード方法を参考にAmazon Kinesis Agentインストールしましょうしてください。
yumが入っていれば以下のコマンドでインストールできます。
sudo yum install –y aws-kinesis-agent
私の場合は、 Java JDEなかったのでtools.jar が見つからないというようなエラーが出ました。そのようなエラーが出た方は
sudo apt-get install openjdk-7-jdk
JDKをインストールしましょう。(参考)
2. agentの設定をする
amazon kinesis agentに「どのファイルログのデータをどこに送るのか」または「どのような形で送るのか」という事などを設定していきます。
Amazon Kinesis Agentの設定ファイルは /etc/aws-kinesis/agent.jsonにあるかと思います。そのファイルを以下のように設定してください。
なお、
filePattern: "full-path-to-log-file" のfull-path-to-log-file解析したいログファイルへのフルパスに(nginxをご使用の方は etc/nginx/access.log かと思います)してください。
deliveryStream: "name-of-delivery-stream" のname-of-delivery-streamを送りたいfirehoseの名前に(ステップ1で作成したfirehoseの名前)してください。
{
"cloudwatch.endpoint": "monitoring.us-east-1.amazonaws.com",
"cloudwatch.emitMetrics": true,
"firehose.endpoint": "firehose.us-east-1.amazonaws.com",
"flows": [
{
"filePattern": "full-path-to-log-file",
"deliveryStream": "name-of-delivery-stream",
"dataProcessingOptions": [
{
"initialPostion": "START_OF_FILE",
"maxBufferAgeMillis":"2000",
"optionName": "LOGTOJSON",
"logFormat": "COMBINEDAPACHELOG"
}]
}
]
}
長くなってしまいますが、親切にするためにはここで気にしなくてはならないことが幾つかあります。
エンドポイント(firehose.endpoint)
一番初めの注意通り、N.VirginiaにFirehoseを作成している方はなんの問題もありませんが、そのようにしていない方はエンドポイント一覧を参考にして, cloudwatch.endpoint とfirehose.endpointを変更してください。なお、はじめの注意でも述べたようにElasticsearchでは数少ないリージョンにしか対応していないため、他のリージョンにしている方は最後になってやり直さなければならない可能性もあります。
情報処理の設定(dataProcessingOptions)
Apacheを使用している方はなんの問題もありませんが、nginxを使用している方はここに少し変更が必要です。こちらの設定でログデータの処理方法を変更できます。
設定のオプションとしてmatchPatternがあり、こちらと正規表現を使用してどのようなログフォーマットでも処理が可能になります。下のものは処理をしたいログとそのmatchPatternの一つの例ですので参考にしてご自身のものを変更してください。(参照)
111.111.111.111 - - [02/Dec/2016:13:58:47 +0000] "POST /graphql HTTP/1.1" 200 1161 "https://www.myurl.com/endpoint/12345" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36" 0.172 "query user userMessages hasPermissions F0 F1" 11111;222222
{
"dataProcessingOptions": [
{
"optionName": "LOGTOJSON",
"logFormat": "COMMONAPACHELOG",
"matchPattern": "^([\\d.]+) - - \\[([\\w:/]+).*\\] \"(\\w+) /(\\w+).*(\\d.+)\" (\\d{3}) (\\d+) \"(\\S+)\" \"(.*?)\" ([\\d.]+) \"(.*?)\" (\\d+);(\\d+)",
"customFieldNames": ["client_ip", "time_stamp", "verb", "uri_path", "http_ver", "http_status", "bytes", "referrer", "agent", "response_time", "graphql", "company_id", "user_id"]
}]
}
3. Amazon Kinesis Agent始動
以下のコマンドでagentを動かします。
sudo service aws-kinesis-agent start
これで終わってもいいのですが、Agentのログファイルでしっかり動いていることを確認しましょう。
tail -f /var/log/aws-kinesis-agent/aws-kinesis-agent.log
tailコマンドを利用してAgentの活動ログを監視します。無事動いているようなら
2017-09-08 08:47:29.734+0000 ip-10-0-0-226 (Agent.MetricsEmitter RUNNING) com.amazon.kinesis.streaming.agent.Agent [INFO] Agent: Progress: 9135 records parsed (1257812 bytes), and 9132 records sent successfully to destinations. Uptime: 88380043ms
このようなログが定期的に流れてきます。
考えられるエラーと解決方法を紹介します
agentがログファイルを読めていない
