1. 初めに
そうえばE資格の講座を去年の8月頃に完了していたことをすっかり忘れていました。去年の8月の受験はコロナの影響で中止となり、今年の2月の受験は、半年前よりコロナが流行っているのに受験するのはいかがなものか、と感じ受験を見送っていました。
今年ことは受験するぞ!ということでとりあえず勉強に励みたいと思う所存です。「E資格って何?」って人はこちらをご覧ください。
今回の記事ではディープラーニングの基礎に該当する部分の情報を簡単にまとめた内容にしたいと思います。
※本記事は、覚えやすいことを優先しているため、一部厳密ではない記載が含まれています。
2. 数学の基礎知識
ディープラーニングの基礎の一つとして、数学があります。行列と微分に関する知識がなければディープラーニングの内容を理解することはできません。私の無い知識を振り絞っておさらいをしましょう。同時に、pythonのnumpyを用いた記述方法を載せていきます。
行列
ディープラーニングの計算は基本的に行列を用います。まずは行列の復習から行います。
A=\begin{pmatrix}
a&b \\
c&d
\end{pmatrix}
上記のAが行列です。水平方向の並びを行、垂直方向の並びを列と呼びます。行がm個、列がn個並んでいる行列を m × n の行列と表現します。つまり、上記のAは2×2の行列になります。
pythonで記述すると以下のようになります。
import numpy as np
A = np.array([[a, b],
[c, d]])
行列積
続いて行列積についておさらいしていきましょう。
A=\begin{pmatrix}
a&b \\
c&d
\end{pmatrix}
B=\begin{pmatrix}
e&f \\
g&h
\end{pmatrix}
としたとき行列積ABは
AB=\begin{pmatrix}
ae+bg&af+bh \\
ce+dg&cf+dh
\end{pmatrix}
となります。Aの各行とBの各列の各要素を掛け合わせて総和を取り、新しい行列の各要素とします。そのため、Aの列数とBの行数は等しくある必要があります。
この行列式をpythonを用いて表すと以下のようになります。
import numpy as np
A = np.array([[a, b],
[c, d]])
B = np.array([[e, f],
[g, h]])
AB = np.dot(A, B)
行列の転置
行列の重要な操作に転置があります。転置を行うと、行と列が入れ替わります。例えば次の行列Aの転置行列はA^Tと表します。転置しなおすと元に戻ります。
A=\begin{pmatrix}
a&b&c \\
d&e&f
\end{pmatrix} \\
A^T=\begin{pmatrix}
a&d \\
b&e \\
c&f
\end{pmatrix}
この行列式をpythonを用いて表すと以下のようになります。
import numpy as np
A = np.array([[a, b, c],
[d, e, f]])
print(A.T)
"""
[[a, d],
[b, e],
[c, f]]
"""
微分
行列の次は微分について復習していきましょう。微分とは、一言でいえばある関数上の各点における変化の割合のことです。関数のある点がx方向に対してこれだけ傾いている、y方向にこれだけ傾いている、z方向にこれだけ傾いているというのが重要になります。
ディープラーニングでは、この傾きを利用しパラメーターをどのように変更すればよいかを決定します。
\frac{f(x + Δx) - f(x)}{Δx}
上記が関数f(x)の微小な変化Δxに対する変化の割合です。また、Δxを限りなく0に近づけたときの導関数f'(x)は以下のようにあらわせます。
f'(x) = \lim_{Δx \to 0} \frac{f(x + Δx) - f(x)}{Δx}
もちろん、関数f(x)が微分可能でないと導関数f'(x)を導くことはできませんが、その辺の話は今回は省きます。ちなみに導関数f'(x)は以下のようにも書くことができます。
