はじめに
この記事は、今年の夏に自分のクラスメイト向けに書いたMarkdownのコピペです。
後々、どっかしらのブログに、清書して載せる予定なので、載り次第またお伝えします。
まえがき
ここでは、良いプログラミング手法について解説しているわけではないことを先に断っておく。
筆者としてプログラミングとは、プログラミング言語というツールを用いて、自身が望むものを、自らの手で考え、試行錯誤した上で作ることをいうのだと思っている。
なので今回は、プログラミング言語の一つである、C言語の使い方とC言語を使うために役立つ知識をより深く掘り下げてみようと思う。
その上で、変数・配列・構造体・ポインタ・mallocなどについて、メモリやアセンブリを交えながら演習をすることによって、扱えるようにすることを目標とする。
また、演習にてプログラムの動作をgdbを用いて追うことにより、gdbを用いたプログラムのデバッグを行えるようにすることも目標とする。
そもそも変数とは?
まず、プログラムのすべてはメモリに保存されることを知っておいてほしい。
変数とは、メモリにラベル付けしたもの(特定の範囲のアドレスに対してラベル付けしたもの)、だと考えるといいです。
メモリにラベル付けすることによって、メモリに保存した値を変数を用いて使用することができます。
正確には、ラベル付けはされておらず、コンパイラがソースコードを解釈し、アセンブリに変換する際にアドレスの幅や場所を指定しています。(確かこんな感じだったはず)
よく一般的なC言語の入門書では、ラベル付けした箱と例えて説明するが、先ほどの説明を踏まえて考えると、「箱をメモリ」、「ラベルを変数名」としていることがわかると思います。
次の演習では、簡易的なC言語のプログラムを実行し、またgdbで変数がアセンブリではどのように扱われているのかを追っていきます。
演習
これ以降の演習では、windows on bash(WSLともいう)を用いておこなっていく。
ただし、Linuxベースの環境(CentOSやMacOS 最悪、gdbとgccが使えればよい)であればなんでもよい。
windows on bashについては、ここに記載しているので、同じ環境でやりたい場合は先にやってみてください。
下準備
まず、どこのディレクトリ上でもよいので、「cprog」というディレクトリを作成しよう。
次に、cprogディレクトリに移動した後に、viなどのテキストエディタを用いて「ex1.c」というファイル名で以下のコードを書こう。
int main(){
int a,b;
a=1;
b=2;
a=a+b;
return a;
}
次に、gccを使用してコンパイルしよう。
コンパイルをするコマンドは、gcc -g -o ex1 ex1.cとするとよい。
どうでもよい話にはなるが、-gはデバッグオプションといい、コンパイルして作られる実行ファイルにソースコードの情報を加える動作を行う。
デフォルトでは、実行ファイルにはソースコードの情報は付随しない。
また、-oオプションは空白を一つあけ、入力した文字列をコンパイルして作られる実行ファイルのファイル名とするものである。
デフォルトでは、a.outやa.exeというファイル名となる。
次に、プログラム実行した後にecho $?コマンドを実行しよう。
以下の図にここまでの実行結果を示す。

すると、3と出力される。
ちなみに、echo $?コマンドを実行すると、直前に実行したプログラムの返り値の値が0~255の値の間で表示される。
このようにすることでも、簡易的なデバッグをすることができる。
ちなみに、プログラムの返り値(C言語の場合はmain関数の返り値)は、raxレジスタに格納されている。
gdbの扱いかた(runコマンド)
では、ここからgdbを用いてアセンブリレベルで変数がどのようにして扱われているかを確認していこう。
gdbの基本的な使い方については、ここに記載しているので、参考にしてほしい。
ちなみに、ここでは実際に実行しながら説明していくから、別に見なくてもいい気もする。
まぁ、困ったら見てねって感じ。
また、使用するgdbでは、gdb-dashboardを使用している。
まず、gdb ex1コマンドを実行しよう。
すると、よくみる例の画面が出てくる。
次に、runコマンドを実行してみよう。
すると、以下の図のような画面になる。

図の[Inferior 1 (process 7834) exited with code 03]というメッセージは、プログラムが終了したこと表している。
やや詳しく説明すると、「process」の後ろに書かれている番号は「process id」である。
ちなみにこれの確認方法は、runコマンドではなく、startコマンドを実行し、Ctrl+Zを押し、ps aux | grep ex1コマンドを実行して、「/cprogまでのディレクトリ/cprog/ex1」の行の二番目の値が、fgコマンドを実行し、gdb上でcontinueコマンドを実行したあとに表示される「process id」であることがわかる。
以下の図に上で示したコマンドの過程を示す。


また、
exited with codeの後ろに書かれている番号はプログラムの返り値である。
考えてみると、echo $?の実行結果と、exited with codeの後ろに書かれている値は同じであることがわかる。
gdbの扱い方(breakpointの設定)
先ほど、gdbでrunコマンドを実行したと思うが、それではすぐにプログラムが終了してしまっていた。
なのでまずは、これをどうにかしよう。
どうすればよいか、それはどこかに「プログラムを停止するポイント」をセットしてやればよい。
この「プログラムを停止するポイント」のことを「breakpoint」という。
よって、「breakpoint」をセットしてやればよいことになる。
ちなみに、breakpointコマンドの使い方は以下の通りである。
breakpoint <関数名> or *(<メモリ or 関数名+メモリ>)
なので、b mainコマンドを実行し、runコマンドを実行してみよう。(breakpointは、bとして省略することができる。)
すると、以下の図のような画面になり、プログラムが停止していることがわかる。

gdbの扱い方(画面の説明)
まず、この画面についてそれぞれ説明しよう。
まず、Assemblyの下に書かれているのは見ての通りアセンブリである。
左から、16進数で書かれているものはメモリ。
次にmain+n(nは任意の数)は、main関数の先頭アドレスからどれだけ離れているか。
次に書かれているのはアセンブリコードである。
また、アセンブリコードが緑色になっている行は次に実行するアセンブリを表している。
ちなみに、やや暗い緑色になる場合があるが、その行と明るい緑色を含めて、下記で示すSourceの行で緑色になっている行に対応している。
次に、Registersの下に書かれているものは、見ての通りレジスタである。
それぞれのレジスタの説明については、省略するが、eflagsについては有効なフラグのみ表示されるようになっている。
次に、Sourceの下に書かれているものは、見ての通りC言語のソースコードである。
これは、コンパイル時に-gオプションを付けることによって表示される。
ほかにも、多くの欄があるが、今回に関しては不要なため、必要に応じて説明することにする。
gdbの扱い方(任意のメモリにbreakpointを設定)
さて、それでは本題に戻ろう。
先ほどは、b mainコマンドを実行し、mainにbreakpointをセットしてrunコマンドを実行した。
しかし、実行後のAssemblyの欄を見てみると、「main+4」の行で止まっている。
これは、前の二行が関数が呼ばれた際に確実に行われる動作であるがために、その2行が実行し終わった場所で止まるようにgdb側で勝手にやってくれているのだ。
ちなみに、b mainではなく、b *(main+0)を実行してからrunを実行したらどうなるだろう。
気になったのでやってみる。
以下の図のようにすることでbreakpointをセットし、runでプログラムを実行する。
このとき、図の最下部にあるように、「すでにプログラム走らせてるけど、始めからやり直して大丈夫?」みたいなこと聞かれるけど、気にせずyを入力し、続けよう。

すると、以下の図のように今度は、main+0でプログラムが停止していることがわかる。

gdbの扱い方(設定したbreakpointの確認)
さて、ここで現在のbreakpointのセット状況を整理しよう。
現在、breakpointは2つセットしているはずだ。
しかし、現在の画面上ではどこにbreakpointがセットしてあるのかわからない。
なので、セットしたbreakpointの情報を表示してみよう。
以下の図のように、info breakpointsを実行することで、breakpointの情報を見ることができる。

それじゃあ、ざっくりと見ていこう。
まず、Numはbreakpointの固有idであり、この番号でbreakpointの有効・無効化ができる。
次に、Typeはいいとして、Dispは関係ないし、EnbはEnableの略でそのままの通り有効か無効かを表している。
有効であればyだし、無効であればnになる。
次に、Addressはそのままでbreakpointがセットされているアドレスのことである。
最後に、Whatであるが、これはなんとなくわかると思うが、先ほどのアドレスをで表示したものになっている。
これでbreakpointを沢山セットして、どこにセットしたかを忘れたとしても、これを見ればいいことがわかった。
gdbの扱い方(breakpointの無効化)
さて、breakpointをセットして、それがどこにセットされているかも確認出るようになった。
ただ、このままでは実行するごとに毎回breakpointで止まって、まともにプログラムの動作を見ることができない。
なので、今度はセットしたbreakpointの無効化をしよう。
そんなわけで、実際にやっていく。
まずは、セットしているbreakpointを二つとも無効化してみよう。
「disable breakpoints」コマンドを実行してみよう。
その後、もう一度「info breakpoints」コマンドを実行してみよう。
すると、以下の図のようになる。

