はじめに
お久しぶりです、なじむです。
最近 AWS のアップデートをそこそこ真面目に追うようになったので、AWS Japan さんがまとめている週刊AWSで確認した内容を自分のメモ用に残していこうと思います(目標は毎週更新…)
間違っている内容があるかもしれないので、見つけたらコメント等いただけると嬉しいです。
今回は7/19週のアップデートです。
7/19(月)
Amazon EBS io2 Block Express Volumeの一般利用開始(GA)が発表されました
EBS の新しいボリュームタイプであるio2 Block Express ボリュームが利用可能になりました。io2 Block Express の登場前までは、構成のストレージを使用するためにはオンプレの SAN と接続するしかありませんでしたが、これにより AWS だけで Oracle、SAP HANA、Microsoft SQL Server および SAS Analytics 等、I/O 負荷の高いミッションクリティカルなデプロイに最適な構成を組めるようになりました。io2 Block Express ボリュームは以下のような特徴を持ちます。
- 最大 256,000 IOPS
- 4000 MB/秒のスループット
- 64 TiB のストレージ容量
gp2 タイプや Block Express でない io2 タイプと比較すると以下のような性能差です。
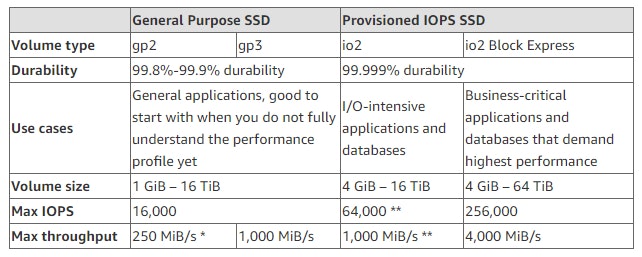
(出典) AWS News ブログより
作成方法は通常のEBSの作成方法と同じですが、Block Express か非 Block Express かを選択する項目は特になく、Block Express に対応したインスタンスタイプ(執筆時点では R5b のみ)を使用していれば自動的に Block Express となり、IOPS を 256,000 に設定できます。
-
r5b.large のインスタンスタイプの場合
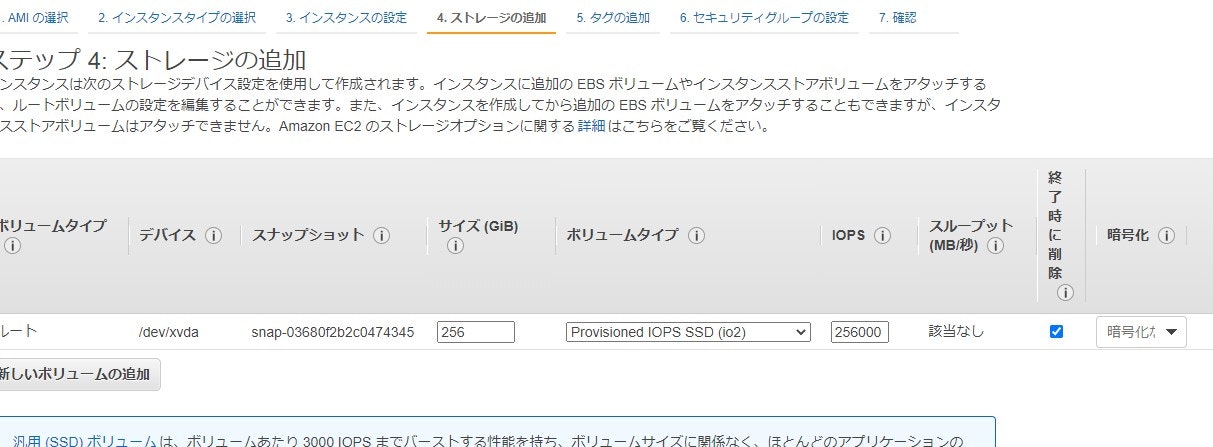
-
t2.large のインスタンスタイプの場合
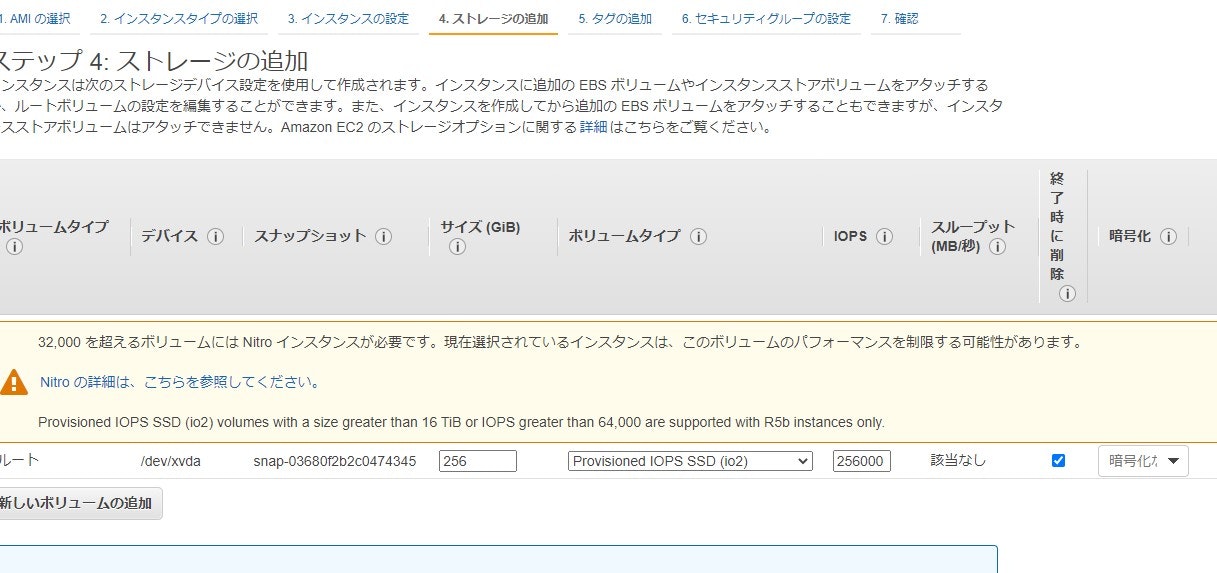
大阪リージョンでは R5b インスタンスに対応していないため、io2 Block Express にも対応していません。
- 日本リージョン対応状況
- 東京:対応
- 大阪:未対応
7/20(火)
Amazon RDS Cross-Region Automated Backupが利用可能なリージョンが拡大
Oracle や MySQL と言った RDBMS のマネージドサービスである RDS で、リージョンを跨いで自動的にバックアップを取得できる Cross-Region Automated Backup の対象リージョンが追加されました。身近なところだと、これまでは東京→大阪へのバックアップは対応していましたが、その逆の大阪→東京は対応していませんでした。今回のアップデートで、大阪→東京へのクロスリージョンバックアップもできるようになりました。
実際の画面は以下です。
大阪リージョンからは東京リージョンへのバックアップしか対応していないので、日本国外へのクロスリージョンバックアップを検討している方はご注意ください。
-
東京リージョン
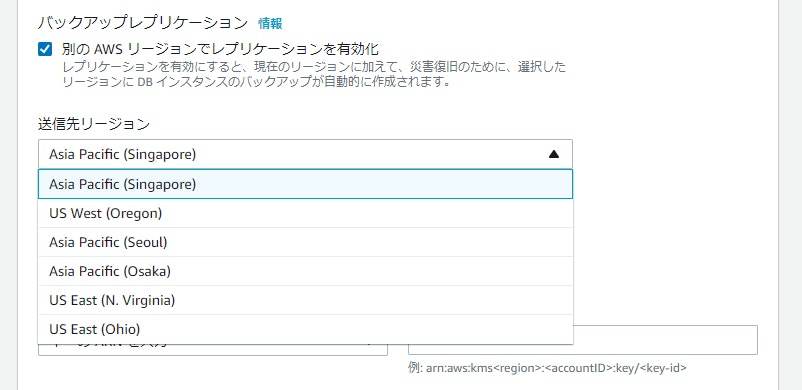
-
大阪リージョン
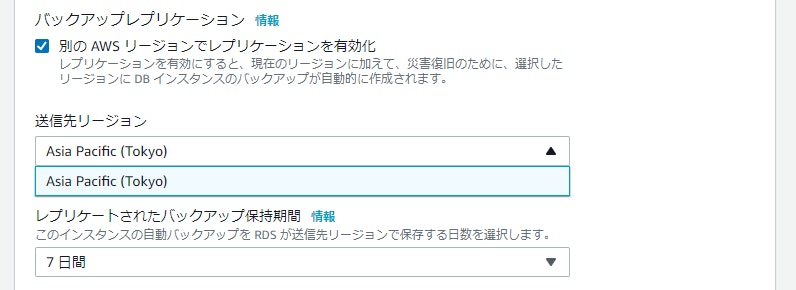
アップデートの内容だと、以下のバージョンで使用できると記載があったのですが、SQL Server は画面上の設定項目を確認できませんでした。見るところが悪かった…?
