はじめに
こんにちは、なじむです。
これまで土日にまとめて確認していたんですが、平日夜にコツコツやる方が健康的かもしれないと思い始めたので、可能な限りコツコツやっていこうと思います。
というわけで今年も張り切ってやっていきましょう!AWS Japan さんがまとめている週刊AWSで確認した内容の自分用メモ。
今回は1/10週のアップデートです。
1/10(月)
Amazon RDS for MySQL が、新しいマイナーバージョン (5.7.36 および 8.0.27) のサポートを開始
RDS はリレーショナルデータベースのマネージドサービスです。
RDS for MySQL で以下のマイナーバージョンが新しく利用可能になりました(本家で 2021/10/19 に GA となったものが、本アップデートにより利用可能になりました)
主なアップデートは以下です。詳細はリンク先のリリースノートを参照ください。
-
Changes in MySQL 5.7.36 (2021-10-19, General Availability)
- OpenSSL ライブラリのバージョンアップ(1.1.1l)
- 多数のバグフィックス
-
Changes in MySQL 8.0.27 (2021-10-19, General Availability)
- 監査ログの出力誤りを修正
- MFA認証のサポート
- C++17 コンパイラのサポート
- OpenSSL ライブラリのバージョンアップ(1.1.1l)
- 多数のバグフィックス
- etc…
実際の画面は以下です。
それぞれのマイナーバージョンの RDS for MySQL が利用可能になっています。
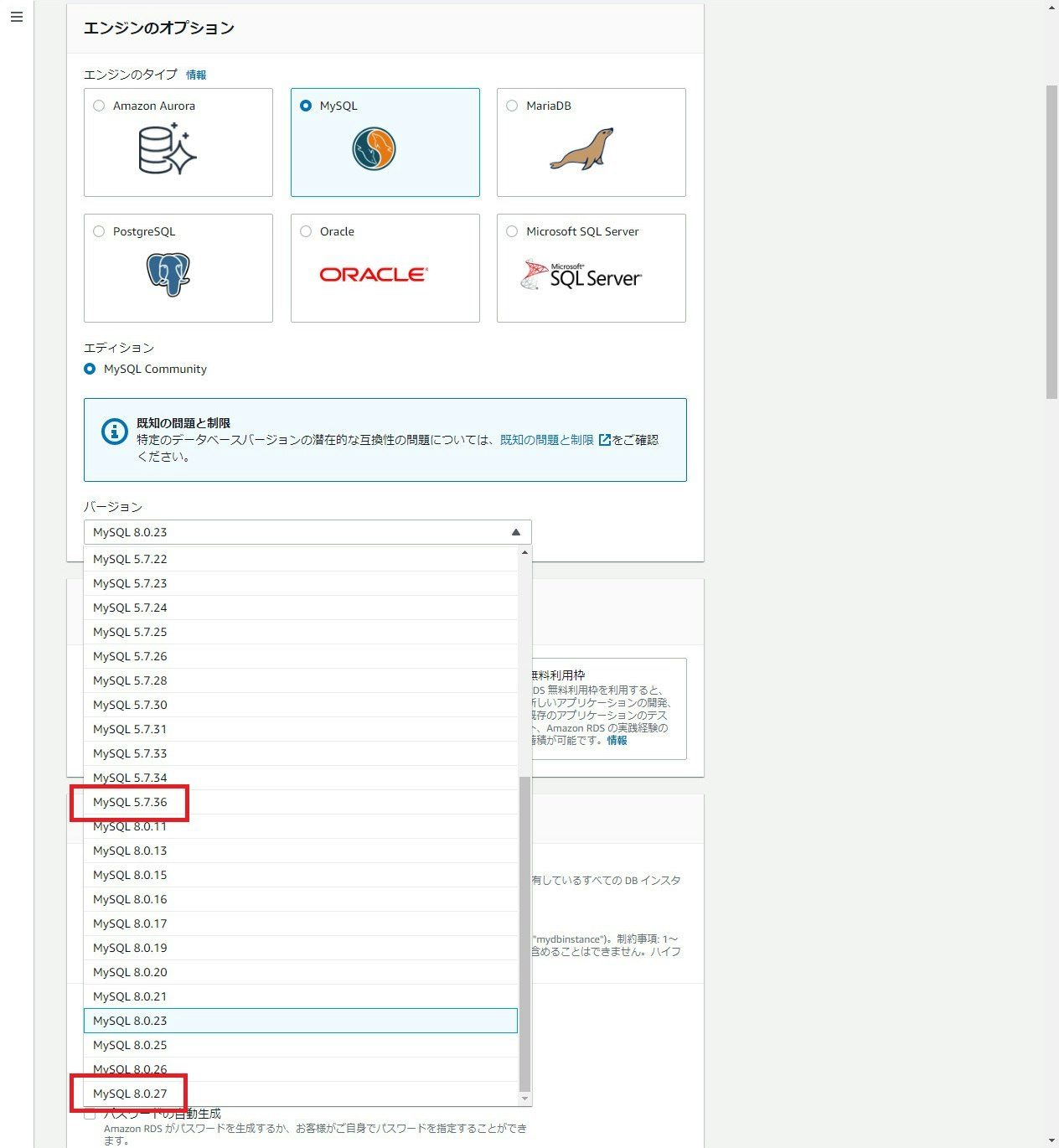
- 日本リージョン対応状況
- 東京:対応
- 大阪:対応
Amazon EC2 Hpc6a インスタンスのご紹介
EC2 は仮想マシンのサービスです。
本アップデートでは、EC2 でハイパフォーマンスコンピューティング (HPC) 向けに最適化された Hpc6a インスタンスタイプが新しく利用可能になりました。これまで、HPC 向けには EFA 対応の EC2 (C5n、R5n、M5n、 M5zN など)を使用していましたが、非常にコストがかかっていました。Hpc6a インスタンスに切り替えることにより、最大 65% 優れたコストパフォーマンスになったようです。
HPC 向けということもあり、めちゃくちゃ大きいインスタンスですね!そしてこのサイズ1つしかないんですね。
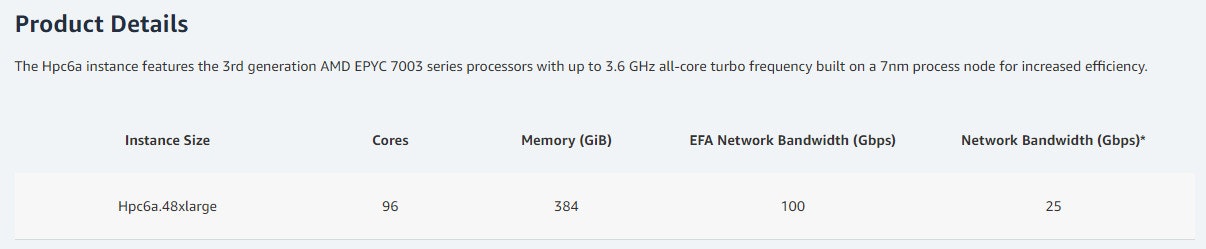
(出典) Amazon EC2 Hpc6a Instances
日本のリージョンが未対応(米国東部(オハイオ)、GovCloud(米国西部)のみ対応)だったため実際のキャプチャは取得していません。詳細は公式ブログを参照ください。