よくみると、Enbのところが、二つともnとなっていることがわかる。
試しに、「run」コマンドを実行してみる。
すると、breakpointでは止まらず、プログラムが終了していることがわかる。
gdbの扱い方(breakpointの有効化)
ただ、このままではやっぱりプログラムの動作が追うことができないので、一番最初にセットしたbreakpointを有効化しよう。
もう、察しのいい人なら気づいているかもしれないが、breakpointの有効化には、「enable breakpoints」を使う。
が、ただただこれを実行するだけでは、すべてのbreakpointが有効化されてしまうため、意味がない。
では、どうしたらよいか。
答えは簡単である、「enable breakpoints」の後ろに空白をあけて有効化したいbreakpointの固有idを入れてあげればよいだけである。
ちなみに、固有idでパッと気づかない人のために念のため言っておくと、「info b」(bはbreakpointの略)を実行したときにNumの欄に書かれている数字のことだ。
そんなわけで、一番最初にセットしたbreakpointの固有idは1であるので、「enable breakpoints 1」を実行してみよう。
その後、「info b」コマンド実行して確認してみよう。
すると、以下の図のようになっていることがわかる。

図をみると、確かに一番最初にセットしたbreakpointのEnbがyになっていることがわかる。
試しに、「run」コマンドを実行してみると、main+4の位置でプログラムが停止していることがわかると思う。
これで、breakpointを使ってプログラムを停止させ、その時のレジスタの状態やアセンブリコードを確認できるようになった。
gdbの扱い方(stepとstepi)
さて、ここまでで自分が状態を見たいところに、breakpointをセットしてやればみれることがわかったが、毎回breakpointをセットしてやるのはめんどくさいので今度はこれをどうにかしよう。
そのために、stepとstepiのコマンドを使う。
それじゃあ、実際に試しながらやっていこう。
一度、状態をすべてリセットするために、「quit」コマンドを実行しよう。
すると、gdbが終了するので再度、「gdb ex1」コマンドを実行する。
次に、「run」コマンドではなく、「start」コマンドを実行しよう。
すると、以下の図のようになる。
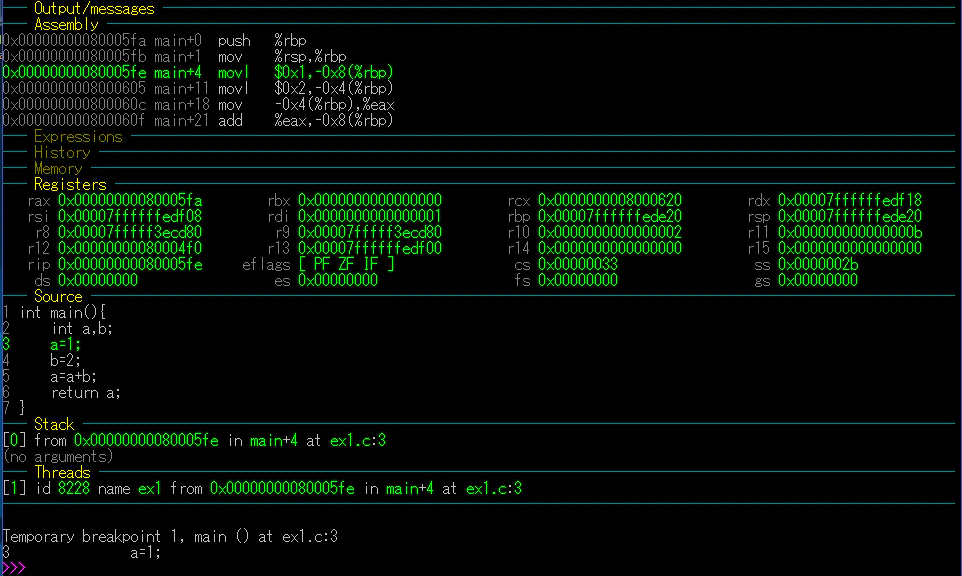
「start」コマンドは、「b main」コマンドの後に「run」コマンドを実行するのと変わらないことがわかる。
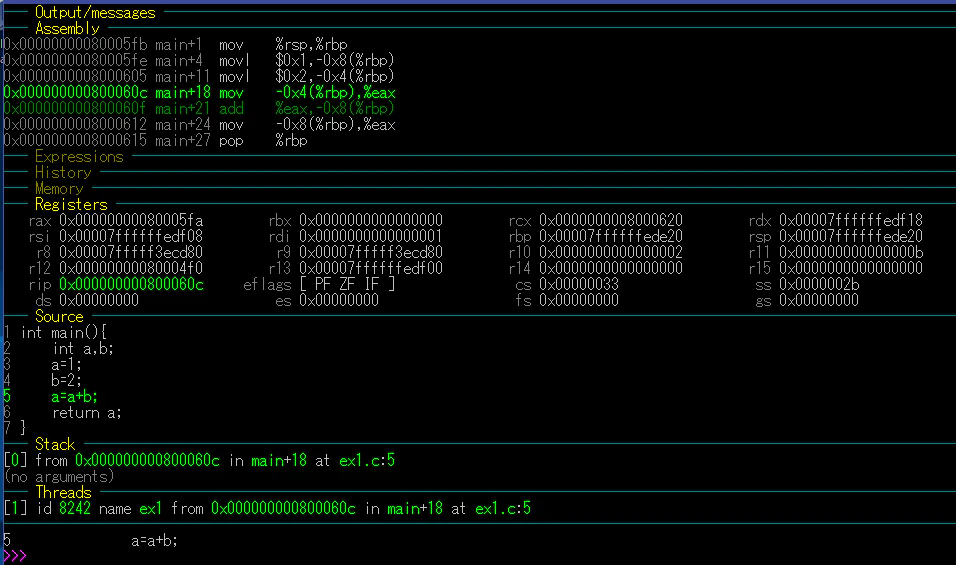
次に、「Assembly」と「Source」欄に注目しながら「step」コマンドを実行してみよう。
もし、実行し直したければ再度、「start」コマンドを実行し、yを入力すればよい。
すると、図のときのタイミングに「step」コマンドを実行すると、Assemblyの行が2行進むことがわかる。
ここで、解説してもよいのだが、それだとあまり身につかない気がするのでもう1ステップ踏んでからにする。
今度は、先ほどと同じように「stepi」コマンドを実行してみよう。
すると、先ほどの図のタイミングに「stepi」コマンドを実行すると、Assemblyの行は1行進んでいるのに対して、Sourceの行は1行も進んでいないことがわかると思う。
さて、いい加減うざったくなってきたが、まあお察しの通り、「step」コマンドと「stepi」コマンドはとても動作が似ているコマンドではあるが、本質的に全く別のコマンドであることがわかると思う。
具体的には、「step」コマンドでは、Sourceの行を1行進める(これを1ステップといったりするはず...)。
「stepi」コマンドでは、Assemblyの行を1行進める動作となっている。
gdbの扱い方(nextとnexti)
ちなみに、今回のプログラムでは関数を用いていないため、わかりずらいと思うが、関数呼び出しの行で、「step」や「stepi」コマンドを実行したときの動作は関数内の処理を行うようになっている。
後々、そのような動作を追うときに再度説明するが、具体的に今知りたいのであれば、簡易的な関数を一つ作成し、実際に実行してみるのがよいだろう。
ちなみに、関数呼び出しの際に関数内の処理を終えた後の状態にするコマンドもある。
それは、「next」や「nexti」コマンドである。
詳しい説明については、ここでは省くが大雑把に言えば、「next」はSource基準で、「nexti」はAssembly基準で動作する。
より、詳細に知りたい場合は実際に実行してみるのがよいだろう。
本題
さて、雑学的な雑談はこの程度にして本題に入ります。
ここで確認したいことは、「C言語の変数がアセンブリだとどのような形で扱われているか」です。
結論を先に示しておくと、最初に言った通り、変数はそれぞれメモリとして扱われています。
なので、変数一つ一つが、特定の範囲内のメモリに割り当てられていることになります。
具体的に、どのように割り当てられているかはここでは省きますが、「コンパイラが頑張ってやってくれている」っという認識でいるといいでしょう。
アセンブリを読む
とりあえず、確認したいことがアセンブリを読まないと始まらないので、逆アセンブルをしましょう。
本当は、コンパイルの時にアセンブリに直してそれを読むというのもいいんですけど、たまには趣向を変えて別の方法を取ってみましょう。
そんなわけで、今回はobjdumpではなく、gdbを使ってみます!
まあ、gdbも一応そういうことができるのですよ。(そもそもアセンブリ表示してるしね)
そんなわけで、図に実行した結果を載せておきます。
ちなみに、コマンドは「disassemble main」です。mainの部分を表示したい関数名に変えてあげることで指定した関数のアセンブリを表示することができます。