- Oracle :12.1 (12.1.0.2.v10 から) 以降
- PostgreSQL:9.6 以降
- SQL Server:SQL Server 2014 以降
日本リージョン内でDRが組めるようになったのは大きいですね。使う方も増えてきそうです。
- 日本リージョン対応状況
- 東京:対応
- 大阪:対応
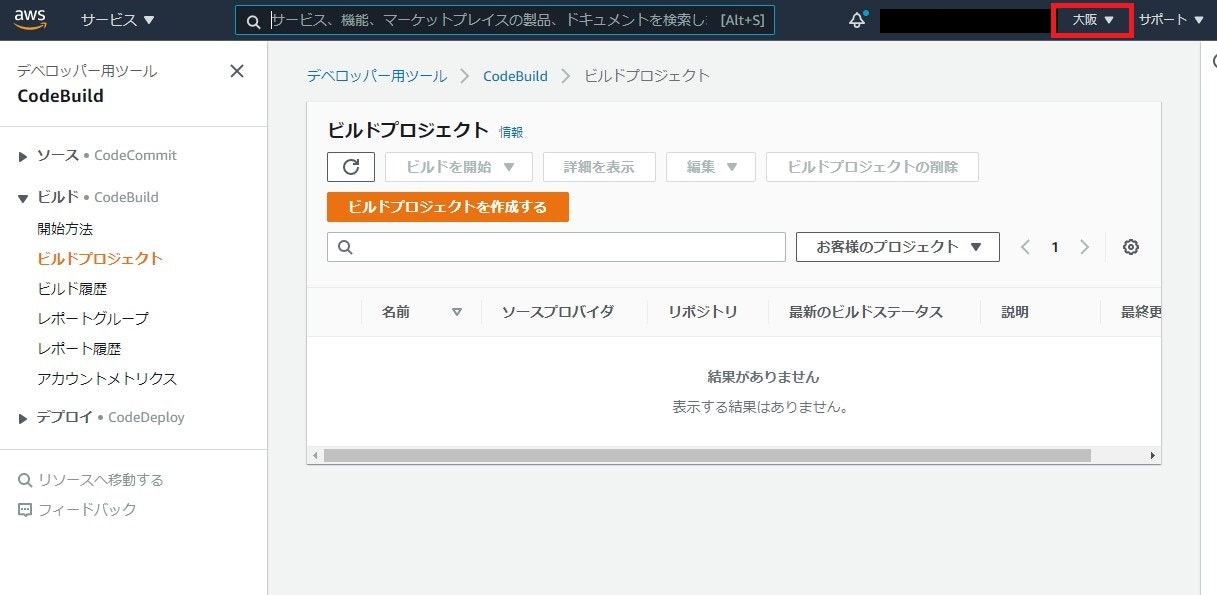
AWS CodeBuildが大阪リージョンでもご利用頂けるようになりました
継続的インテグレーション (CI) のマネージドサービスである CodeBuild が大阪リージョンで使用できるようになりました。
仕様を最初に決めて一度に大きなリリースをするウォーターフォール型と異なり、小さなリリースを何度も繰り返すアジャイル開発の現場では、開発 > ビルド > テスト > リリースを早いサイクルで実施する必要があります。開発は手動で実施する必要がありますが、テスト、リリースを毎回手動で実施するのは大変です。それを自動化しようというのがCI/CDという考え方です。
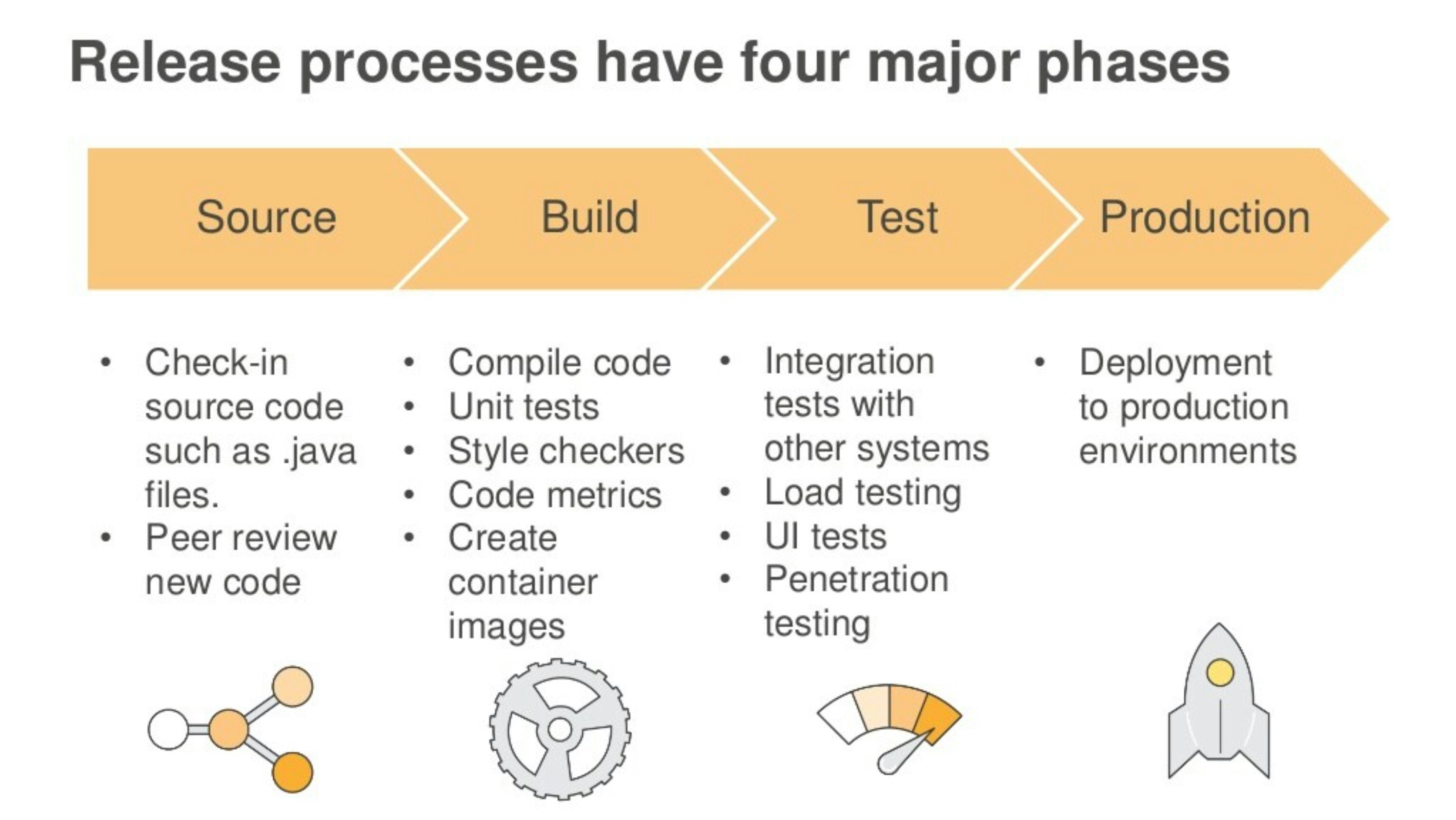
(出典) DevOps on AWS: Deep Dive on Continuous Delivery and the AWS Developer Tools
AWSではCodeシリーズがそれに該当し、以下のようなマッピングです。
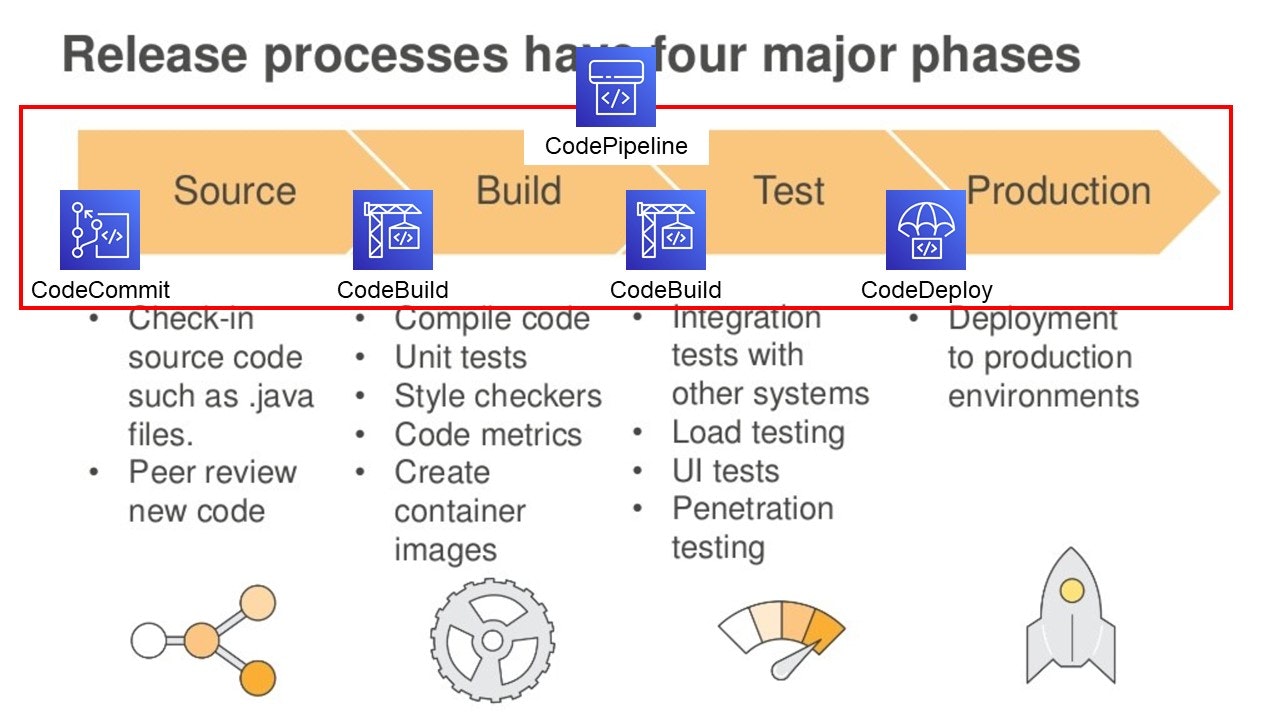
実際の画面は以下です。大阪リージョンで使用できていますね。ただ、CodePipeline だけ大阪リージョンで未対応のためご注意ください。
- 日本リージョン対応状況