(参考) ハイパフォーマンスコンピューティング向けに最適化された Amazon EC2 HPC6a インスタンス
EC2 のインスタンスタイプと追加情報の説明の一覧(AWS公式ドキュメント)ってないのかな…
- 日本リージョン対応状況
- 東京:未対応
- 大阪:未対応
1/11(火)
Amazon Redshift Spectrum がカスタムデータ検証ルールを提供
Redshift Spectrum は S3 上のデータを直接 Redshift からクエリできるようにするサービスです(※通常は S3 上のデータを Redshift に取り込んでクエリをかける必要があります)。Redshift Spectrum を使用することにより、ロードの手間を減らす、S3 と Redshift の両方にデータがあること(コストが二重にかかること)を防ぐといったことが可能になります。
(出典) データウェアハウスをエクサバイト級に拡張するAmazon Redshift Spectrum
本アップデートでは、Redshift Spectrum で使用する外部スキーマに以下のような TABLE PROPERTIES を設定し、カスタムデータ検証ルールが設定できるようになりました。
| TABLE PROPERTIES | 説明 |
|---|---|
| surplus_char_handling | VARCHAR、CHAR、および文字列データを含む列の余剰文字の入力処理を指定 |
| invalid_char_handling | VARCHAR、CHAR、および文字列データを含む列の無効な文字の入力処理を指定 |
| numeric_overflow_handling | 整数および小数のデータを含む列でキャストオーバーフロー処理を指定 |
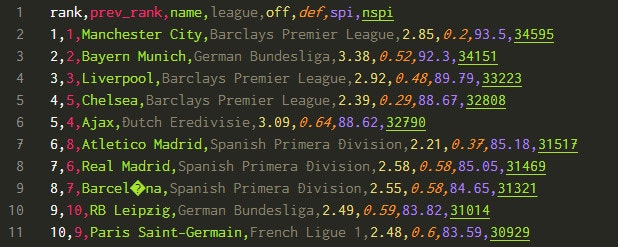
例えば、以下のように文字化けしているデータ(9行目 (#8) )があった時に、そのデータをどう扱うか(任意の文字に置き換えるのか、行を表示しないのか等)を指定できるようになった感じです。
Redshift Spectrum 環境構築の流れは以下です。
- Redshift クラスターの構築 ※詳細は割愛
- Redshift クラスターへの IAM ロールの紐づけ(S3 への Read 権限) ※詳細は割愛
- S3 へのデータ格納 ※ spi_global_rankings.csv を使用
- Redshift Spectrum 用の外部スキーマの作成
- クエリの実行
今回は例として invalid_char_handling を設定した場合と設定しない場合で検証していきます(上述の手順の 4, 5 のみ実施します)
※ 3 のデータは "s3://nagym-redshift-spectrum/" に格納して使用しました。皆さんがやる場合はそれぞれの環境用に置き換えてください。
- invalid_char_handling を設定しない場合
4.外部テーブルの作成