f'(x) = \frac{d}{dx}f(x)
3. ディープラーニングとは
ディープラーニングを用いていろいろなことができるようになりました。例えば画像認識、2012年にトロント大学が物体認識の精度を競う国際コンテスト「ImageNet Large Scale Visual Recognition Challenge(ILSVRC) 2012」で断トツの結果を出したことはあまりに有名です。この画像認識の領域は、車の自動運転のカメラの情報を処理するのに利用されたり、医療現場でガンの早期発見に役立ったりなど社会に変革をもたらしています。
また、翻訳機能にも優れています。私はよくディープラーニングを利用した翻訳サイト、DeepL翻訳を使用していますが、とても上手く翻訳してくれます。~~なんだか英語の勉強をするのが馬鹿らしくなります。~~ある言語モデルは悪用されることへの懸念から完全版が非公開となったりしました。社会に与えるインパクトの大きさが伺えます。
他にも、画像・動画生成(写真の年齢・性別を変化、ディープフェイク等)や工場の異常検知等ディープラーニングがカバーしている領域はとても広いです。
では、本題です。ディープラーニングとは何でしょうか。
便利なAI? 人間の代わりに色々判断してくれるのもの? 色々と答えは思いつきますが、残念ながらその答えを私は持ち合わせていません。代わりと言っては何ですが、ディープラーニングの仕組みならば答えることができます。ずばり、生物の脳の中の機能である神経細胞の働きをコンピュータで再現したもの(=ニューラルネットワーク)を用いて学習したモデル、ととらえることができます。
以下が神経細胞の模式図(?)です。ニューラルネットワークではニューロンと呼ばれます。
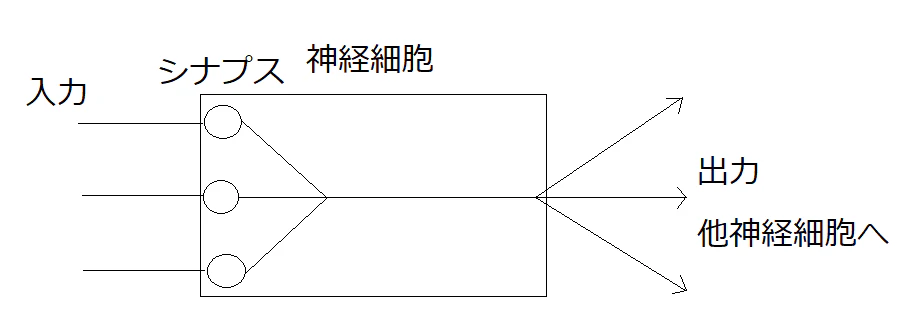
他神経細胞から入力を受け取った神経細胞では、それぞれの入力がシナプスによって処理されます。ニューラルネットワークではこのシナプスは重みづけと言われ、その字の通りに入力のどれが神経細胞にとって重要かを示しています。
例えば、ある画像に映っているものが犬かどうか判断するモデルがあったとします。おそらく、このモデルのニューロン(神経細胞)に入ってくる入力の内、犬かどうかの判断材料になる入力の重みづけ(シナプス)は大きくなり、他の重みづけは小さくなることが予想されます。
※厳密には、ニューラルネットワークの重みづけが何を表しているかを理解することはできません。そのためディープラーニングによって判断された結果の理由はブラックボックス化されます。
シナプスを通った信号が神経細胞を通って出力されます。しかし、そのまま出力される訳ではありません。信号を受け溜まった電圧の合計がある一定を超えた時のみ出力されます。この、神経細胞が活性化するかどうかの処理はニューラルネットワークでは活性化関数と呼ばれるもので処理されます。
以下がニューロンの模式図(?)です。神経細胞を模していることがわかります。
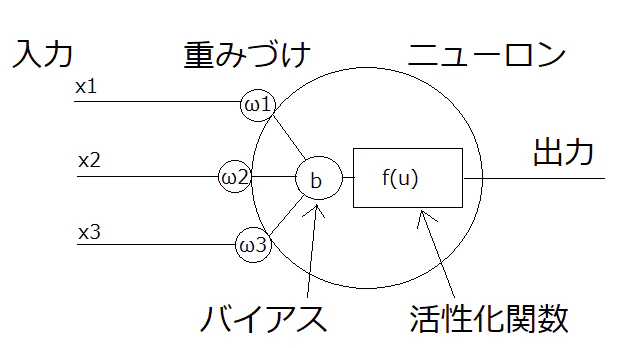
先ほど説明のなかったバイアスはそのニューロンの興奮しやすさのパラメータです。入力xと重みωの積の総和にバイアスbを足します。それをuで表すと、
u = \sum_{k=1}^{n}(x_k ω_k) + b
となります。活性化関数をfとすると、出力yは以下のように表せます。
y = f(u) = f(\sum_{k=1}^{n}(x_k ω_k) + b)
ニューラルネットワークでは、このニューロンを複数接続し層状に重ねていきます。

ニューラルネットワークにおける層は入力層、中間層、出力層の3つに分類することができます。入力層は入力を受け取って中間層にデータを渡す役割、中間層から出力層ではニューロンによる演算を行い、その結果を出力層から出力します。入力層から出力層に向けて情報が伝わることを順伝播、その逆に出力層から入力層に伝わることを逆伝播と呼びます。
上のニューラルネットワークの図の入力をX, 入力層と中間層1層目の間の重みづけをW, そのバイアスをBとするとそれぞれは以下のようになります。