- 東京:対応
- 大阪:対応
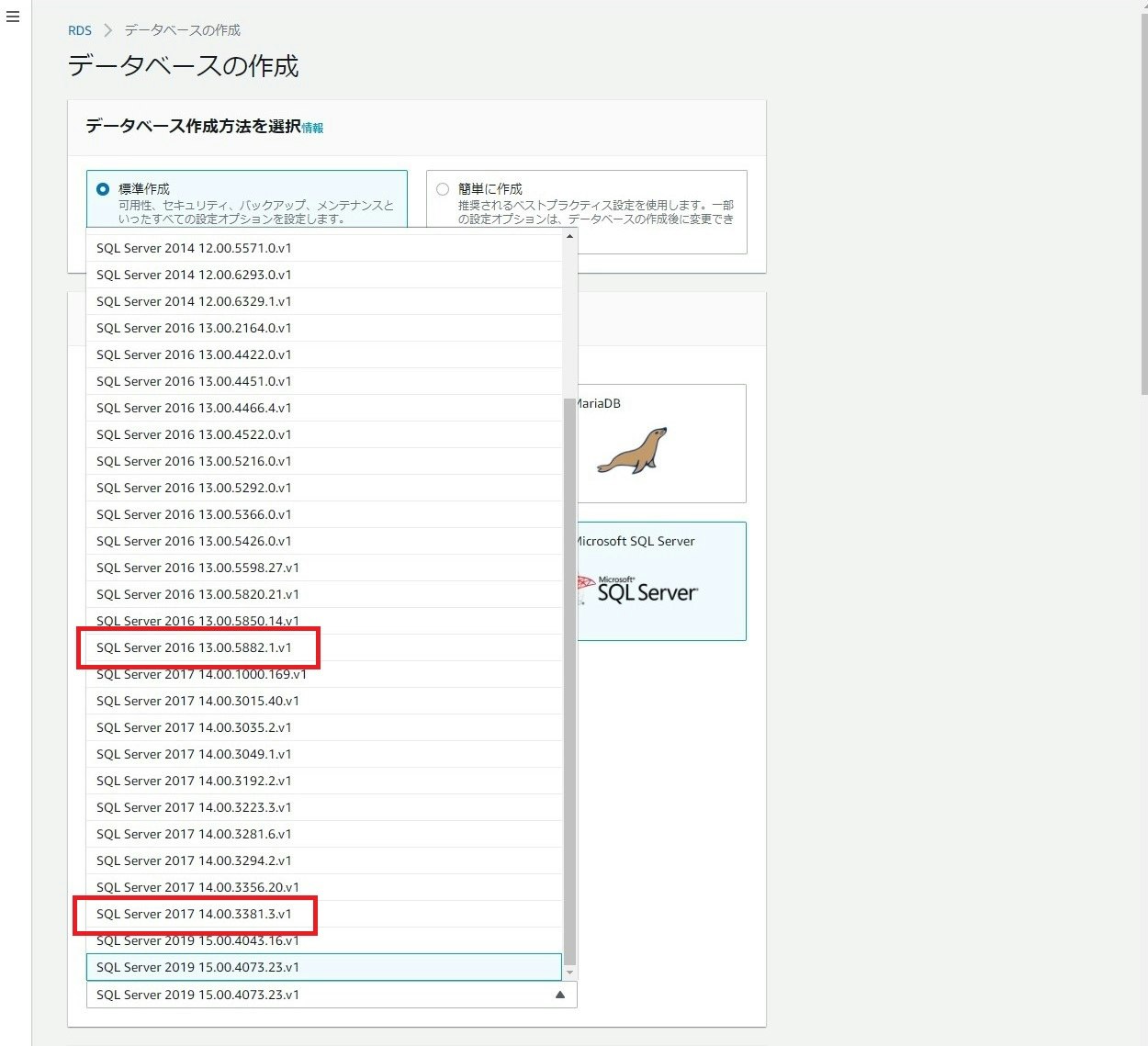
Amazon RDS for SQL Serverで新たなマイナーバージョンが利用可能に
Oracle や MySQL と言った RDBMS のマネージドサービスである RDS で、SQL Server の以下マイナーバージョンが使用できるようになりました。
詳細なアップデートの内容は確認していないので、Microsoft 社の公式ページを参照ください。
実際の画面は以下です。どのエディションでも使えるようになっていました。
- 日本リージョン対応状況
- 東京:対応
- 大阪:対応
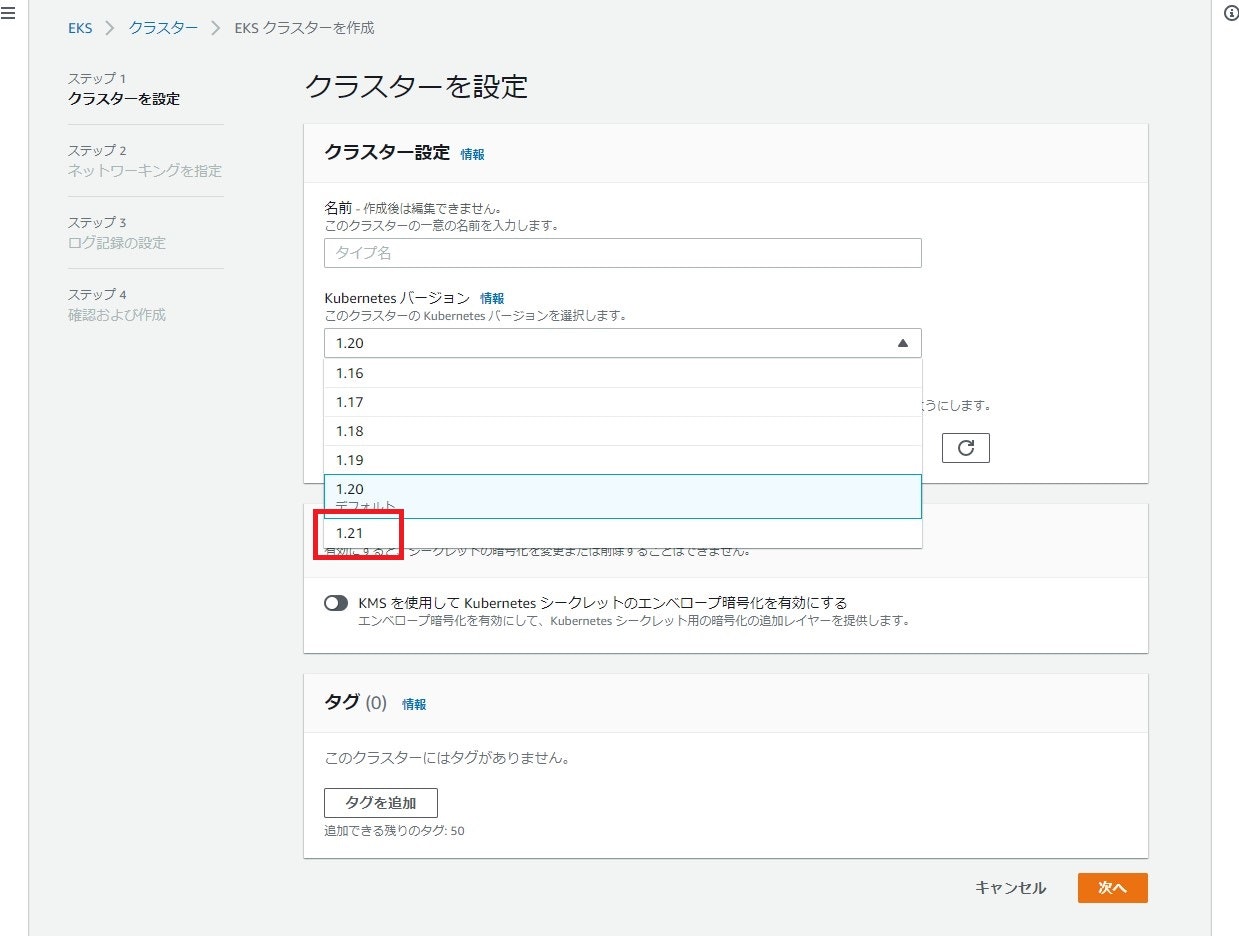
Amazon EKSとEKS DistroがKubernetes version 1.21をサポート
Kubernetes のマネージドサービスである EKS と、EKS で使用している Kubernetes の OSS である EKS Distro で Kubernetes の 1.21 が使用できるようになりました。
Kubernets 1.21 では Cronjobs の正式版が利用可能になっているので、待っていた方も多いのではないでしょうか。詳細な更新内容は Kubernetes 公式を参照ください。
実際の画面は以下です。1.21 が使えるようになっていましたが、デフォルトはまだ 1.20 でした。
Kubernetes を使用する上では EOSL が気になるところですが、Amazon EKS Kubernetes release calendarを確認すると 1.21 は 2022年9月までのようです。