さて、それじゃあアセンブリを読んでいこう。
とりあえず、純粋なアセンブリを以下に載せておきます。
push rbp
mov rbp,rsp
mov DWORD PTR [rbp-0x8],0x1
mov DWORD PTR [rbp-0x4],0x2
mov eax,DWORD PTR [rbp-0x4]
add DWORD PTR [rbp-0x8],eax
mov eax,DWORD PTR [rbp-0x8]
pop rbp
ret
まず、1と2行目これは、前に書いた通り、関数が呼び出されたときに必ず出てくるやつです。
あと、8行目と9行目も同じく関数が呼び出されたときに必ず出てくるやつです。
なので、これらはとりあえず飛ばします。
ちなみに、1と2行目の処理のことをFunction prologueと呼び、8と9行目の処理のことをFunction epilogueと呼びます。
本当は、ちゃんと書いて説明しようとしたけど、ちょっと難しいので詳しくは調べてみてね。
さて、それじゃあまずはざっくりと読んでいきましょう。
3行目は、とあるアドレス先の値に1を代入していることがわかると思います。
なので、これをC言語のソースコードから探すと、a=1;の処理だと考えられます。
ここで、どうやらDWORD PTR [rbp-0x8]が変数aに該当すると考えられます。
また、変数はすべてメモリであることを思い出すと、アセンブリでは[]の中身がアドレスである。
なので、rbp-0x8が変数aのメモリがある場所、つまりアドレスであることが考えられると思います。
よって、変数aのアドレスはrbpから0x8引いたところであると考えられます。
同様に、4行目も考えていくと、変数bのアドレスはrbp-0x4の位置であることがわかります。
さて、これによって変数aとbのアドレスの位置がわかったわけですが、後は肝心のメモリの範囲です。
アドレスは、メモリの範囲の先頭(もしくは最後)を表すことが基本なのですが、メモリの範囲がわからないことには正常にメモリから値を取り出すことはできません。
なので、今度はこれを調べてみます。
アセンブリを見てみると、まだDWORDがよくわからないと思います。
言ってしまえばこれが、メモリの範囲、もしくは大きさを表しています。
DWORDは、4バイト(=32ビット)を表しています。
なので、ここからintの大きさは4バイトであるとも推測できます。
ここまでで、3行目と4行目がC言語のソースコードでどの位置に対応しているのか理解できたと思います。
念のため、C言語のソースコードとアセンブリを再掲しておくと、以下の通りですね。
int main(){
int a,b;
a=1;
b=2;
a=a+b;
return a;
}
push rbp
mov rbp,rsp
mov DWORD PTR [rbp-0x8],0x1
mov DWORD PTR [rbp-0x4],0x2
mov eax,DWORD PTR [rbp-0x4]
add DWORD PTR [rbp-0x8],eax
mov eax,DWORD PTR [rbp-0x8]
pop rbp
ret
ちなみに、アセンブリの3行目はC言語の3行目、アセンブリの4行目はC言語の4行目に対応しています。
次に、C言語の5行目に対応しているところを探してみます。
もう、「余裕でわかるわ笑」と思っている人もいると思いますが、一応ちゃんと説明しておきます。
まず、C言語の5行目の処理をより細かくしてみます。
するとa+bをした結果を、変数aに代入していると考えられます。
と考えると、まず足し算の命令はアセンブリでは6行目に相当していることがわかると思います。(addという命令がありますし。)
さて、この6行目に使われているeaxですが、これはなんでしょう。
これは、レジスタですが、今知りたいのは、このレジスタにどんな値が入っているかです。
すると、1行戻って5行目を見てみると、eaxに[rbp-0x4]の値が代入されていることがわかります。
これをよりわかりやすくいってあげると、eaxに変数bの値を代入している、となります。
つまり、ここまでの2行の処理、5・6行目の処理がC言語の5行目の処理に相当していることになります。
本当はここまでで十分なのですが、せっかくなので最後まで読んでみることにします。
アセンブリの7行目を見てください。
ここで、eaxに変数aの値を代入していることがすぐにわかると思います。
さて、ではなぜこんなことをしているのでしょうか?
理由は簡単です。
これが、C言語の6行目の処理の一部だからです。
まあ、より詳しく説明すると、C言語の6行目では変数aを返り値として指定しています。
また、アセンブリではこの返り値は、eaxレジスタに入れておく決まりがあります。
なので、eaxに変数aの値を代入しているわけなのです。
このように、C言語のソースコードはアセンブリと(大体)対応しています。
なので、C言語で書いた処理はほぼそのままアセンブリに直されると考えておくといいでしょう。
確かに、コンパイラには最適化の処理が含まれます。
ですが、この最適化の処理はアルゴリズムそのものを変化させることは、ほぼほぼ無いようです。
なので、何かしらのプログラムを作成する際には、最適なアルゴリズムを考えたうえで、プログラムを実装してあげることによって、より高速なプログラムを作ることができるというわけです。
まあ、現在だとマシンスペックが鬼つよになってるから、正直、滅茶苦茶高度な計算でもしない限り、そのような配慮はいらないと思いますけどね。
課題
さて、それじゃあここからがちょっとした課題です。
以下の二つの表に、BYTE・WORD・DWORD・QWORDの大きさとchar型・short型・int型・long型・long long型の大きさをそれぞれ示します。
| 型名 | 大きさ |
|---|---|
| BYTE | 1 byte(=8 bit) |
| WORD | 2 byte(=16 bit) |
| DWORD | 4 byte(=32 bit) |
| QWORD | 8 byte(=64 bit) |
参考: Intel® 64 and IA-32 Architectures Software Developer’s Manualの91ページ目
| 型名 | 大きさ(32ビットCPU) | 大きさ(64ビットCPU) |
|---|---|---|
| char | 1 byte(=8 bit) | 1 byte(=8 bit) |
| short | 2 byte(=16 bit) | 2 byte(= 16bit) |
| int | 4 byte(=32 bit) | 4 byte(=32 bit) |
| long | 4 byte(=32 bit) | 8 byte(=64 bit) |
| long long | 8 byte(=64 bit) | 8 byte(=64 bit) |
参考:limits.hに以下のような記述がある。(WSLの環境だと、/usr/includeディレクトリ配下に存在してるよ)
どうやらlimits.hに色々と定義されているっぽい。
(本当は、ちゃんとした言語仕様が書かれているやつからもってきたかったけど、しんどかったのであきらめた笑
多分、C99時の言語仕様のヘッダーファイルだから、ちょっと古いかも。)
ちなみに、上の表の内容はこのサイトと同じ。
/* These assume 8-bit `char's, 16bit `short int's, and 32-bit `int's and `long int's. */
さて、まあ以上の表のようにアセンブリとC言語でそれぞれ型が決まっているわけなんですが、実際にそれが本当になっているのかを確かめてもらいます。
具体的には、一番最初に書いてもらったex1.cというソースコードの変数宣言部分(int a,b;)のintをshortやcharなどに書き換えて、コンパイルし、gdbなどでアセンブリがどのように変化しているのかを確認してもらいたいのです。
やってみて、実際にcharだったら、DWORDだったところがBYTEに変わったりするはずです。
お試しを。
(ちなみに、アドレスrbp-0xNが、どうしてN引かれているのかを考えてみると少し面白いかもしれませんよ。)
一例として、以下にgdbの画面を載せておきます。