\begin{eqnarray}
X &=& (x_1, x_2, x_3) \\
W &=& \begin{pmatrix}
ω_{11}&ω_{21}&ω_{31}&ω_{41} \\
ω_{12}&ω_{22}&ω_{32}&ω_{42} \\
ω_{13}&ω_{23}&ω_{33}&ω_{43}
\end{pmatrix} \\
B &=& (b_1, b_2, b_3, b_4)
\end{eqnarray}
実際に中間層一層目の重みWと入力Xの積にバイアスBを加えたUを計算すると、
\begin{eqnarray}
U &=& XW + B \\
&=& (x_1, x_2, x_3)\begin{pmatrix}
ω_{11}&ω_{21}&ω_{31}&ω_{41} \\
ω_{12}&ω_{22}&ω_{32}&ω_{42} \\
ω_{13}&ω_{23}&ω_{33}&ω_{43}
\end{pmatrix} + (b_1, b_2, b_3, b_4)\\
&=& (\sum_{k=1}^{3}x_k ω_{1k} + b_1, \sum_{k=1}^{3}x_k ω_{2k} + b_2, \sum_{k=1}^{3}x_k ω_{3k} + b_3, \sum_{k=1}^{3}x_k ω_{4k} + b_4)
\end{eqnarray}
となります。Uの中身の一つ一つが、ニューロンの中での計算結果になっていることがわかります。最後にこのUを活性化関数に入れれば出力が得られます。
代表的な活性化関数
ステップ関数
y= \left\{
\begin{array}{ll}
0 (x≦0)\\
1 (x>0)
\end{array}
\right.
def step_function(x):
return np.where(x<=0, 0, 1)

ニューロンの興奮状態を1か0かでシンプルに表現できる活性化関数がステップ関数です。実装が簡単である一方、0と1の中間の状態を表現できないというデメリットがあります。
シグモイド関数
\begin{eqnarray}
y &=& \frac{1}{1 + exp(-x)} \\
y' &=& (1-y)y
\end{eqnarray}
def sigmoid_function(x):
return 1/(1+np.exp(-x))
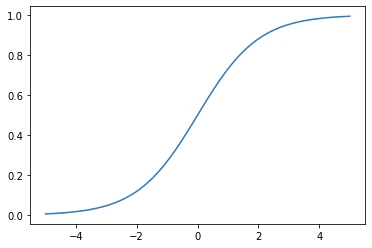
ステップ関数に比べ、0から1を滑らかに表現することができる関数がシグモイド関数です。また、微分が扱いやすいという特性もあります。
tanh関数
\begin{eqnarray}
y &=& \frac{exp(x)-exp(-x)}{exp(x)+exp(-x)} \\
y' &=& 1-y^2
\end{eqnarray}
def tanh_function(x):
return np.tanh(x)

tanh関数は-1から1を滑らかに変化する関数です。曲線の形状はシグモイド関数に似ていますが、0を中心とした対象になっており、バランスのいい活性化関数となっております。
ReLU
y= \left\{
\begin{array}{ll}
0 (x≦0)\\
x (x>0)
\end{array}
\right.\\
y'= \left\{
\begin{array}{ll}
0 (x≦0)\\
1 (x>0)
\end{array}
\right.
def relu_function(x):
return np.where(x<=0, 0, x)

x>0の範囲でのみ立ち上がるのが特徴的な関数がReLU関数です。入力xが負の値の時に0、正の値の時はそのまま出力します。シンプルかつ層の数が多くなっても安定して学習できることが知られています。
Leaky ReLU
y= \left\{
\begin{array}{ll}
0.01x (x≦0)\\
x (x>0)
\end{array}
\right.\\
y'= \left\{
\begin{array}{ll}
0.01 (x≦0)\\
1 (x>0)
\end{array}
\right.