※日本語ページだと執筆時点では 1.20 までしか記載がなかったので英語ページを参照ください。
- 日本リージョン対応状況
- 東京:対応
- 大阪:対応
7/21(水)
Amazon AthenaのPower BI用データソースコネクタを発表
Microsoft 社が公開している BI (Business Intelligence) ツールのクライアントアプリである Microsoft Power BI Desktop でデータソースに Amazon Athena が選択できるようになりました。これにより、Microsoft Power BI Desktop で Athena のデータを使用して、Power BI のダッシュボードやクエリが行えるようになりました。
※BI ツール:企業に蓄積された大量のデータを集めて分析し、迅速な意思決定を助けるのためのツール。経営管理や売上のシミュレーションなどに活用できる。
これが出る前までは、データソースに ODBC を選択して Athena に接続していたようです。
(参考) Power BI DesktopからAmazon AthenaにODBC接続してみた
以下のチュートリアルがとても参考になったので気になる方は試してみてください。
(参考) Creating dashboards quickly on Microsoft Power BI using Amazon Athena
実際の画面は以下です。テスト用に構築した EC2 から Microsoft Power BI Desktop を介して Athena に接続ができました。
-
Microsoft Power BI Desktop から Athena への接続。ただ、見つかったのは Beta 版…?古い AMI を使用してしまったかもしれません。