まとめ
そんなわけで、まとめです。
どうでしたか?gdbの扱い方、アセンブリとC言語での変数の扱われ方について理解できましたか?
念のため、ここに重要な部分だけを抜粋して載せておきます。
わからないことがあったら、LINEとかで言ってくれれば多少なりとも答えます。
では、一旦おつかれさまでした。
gdbの扱い方
| コマンド名 | 説明 |
|---|---|
| file 実行ファイル | 指定した実行ファイルを読み込むgdb 実行ファイルじゃなくても、こうするとデバッグできる |
| run | プログラムを実行する breakpointがあったらそこで止まる。 |
| continue | 停止したプログラムの動作を再開する breakpointがあったらそこで止まる。 |
| breakpoint X | breakpointを設置する Xに関数名、もしくは*(関数名+n)、*(アドレス)を指定して使う。 |
| info breakpoints | 設置したbreakpointの情報を表示する |
| step | ソースコード基準で1行ずつ実行する |
| stepi | アセンブリ基準で1行ずつ実行する |
| next | ソースコード基準で1行ずつ実行する 関数呼び出しがあったら関数内の処理を終えた後で止まる |
| nexti | アセンブリ基準で1行ずつ実行する 関数呼び出しがあったら関数内の処理を終えた後で止まる |
| print X | Xに値を入れるとその値を表示してくれる Xに$変数名を入れてあげると変数の値を表示してくれる。 |
| set $X=Y | 変数名XにYの値を代入する |
変数の型のサイズ
| 型名 | 大きさ |
|---|---|
| BYTE | 1 byte(=8 bit) |
| WORD | 2 byte(=16 bit) |
| DWORD | 4 byte(=32 bit) |
| QWORD | 8 byte(=64 bit) |
| 型名 | 大きさ (32ビットCPU) |
大きさ (64ビットCPU) |
|---|---|---|
| char | 1 byte(=8 bit) | 1 byte(=8 bit) |
| short | 2 byte(=16 bit) | 2 byte(= 16bit) |
| int | 4 byte(=32 bit) | 4 byte(=32 bit) |
| long | 4 byte(=32 bit) | 8 byte(=64 bit) |
| long long | 8 byte(=64 bit) | 8 byte(=64 bit) |
そもそも配列とは?
まあ、明確な定義とか正直どうでもいいので、ざっくりというと、「変数が沢山繋がっているやつ」です。
よくある例え的なイメージでいうと、「箱が沢山繋がっているやつ」ですかね。
まあ、こんなことはもう知ってますよね。
なので、もう少しメモリに関連付けて話します。
前回の話で、変数は特定の範囲のメモリに割り当てられているといいました。
そして、C言語の型に対するそれぞれのサイズについても表にして示しました。
さて、ここまでの話を一度整理してみましょう。
配列とは、変数が沢山繋がっているものです。
このとき、どれだけ繋がっているかは、要素数という形で、指定することができます。
そして、その変数は型ごとにサイズが異なります。
つまり、配列とは、特定のサイズの変数が指定した数だけ連続してあるものであるといえます。
なので、配列は「指定数×変数のサイズ分」だけ、アドレスをずらしてやるだけで、別の値を保持したり取り出すことができるというわけです。
ちなみに、これを配列としての使い方で書くと、変数名[N-1](Nは要素数)になり、このようにして各要素を操作することができます。
また、[]内の数のことをindexといったりします。
演習
確認したところ、どうやら以下の演習の内容がCentOSとUbuntuで異なるようです。
もし仮に、演習をしていて演習通りにならないなと思ったのであれば、この文章を読むことによって、原因が判明すると思います。
下準備
とまあ、色々と言ってみましたが、やってみて感覚掴んだ方が早いし、楽です。
なので、以下のコードをファイル名ex2.cとして書いて、cprogディレクトリに保存してください。
# define MAX 3
int main(){
int a[MAX];
char b[MAX];
for(int i=0;i<MAX;i++) a[i]=i;
b[0]='M';
b[1]='A';
b[2]='X';
int c[]={1,2,3};
char d[]={'H','e','l','l','o'};
char e[]={'W','o','r','l','d','\0'};
char f[]="HelloWorld";
puts(d);
puts(f);
return 0;
}
次に、gcc -g -o ex2 ex2.cを実行してコンパイルします。
ほぼ確実にputsで、warningが起こると思いますが、大丈夫です。
(もし、後々実行してみて、なにも表示されない場合は、#include <stdio.h>をプログラムの最上部に書き足してください。)
これで、準備完了です。
コードを読む
さて、今回は実行する前にコードを読んで、どんな処理になるかを色々と考えてみましょう。
まあ、実行してから読んでどうしてかを考えてもいいのですが、今回のプログラムの場合はそれをしようとするには少し情報量が多い気がします。
とはいえ、ざっくりと読んでいきます。
4・5行目は、見ての通り(配列の)変数の宣言ですね。
この二つの行からは、以下の2つがいえます。
- 変数aには、int型の変数3つ分のメモリが割り当てられます。
- 変数bには、char型の変数3つ分のメモリが割り当てられます。
課題:6行目が終わった後の配列aの要素は、それぞれどんな値になってるか考えてみてください。(考えたら、この質問を押してください)
6行目も見ての通り、for文で0~2まで変数iの値を増加させ、それを配列aのi番目の要素にiの値を代入しています。
| index | 値 |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 2 |
さて、こんな感じで数値の場合は配列を扱うわけですが、文字の場合はどうでしょうか?
答えは、7・8・9行目にある通りです。
数値と同じように、indexを指定した要素に文字を代入していきます。
ちなみにC言語には、
文字は、'(シングルクォーテーション)で囲み、
文字列は、"(ダブルクォーテーション)で囲む習慣があります。
ちなみに、半角英数字は1 byteで表すことができ、全角文字は2 byteで表すことができます。
ここら辺の話は、文字コードについて調べればわかりますが、ASCIIコードについては後で軽く触れます。
11行目は、要素数を指定せずに変数の宣言と初期化をしています。
このように、,(カンマ)区切りで値を書くことで、要素数3として、indexが0のところに1、1のところに2、2のところに3の値が入ることになります。
次に、文字の代入です。
これには、二通りのやり方があります。
一つ目が12行目のように、11行目と同様にカンマ区切りで一文字ずつ記述しておく方法です。
二つ目が14行目のように、ダブルクォーテーションで囲ってその中に文字列を記述しておく方法です。
さて、まあこんな感じでほぼほぼすべてのコードを読んでみたわけですが、最後に2行(16・17行目)を読みましょうか。
この2行で使われているのは、putsという関数です。
この関数は、引数の文字列を出力し、最後に改行も出力する関数です。
要するに、「最後に変数dとeの中身出力して終わりましょ」ってことです。
では、次に行く前に軽くどのような出力になるのかを考えてみてください。
実行してみよう
さて、準備はいいですか?
ちゃんと考えましたか?
では、実際に実行してみましょう!
...あれ?なんか、おかしくね??
って思った人!
そうです!!
正しいです!!
これ、おかしいんです!笑
(「いや、当たり前だろ」って人は、さらに正しいんですけどね笑)
ちなみに、実行したら以下の図のようになっていると思います。

恐らく、多くの人はこう予想していたはずです。
Hello
HelloWorld
っと、表示されるだろうと。
でも、現実は違います。
実際には、
HelloWorld
HelloWorld
っと表示されています。
簡単に考えれば、なんか知らないけど、Helloの後ろにWorldが表示されてるってことになります。
なので、どうしてこう表示されるかをこれから探っていきたいと思います。
...なんか、ワクワクしませんか?笑
gdbで見てみるか
そんなわけで、一行一行コメントアウトするなりして確認するのありなのですが、正直そんなめんどうなことはしたくないです。
なんなら、無駄です。
そんなことしても、根本の原因を見つけることは、その手法ではほぼ不可能だからです。
そんなことをしなくても、今ならば私たちはgdbという便利なデバッグツールを使うことができます!
なので、gdbを使ってとりあえず、どの行で出力されるのかを見ていきたいと思います。
起動コマンドは覚えてますよね?
gdb ex2ですよ?
起動すると、いつもの画面になると思います。
とりあえず、startコマンドを実行します。
すると、以下の図のような画面になるはずです。

さて、本来はここからstepやnext、stepiやnextiを使って、自力で見つけるわけなんですが、今回は少し手助けをしましょう。
記述したソースコードは以下の通りですよね。
# define MAX 3
int main(){
int a[MAX];
char b[MAX];
for(int i=0;i<MAX;i++) a[i]=i;
b[0]='M';
b[1]='A';
b[2]='X';
int c[]={1,2,3};
char d[]={'H','e','l','l','o'};
char e[]={'W','o','r','l','d','\0'};
char f[]="HelloWorld";
puts(d);
puts(f);
return 0;
}
このプログラムの中で、まず出力している関数が書かれている行を探します。
っといっても、探す必要はないですね。
16・17行目です。
なので、それよりも前のコードは今は関係ないとしましょう。
すると、16行目の前まで気軽にstepが実行できるとわかりますね。
なので、step 9と実行します。
こうすることによって、stepを9回実行したことになります。
すると、以下の図のところでプログラムが停止していると思います。