CREATE EXTERNAL TABLE schema_spectrum_uddh.soccer_league
(
league_rank smallint,
prev_rank smallint,
club_name varchar(15),
league_name varchar(20),
league_off decimal(6,2),
league_def decimal(6,2),
league_spi decimal(6,2),
league_nspi smallint
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n\l'
stored as textfile
LOCATION 's3://nagym-redshift-spectrum/'
table properties ('skip.header.line.count'='1');
5.クエリの実行
select league_rank,club_name,league_name,league_nspi
from schema_spectrum_uddh.soccer_league
where league_rank between 1 and 10;
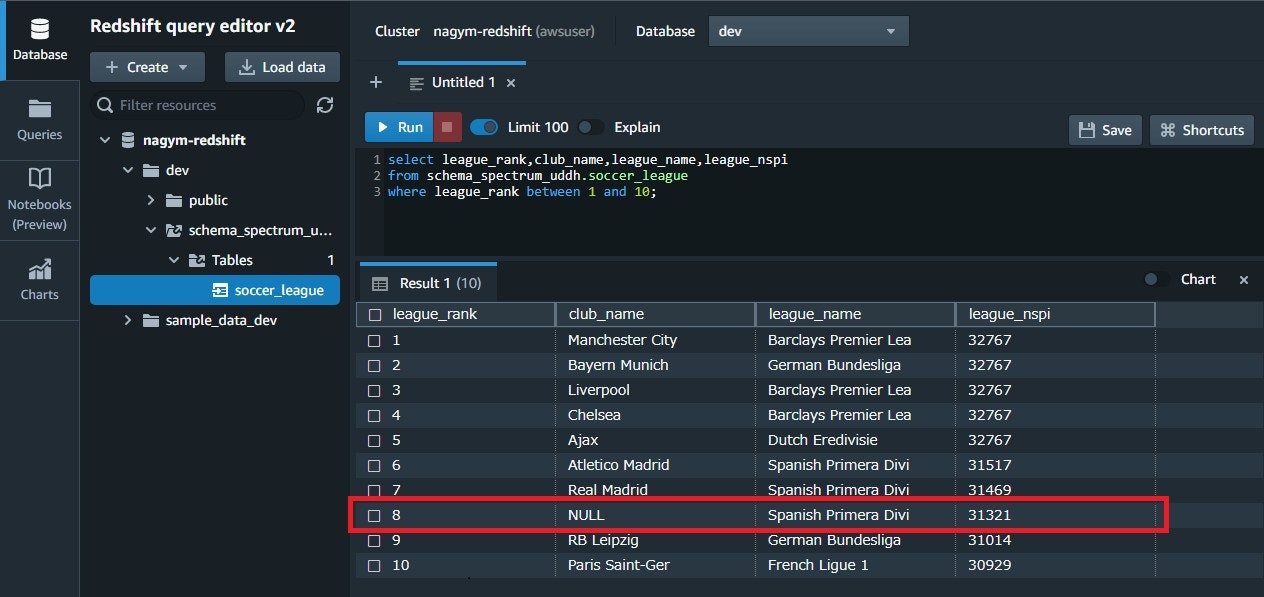
6.結果確認
8 行目の "club_name" が "NULL" になっていることが分かります。
- invalid_char_handling で無効な文字を "?" で置換する場合
4.外部テーブルの作成:"invalid_char_handling'='REPLACE','replacement_char'='?','data_cleansing_enabled'='true'" を追加
CREATE EXTERNAL TABLE schema_spectrum_uddh.soccer_league2
(
league_rank smallint,
prev_rank smallint,
club_name varchar(15),
league_name varchar(20),
league_off decimal(6,2),
league_def decimal(6,2),
league_spi decimal(6,2),
league_nspi smallint
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n\l'
stored as textfile
LOCATION 's3://nagym-redshift-spectrum/'
table properties ('skip.header.line.count'='1','invalid_char_handling'='REPLACE','replacement_char'='?','data_cleansing_enabled'='true');
