この記事は、NTTテクノクロス Advent Calendar 2024 シリーズ2の10日目の記事になります。
皆さんこんにちは。NTTテクノクロスの畑です。現在はVR機器を使用した配信システム保守やAIを活用したソリューション検討などを行っています。
「Stability Matrix」はなぜできたのか
最近若干の下火感が否めないAI技術ですが、これまでの進歩速度には凄まじいものがありました。
今回はその一角を担っていた画像生成AI「Stable Diffusion」の話をするとしましょう。
画像生成AI「Stable Diffusion」がオープンソースになったことで、望む画像を生成する方法を各方面のエンジニアたちが試行錯誤し、血で血を洗う切磋琢磨の日々が送られてきました。
この記事では実際に画像生成を行うことを焦点とするため、「Stable Diffusion」の技術的な話には触れていません。そのため、もしそちら側が気になる人は以下の記事を参考にすることを推奨します。
始まりは「AUTOMATIC1111」氏が作成したWebUIでした。これが非常に優れた拡張性を有していたため、このwebUIを基盤とした様々な拡張機能が多くのエンジニアによって作られました。またその発展過程で、エンジニアたちが工夫を凝らした結果、次のような画像生成手法が確立されていきました…
checkpoint生成
「Stable Diffusion」モデルを使用してトレーニングを行い画像を自身で学習させることで、望みの画像を生成する手法。
checkpoint merge
checkpoint同士を合成することで、望みの画像を生成する手法。
ControlNet
ControlNet手法を使うことでニューラルネットワークへ追加条件を付与し、望む画像を生成する手法。
追加学習
「LoRA」や「LyCORIS」などの追加学習モデルを使用して、生成画像を望みの画面へ修正する手法。
プロンプトエンジニアリング
Stable Diffusionモデル生成時に付けられたタグを類推することで、生成画像を望む方向へ修正する手法。
一度生成した画像の一部分を入力とした画像生成を行うことで、望む画像へ近づけていく手法。
補足:
上記のcheckpointとは学習過程で作成された画像の特徴を保存したファイルを指しており、ほかAIツールではモデルと称されるものである('ω')ノ
しかし、このような手法が確立された一方で「Stable Diffusion web UI by AUTOMATIC111」を使った環境構築手順がどんどん複雑化していきました。
その結果、原初の「Stable Diffusion web UI by AUTOMATIC1111」では対応しきれない箇所が増えてきたため、様々な特色を持つwebUI([ComfyUI]・[Stable Diffusion WebUI Forge]・[Fooocus])が開発されました。
しかし今度はこれらのwebUIを管理、統括することが難しくなってきているのが現状です。
これらの問題点を解決するために「Stability Matrix」という環境構築用のアプリケーションが「LykosAI」氏によって開発されました。