考えれる原因の考えられる原因は、
- ログファイルへのフルパスが間違えている
- ログファイルを読む権限がない
1.のフルパスが間違えている場合は、先程のagentの設定ファイルで変更した。"filePattern"のパスに問題があることになるので、そのパスが実際存在するか確認しましょう。
tail ログファイルへのパス
file does not exists 的なメッセージがでたらファイルが存在しないということなので正しいログファイルへのフルパスに変えてあげましょう。
2.のログファイルを読む権限がない場合は、agentがログファイルを読み込めれるように
sudo chmod o+r ログファイルへのパス
で誰でもログファイルを読めるようにしましょう。(インフラエンジニア的にこれはありなのか疑問)
ログデータの送り先が不在
これが該当する場合は、確か404のエラーコードを大量にログファイルに出力されます。
この場合は、agentのログファイルのdeliveryStreamのプロパティの名前と一番初めに作成したAmazon Kinesis Firehoseの名前があっていることを確認しましょう。
それがタイポもない場合はagentを再インストールしたらなおるかもしれません。
アクセスキーとシークレットキーがみつからない
credentialsなのでAWSのアクセスキーとシークレットキーが見つからない方は、awsのcredentialsに登録してもいいですが、確実なのはagentの設定ファイルで設定することです。
{
"awsAccessKeyId": "あなたのアクセスキー",
"awsSecretAccessKey": あなたのシークレットキー
}
ステップ3:Amazon Elasticsearch Serviceドメインの作成
- Elasticsearchのページに行き、新たなドメインを作成するためにGet StartもしくはCreate a new domainのボタンをクリックします。
- はじめにドメインに名前をつけます。他と同じくなんでも構いませんが、何をつければいいのかがわからない方は「log-summary」にでもしましょう。
- 次の選択肢はElasticsearchのバージョンですが、特にこだわりがないかたは最新でものでいいと思います。なのでそのままにして、Nextボタンをおしましょう。
- 次の設定も同じく特にこだわりがない方はそのままにしておいて、Nextボタンをおして次にいってください。
- その次では、このElasticsearchへのアクセスを制限をします。Templateから簡単に設定ができますのでそちらから各自設定してください。難しいことはわからないしめんどくさいのも嫌な方はTemplateからAllow open access to the domainを選択してください。こちらは特に制限なくアクセスが可能になるのでAWS側ではおすすめしていません。重要なデータをお使う場合は必ずきちんと設定しましょう。
- 次の画面でもろもろの設定を確認してConfirmボタンをおしましょう。そうすればElasticsearchドメインが作成されます。(起動までしばらく時間がかかります)
ステップ3:二つ目のFirehoseの作成
次に先程作成したAmazon Elasticsearch Serviceへデータを送るためにfirehoseを作成します。これは、EC2から一つ目のFirehoseを通じ、(まだ作ってない)Amazon Kinesis Analyticsにより処理された情報をElasticsearchに送るためのFirehoseです。
-
Amazon Kinesis へアクセスします。
- Firehoseへ行き、 Create Deliver Stream(デリバリーストリームを作成) ボタンを押し作成します。
-
Delivery stream nameを入力しますが、ここはこのFirehoseの名前なのでなんでも構いません。何を入力すればよいかわからない方は 「log-summary-stream」としましょう。
- 次に情報元をDirect PUT or other sources(直接のPUTまたは他の情報源)に選択します。
- 一番下まで行き、Nextボタンを押します。押した後、次の選択肢はデフォルトのDisabledを選択します。
- Nextボタンを押し、次は送り先(Destination)をAmazon Elasticsearch Serviceに選択します。
- 送り先のElasticsearchとして、先ほど作成したドメインを選択します
- Indexは、request_dataにして、typesはrequestsにします。その他のIndex RotationとRetry durationはそのままにしておいてください。
- Elasticsearchに送るのを失敗した場合にS3にバックアップとしてデータを送ります。Backup S3 bucketとして新しく、バケットを作成しましょう。名前はなんでも構いませんが、思いつかない方は「log-summary-failed」とでもしておいてください。
- Nextボタンを押し、一番したまで行けば、IAM roleをしていするフォームがありますので、Create new or Chooseボタンを押しましょう。
- タブが開けば、Create new IAM roleを選択したまま他はデフォルトで右下のAllowを押します。
- 完了すればNextを押し確認に問題がないようでしたらCreate delivery streamボタンを押し、作成します。
ステップ4: Amazon Kinesis Analytics を作成
Amazon Kinesis Analyticsでははじめに作成したEC2からログデータを取ってくる一つ目のFirehoseと先ほど作成したElasticsearchを目的地にしている二つ目のFirehoseの中間にあるものになります。つまりは一つ目のFirehoseからログ情報を所得し、それを処理した後、二つ目のFirehoseに渡しそれがElasticsearchへ流れ着きます。では実際に作っていきましょう。
- Amazon Kinesis Analyticsへアクセスする。
- Create Applicationに行き、Applicationの名前をつけます。何をつければいいかわからない方は、log-aggregationとでもしておいてください。なんでも構いません。
