この記事はアラタナアドベントカレンダー6日目の記事になります。

みなさんリングフィットアドベンチャーしてますか?
僕はめちゃくちゃやりまくりたいけど30分もたずにダウンしちゃいます。
プレイ終了のときに今回どれだけ運動できたか記録が出るのですが、僕はそこでスマホで写真を撮ります。(Switch初心者で画面キャプチャできるの知らなかった人です)
↓こんなやつです
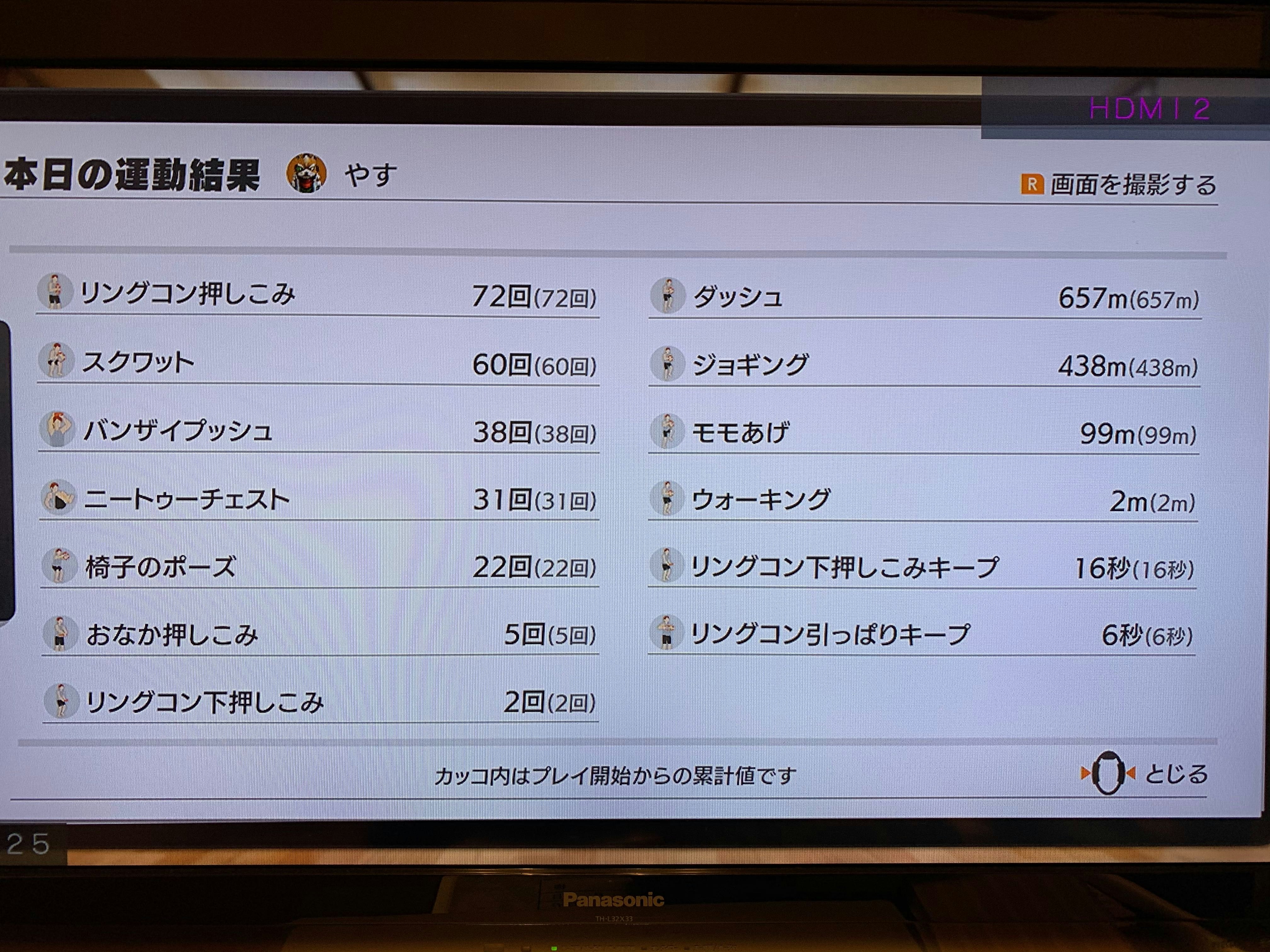
Switch初心者ゆえに知らないだけかもしれないのですが記録のエクスポートは出来ないっぽかったです。
どれだけ自分が努力できたか数字が欲しくなったので、今回は写真から文字起こししてくれるOCRを使って記録をとってみようと思います。
準備
brew install tesseract
pip install pyocr
実践
オープンソースのOCRツールTesseractをラップするpyocrを使います。
ひとまず画像を読み込んでOCRかけてみます。
from PIL import Image
import pyocr
import pyocr.builders
image = Image.open("image_path")
tools = pyocr.get_available_tools()
tool = self.tools[0]
result_ocr = self.tool.image_to_string(
image,
lang="jpn",
builder=pyocr.builders.TextBuilder(tesseract_layout=6))
print(result_ocr.splitlines())
本 日 の 運 動 総 果 暮 ゃ す
リ ン ク コ ン 挫 し こ み _
で ス ク ワ ッ ト
ー バ パ ン ザ イ プ ッ シ ュ
ト ニ ー ト ゥ ー チ ェ ス ト
ー 椅 子 の ポ ー ズ
で お な か 押 し こ み ー
_ /② 団 ② 回
⑥0 回 (eom
③⑧ 回 (③⑧ 四 )
③① 回 G 四
②② 回 (②② 因 )
⑤ 回 ⑤ 四
ー ② 因 ② 回
ダ ッ シ ュ ー
ジ ョ ギ ン グ
モ モ あ げ
ウ ォ ー キ ン グ
リ ン グ コ ン 下 押 し こ み キ ー プ
m ⑤ パ ー
圓 画 面 を 播 影 す る
⑥⑤⑦m(⑥⑤zm)
ー m(④⑤⑧m
⑨⑨m(gom)
_②m(②m)
⑯ 秋 ⑯ 功
ー ー ⑤ 程 (⑥ 功
峡0縄 と じ る
ひどいですね!
ひどいですがとりあえずOCR自体は成功ということで、、、
文字間の空白が気になりますね、次はこの空白をどうにかします。
tesseractには空白を詰めることのできるオプションがあるようです。
-c preserve_interword_spaces=1
オプションを指定する記述をpyocrのソースから見つけることができたので使ってみます。
builder = pyocr.builders.TextBuilder(tesseract_layout=6)
builder.tesseract_configs.append('-c')