今回はこの「Stability Matrix」というStable Diffusion統合環境を使用して、できるだけ簡単に「Stable Diffusion web UI by AUTOMATIC1111」環境を構築し、その中でStable Diffusionモデルの一つである、SDXLモデルを使用した動画像生成してみようと思います(^▽^)
筆者の実行環境について
筆者は以下の環境を使用して動作実験を行いました。
CPU : Intel(R) Core(TM) i7-9700K CPU @ 3.00GHz
GPU : NVIDIA GeForce RTX 3060
GPUドライバー:NVIDIA Studio Driver ver.560.94
memory : 32GB
SSD : 1TB
Stable Diffusion web UI by AUTOMATIC1111環境
version: v1.10.0 • python: 3.10.11 • torch: 2.1.2+cu121 • xformers: 0.0.23.post1 • gradio: 3.41.2 • checkpoint: 896faa18cd • WebUI State commit: c19d0443
環境構築
ここからは、画像生成AIを使用するための環境構築を行います(*'▽')
ステップ1:「Stability Matrix」のインストール(>_<)
はじめに、「Stability Matrix」のインストールをしていきましょう!
1. 次のページにアクセスします。('ω')
https://github.com/LykosAI/StabilityMatrix?tab=readme-ov-file
2. スクロールすると以下の画面があるため、自身の環境に合わせたボタンを押します。('ω')
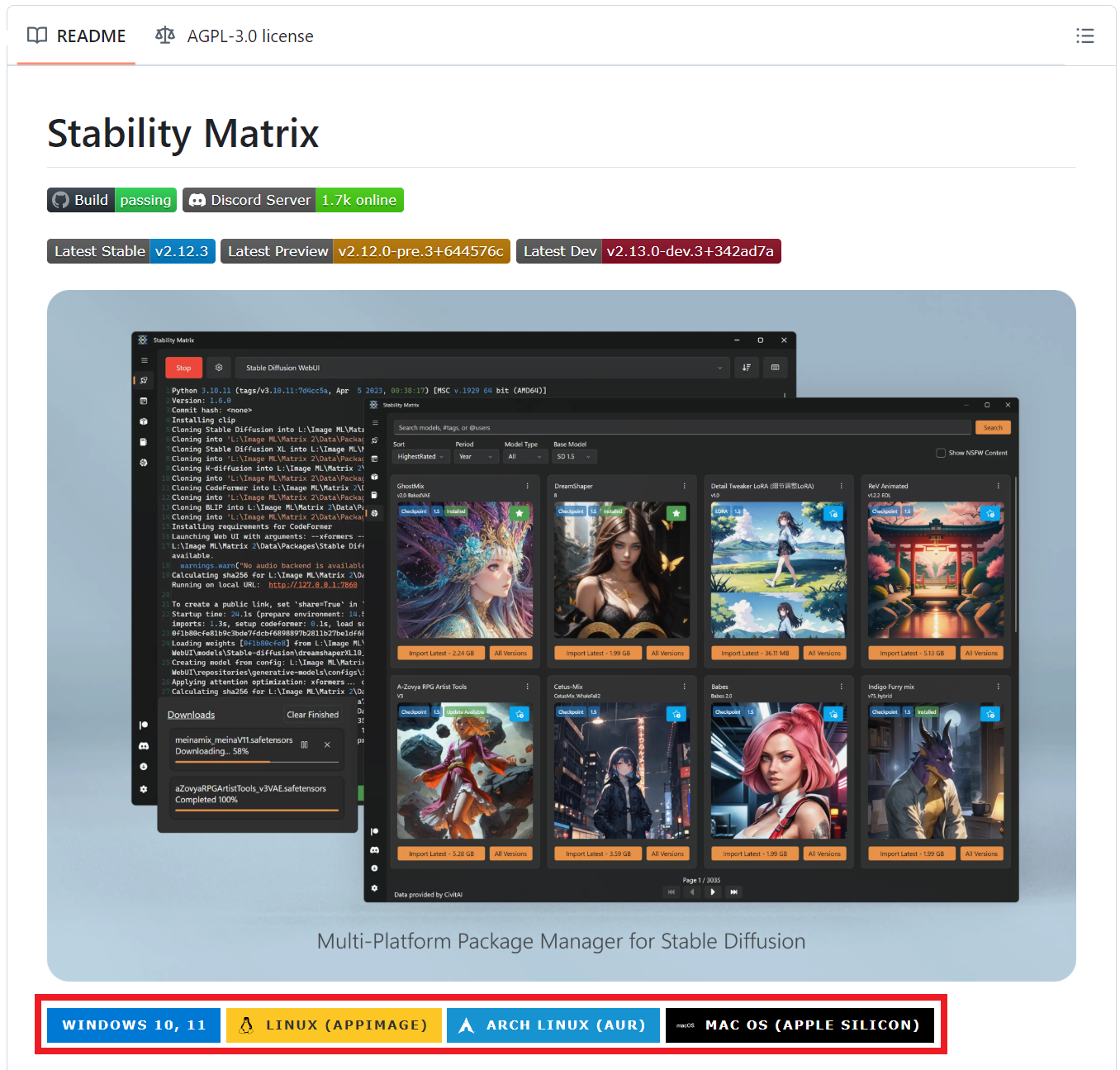
https://github.com/LykosAI/StabilityMatrix?tab=readme-ov-file
3. zipを解凍して適当な場所に置きます。('ω')
外部接続の保存デバイス(USBドライブ等)では認識しないので、注意してください。
4. 終わりです。('ω')
最近のスマホアプリよりも簡単にできました(≧▽≦)
ステップ2:「Stable Diffusion web UI by AUTOMATIC1111」のインストール(>_<)
ここから実際に使用する環境(Stable Diffusion web UI by AUTOMATIC1111)を「Stability Matrix」を使って、インストールしていきます。
1. 展開したファイルにあるexeを起動します。('ω')
起動すると以下の画面にて搭載されているGPUを読み込んで、性能を評価してくれます。
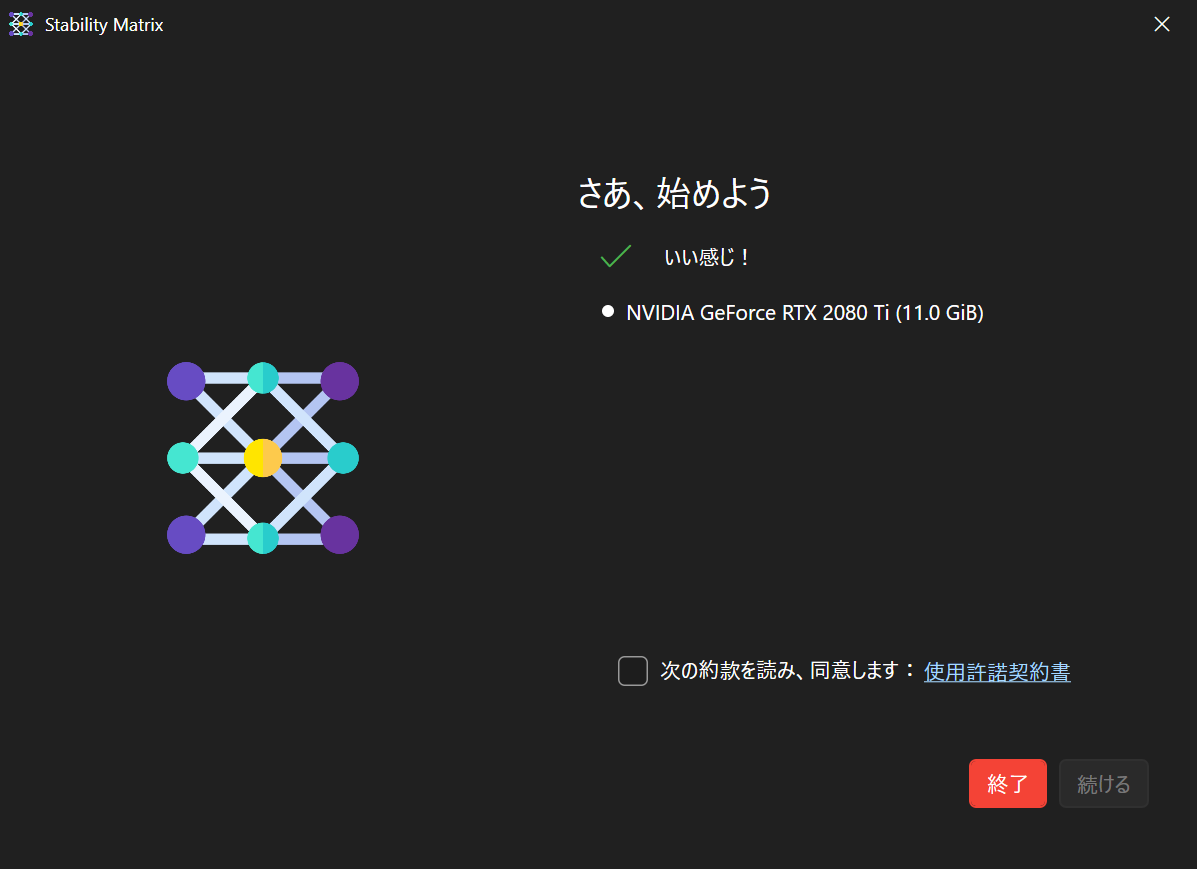
親切設計ですね。( *´艸`)
ここであまりいいことが書かれていない場合、動画像生成は難しいかもしれません。
GPUのスペックは余裕を持っておきましょう( ;´Д`)
最低でも筆者と同水準の環境はほしいところです。
2. データフォルダの選択をします。('ω')
次に以下のような画面が出るためデータを格納するフォルダを設定します。
ここで選択した場所がStable Diffusion関連のデータ(モデルデータや生成された画像データなど)を保存する場所になります。