5.クエリの実行
select league_rank,club_name,league_name,league_nspi
from schema_spectrum_uddh.soccer_league2
where league_rank between 1 and 10;
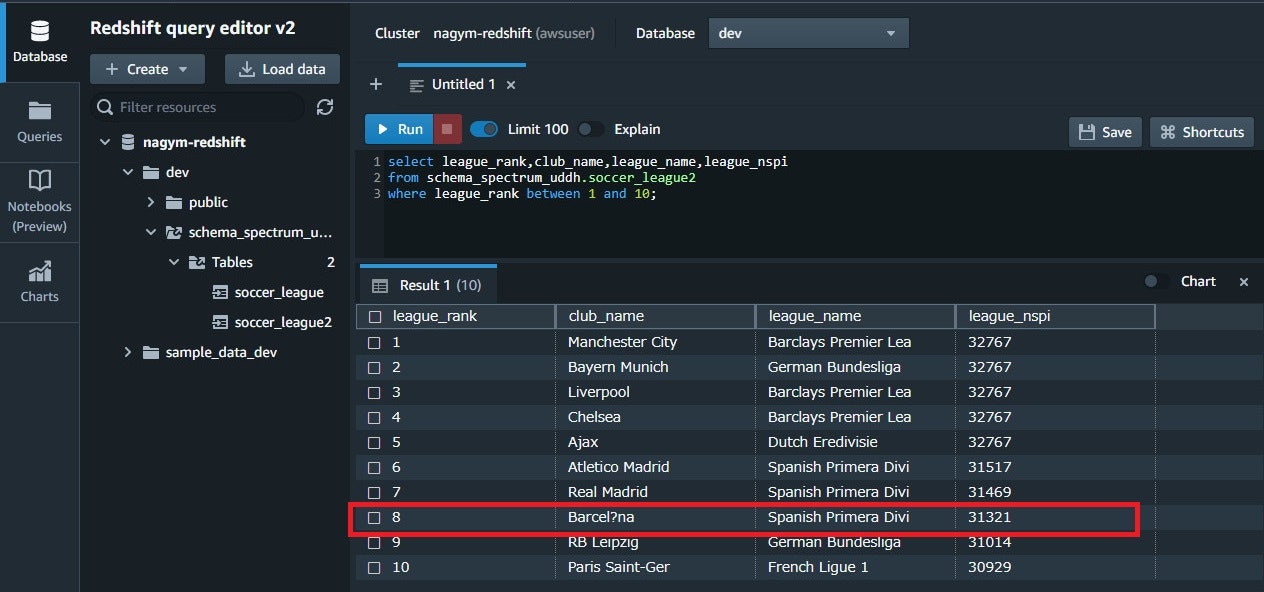
6.結果確認
8 行目の "club_name" が "NULL" から "Barcel?na" になっていることが分かります。データ検証ルールが働いていますね。
データ検証ルールを設定することで、想定外の値が入っていた際の動作を設定できるようになりました。今回の検証は以下ドキュメントを参考にしましたが、上述の例以外も載っているのでぜひご覧ください。
(参考) Data handling examples
これちゃんと1本ブログ書ける量だよな…
- 日本リージョン対応状況
- 東京:対応
- 大阪:対応
AWS が、Amazon EC2 上の Microsoft Windows Server インスタンス向けの新しい起動速度の最適化を発表
EC2 は仮想マシンのサービスです。
本アップデートでは、Windows Server の AMI に設定を加えることで、その AMI から起動される EC2 の起動時間を 65% 早くする機能が利用可能になりました。これにより、急なスケールアウトや障害時の復旧をより迅速に行うことができるようになりました。
設定のための流れは以下です。Sysprep を使用した AMI の作成方法は以下を参照ください。
(参考) Sysprep を使用して標準化された Amazon マシンイメージ (AMI) を作成する
- [Shutdown with Sysprep] を実行して Windows AMI を作成する
- Windows AMI で [Enable windows faster launching] を有効にする
- フラグを有効にした Windows AMI から EC2 を起動する
また、設定にあたり以下の注意事項があるのでご注意ください。
- デフォルト VPC が設定されていること(これ何で必要なんだろう…)
- 当該 AWS アカウントで、Windows AMI を所有していること
- [Shutdown with Sysprep] を実行して Windows AMI を作成していること(先のとおり)
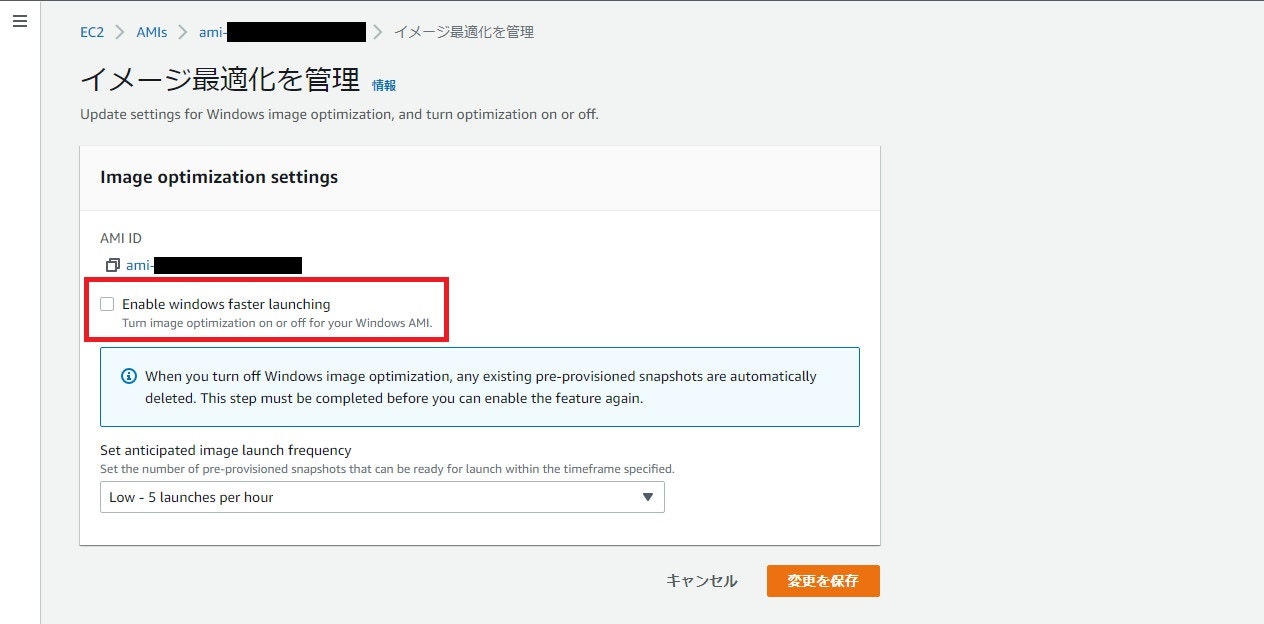
実際の画面は以下です。
AMIを選択し、[アクション] > [イメージ最適化を管理] から [Enable windows faster launching] を設定できます。
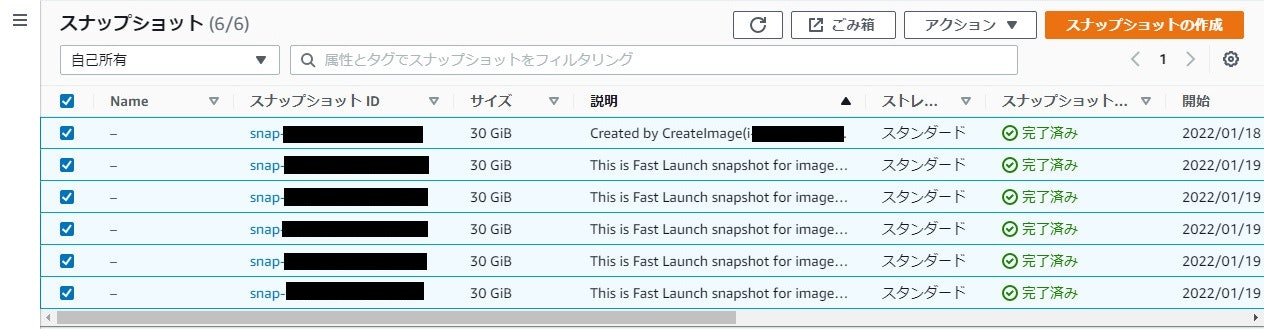
ちなみに、この設定を有効にするとスナップショットが大量に増えました。どういう仕組み何だろう…?