-
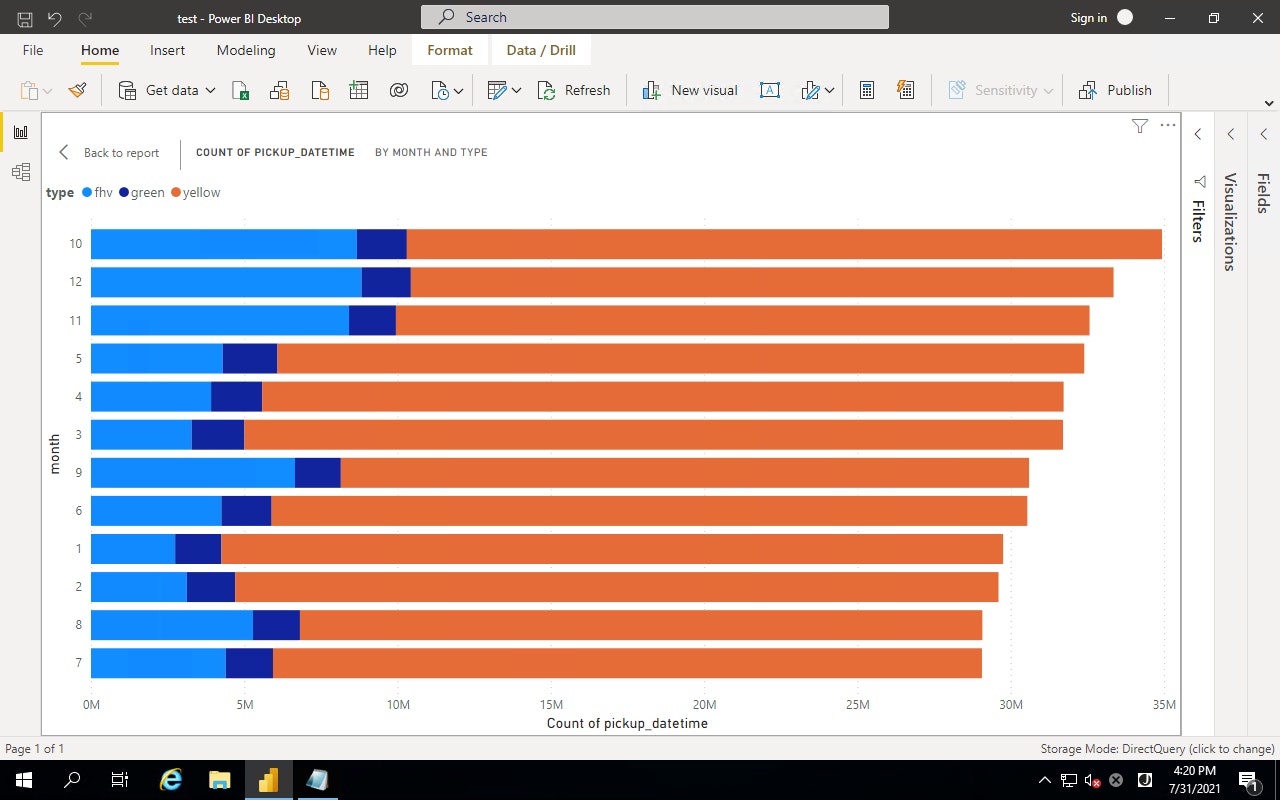
Microsoft Power BI Desktop でデータの集計
大阪リージョンでは Athena 自体が未対応のため、本機能も対応していません。
- 日本リージョン対応状況
- 東京:対応
- 大阪:未対応
7/22(木)
Amazon VPCでEC2インスタンスに対してIPプレフィックスを割り当てることが可能に
※具体的な動作を検証していないので推測込みです※
EC2 インスタンスの ENI に IPv4、IPv6 のプレフィックスを割り当てられるようになりました。これにより EKS や ECS、Docker on EC2 等、インスタンスに複数の IP アドレスを必要とするコンテナアプリケーションやネットワークアプリケーションのスケールや管理の簡素化が可能になりました。
なるほど、分からん。ということで、EKSの場合で推測してみようと思うのですが、EKS のデータプレーンに m5.large の EC2 を使用している場合、付与できる IP アドレスは最大 30 個(アタッチできる ENI:3 つ、 ENI あたりの IP 上限:10個)です。つまり、インスタンスあたりの稼働できるコンテナ数も 30 個までとなります。
(参考) https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/using-eni.html#AvailableIpPerENI
本機能を使用することで何百、何千の IP を付与できるようになるため、インスタンスあたりで稼働できるコンテナ数も何百、何千になるのでは、と思いました。ただ、実際の画面で軽く見た感じだとそうでもないのかなと感じ、ここは実際に環境を構築しないと分かりませんでした。。