Portableモードを有効にするとすべてのデータと設定ファイル、python仮想環境、Portable版Gitが同じファイル(\Data)に置かれるため、別環境などへの移行性が飛躍的に向上します。
Portableモードを有効にした場合関連データはすべてexeのあるファイル直下のDataファイルに入ります。
筆者の環境ではPortableモードのデメリットとしては少しファイル容量が増える程度のものでしたが、一部環境では動作しない場合があるそうなので注意してください。
画像生成ではそれなりのストレージ容量が必要になります。※最低でも20GB以上
余裕をもって100~300GB以上空き容量のあるストレージをお勧めします。( ゚Д゚)
3. 次にInstallするwebUIを決定します。('ω')
今回はできるだけ簡単に動かしたいので、使用難易度が低い「Stable Diffusion web UI by AUTOMATIC1111」を使用します。

必ずStable Diffusion web UI by AUTOMATIC1111をインストールしてください。
※Forgeの方を使用する場合、インストールする拡張機能が変わります。
次にこのような画面が表示されます。
本来であれば、ここで画像生成に必要なモデルをインストールするのですが、今回は推奨モデルに使いたいものがないため、閉じてしまいましょう。

そうするとStable Diffusionのインストールが開始されます。※インストール完了までしばらくかかります。
※体感30分程度(´゚д゚`)