実際の起動時間を計っておらず何とも言えないので、誰か計ってくれれば…
- 日本リージョン対応状況
- 東京:対応
- 大阪:対応
SQL Explorer in EMR Studio の紹介
EMR Studio は R、Python、Scala、PySpark で記述されたアプリケーションのための統合開発環境 (IDE) です
本アップデートにより、EMR Studio で EMRクラスタに対して SQL クエリを実行できる SQL Explorer が利用可能になりました。
利用までの流れは以下です。
- EMR on EC2 クラスター(EMR:6.4.0 以上、Presto:0.254.1 以降)を作成する
- EMR Studio を作成する
- EMR Studio WorkSpace を作成する
- EMR Studio WorkSpace にアクセスする
- EMR on EC2 クラスターを EMR Studio WorkSpace にアタッチする
- SQL Explorer を開き、クエリを実行する
実際にクエリを実行した画面は以下です。
何のデータも入っていなかったので面白味のない画面になってしまいました…
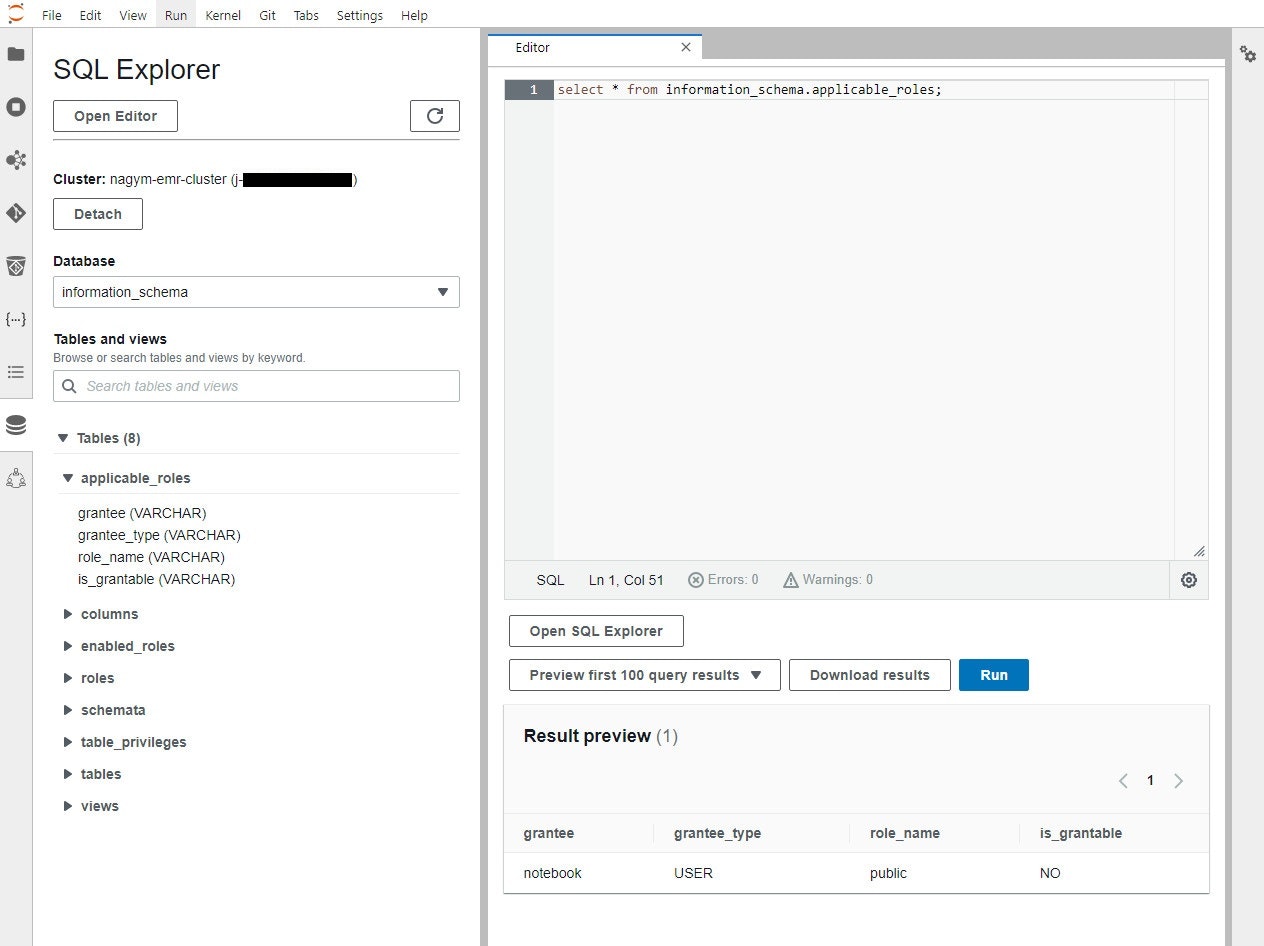
文法を記載したドキュメントを見つけられなかったので分かりませんが、普通の SQL なら全部使えるんだろうか…?