さて、それじゃあ今度はputs関数の後にどのような出力がされるかを知りたいのでnextを実行してみましょう。
すると、以下の図のようになったと思います。

よくみると、Output/messagesの欄にHelloWorldと書かれているのがみれると思います。
これが、puts関数を実行したときの出力結果です。
試しにもう一度、nextコマンドを実行してみましょう。
すると、以下の図のように、今度もHelloWorldと出力されていることがわかると思います。

6
さて、ここまでで16行目のputs関数で、Worldが一緒に出力されていることがわかったと思います。
そもそもputs関数って?
さて、それじゃあ少しだけputs関数をより詳しく見ていきましょう。
っていっても、gdbでputs関数の中に入って、どんな処理がされているのかを追ったりはしません。
してもいいですが、やっても辛いだけな気がするのでやめておきます。
なので、puts関数について調べてみます。
すると、このようなサイトを見つけました。
これによると、「puts()関数は、ヌル文字を改行文字に置き換えて出力します」とのことです。
つまり、変数dにはNULL文字(\0)がないから、変数dの中身で止まらずに変数eの中身まで出力してしまったという、仮説がたてられます。
仮説を確かめる
さて、果たして本当に仮説の通りなのか。
これを実際に確かめていきます。
ちなみに、デバッグの基本は「仮説をたて、実証すること」だと思っています。
実証してみて、本当なのか全く違ったのか、それを確かめるのがデバッグだと思います。
(まあ、最後にそれを直すのが本来のデバッグなはずなのですが、今回は直したりはしません。)
とりあえず、変数dとeとfがどのようにして初期化されているかを確認しましょう。
具体的には、アセンブリ上では文字列はどのように扱われているかを確認します。
一度、startを実行し直してください。
次に、step 6を実行し、変数dが初期化される手前まで進めます。
さて、ここからどのようにするか悩んだのですが、一度すべてのアセンブリを書きだすのがよいと思ったのでそうします。
以下に、ソースコードで12~14行までに対応するアセンブリを書きだします。
(#の行は対応するC言語のソースコードを記述しています。)
ですが、実際に皆さんもstepiやnextiを活用して、書きだしてみてください。
# char d[]={'H','e','l','l','o'};
mov BYTE PTR [rbp-0x1e],0x48
mov BYTE PTR [rbp-0x1d],0x65
mov BYTE PTR [rbp-0x1c],0x6c
mov BYTE PTR [rbp-0x1b],0x6c
mov BYTE PTR [rbp-0x1a],0x6f
# char e[]={'W','o','r','l','d','\0'};
mov BYTE PTR [rbp-0x19],0x57
mov BYTE PTR [rbp-0x18],0x6f
mov BYTE PTR [rbp-0x17],0x72
mov BYTE PTR [rbp-0x16],0x6c
mov BYTE PTR [rbp-0x15],0x64
mov BYTE PTR [rbp-0x14],0x0
# char f[]="HelloWorld";
movabs rax,0x726f576f6c6c6548
mov QWORD PTR [rbp-0x13],rax
mov WORD PTR [rbp-0xb],0x646c
mov BYTE PTR [rbp-0x9],0x0
さて、見ての通り大体似たようなコードになってるのがわかりますね。
まずは、変数dの初期化に相当するアセンブリを読んでいきましょうか。
その前に、皆さんにはASCIIコードについて知ってもらう必要があります。
ASCIIコードとは、文字コードの一種なのですが、英文字+記号+制御コードが数に対応付けられています。
以下にASCIIコードの対応表を載せておきます。
(あまりするべきではないのですが、以下の表は自作エミュレータで学ぶx86アーキテクチャ コンピュータが動く仕組みを徹底理解!に記載されているものを持ってきました。この本、かなりの良本なのでぜひ一度読んでみることをオススメします。)

さて、この表の見方ですが、とても簡単です!
例えば、0x20という16進数があったときに、これがどの文字に対応してるかを知りたいとします。
すると、0x20の上位桁は2で、下位桁は0です。
なので、SPACEであることがわかると思います。
ちなみに、SPACEは空白なので、空白文字( )です。
このようにして、使います。
さて、この表を持ってきた理由ですが、そもそも文字(英文字)はC言語やアセンブリではASCIIコードが扱われます。
なので、ASCIIコードがわかれば文字がどのように扱われているかがわかるということです!
そんなわけで、この表を使いながら一行ずつアセンブリを読み解いていきましょう。
まず、mov BYTE PTR [rbp-0x1e],0x48の行です。
これは、まず0x48をASCIIコードを用いて文字に直します。
すると、0x48はHであることがわかります。
なので、rbpレジスタに格納されているアドレスから0x1e引いたアドレス先の値にH(0x48)を代入していることがわかります。
さて、他の行も試しに16進数を文字に直すことだけやってみましょうか。
すると、0x65はe、0x6cはl、0x6fはoになっています。
まとめてみると、ちゃんと「Hello」になっていますね。
それ以外、余計なものは処理されていないこともわかります。
さて、ここで一度本当に代入がされているかを一度確認してみましょう。
x /5c $rbp-0x1eというコマンドを実行してみてください。
すると、以下の図のように画面に出力されたはずです。

ちなみに、先ほどのコマンドの意味ですが、/の後ろに5cと書くことによって、5文字分出力という意味になります。
さらに後ろの$rbp-0x1eはアドレスですね。
これで、gdbを使って変数dの初期化についてみることができましたね。
この調子で残りの2行分も見ていきましょう!
次は変数eの初期化ですね。
ここも、先ほどと全くわかりません。
同じように、16進数を文字に直すと、0x57はW、0x6fはo、0x72はr、0x6cはl、0x64はdとなっていることがわかります。
また、最後の0x0を文字に直すと、ちゃんとNULL文字(\0)になっていますね。
gdbのコマンドx /6c $rbp-0x19を実行してみても、以下の図のようにちゃんと代入されていることがわかります。

さて、最後ですね。
movabs rax,0x726f576f6c6c6548
いきなり全く違いますが、大丈夫です、すごく簡単です。
movabsですが、これはこのサイトにこのように記載されています。
「In 64-bit code, ‘movabs’ can be used to encode the ‘mov’ instruction with the 64-bit displacement or immediate operand. 」
つまり、movでオペランドが64 bitで扱う場合にのみ、明示的にmovをmovabsとしているようです。
なので、単なるmovと変わりません。
よって、0x726f576f6c6c6548とめちゃくちゃ長い16進数をただraxレジスタに格納しているだけという意味になります。
さて、この0x726f576f6c6c6548ですが、これも文字に直してみましょう。
すると、「roWolleH」になります。
おや?これ逆になっていますね。
ですが、これが正しいんです!
というのも、どうやら値を格納する際には、1 byteづつ、16進数の場合は下位桁のほうからいれてくようなんです。
つまり、格納される順番としては、0x726f576f6c6c6548の場合、48、65、6c、6c、6f、57、6f、72となります。
すると、ちゃんと正しい順番になっていることがわかりますね。
さて、後々しっかりと格納されていることを確認しますが、その前に次の行です。
mov WORD PTR [rbp-0xb],0x646cも先ほどと同様に、0x646cは文字に直すと、dlですね。
最後の行ですが、ここでもう皆さんお分かりですね?
そう!NULL文字が入っているんです!
先ほど、C言語のソースコードの12行目に相当するアセンブリではNULL文字が格納されなかったのに対して、ソースコードの14行目ではNULL文字が格納されているんですよ!
つまり、12行目と14行目の書き方には、NULL文字が勝手に入ってくれるのか、くれないのか、という明確な違いがあるんです!
なので、文字を扱う際にはNULL文字には気を付ける必要があるんです。
さて、それじゃあ最後にちゃんと文字が格納されているかを確認しましょうか。
x /11c $rbp-0x13を実行することで、以下の画面のようになるはずです。