builder.tesseract_configs.append('preserve_interword_spaces=1')
本日の運動総果 暮 ゃす
リンクコン挫しこみ_
で スクワット
ー バパンザイプッシュ
ト ニートゥーチェスト
ー 椅子のポーズ
で おなか押しこみ ー
_ /②団②回
⑥0回(eom
③⑧回(③⑧四)
③①回G四
②②回(②②因)
⑤回⑤四
ー ②因②回
ダッシュ ー
ジョギング
モモあげ
ウォーキング
リングコン下押しこみキープ
m ⑤パー
圓 画面を播影する
⑥⑤⑦m(⑥⑤zm)
ー m(④⑤⑧m
⑨⑨m(gom)
_②m(②m)
⑯秋⑯功
ー ー ⑤程(⑥功
峡0縄 とじる
文字間の空白がなくなりました。
そろそろOCR自体の精度が気になります。
とりあえず前処理を追加してみます。
ついでに余計な空白がなくなったのでsplitline()からsplit()に変更しました。
im_blur = cv2.GaussianBlur(image, (5, 5), 0)
_, image = cv2.threshold(im_blur, 0, 255, cv2.THRESH_OTSU)
ガウシアンフィルタでノイズ除去と、大津の二値化の処理を加えました。
ひとつめがsplit()する前で、ふたつめがsplit()した後のものです。
本日の逼動総果 慰 ゃす ` 画面を掘影する
。 リングコン押しこみ ⑦②回(⑦②四) ・ ダッシュ ⑥⑤⑦m(⑥⑤⑦m)
“ スクワット ⑥0回(⑥ol) ・ ジョギング ④③⑧m(④③⑧m)
` バンサザイプッシュ ③⑧回(③⑧吏) * モモあけげ ⑨⑨m(⑨⑨m)
ゃ ニートゥーチェスト ③①回(③①i団) ・ ウォーキング ②m(②m)
・ 椅子のポーズ ②②回(②②四) ・ リングコン下押しこみキープ ⑯秋⑯役)
ゅ おなか押しこみ ⑤回(⑤四) 。 リングコン引っぱりキープブ ⑥秋(⑥君)
・ リングコン下押しこみ ②回(②回)
_ カッコ内はプレイ開始からの累計価です 〔`。〈 とじる
‥* レー顕談シショコープー ー ー ・喪談e
['本日の逼動総果', '慰', 'ゃす', '`', '画面を掘影する', '。', 'リングコン押しこみ', '⑦②回(⑦②四)',
'・', 'ダッシュ', '⑥⑤⑦m(⑥⑤⑦m)', '“', 'スクワット', '⑥0回(⑥ol)', '・', 'ジョギング', '④③⑧m(④③⑧m)',
'`', 'バンサザイプッシュ', '③⑧回(③⑧吏)', '*', 'モモあけげ', '⑨⑨m(⑨⑨m)', 'ゃ', 'ニートゥーチェスト'
, '③①回(③①i団)', '・', 'ウォーキング', '②m(②m)', '・', '椅子のポーズ', '②②回(②②四)', '・', 'リング
コン下押しこみキープ', '⑯秋⑯役)', 'ゅ', 'おなか押しこみ', '⑤回(⑤四)', '。', 'リングコン引っぱりキ
ープブ', '⑥秋(⑥君)', '・', 'リングコン下押しこみ', '②回(②回)', '_', 'カッコ内はプレイ開始からの累
計価です', '〔`。〈', 'とじる', '‥*', 'レー顕談シショコープー', 'ー', 'ー', '・喪談e']