Visual Studioの通信許可を求める通知が出ますが、許可を選択してください。
4. 画像生成に使用するモデルをダウンロードします。('ω')
インストールが完了したら、画像生成に使用するモデルをインストールしましょう!(^^)!
画像生成モデルが配布されているサイトは複数ありますが、筆者は圧倒的にcivitaiをお勧めします。
理由としては以下が挙げられます。
・モデル数が多い
・サンプル画像があるためモデルを見つけやすい
・生成例のpromptが同時に確認できる
・拡張機能によるwebUIとの連携機能が容易
https://civitai.com/models/261336/animapencil-xl
上記のURLにアクセスし、下記のモデルをダウンロードしましょう
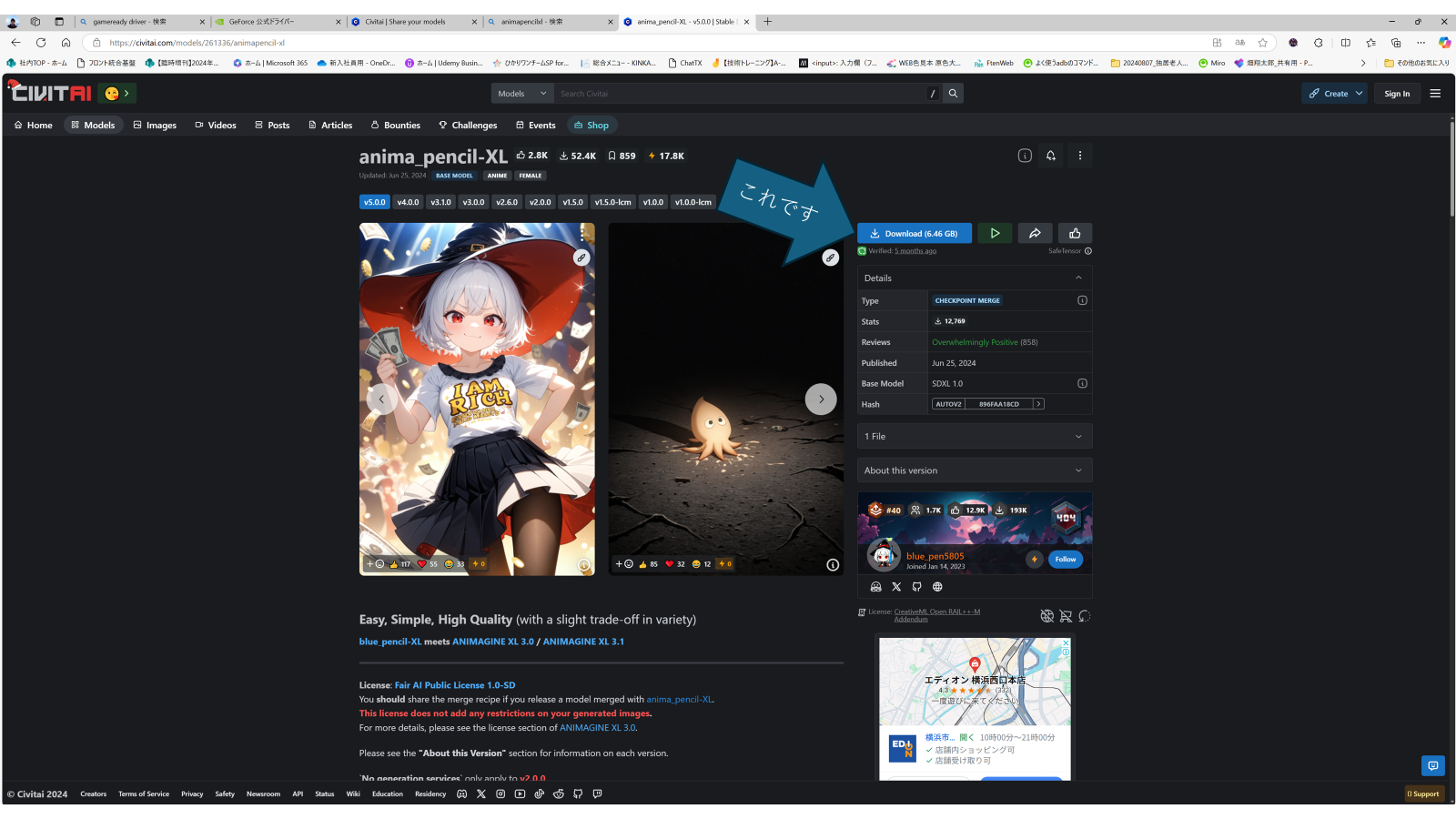
ダウンロードしたモデルファイルを以下に配置してください。
\Data\Models\StableDiffusion
そんなこんなで「Stable Diffusion web UI by AUTOMATIC1111」のインストールが完了しました。
5. 最後に「Stable Diffusion web UI by AUTOMATIC1111」を起動してみましょう!