見ての通り、ちゃんと(自分たちが思っている)正しい順番で文字が入っているのが確認できましたね。
まとめ
さて、これで配列については以上です。
どうでしたか?配列について理解できましたか?
恐らく、ここまで深く配列について考えたことがある人は少なかったと思いますが、一度このようにして考えてみると、今まで不明確なイメージでとらえていた配列が正確なイメージでとらえることができたのではないでしょうか。
(ちなみに、このようなことをして実際の配列を知るまで、自分は配列のことを、座標や図形に例えて考えていました。)
それでは、まとめます。
配列とは、指定した型名のサイズで、指定した数分のメモリを確保しているものです。
また、indexを指定することによって、確保したメモリの先頭アドレスからindex×指定した型のサイズの場所の値を操作することができる。
文字列は、文字の配列であることから、配列を用いることで扱える。
また、文字列の最後はNULL文字(\0)が入り、これが文字列の終端を意味する。
逆に言えば、これがないと文字の表示がおかしなことになったりする。
さて、こんな感じですかね。
以上で、配列の説明を終わります。
ここに関しても、「わからない」、「日本語がおかしい」とかがあればLINEかコメント機能を使用して教えてくれればありがたいです。
それでは、おつかれさまでした。
お詫び
内容がCentOSとUbuntuで異なるようです。
もし仮に、演習をしていて演習通りにならないなと思ったのであれば、この文章を読むことによって、原因が判明すると思います。
具体的には、CentOSとUbuntuでは文字がメモリ上に配置されるときに違いができ、それによって想定していた結果にならないというものです。
以下の図にCentOSとWSL(Ubuntu)の環境での逆アセンブリの結果を示します。

一見同じように見えるコードですが、[rbp-0xNN]の部分に注目してみると確かに違うことがわかります。
以下の図に、CentOSの逆アセンブリの結果のアドレスに赤線を引いたものを示します。
これを見ると、CentOSの方は、0xNNの部分が連続になっているように見えますが、連続にはなっておらず、「0x25~0x21」と「0x2b~0x26」とわかれていることがわかります。

以下の図に、Ubuntuの逆アセンブリの結果のアドレスに赤線を引いたものを示します。
これを見ると、先ほどのCentOSとは違く、「0x1e~0x14」とアドレスが連続になっていることがわかると思います。