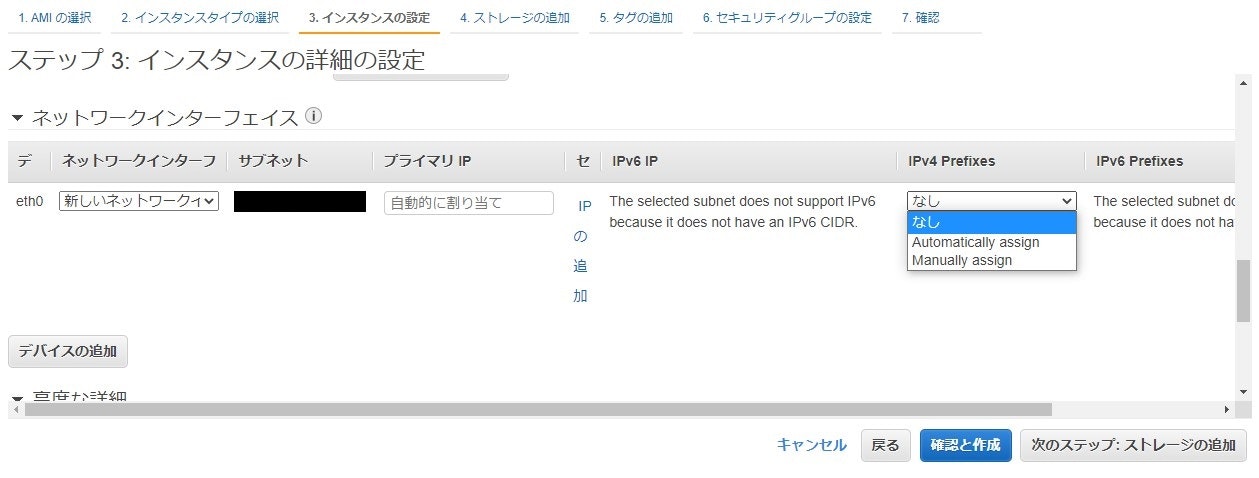
プレフィックスはEC2インスタンスの作成時に指定します。採番方法は以下2通りあります。
- Automatic assignment — AWS が自動的にプレフィックスを割り当ててくれます。
- Manual Assignment — 自分で xxx.xxx.xxx.xxx/28 のプレフィックスを指定します。
実際の画面だと以下です。
インスタンスタイプにより設定できるものとできないものがあり、例えば t2 シリーズでは設定できず、m5 シリーズでは設定できました。また、m5.large, m5.xlarge だと Automativally assign で付与できるプレフィックスは 1 つでした。この辺の仕様はどのドキュメントを見れば分かるのだろう…
Automativally assign でプレフィックスを付与すると、xxx.xxx.xxx.xxx/28 のプレフィックスが付与されるので、16個のIPアドレスが付与できるようになるものと思います。
-
設定画面
-
設定値の確認
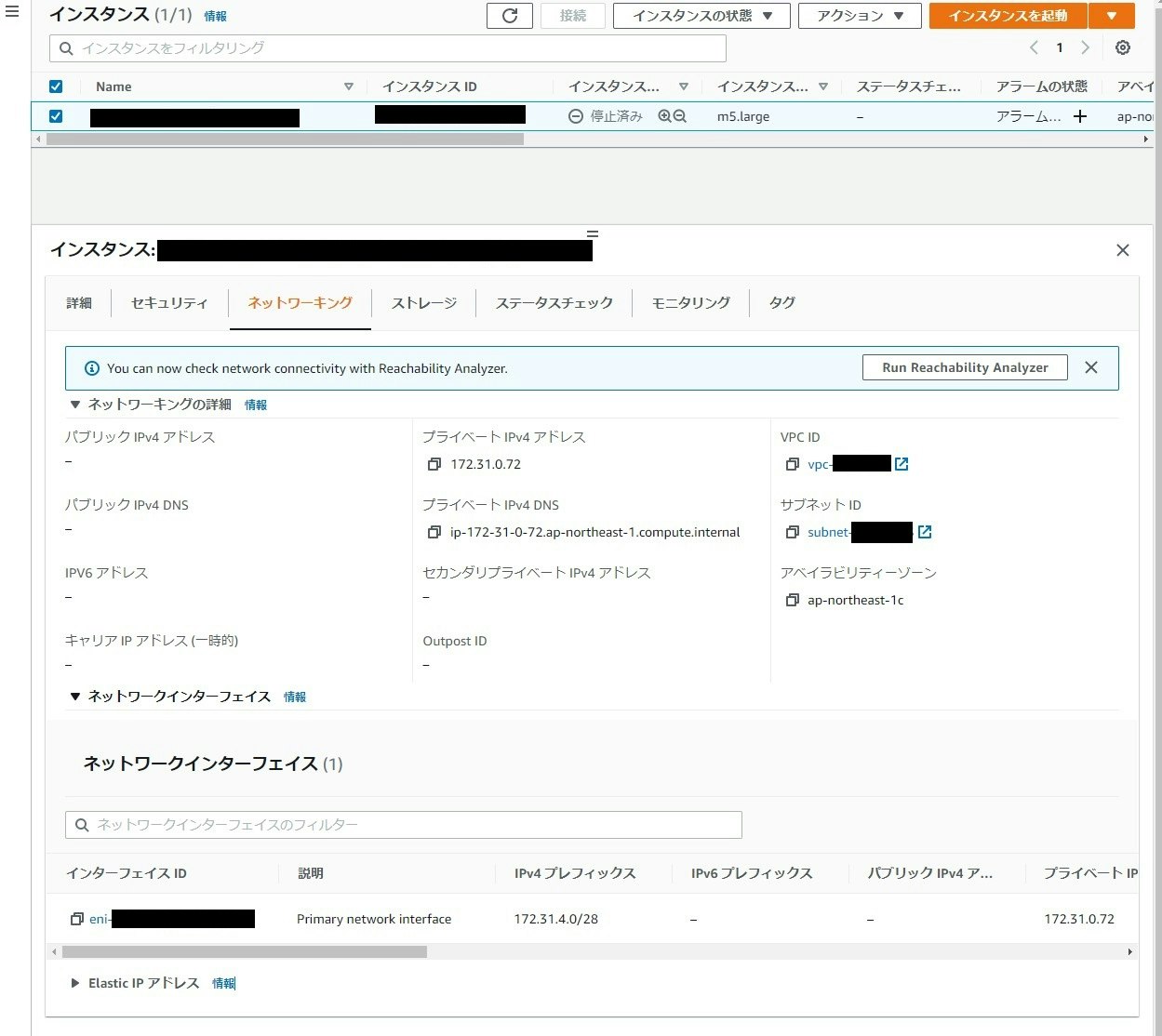
詳細は内容は Assigning prefixes to Amazon EC2 network interfaces を参照ください。
ドキュメント上だと "すべてのパブリックリージョンとAWS GovCloud (米国) でご利用いただけます" と記載があったのですが、大阪リージョンではプレフィックスを設定することができませんでした。大阪リージョンはパブリックリージョンではない…?