このような画面が出てきますのでLaunchボタンを押してください。
しばらく待つと自動的に起動すると思います。
歯車マークを押すと「webUI」のオプションが選択できます。
オプション「--share」を有効にしていると、自動的にwebUIが表示されません。
※--shareオプションは同一ネットワーク上にパブリックでwebUIを立ち上げるオプションです。
その場合、表示されているlocalhostから始まるリンクを踏むか、右上の「webUIを開く」ボタンを押してください。
PC環境によっては起動に失敗する場合があります。
その場合はRuntimeErrorと表示されている部分の指示に従うことでエラーを回避できます。
※オプションを使ってエラーを無視する方法もありますが、おすすめしません。
エラーの種類は多岐にわたりますが、大抵の場合はグラフィックドライバー関連のエラーであることがほとんどです。そのため何らかの問題が起こった場合ひとまずグラフィックドライバーを最新化することをお勧めします。
それ以外の代表的なエラーの解決方法を載せている記事が以下にありますので、参考にしてみてください。
proxy環境下で実行する際にはコードへ変更を加える必要があります。以下を参照してコードを変更してみてください。
https://bibohlog.ltt.jp/set-proxy-on-stable-diffusion-webui/
6 . 以下のような画面が出れば起動成功です。(^ω^)

ページを開いた際に、右側にエラー表示がある場合は正常に起動することができていないのでコンソールを確認してみてください。
このような場合以外にも、webUIには表示されないエラーなどはすべてコンソール側に出力されるので、問題が起これば初めにコンソールを確認することをお勧めします。
これで「Stable Diffusion web UI by AUTOMATIC1111」の環境構築は完了です!!
この時点で画像を生成する環境は整いました!!
ヤタ━━━━━ヽ(゚∀゚)ノ━━━━━!!!!
ここからは実際に「Stable Diffusion web UI by AUTOMATIC1111」を「SDXLモデルの使用」と「動画像を生成」に最適化していこうと思います。( ^ω^)
ステップ3:「Stable Diffusion web UI by AUTOMATIC1111」のUIをカスタムする。(>_<)
Settingsタブを開き、以下の項目を追加し、Apply settingsを押下してください。