運動の種類と回数がパット見でもわかるようになりましたね。
1が①のようになっているのはtesseractの仕様みたいなので、プログラム内でマッピング処理を書いちゃおうと思ったのですが、使えそうな関数があったので使ってみました。
unicodedata.normalize()
あとは運動と回数をそれぞれ雑に取り出します。
target_list = [
"スクワット", "リングコン押し込み", "ダッシュ", "ジョギング", "バンザイプッシュ", "モモあげ",
"ニートゥーチェスト", "ウォーキング", "椅子のポーズ", "リングコン下押しこみキープ", "おなか押しこみ",
"リングコン引っ張りキープ", "リングコン下押しこみ"
]
result = []
for target in target_list:
s = []
for j, line in enumerate(texts):
s.append(
difflib.SequenceMatcher(a=target, b=line).ratio())
result.append(texts[s.index(max(s)) + 1].split('(')[0])
最後に実行するたびに追記していくようにしたものがこちらです。
{
"0": {
"スクワット": "60回",
"リングコン押し込み": "72回",
"ダッシュ": "657m",
"ジョギング": "438m",
"バンザイプッシュ": "38回",
"モモあげ": "99m",
"ニートゥーチェスト": "31回",
"ウォーキング": "2m",
"椅子のポーズ": "22回",
"リングコン下押しこみキープ": "16秋16役)",
"おなか押しこみ": "5回",
"リングコン引っ張りキープ": "6秋",
"リングコン下押しこみ": "2回"
},
"1": {
"スクワット": "60回",
"リングコン押し込み": "72回",
"ダッシュ": "657m",
"ジョギング": "438m",
"バンザイプッシュ": "38回",
"モモあげ": "99m",
"ニートゥーチェスト": "31回",
"ウォーキング": "2m",
"椅子のポーズ": "22回",
"リングコン下押しこみキープ": "16秋16役)",
"おなか押しこみ": "5回",
"リングコン引っ張りキープ": "6秋",
"リングコン下押しこみ": "2回"
}
}
同じ画像で実行したため2回とも同じ回数で記録されていますが、追記できました。
"リングコン下押しこみキープ": "16秋16役)",
一部きれいに取得できてなかったり”回”が認識できてないところもあるのですが一旦良しとしちゃいます。
まとめ
今回はocr部分をpyocr(tesseract)に完全に乗っかったため、上記のような”回”を”秋”としてしまっているところなどどうすれば改善できるかは考えなかったのですが、次は認識精度向上もやってみたいですね。
ただ今回ocrを初めてやってみて、変な空白が入るのどうしよう…?前処理しないと精度よくならない…?など壁にぶつかるたびに対応を考えるのは楽しかったし勉強になりました。
csv出力や合計値の出力など、もう少し機能追加していきたいと思います。