以下の図に、メモリとメモリ上の値について注目したものを示します。

この図をみると、先ほどまでの図よりも値の配置のされ方が違うことがよくわかると思います。
ここで、puts関数について考えると、puts関数は文字列の先頭アドレスから読み取り始め、NULL文字(\0)まで読み取ります。
なので、下のUbuntuの場合は、Helloの先頭アドレスを渡すと、Worldの後ろにあるNULL文字まで読み取ります。
逆に、上のCentOSの場合は、Helloの先頭アドレスを渡すと、Helloのoまで読み取り、次にこの図からはわかりませんが、もしoの後ろにNULL文字があった場合、そこで読み取りが終了します。
以上が、CentOSとWSL(Ubuntu)での動作の違いです。
あくまで、一例ですが恐らくどちらか似たような動作になると思います。
また、この章で言いたかったことは、「値はメモリ上に配置される」、「文字列はNULL文字で終わる」ということです。
上のCentOSの場合で考えると、もし仮にHelloよりも前のアドレスに重要なデータがNULL文字を挟まずに格納されていた場合、そのデータも一緒に出力されてしまいます。
このような、プログラムは大変な脆弱性を持つものとなってしまうので、たとえC言語でプログラムを書かなかったとしても、知識として知っておいて欲しかったのです。
そもそも構造体とは?
構造体とは、複数の変数をまとめて、一つの変数として扱うものです。
例えば、文字列を保持する変数labelと値を保持する変数valがあったとします。
今までであれば、これら二つの変数を以下のように宣言して別々のものとして扱うはずです。
char label[20];
int val;
これを、構造体を使うことによりまとめて扱うことができます。
例えば、構造体の名前をboxとするとします。
すると、先ほどの変数のlabelの値が知りたいのであれば、「boxのlabelはなに?」とするような扱い方ができるようになります。
こうすることによって、バラバラだった変数を一つにまとめることで、コードの可読性があがります。
他にも、複数の要素(変数)で構成された変数を簡単に作成することができるという利点もあると思います。
それでは、次の演習で試してみましょう。
演習
下準備
以下のコードをファイル名ex3.cとして書いて、cprogディレクトリに保存してください。
# include <stdio.h>
int main(){
struct box {
char label[20];
int val;
};
struct box box1={"box1", 2};
printf("box1:\t%s\t%d\n", box1.label, box1.val);
box1.val = 1;
printf("box1:\t%s\t%d\n", box1.label, box1.val);
typedef struct box box;
box box2={"box2",1};
printf("box2:\t%s\t%d\n",box2.label, box2.val);
puts("");
typedef struct parameter{
char label[20];
int x;
double y;
}para;
para p1={"p1",1,1.0};
para p2={"p2",2,2.0};
printf("%s:\t(%d , %lf)\n",p1.label, p1.x, p1.y);
printf("%s:\t(%d , %lf)\n",p2.label, p2.x, p2.y);
typedef struct parameter2{
char label[20];
double x;
int y;
}para2;
para2 p3={"p3",1.0,1};
printf("%s:\t(%lf , %d)\n",p3.label, p3.x, p3.y);
puts("");
printf("p1: %ld\tp2: %ld\tsizeof(p1)==sizeof(p2): %d\n",sizeof(p1),sizeof(p2),sizeof(p1)==sizeof(p2));
printf("p1: %ld\tp3: %ld\tsizeof(p1)==sizeof(p3): %d\n",sizeof(p1),sizeof(p3),sizeof(p1)==sizeof(p3));
printf("char: %ld\tint: %ld\tdouble: %ld\n",sizeof(char),sizeof(int),sizeof(double));
return 0;
}
次に、gcc -g -o ex3 ex3.cを実行してコンパイルします。
これで準備完了です。
学んでほしいこと
今回は、先に学んでほしいことについてあげます。
- 構造体(struct)の使い方
- typedefの使い方
- sizeofの使い方
- 構造体のメンバの並びによる構造体のサイズの違い
この4つです。
また、今回に関しては基本的にコードを読み、実行結果を予測し、実行結果をみて考えるような手順を踏んでいきたいと思います。
コードを読むその1
さて、まずはコードを読みましょう。
最初は、あまり読み取れないかもしれませんが、ある程度のコードの塊を見て、やりたいことがなんとなくわかるかもしれません。
人が書いたコードは、自身が書いたコードに比べて読むのが大変ですが、ある程度イメージしながら読めるようになると、かなり楽に読めるようになると思います。
とはいっても、ある程度基本的なコードの書き方がわかっていないと読むことすらできないことが多かったりします。
そんなときは、もちろん調べながら読んだりするわけですが、個人的にはまずコードの全体像を一度見てから、少しずつ細かく見ていく方法がよいと思っています。
イメージ的には、マトリョーシカのように外側から段々と小さい内側を見ていく感じですかね?
本当はそのような読み方もやってみたんですけど、今回のコードに関しては順番に見ていく方が早いので順番に見ていきます。
それでは、読んでいきましょう。
まずは、3行目から6行目ですね。
struct box {
char label[20];
int val;
};
ここで、20文字分のlabelという変数と、int型のvalという変数で構成されているboxという名前の構造体を定義しています。
構造体の宣言の仕方は、以下の通りです。
struct 構造体タグ名 {
メンバ1;
メンバ2;
・・・
メンバN;
};
構造体タグ名の名前の付け方は、普段の変数名の付け方と変わりません。
メンバは、型名 変数名;のように書きます。
次に8行目です。
struct box box1={"box1", 2};
ここで、先ほど宣言したbox型の変数名box1という変数を宣言しています。
struct boxの部分を型名と考えると、box1が変数名になっているのがわかりやすいと思います。
また宣言と同時に、box1のlabelを「box1」という文字列と、box1のvalを「2」という値で初期化しています。
これは、以下のように書き直すこともできます。
struct box box1;
box1.label="box1";
box1.val=2;
このとき、box1という構造体のメンバを使用する場合には、<構造体の変数名>.<メンバ名>のように「.」を使うことで、メンバを扱えます。
この「.」のことを、ドット演算子あるいはメンバ参照演算子と呼びます。
次に、10行目です。
printf("box1:\t%s\t%d\n", box1.label, box1.val);
ここでは、見ての通り実際にprintf関数を使用して、box1のlabelとvalの値を出力して値が代入されていることを確認してます。
ちなみに、
box1:\t%s\t%d\nの部分の「\t」と「\n」は、エスケープシーケンスと呼ばれるもので、出力される際に対応した制御コードに置き換わります。
「\t」の場合はタブに、「\n」の場合は改行に置き換わります。
さて、この行の出力はどうなるでしょうか?
少し考えたら以下の答えと書かれている部分をクリックして、開いてみてください。
答え
box1: box1 2
どうでしょうか?
なんとなく、構造体の扱い方がわかってきた気がしませんか?
それでは、次は12~14行目です。
box1.val = 1;
printf("box1:\t%s\t%d\n", box1.label, box1.val);
まあ、先ほどメンバの扱い方について話したので、ほぼわかると思います。
box1.val=1;では、見ての通りbox1のvalに1を代入していますね。
さて、それじゃあ、printf("box1:\t%s\t%d\n", box1.label, box1.val);の出力結果はどうなるでしょうか?
答え2
box1: box1 1
もちろん、こうなりますよね。
次は、16行目です。
typedef struct box box;
ここで、なにやら始めてみる気もするtypedefというものが出てきましたね。
これは、すでに定義されている型名に新しい型名を付けて定義することができるというものです。
使い方は、typedef <定義されている型> <定義する新しい型名>;です。
つまり、この行ではstruct boxという型名をboxという型名で使えるようにしているということです。
次に、17行目を見てみましょう。
box box2={"box2",1};
非常に、8行目と似ていますが、8行目と違ってstructがありません。
これは、16行目でstruct boxをboxとして使えるようにしたからです。
なのでこの行では、3~6行目で宣言した構造体を用いて、box2という変数名で宣言し、box2.labelをbox2、box2.valを1で初期化しているということになります。
19行目では、そのようにして宣言したbox2が正しく使えることを値を出力して確認しているだけです。
printf("box2:\t%s\t%d\n",box2.label, box2.val);
もちろん、この出力結果は以下の通りになります。
box2: box2 1
コードを読むその2
さて、ここまでで構造体の基本的な使い方がわかったと思います。
次からの行では、構造体を使う際にメンバ並びによって構造体のサイズが異なることについてを中心に話を進めていきます。
それでは、21行目からです。
puts("");
とはいっても、これは大したことはしていません。
結果から言ってしまえば、改行を出力しているだけです。
前回、puts関数は文字をNULL文字まで出力して改行すると、話しました。
すると、もし仮にNULL文字だけ指定して出力するとどうなるでしょうか?
答えは、改行のみを出力します。
このような、コードを一行追加してあげるだけで、出力結果の見やすさは格段に上がることが多いです。
可能な限り、見やすく綺麗なコードと出力が書けるようになると良いですね。
次は、23~27行目です。
typedef struct parameter{
char label[20];
int x;
double y;
}para;
ここでは、もちろん構造体を宣言しているのですが、同時にtypedefで型の宣言もしています。
よりわかりやすく書くと、以下のようになりますね。
typedef struct <構造体型名>{
メンバ;
}<typedefでつける型名>;
このようにして、構造体の宣言と型の宣言を同時に行うこともできます。
次に、29~33行目です。
para p1={"p1",1,1.0};
para p2={"p2",2,2.0};
printf("%s:\t(%d , %lf)\n",p1.label, p1.x, p1.y);
printf("%s:\t(%d , %lf)\n",p2.label, p2.x, p2.y);
ここでは、p1とp2の構造体の宣言と初期化を行い、printfで出力しています。
それじゃあ、次は35~43行目までまとめて見ていきましょう。
typedef struct parameter2{
char label[20];
double x;
int y;
}para2;
para2 p3={"p3",1.0,1};
printf("%s:\t(%lf , %d)\n",p3.label, p3.x, p3.y);
ここでも、同様に構造体の宣言をして、構造体の変数を宣言と初期化を行って、出力をしています。
が、注目するべき点はそこではありません。
23~27行目と、35~39行目を比べてみましょう。
typedef struct parameter{
char label[20];
int x;
double y;
}para;
typedef struct parameter2{
char label[20];
double x;
int y;
}para2;
構造体の型名は確かに違うのですが、メンバをよく見ると、変数の並びかたが違うことがわかります。
paraの方は、char・int・doubleの並び順になっています。
しかし、para2の方は、char・double・intの並びになっています。
さて、確かに並びが違いますが、ぱっと見では全く違わないと思えます。
ですが、この時点で大きな違いが出ているのです!
最後に、47~49行目を見ていきましょう。
printf("p1: %ld\tp2: %ld\tsizeof(p1)==sizeof(p2): %d\n",sizeof(p1),sizeof(p2),sizeof(p1)==sizeof(p2));
printf("p1: %ld\tp3: %ld\tsizeof(p1)==sizeof(p3): %d\n",sizeof(p1),sizeof(p3),sizeof(p1)==sizeof(p3));
printf("char: %ld\tint: %ld\tdouble: %ld\n",sizeof(char),sizeof(int),sizeof(double));
さて、やたらと長いprintf関数が3つも並んでいます。
さて、違いの説明をする前にsizeof関数について説明しておきます。
sizeof関数は関数名の通り、引数のサイズを調べ、結果を返り値とする関数です。
例を挙げて、わかりやすく説明しましょう。
以下のようなコードがあったとします。
int main(){
return sizeof(int);
}
このとき、このプログラムを実行した返り値はいくつでしょう?
正解は、4です。
これは、intのサイズが4バイトであることからそういえます。
つまり、sizeof関数がint型のサイズを調べ、その結果をバイト数として返したものが実行結果になっているといえます。
さて、なんとなくsizeof関数についてわかってもらえたでしょうか?
それでは、本題に戻ります。
typedef struct parameter{
char label[20];
int x;
double y;
}para;
typedef struct parameter2{
char label[20];
double x;
int y;
}para2;
paraとpara2は、それぞれchar×20とintとcharで構成されています。
違いは、メンバの並び順だけです。
まずは、paraのサイズを考えてみましょう。
charは1バイトです。
intは4バイトです。
doubleは8バイトです。
さて、paraのサイズはいくつでしょう?
正解は?
32バイトです!!まあ、これは単純に、1×20+4+8をすればよいだけですね。
さてすると、もう47行目はわかるのではないでしょうか?
printf("p1: %ld\tp2: %ld\tsizeof(p1)==sizeof(p2): %d\n",sizeof(p1),sizeof(p2),sizeof(p1)==sizeof(p2));
まず、一つ目の値はsizeof(p1)です。
p1の型はparaです。
そして、paraのサイズは先ほどの答えですね。
さて、ここでもしかしたら疑問に思う人もいるかもしれないので、言っておきます。
たとえ、変数の中の値がいくつであろうと、その変数自体のサイズは変わりません!
なぜなら、すでに確保してあるメモリの範囲内に値を入れるのですから、大元の確保してあるメモリの範囲は変わりませんよね。
イメージ的に言えば、箱の中にものを入れても箱の大きさは変わらないみたいな感じです。
また、もとのサイズより大きい値を代入しようとした場合は、もとのサイズの最大値になります。
さて、このことを踏まえて残り二つを考えると、sizeof(p2)の結果も32だとわかります。
そして、sizeof(p1)==sizeof(p2)は32==32と置くことができます。
そして、==は両辺が等しい場合には1になるので、sizeof(p1)==sizeof(p2)の結果は1となります。
実行してみよう
さて、ここまで説明されても、やっぱり48と49行目は同じになりそうな気がします。
なので、実行結果から考えることにします。
以下に実行結果を示します。
(実は、ここの実行結果は32bitOSと64bitOSで異なります。以下の実行結果は64bitOSの実行結果です。)
box1: box1 2
box1: box1 1
box2: box2 1
p1: (1 , 1.000000)
p2: (2 , 2.000000)
p3: (1.000000 , 1)
p1: 32 p2: 32 sizeof(p1)==sizeof(p2): 1
p1: 32 p3: 40 sizeof(p1)==sizeof(p3): 0
char: 1 int: 4 double: 8
上の実行結果から、48行目と49行目の実行結果のみを以下に示します。
p1: 32 p2: 32 sizeof(p1)==sizeof(p2): 1
p1: 32 p3: 40 sizeof(p1)==sizeof(p3): 0
char: 1 int: 4 double: 8
すると、たしかに違っていることがわかります。
さて、これはなぜでしょうか。
実は、これはバイト境界やアラインというものが関わっています。
ざっくりと説明をすると、バイト境界というのは、何バイト毎にデータにアクセスするのかを決めた境界のことです。
また、アラインはこのバイト境界を越えてデータを配置しないようにすることを言います。
詳しくは、このサイトを見たり、調べてみるといいかもしれません。
さて、このバイト境界なのですが、64bitOSの場合、8バイトになっています。
また、C言語の構造体はこの8バイト境界になるべく収まるようにデータを配置する、つまりアラインするようになっています。
すると、paraの方では1×20バイト+4バイト+8バイトなので、1×20バイト+4バイトで8バイト境界(8×3に)収まっています。
24バイト+8バイトしても、32バイトになるので、綺麗に8バイトの倍数で収まっています。
しかし、para2の方では、1×20バイト+8バイト+4バイトなので、なにも考えずに入れてしまうと、8バイトの途中で8バイト境界をまたぐことになります。
なので、ここでアラインの処理が入ります。
1×20バイトにプラスで4バイトしているのです。
すると、24バイトとなり、次の8バイトが8バイト境界をまたがずに済みます。
ここまでで、20+4+8=32バイトなわけですが、残りのintの分、つまり4バイト残っています。
どうやら、コンパイラはアラインして余分なサイズのところに別の変数を割り当ててる訳ではないようです。
すると、32+4=36バイトになります。
しかし、実行結果では、40バイトでした。
つまり、残り4バイトどこかに付くということになります。
これは、すごく簡単で、36バイトだと8バイト境界にぴったりと収まらないために、プラスで4バイト付けているのです。
つまり、36+4バイトです。
すると、40バイトとなり、実行結果と合致することになります。
さて、まとめると
1(char)×20+4(padding)+8(double)+4(int)+4(padding)=40バイト
となっていたわけですね。
まとめ
このように、並び方を変えただけなのに、何バイトもサイズが異なってしまうことがあります。
今の時代、正直こんなことを気にする必要はほぼないと思いますが、このようなことがあるということを知ってもらえると、どこかで役に立つかもしれません。
そんなわけで、構造体についてでした。
構造体の使い方は理解できたでしょうか?
もし分かりづらいことや、なんか納得いかないところがあれば、教えてくれれば追加で教えますので、よろしくお願いします。
そんなわけで、お疲れ様でした。
おまけ
さて、ここでちょっとだけおまけです。
「実行してみよう」の最初に、32bitOSと64bitOSによって実行結果が異なると書いていました。
それについて、少しだけ解説します。
64bitか32bitかの判別についてはこのサイトを参考にしてみるといいと思います。
32bitOSで実行した場合、48行目と49行目の実行結果は同じになります。
びっくりですね笑
まあ、考えればそれは当然のことなんですけどね。
32bitOSのバイト境界は、4バイトになっています。
はい、すでにここで64bitOSとの違いがありますね。
すると、paraの場合、20+4+8と、どの変数でみても、しっかりと4バイト境界になっています。
また、para2の場合、20+8+4と、これまたどの変数でみても、同様に4バイト境界になっていますね。
なので、どこにもアラインの処理が入らず、余計なメモリのpaddingが入らないというわけです。
ポインタってなに?
ポインタとは、アドレスを格納する変数です。
イメージ的には、ショートカットと考えるといいかもしれません。
例えば、ポインタ変数pに整数型変数aのアドレスを格納しているとしましょう。
すると、変数pとaはアドレスで関連付けられていることになります。
この変数pを使用して、pに格納されているアドレスの先の値を変えることが可能です。
これにより、変数pからaの値を書き換えるということができます。
演習
下準備
以下のコードをファイル名ex4.cとして書いて、cprogディレクトリに保存してください。
# include <stdio.h>
int main(){
int a=0;
int *p1;
printf("%p\t%p\n", &a, p1);
p1=&a;
printf("%p\t%p\n", &a, p1);
puts("");
printf("a=%d\n", a);
printf("a=%d\n", *p1);
puts("");
*p1+=1;
printf("a=%d\n", a);
printf("a=%d\n", *p1);
puts("");
*p1++;
printf("a=%d\n", a);
printf("a=%d\n", *p1);
puts("");
*p1--;
printf("a=%d\n", a);
printf("a=%d\n", *p1);
puts("");
(*p1)++;
printf("a=%d\n", a);
printf("a=%d\n", *p1);
}
次に、gcc -g -o ex4 ex4.cを実行してコンパイルします。
これで準備完了です。
mallocってなに?
指定した大きさのメモリの先頭アドレスを持ってきてくれるやつだよね。
使い方を書きたいな。
ポインタと配列
*pとp[0]のお話したいな。
*(p+1)とp[1]って確か同じ意味だったからね。
構造体の配列って?
そのままの意味だよね。
多分上でやったこと理解できてれば、すんなりいけそうだよね。
まあ、ちょっと構造体の中にポインタ入れたりとか、して遊ぶと面白そうかな。
bagアルゴリズムを一部実装してみよう
軽い実装でいいや、構造体とポインタとmallocが使えるかを確認する程度で。
ここからは、全部ステップ分けて、少しずつ完成していく風に書きたいな。
キューリングを実装してみよう
上と同じかな。
ただ、キューリングのほうがよっぽど簡単な気がする。
双方向連結リストを実装してみよう
タイトル的に内容が飛びまくってるけど、最終目標はこれがいいな。
段階的に、連結リストと、単方向連結リストにして、最後に双方向連結リストにする感じで。
小ネタ
0.1を10回足しても0.1にならない
浮動小数点の誤差によって発生する。
記事としては、以下の記事がいいかも。
https://qiita.com/angel_p_57/items/24078ba4aa5881805ab2