上記が完了したら、webUIを再起動してください。
※Stability Matrixにリスタートのボタンがあると思います。
次の様な画面になっていればSettingの変更は完了です。
下記にはそれぞれ各UIの説明を追記してあります。
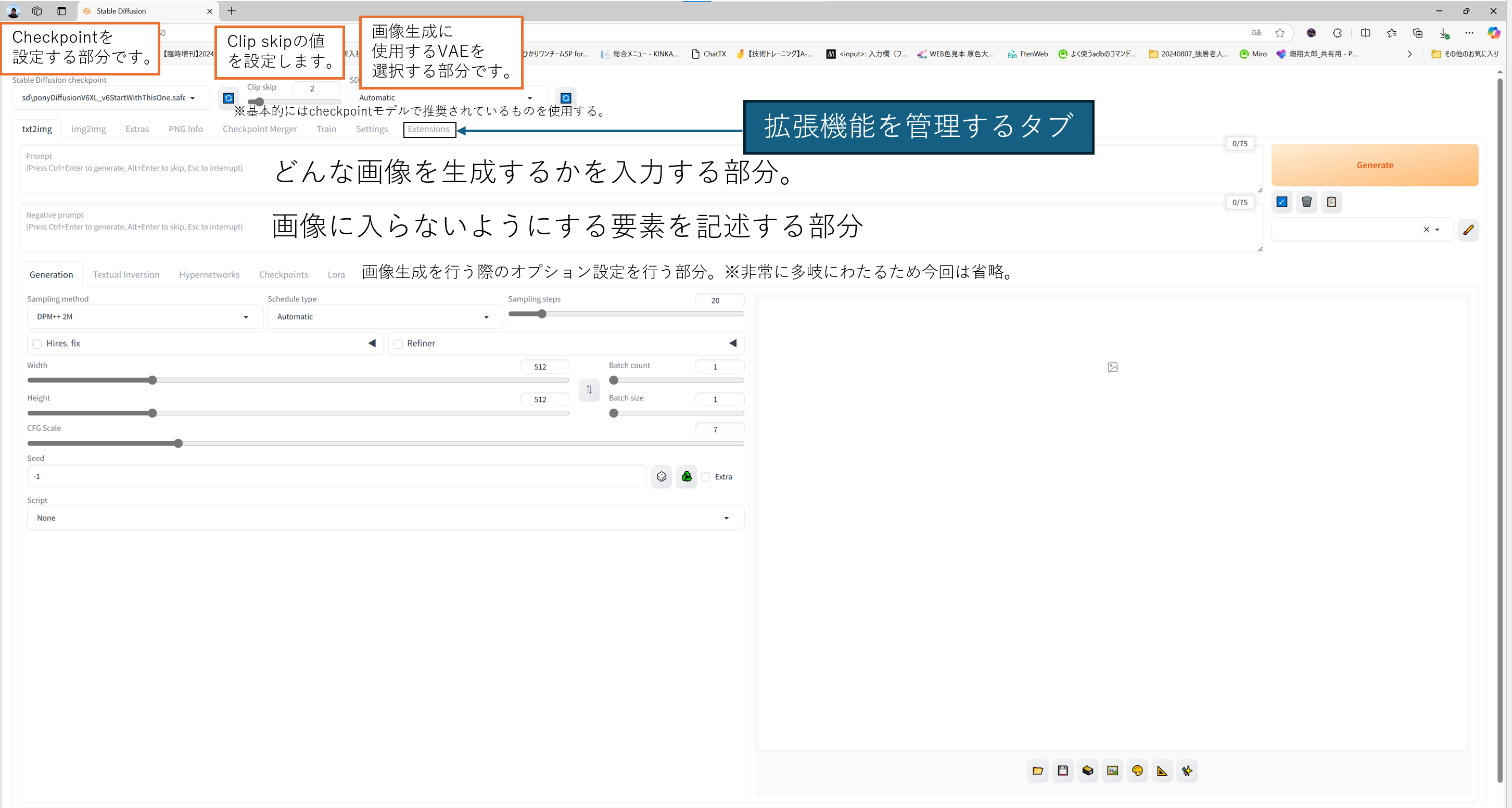
※1 「Stable Diffusion web UI by AUTOMATIC1111」の画面説明
一応説明を書いてみましたが、機能が非常に多岐にわたるため今回は基本的な部分と今回使用する部分のみ記述しています。m(_ _)m
Stable Diffusion web UI by AUTOMATIC1111の詳しい説明は、以下のサイトがすごく親切に記述してくれているので、これを参考にすると良いかと思います。
これだけで使用感が大きく変わります( `ー´)ノ
ステップ4:拡張機能「AnimeDiff」をインストール(>_<)
これまでは画像生成環境を整えてきましたので、ここからは「AnimeDiff」の拡張機能をインストールすることで、動画像生成を行えるようにしたいと思います!('ω')
大きく二つのやり方があるのですが、今回は他の拡張機能インストール時にも使えるGitHubからのインストール方法を紹介します。
先程の図※1にある「拡張機能を管理するタブ」(Install from URL)タブを開いてみましょう。すると以下のような画面になるはずです。

ここの「URL for extension's git repository」の部分に追加したい拡張機能が配布されたGitHubのURLを入力することで拡張機能がインストールできます。
以下が今回使用する「sd-webui-animatediff」のURLになります。
以下のような画面の状態でInstallを押すとインストールが始まります。

--shareオプションを使用している場合、--enable-insecure-extension-accessのオプションを追加することで、拡張機能のインストールができます。
proxy環境で作業を行っているなどで、うまくInstallできない場合はGitHubから直接ファイルをcloneし、
\Data\Packages\stable-diffusion-webui\extensions
に配置してください。
インストールが終了するとIntallボタンの下に何らかの表示が出るので、webUIをリスタートしてください。
リスタート後以下のような画面になっていれば「AnimeDiff」のインストールは完了です。
あなた:ヤタ━━━━━ヽ(゚∀゚)ノ━━━━━!!!!
と思っていたのか!!(´゚д゚`)(ブロリー感)
あなた:Σ(゚Д゚)
実はもう少しあります…
AnimeDiffに必要なmodelを自身でダウンロードして所定の場所に配置する必要があります。
以下のリンクを踏んでください。
https://huggingface.co/guoyww/animatediff/blob/main/mm_sdxl_v10_beta.ckpt
すると次のような画面が出ると思いますのでdownloadをクリックしてください。