- 日本リージョン対応状況
- 東京:対応
- 大阪:未対応
AWS Serverless Application Model Pipelines(AWS SAM Pipelines)のパブリックプレビューを開始
SAM で CI/CD パイプラインの機能がパブリックプレビューとして公開になったなったようです。
このアップデート、私が SAM をよく分からないために説明できないのですが(調べるのに力尽きた…)、Classmethod 社のブログを参考にして頂くとイメージが湧くかなと思いました。詳しくは以下記事を参照ください。
(参考) パブリックプレビューのAWS SAM パイプライン機能を試してみた
- 日本リージョン対応状況
- 東京:対応
- 大阪:対応 ※CodePipeline を使用する場合は未対応かも。Jenkins 等を使用する場合は大丈夫そう。多分。
7/23(金)
AWS Glue DataBrewが自動生成するデータクオリティに関する統計処理を指定可能に
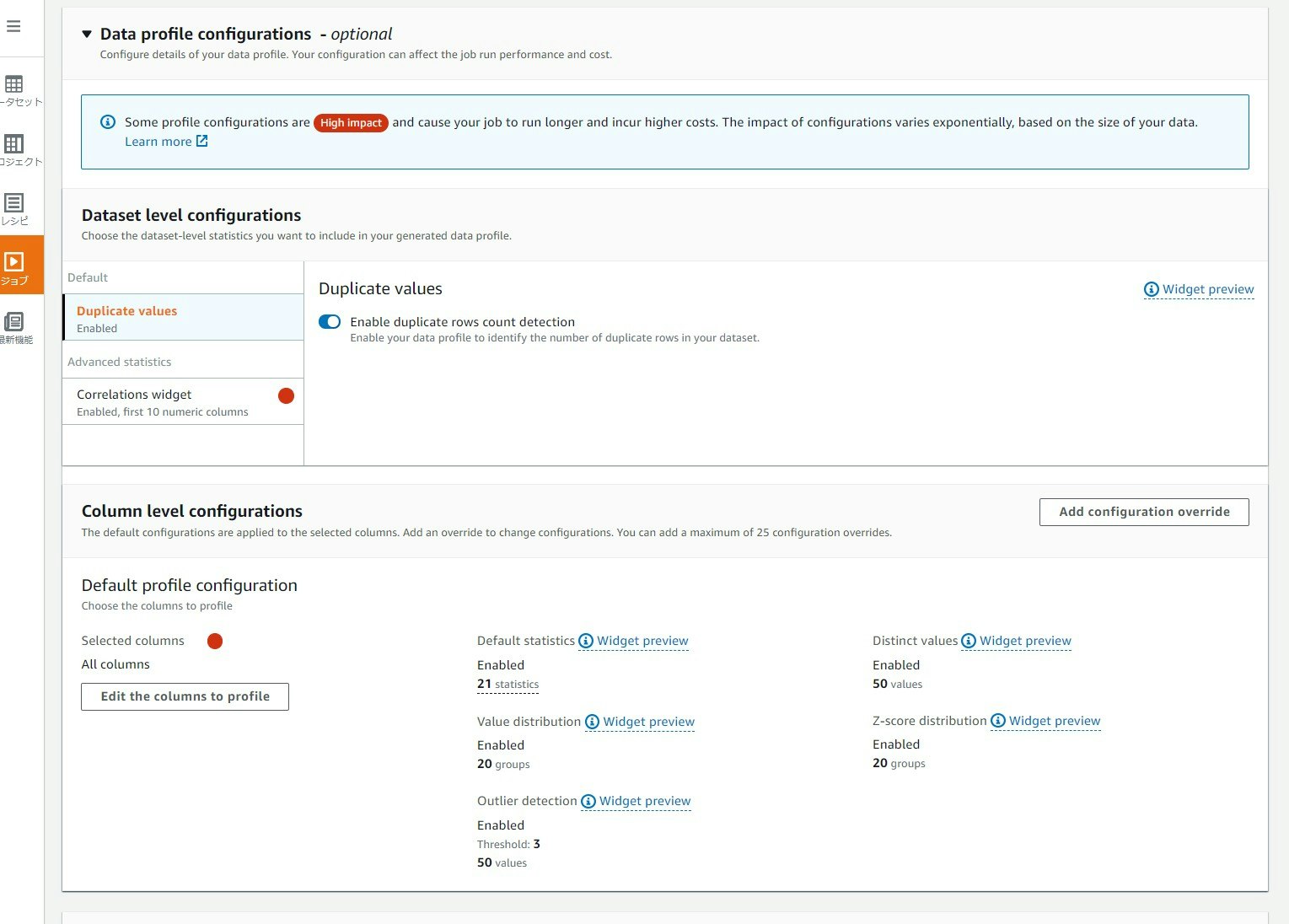
コードを書かずに、GUI でデータクレンジングや正規化と言ったデータの前処理を行うことができる(個人的にはめっちゃエクセルに見える)サービスである Glue DataBrew で、プロファイルジョブを実行する際に重複値、相関値、異常値等、どのデータ品質の統計を生成するか指定できるようになりました。
Glue DataBrew のプロファイルジョブは前処理を行うデータの包括的なプロファイル情報を作成するための機能です。これまではデフォルトで重複値、相関値、異常値等、全ての項目の統計を生成していましたが、今回のアップデートにより、任意の項目を選択できるようになりました。おそらく、統計の項目を減らすと使用するコンピュータリソースも減るので、ジョブの実行時間が短縮され、それに係る料金も減るものと思います。
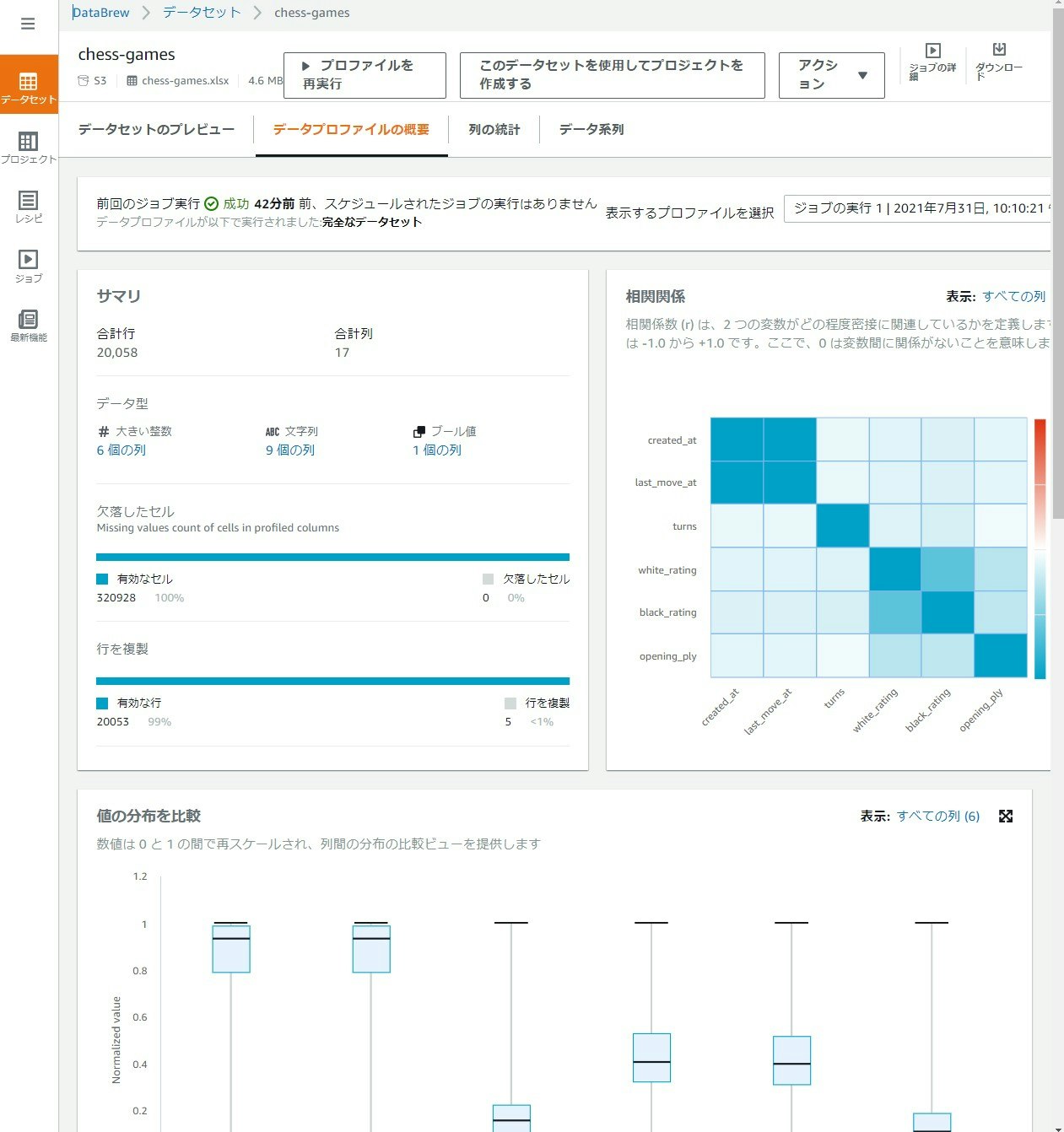