windows on bash(WSL)のインストール
本当は、ちゃんと書こうと思ったんだけど、こんなことまでやってたら時間が足りないので、よさげなQiitaの記事を載せておきます。
ちなみに、さっきの記事の中でやる必要あるものは
- 機能の有効化
- 開発者モードの有効化 (やる必要ないかもだけど一応)
- ストアからWSLをインストール
- パッケージのアップデート
ですね。
以上のことが無事に終わったら以下のコマンドを実行しておいてください。
sudo apt -y install build-essential gdb # gcc・make・gdbをインストール
wget -P ~ git.io/.gdbinit # gdb-dashboardも一緒に使えるように
(もしこれで、コンパイルうまくできないとか、gdb-dashboardの画面になってないとかしたら、LINEでいいから言って。)
ちなみに、vimをきれいに使いたいとかいうのであれば、以下のコマンドを実行してvimをインストールして、この記事を試すといいと思う。
(テキストエディタがきれいになるだけで、やる気が全然違うと思うぞ。)
apt -y install vim
gdbの使い方
gdb-dashboardは、上のところでやってるよ。
これも、記事(これとかこれ)を紹介するだけにとどめとくわ。
一応、演習中に解説してるので、それで勘弁して。。。
(気が向いたら、ちゃんと書きます)
と思ったんだけど、少しだけ書き足します。
というのも、初期状態だとアセンブリの表記がAT&T表記で、授業でやっているIntel表記じゃないことをすっかり忘れてたんですね。
(まあ、別にどっちであろうと読めばいいだけなんだけど。)
なので、それを改善する方法だけ、やっておきます。
その方法はいたって簡単!
以下のコマンドを実行して、.gdbinitに一行書き足すだけ!!
echo "set disassembly-flavor intel" >> ~/.gdbinit
ちょっとだけ、まとまったので再度追記。
軽くコマンドについて表がまとまったので、載せておきます。
ただし、かなりざっくりとしかまとまっていないので、本当に参考程度に。
| コマンド名 | 説明 |
|---|---|
| file 実行ファイル | 指定した実行ファイルを読み込むgdb 実行ファイルじゃなくても、こうするとデバッグできる |
| run | プログラムを実行する breakpointがあったらそこで止まる。 |
| continue | 停止したプログラムの動作を再開する breakpointがあったらそこで止まる。 |
| breakpoint X | breakpointを設置する Xに関数名、もしくは*(関数名+n)、*(アドレス)を指定して使う。 |
| info breakpoints | 設置したbreakpointの情報を表示する |
| step | ソースコード基準で1行ずつ実行する |
| stepi | アセンブリ基準で1行ずつ実行する |
| next | ソースコード基準で1行ずつ実行する 関数呼び出しがあったら関数内の処理を終えた後で止まる |
| nexti | アセンブリ基準で1行ずつ実行する 関数呼び出しがあったら関数内の処理を終えた後で止まる |
| print X | Xに値を入れるとその値を表示してくれる Xに$変数名を入れてあげると変数の値を表示してくれる。 |
| set $X=Y | 変数名XにYの値を代入する |