今回はSDXLモデルを使用するため一つしか選択肢がありませんが、ほかにもいくつかモデルがあります。
ちなみにほかのAnimeDiffモデルは以下のリンクにまとめてあります。
https://huggingface.co/guoyww/animatediff/tree/main
そしてダウンロードしたファイルを以下のフォルダにコピーしてください。
\Data\Packages\stable-diffusion-webui\extensions\sd-webui-animatediff\model
これで本当に準備完了です!!!!!!!!
ヤタ━━━━━ヽ(゚∀゚)ノ━━━━━!!!!
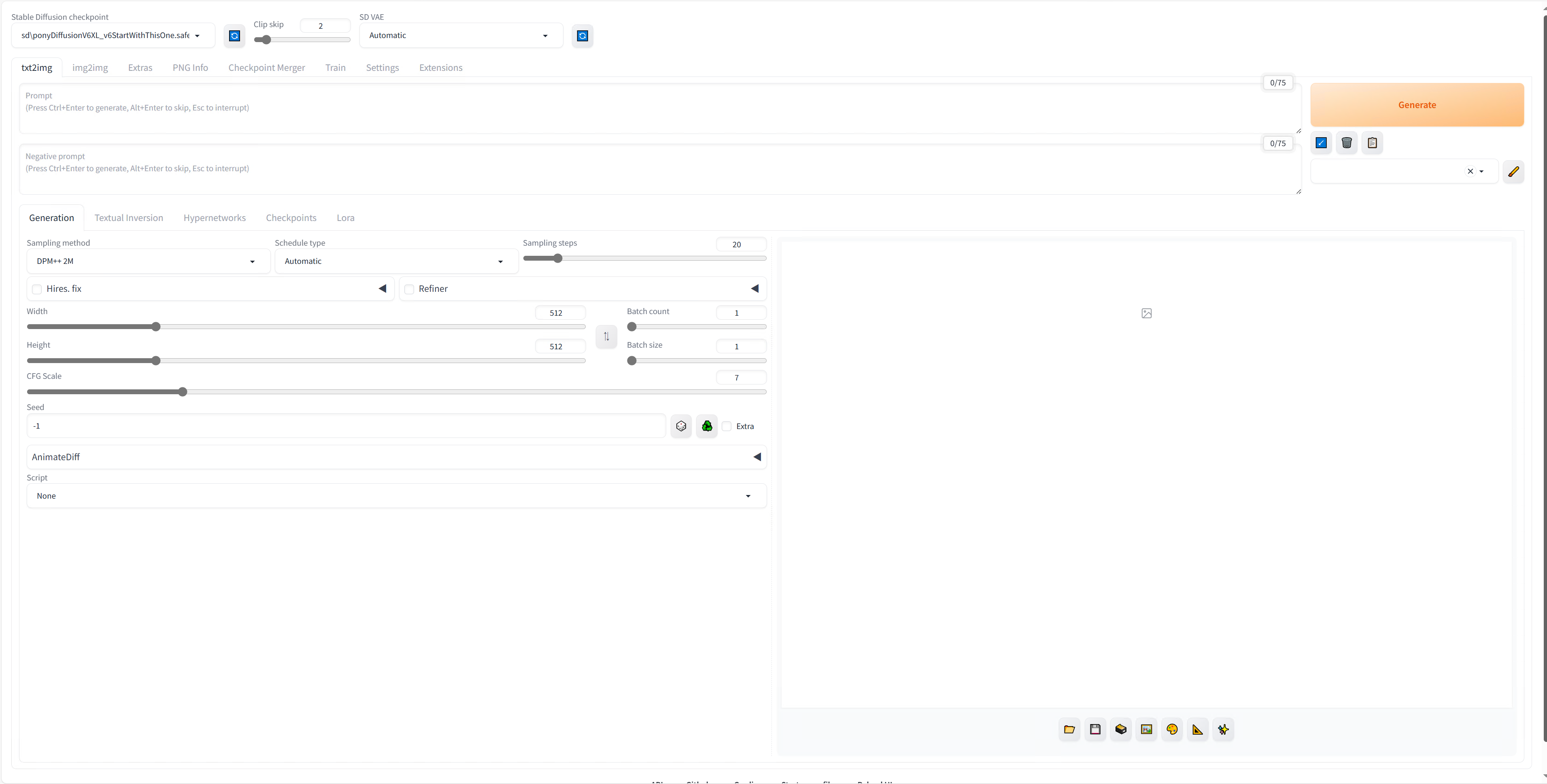
txt2imgで動画像生成を行う。
手始めにtxt2imgを使った動画像生成を行い、以下を作ってみましょう!(#^^#)

txt2imgの画像生成を行う
まずは動画像を作る前に画像生成のパラメータ設定を行うことで、自身の作りたいシーンを再現してみましょう。(*‘∀‘)
プロンプトは英語で記述してください。
学習は日本語でなく英語で行われているため、これは必須です。
単語単位で描写したいものを記述し、結果をみてから追記していくことで自身の理想に近付けていく手法をおすすめします
きれいな画像を生成するコツですが、先人たちの記述方法に習うのが賢いと思います。
生成モデルをダウンロードする画面にてインフォメーションマークのようなものがあるのですが、これを押すとその画像を生成するのに使われたプロンプトや設定を見ることができます。これを参考にすることで、きれいな画像を生成することができるようになります。
このモデルの場合masterpieceとbest qualityが非常に重要な役割を果たしています。