実際の画面では以下です。今回のデータセットは、AWS がサンプルとして用意している「有名なチェスゲームの動き」を使用しています。
すべての統計を無効にしたら、だいぶ簡素になってしまいました…
-
設定画面
-
すべての統計を有効にした場合の結果画面
-
すべての統計を無効にした場合の結果画面
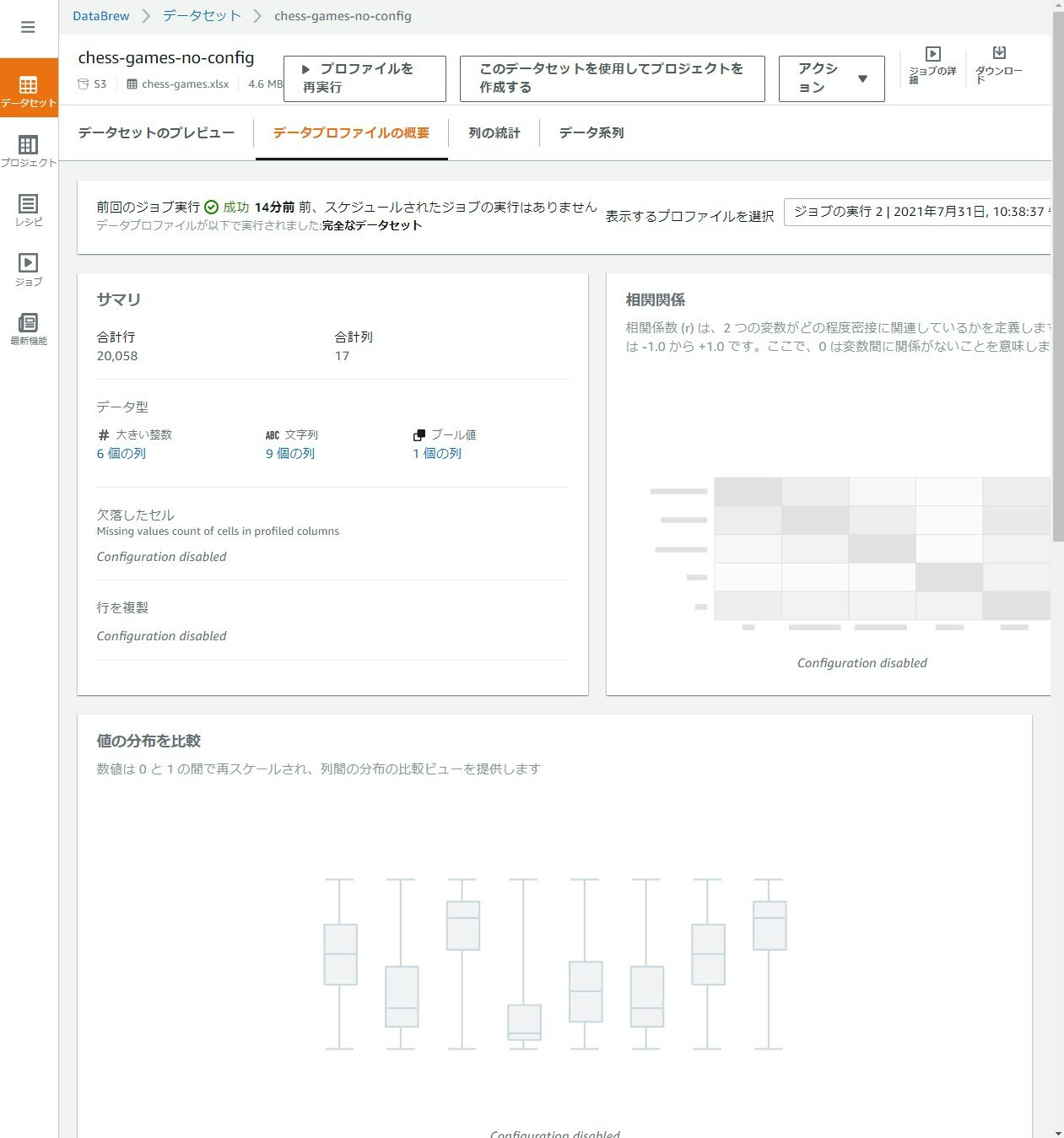
大阪リージョンでは Glue DataBrew 自体が未対応のため、本機能も対応していません。
- 日本リージョン対応状況
- 東京:対応
- 大阪:未対応 ※Glue DataBrew 自体が未対応
Glue DataBrew は真剣に触ったことがないので、いつか AWS Glue DataBrewハンズオン をやろうということで個人的なメモ。
AWS Glue DataBrewでプリパレーションが完了したデータをJDBCを介して直接書き込み可能に
次も同じく Glue DataBrew のアップデートです。
データのフィルターやグループ化を定義したレシピを実行するジョブで、分析結果の出力先に JDBC に対応した DB (MySQL, Oracle, SQL Server 等) や DWH (Redshift 等) に直接出力できるようになりました。
実際の画面は以下です。今回は DB を用意していないので実際の動作は確認していません。
大阪リージョンでは Glue DataBrew 自体が未対応のため、本機能も対応していません。
- 日本リージョン対応状況
- 東京:対応
- 大阪:未対応
感想
調べたことで何となく分かった気になりましたが、思った以上に日記帳になりました。アップデートを真面目に見ようとすると分からないことが多いということも分かりました…特に普段使わないサービスは(そして力尽きた…)
ただ、自分のためにも、このブログ投稿を通じて徐々に知識を増やしていこうと思っているので、毎週継続してやっていこうと思います。
間違っていたらその時はその時で…その際はご指摘ください。理解が間違っていたことが分かったという大きな進歩になりますので。