def leaky_relu_function(x):
return np.where(x<=0, 0.01*x, x)

ReLU関数を改良したもので、xが負の領域で直線がわずかに傾いている関数がLeaky ReLU関数です。ReLUでは出力が0でになって学習が進まないニューロンが多数出現する現象が起こりますが、負の領域に勾配を設けることで回避しています。
恒等関数
y=x
回帰問題を扱うニューラルネットワークの出力層でよく用いられる関数です。出力の範囲に制限がなく連続的なため、連続的な数値を予測する回帰問題を扱うのに適しています。
ソフトマックス関数
\begin{eqnarray}
y &=& \frac{exp(x)}{\sum_{k=1}^{n}exp(x_k)} \\
\end{eqnarray}
def softmax_function(x):
return np.exp(x)/np.sum(np.exp(x))
これだけ少し毛色が違います。こちらは分類問題を解くときの出力層の活性化関数に用います。出力をすべて足し合わせると1になることがわかると思います。その性質を利用して、その出力層のニューロンが対応する枠に分類される確率を表現することができます。
誤差逆伝播法
ニューラルネットワークでは、以上のような計算を何層にも展開することで、柔軟な認識・判断能力を持つことが可能になります。そのためにも、パラメータである重みとバイアスを更新する仕組みがディープラーニングには必要になります。では、どのように値を更新したらよろしいでしょうか。
先ほどは入力を入力層から出力層へ伝播させて出力を求めました。値の更新ではその逆を行います。つまり、出力層で求められた出力と正解の値を比べ、その誤差を出力層から入力層に伝播していきます。その各層に伝播した誤差から、値をどのように更新すればよいかを求め、重みとバイアスの更新を行います。
これを何度も繰り返すことで次第にネットワークの誤差が最小になるように最適化されていきます。学習が成功したネットワークは、任意の入力に対して柔軟に認識・判断ができるようになります。以下に誤差逆伝播法の重要な要素について紹介していきます。
訓練データとテストデータ
ニューラルネットワークの学習に用いるデータは訓練データとテストデータに分類されることが多いです。訓練データはネットワークの学習に用いますが、テストデータは学習結果の検証に用います。通常は訓練データの数をテストデータの数より多くします。訓練データで学習したネットワークを用い、テストデータでよい結果を出すことが目的になります。
損失関数
出力yと正解tの誤差を定義するのが損失関数です。誤差Eが大きければニューラルネットワークが本来の状態から離れていることになります。学習はこの誤差が最小になるように進みます。
二乗和誤差
E = \frac{1}{2} \sum_{k}(y_k-t_k)^2
def step_function(x):
return 1.0/2.0 * np.sum(np.square(y - t))
出力yと正解tの差を二乗し、すべての出力層の総和を取ったものを二乗和誤差と呼びます。二乗和誤差を用いることで、ニューラルネットワークの出力がどの程度正解と一致しているかを定量化することができます。二乗和誤差は正解や出力が連続的な数であるケースに向いているため、回帰問題でよく用いられます。
交差エントロピー誤差
E = - \sum_{k}t_klog(y_k)
def step_function(x):
return -np.sum(t * np.log(y + 1e-7))
# logの中身が0にならないように微小な値1e-7を加えている
この式は分類問題で用いられる交差エントロピー誤差です。出力yの自然対数と正解値の積の総和をマイナスにしたもので表されます。
分類問題では、正解値が1が1つ、他が0となるone-hot表現になります。そのため、シグマで積の総和を取っていますが、実際は -log(y_k) のみが与えられます。
自然対数を取っている理由としては、正解値1から出力yが遠ざかるほど勾配が大きくなるためです。そのため、出力と正解の乖離が大きいときに学習速度が速くなります。
勾配降下法
損失関数により求めた誤差Eの値を利用しニューラルネットワークの値を修正していくのですが、この時に勾配降下法を用います。勾配降下法とは、ある関数f(x)があったときに、その導関数f'(x)を利用して関数f(x)の最小値のパラメータxを探す手法のことを指します。例えば、ボールは坂道を下っているとします。これは勾配があることに起因します。逆に言えば、勾配があればどっちにボールが進むべきか、どっちにパラメータxを変更すればよいかがわかります。