- Descriptionの方も何か書きておいた方は書いていただき、特にわからない方は空欄のままCreate Applicationボタンをおしましょう。
情報元(Source)を選択する
- 作成した後、作成されたアプリケーションのホームページに行くと思います。 そのままConnect to a sourceボタンをおして情報元を選択します。
- 情報元を選択するページに行くと2つのFirehoseの名前が出てくると思いますが、ここのステップのはじめにも紹介したように一つ目のFirehose(EC2から情報を取ってきている方)を選択してください。
- 選択した後しばらく待つと、流れてきているログをAnalyticsアプリケーションが所得するので、それが確認出来しだいSave and continueボタンをおしましょう。
SQLを使用して処理をする
今まではクリックするだけだっだのですが、ここがおそらく最も大変なところです。SQLをもともとちゃんと書けるエンジニアは簡単に実装できていいじゃんという感じですが、私みたいなエセエンジニアは困ったものです。
Go to SQL editorでFirehoseにホーム画面からSQLおエディターに移動できます。
ここで好きなようにデータを処理変更してくださいと言っても何をどうすればいいかわかんない方がいると思います。
このSQLではtableの代わりにstreamを変更します。SOURCE_SQL_STREAM_001が情報が流れているstreamでこちらからログ情報を取ってきて、処理をしDESTINATION_SQL_STEAMという名前のストリームに変換します。そうしたらそのストリームを次のFirehoseに送ってくれます。
以下に一つの処理方法の例を載せておきます。これはresponseというカラムの数の合計をstatusCountに入れています。つまりresponse(200, 404とか)の数をまとめて数を数えているということです。
ここからわかることは、"(ダブルクオーテーションマーク)で囲むことで、SOURCE_SQL_STREAM__001のカラムの値が手に入ることです。
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (
datetime VARCHAR(30),
status INTEGER,
statusCount INTEGER);
CREATE OR REPLACE PUMP "STREAM_PUMP" AS
INSERT INTO "DESTINATION_SQL_STREAM"
SELECT
STREAM TIMESTAMP_TO_CHAR('yyyy-MM-dd''T''HH:mm:ss.SSS',
LOCALTIMESTAMP) as datetime,
"response" as status,
COUNT(*) AS statusCount
FROM "SOURCE_SQL_STREAM_001"
GROUP BY
"response",
FLOOR(("SOURCE_SQL_STREAM_001".ROWTIME - TIMESTAMP '1970-01-01 00:00:00') minute / 1 TO MINUTE);
こちらが僕が実際に使っているコードです。 SOURCE_SQL_STREAM_001のdatetimeのフォーマットyyyy-MM-dd''T''HH:mm:ss.SSSのように変換してElasticsearchへ保存しています。
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (
datetime VARCHAR(30),
host VARCHAR(16),
request VARCHAR(32),
response INTEGER,
bytes INTEGER,
agent VARCHAR(32));
CREATE OR REPLACE PUMP "STREAM_PUMP" AS
INSERT INTO "DESTINATION_SQL_STREAM"
SELECT
STREAM
TIMESTAMP_TO_CHAR('yyyy-MM-dd''T''HH:mm:ss.SSS', CHAR_TO_TIMESTAMP('dd/MMM/yyyy:HH:mm:ss Z', "datetime")) as datetime,
"host" as host,
"request" as request,
"response" as response,
"bytes" as bytes,
"agent" as agent
FROM "SOURCE_SQL_STREAM_001"
より詳しくは公式ページドキュメントを参照してください。
コメントで質問していただければ頑張って答えます。
目的地を選択する
そのままDestinationタブを選択して、処理された情報の送り先を選択します。Select a streamから二つ目のFirehose(Elasticsearchにつながっている方)を選択し、他のものはそのままでSave and continueをクリックしましょう。
これで全てのパイプラインは繋がり作業はほとんど完成です。
ステップ5:Kibanaで可視化されたデータをみる
Amazon Elsacticsearch serviceにはデータを可視化してくれるKibanaが含まれています。
Elasticsearchの作成したドメインのホーム画面に行きkibanaという文字の横にリンクが有ると思います。そこをクリックするとKibinaのページに飛びます。はじめて訪れた場合はindex-patternを入力しなければなりません。そこにはrequest_dataと入力してください。
仮に、request_dataと入力しても続けれない方はしばらく時間をおいてみてもう一度試してください。データがElasticsearchに貯まるまで時間がかかるためだと思われます。
KibanaはDatetimeのカラムを自動で認識します。ただし、フォーマットに制限があるらしくyyyy-MM-dd''T''HH:mm:ss.SSSのような形で情報を保存すればKibanaは必ずDatetimeだと認識します。
そのまま続行を押すとKibanaのサイトで自由に可視化されたデータをみれます。
長い作業、お疲れ様でした。他にはAmazon Kinesis Analyticsでデータを複雑に処理をしたりも可能なので挑戦してみてください。
編集リクエストお待ちしております。m(_ _)m