- 日本リージョン対応状況
- 東京:対応
- 大阪:未対応
1/12(水)
AWS Launch Wizardは、パフォーマンス要件の増加に対応するためのHANAベースのSAP派遣のスケーリングをサポートするようになりました
Launch Wizard はサードパーティ製品を迅速、簡単にデプロイするためのサービスです。
Launch Wizard for SAP を使用することで、これまで数週間かかっていた SAP 環境の構築が数時間で完了し、また SAP のエンジニアと連携の手間もなくなります。本アップデートでは、Launch Wizardを使用してデプロイされたSAPシステムに対して、Launch Wizardを使用してノードを追加することが可能になったようです。
SAP 全然分からないので構築していないんですが、SAP on AWS の試験も今年から始まるしこの辺も理解していかないといけないんだろうな…
徐々に身に着けていきます…
- 日本リージョン対応状況
- 東京:対応
- 大阪:対応
AWS マネジメントコンソールで新しいコンソールホームを発表
マネジメントコンソールが新しくなりました。
従来のコンソールと比較するとだいぶ変っています。
- 旧コンソール:各サービスへのアクセスがしやすかった
- 新コンソール:コストや Health 等がログインした瞬間にパッと分かるようになった
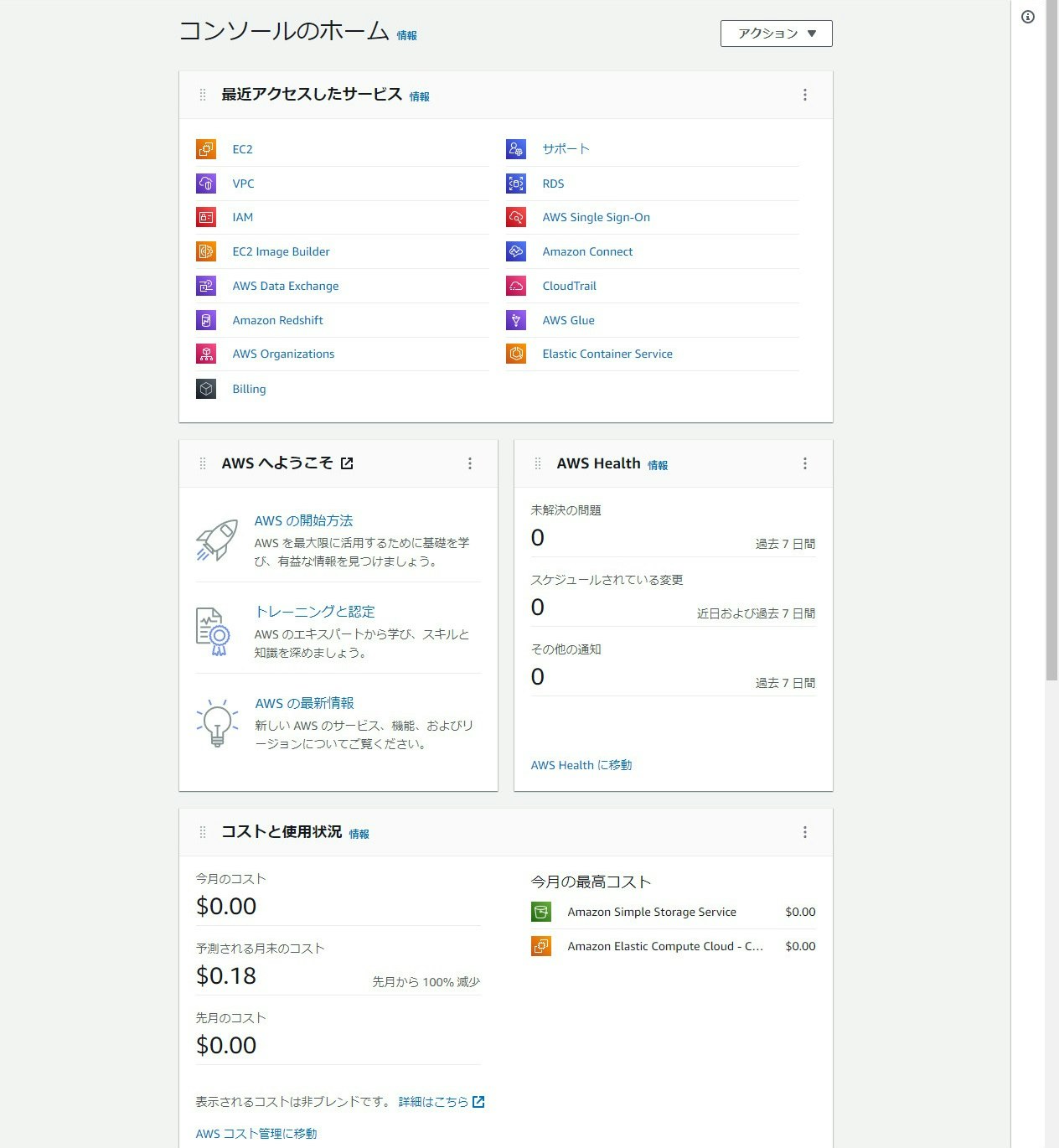
ホーム画面に "コストと使用状況" や "AWS Health" 等を表示でき、パッと環境のサマリが見れるようになりました。現時点で追加できるウィジェットは少ないですが、今後追加されていくものと思います。
ちなみに、例えばBillingの参照権限がないと、トップページの Widget に権限がない旨のエラーが表示され、値を見ることができないのでご注意ください。