誤差逆伝播法のは、重みωの更新を行いたければ誤差Eを重みωで偏微分し勾配を求め変化量を決定する、バイアスbを求めたければ誤差Eをバイアスbで偏微分し勾配を求め決定します。
しかし、誤差Eから何層も離れた層の重みωとバイアスbで偏微分することは中々現実的ではありません。そこで前の層に誤差Eを入力yで微分したものを伝播します。これを用いることで例えば出力層のひとつ前の層の誤差の勾配は、以下の式で求められます。
\frac{∂E}{∂ω_{n-1}} = \frac{∂E}{∂y_{n-1}}\frac{∂y_{n-1}}{∂ω_{n-1}}
そのひとつ前の層も同様に求められます。
\begin{eqnarray}
\frac{∂E}{∂ω_{n-2}} &=& \frac{∂E}{∂y_{n-2}}\frac{∂y_{n-2}}{∂ω_{n-2}} \\ &=& \frac{∂E}{∂y_{n-1}}\frac{∂y_{n-1}}{∂y_{n-2}}\frac{∂y_{n-2}}{∂ω_{n-2}} \\ &=& \frac{∂E}{∂ω_{n-1}}\frac{∂y_{n-2}}{∂ω_{n-2}}
\end{eqnarray}
最適化アルゴリズム
先ほどボールを例にとって勾配降下法の話をしましたが、実際は少し違います。ボールの例で行くとボールには慣性があるため、常に勾配の方向に降りるわけではありませせん。また、たどり着いた場所が真の最小値になるとは限りません。
確率的勾配降下法(SGD)
ω ← ω - μ\frac{∂E}{∂ω} \\
b ← b - μ\frac{∂E}{∂b}
確率的勾配降下法は学習係数と勾配をかけてシンプルに更新量を求める最適化アルゴリズムです。訓練用のデータの中からランダムにサンプルを選ぶことができるため、局所最適解にとらわれにくいというメリットがあります。一方で、学習の進行に応じた柔軟な更新量の調整はできません。
Momentum
ω ← ω - μ\frac{∂E}{∂ω} +αΔω\\
b ← b - μ\frac{∂E}{∂b} +αΔb
確率的勾配降下法に慣性項を付け加えたアルゴリズムです。αが慣性の強さ、Δωは前回の更新量になります。これにより急激な変化が妨げられ、より滑らかな更新が実現できます。
AdaGrad
h ← h + (\frac{∂E}{∂ω})^2\\
ω ← ω - μ\frac{1}{\sqrt{h}}\frac{∂E}{∂ω}
学習が進むとhが大きくなり更新量が徐々に小さくなるアルゴリズムです。これにより最初は広い領域で探索し、次第に探索範囲を絞るという効率のいい探索が可能になります。ただし、更新量は常に減少するため、途中で更新量がほぼ0になってしまい学習がそれ以上最適化されなくなってしまうことがあります。
RMSProp
h ← ρh + (1-ρ)(\frac{∂E}{∂ω})^2\\
ω ← ω - μ\frac{1}{\sqrt{h}}\frac{∂E}{∂ω}
AdaGradの弱点に対応したものでρの存在により過去のhを適当な割合で忘れることで更新量がほぼ0になることを防ぎます。
バッチサイズ
バッチサイズとは重みとバイアスの更新を行う間隔のことです。全ての訓練データを一通り学習することを1エボックと数えます。また、あるサンプルの固まりを使用してから重みとバイアスの更新を行うのですがそのかたまりをバッチ、バッチに含まれるサンプル数をバッチサイズといいます。
バッチ学習
バッチ学習では、バッチサイズが全訓練データの数になります。つまり1エボックごとに全訓練データの誤差の平均を求め、重みとバイアスの更新を行います。ただし、局所最適解にとらわれやすいのが欠点です。
オンライン学習
オンライン学習では、バッチサイズが1になります。個々のサンプル毎に重みとバイアスが更新される学習法です。安定性に欠けますが、局所最適解にとらわれるとこは防がれます。
ミニバッチ学習
ミニバッチ学習では、訓練データを小さなかたまり(バッチ)に分離し、そのかたまり毎に重みとバイアスの更新を行います。バッチ学習と比較して局所最適解に囚われずらく、オンライン学習よりも間違った学習を行うリスクを軽減できます。
4. おわりに
いかがだったでしょうか。本当は簡単なディープラーニングをpythonで実装したものを載せたかったのですが、それはまたの機会にしておきます。
ここまで読んでいただきありがとうございました。余力があれば続きます。