- 日本リージョン対応状況
- 東京:-
- 大阪:-
1/13(木)
Amazon ElastiCache が Redis エンジンログのストリーミングと保存のサポートを追加
ElastiCache for Redis は Redis 互換のインメモリデータストアのマネージドサービスです。例えば、データストアの前に ElastiCache for Redis を置くことにより、アプリケーションから受け付けたリクエストをキャッシュし、次回以降のリクエストを ElastiCache for Redis から返すことでパフォーマンスを向上することができます。
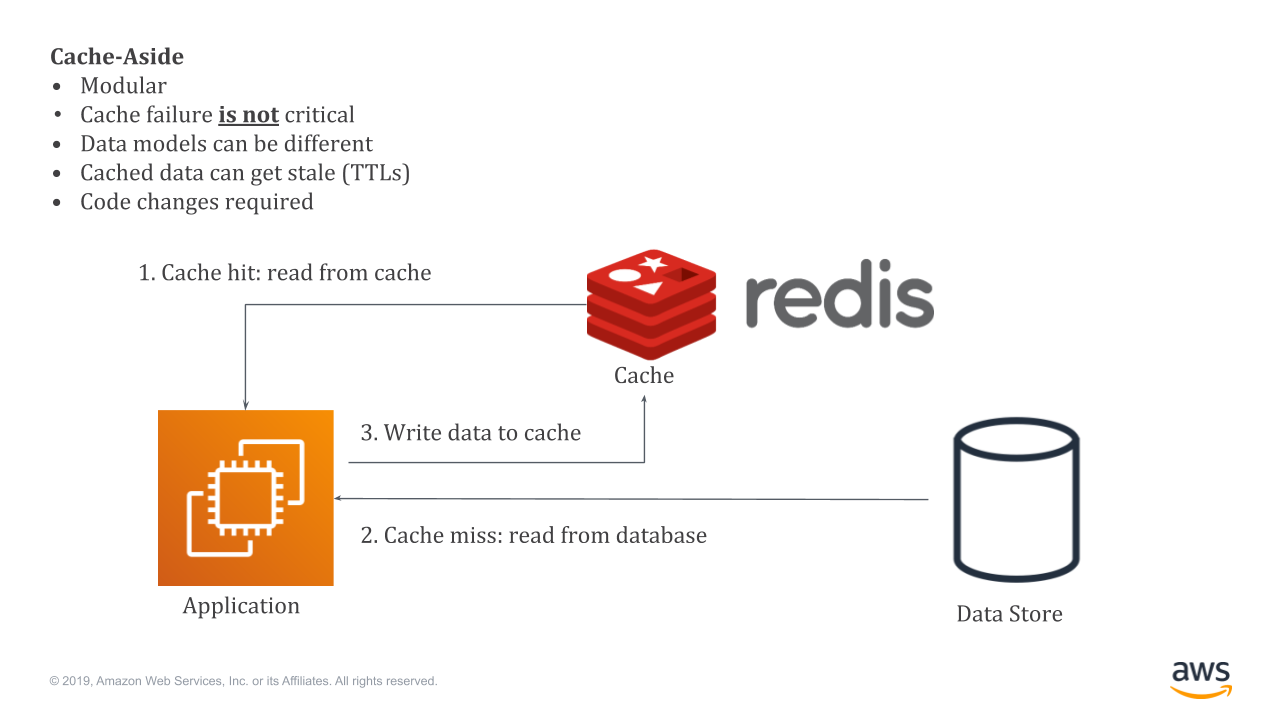
(出典) Amazon ElastiCache for Redis を使い、MySQL データベースのパフォーマンスを向上させる
Redis のエンジンログは Redis の内部オペレーションやそのオペレーションに関するインサイトを記録したログです。本アップデートでは、CloudwatchLogs、Kinesis Firehose に対してエンジンログを出力できるようになったため ElastiCache for Redis のトラブルシューティングがこれまでよりも簡単に行えるようになったのではないかと思います。
実際の画面は以下です。
ElastiCache for Redis (6.2) を作成する際にエンジンログを出力できるようになっています。
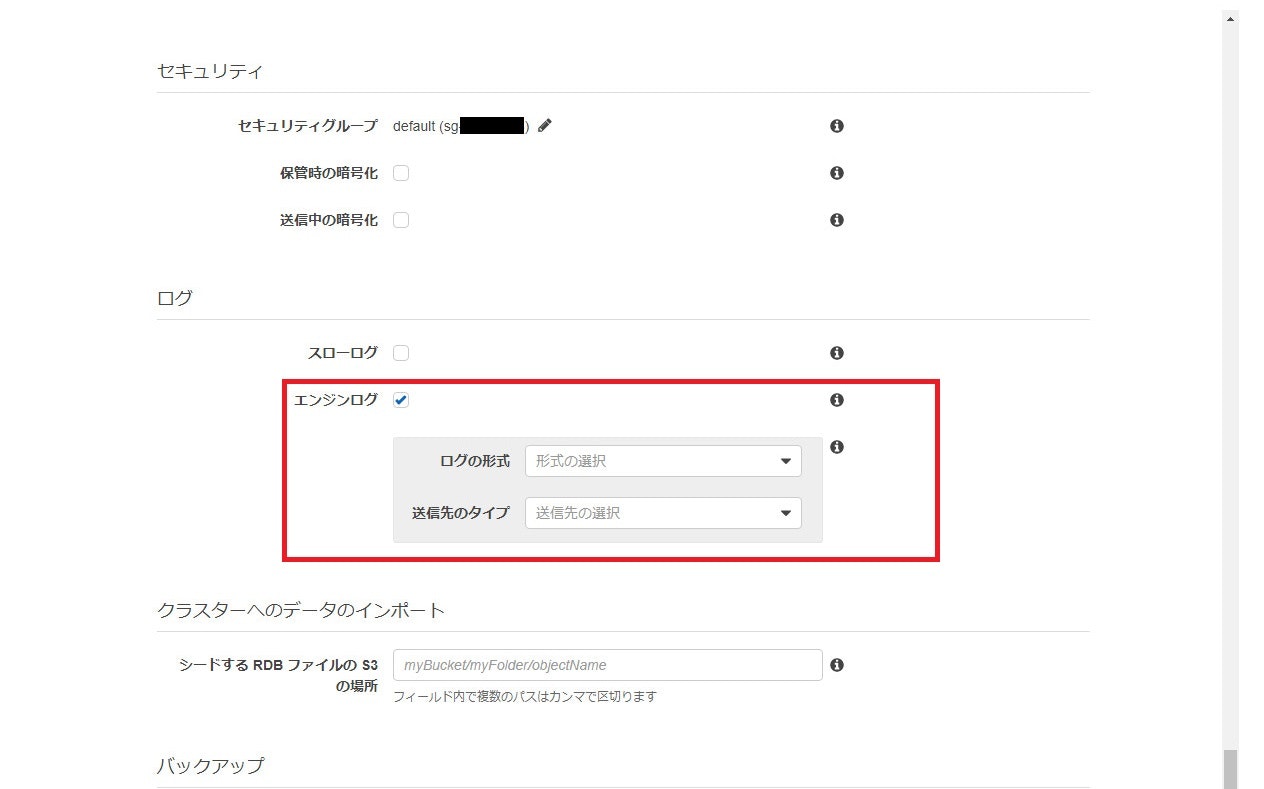
出力形式、送信先はそれぞれ以下が選択可能です。
- ログの形式
- Text
- JSON
- 送信先のタイプ
- CloudwatchLogs
- Kinesis Firehose
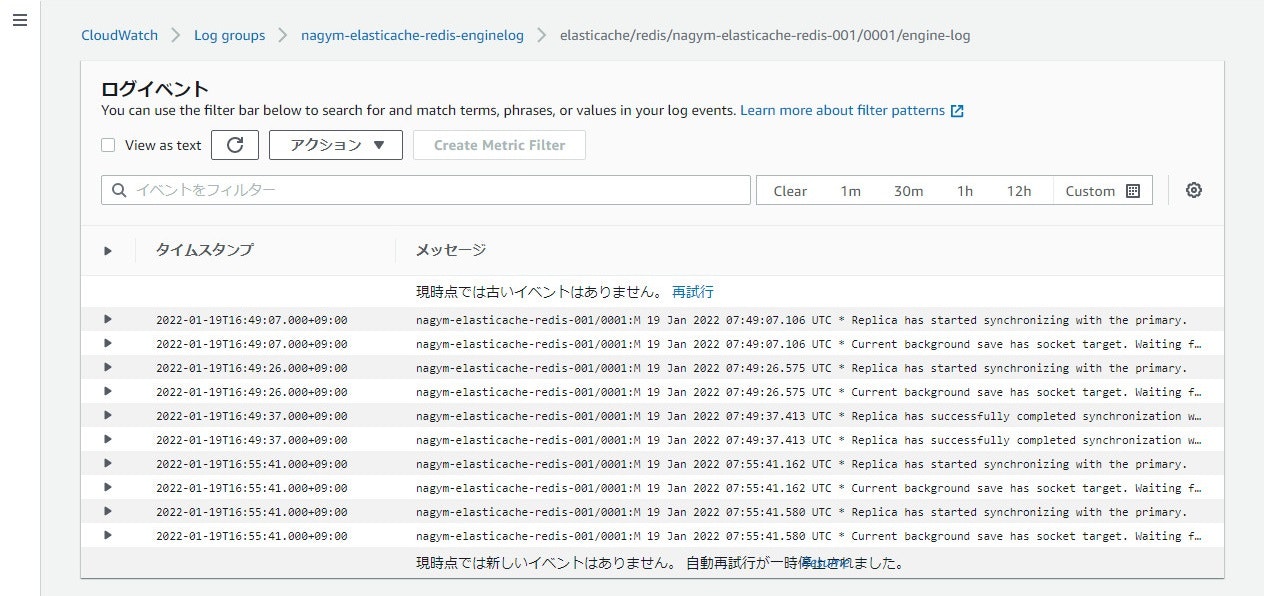
実際に出力してみると、以下のようなログが出力されていました(今回は TEXT 形式で CloudwatchLogs に出力)
レプリケーションの開始、成功等のログが出ていましたがよく分からない…
- 日本リージョン対応状況
- 東京:対応
- 大阪:対応
1/14(金)
Amazon Forecast が、データセットおよびデータセットグループのリソースを管理するための AWS CloudFormation のサポートを開始
CloudFormation は AWS リソースの IaC (Infrastructure as Code) のサービスです。JSON または YAML で AWS のリソースを記載することにより、AWS のリソースをテンプレートとして管理することができます。
本アップデートでは、時系列データの予測サービスである Forecast で使用するデータセット、データセットグループの作成、管理を CloudFormation で行えるようになりました。
- AWS::Forecast::Dataset
- AWS::Forecast::DatasetGroup
具体的な文法に関してはリファレンスを参照ください。
(参考) Forecast resource type reference
- 日本リージョン対応状況 ※各サービスが東京、大阪に対応していれば CloudFormation で記述可能
- 東京:対応
- 大阪:未対応 ※大阪は Forcast に未対応です。
感想
SAP on AWS をしっかりやらないとなぁ…と思いました。全然分からない…
あとはもう少し全体的に見やすい構成、文章にしないとと思いました。デザインとか表現とかその辺の勉強もやっていこうと思います…