ほかにも様々なコツがあるので、ぜひ自身でオリジナルのプロンプトテンプレートを作ってみてください!( ^^) _U~~
筆者は以下のような設定で生成しました。参考程度に…

これで望みの画像を生成することができたなら、実際に動画像を生成してみましょう(*'▽')
動画像を生成するため「AnimeDiff」を有効化する
パラメータの設定はそのままにして、下の部分にある「AnimeDiff」の設定を以下のように変更してください。

あとは画像生成と同じ要領で実行するしましょう( ̄▽ ̄)
すると次のような画像を生成することができます。\(^_^)/
原理としてはAnimeDiffのモデルを使用することで、画像の一貫性を保ちながら1フレームずつ画像を生成、それをつなぎ合わせて連続再生させることで動画像を生成しています。
そのため非常に多くの時間がかかると思います。
この動画像を生成するために、筆者の環境では30分程度かかりました。
「AnimeDiff」の各パラメータ解説です。
各UIに注釈を追記したものが下記になります。

ここに各パラメータのさらに詳細な説明を記述します。
| パラメータ名 | 内容 |
|---|---|
| Motion module | AnimeDiffに使用されるモデルを決定する |
| Save format | 動画像をどのような形(フォーマット)で出力するかを決定する |
| Enable AnimeDiff | チェックボックスを外すとAnimeDiffの機能が無効になる |
| Number of frames | 生成する動画像の総フレーム数を決定する |
| FPS | 生成する動画像のフレームレートを決定する |
| Display loop number | git動画の繰り返し回数を決定します。※0の場合無限回となり、gifが繰り返し続けるようになります |
| Closed loop | 動画像を最初と最後でつなげるかどうかを設定します。基本的には「N<R-P<R+P<A」の順番で最初と最後がつながりやすくなります。詳細はこちらを参照してください(https://github.com/continue-revolution/sd-webui-animatediff/blob/master/docs/how-to-use.md#:~:text=motion%20modules.16-,Closed%20loop,-%E2%80%94%20Closed%20loop%20means) |
| Context batch size | モーションモジュールに一度で渡されるフレーム数の設定です。基本的にはモーションモジュールに依存した値にする必要がありますが、その際にNumber of framesの値を超えないように注意が必要です(今回であれば本来32であることが望ましいが総フレームが16のため、値を16に設定している) |
| stride | 値を大きくすることで動画像の動きが大きくなる |
| Overlap | 値を大きくすることで動画像の動きがより滑らかになる |
| Frame Interpolation | Deformの機能を使うことで、生成画像間フレーム補完を行うこれを有効にするにはDeform拡張機能をインストールする必要がある |
| Interp X | フレーム間にいくつの画像を差し込むかを設定する (例:4FPSの際に設定値を10にすると40FPSとなる) |
| Video source | ControlNetを使用したV2Vに使用します |
筆者個人の見解ですが、FPSは一桁に抑えDeformの機能を使用して、フレーム補完を行うことを推奨します。
これによって生成時間を可能な限り短くして、動画像を生成することができるためです。
以下にDeformの拡張機能のURLを添付しておくので、AnimeDiffをインストールした際と同じ方法を用いてインストールし、生成時間の違いを検証してみるのもよいと思います。
ControlNetを併用してキャラクターがダンスをしている動画像を生成する。
AnimeDiffとControlNetを併用することでキャラクターがダンスを行っている動画を生成することができます。
今回は人がダンスしている動画像を参考に、同じダンスをしている動画像生成にチャレンジしてみたいと思います(/・ω・)/
SDXLにも対応したControlNet環境設定
まずはControlNetの環境設定を行いましょう(*'▽')
1.webUIにControlNetの拡張機能をインストールする
手順としてはAnimeDiffをインストールした際と同じ方法でインストールできます。
「ControlNet」のURLは以下になります。
2.SDXL用のControlNetモデルをダウンロードする
次にControlNetで使用するモデルをダウンロードしていきます。
次のURLにアクセスしてください。
https://huggingface.co/lllyasviel/sd_control_collection/tree/main
今回は人間の骨格推定を行うopenposeと画像から奥行きを推定するdepthを使いたいと思います。
ここにある「thibaud_xl_openpose.safetensors」(openposeのモデル)と「diffusers_xl_depth_full.safetensors」(depth推定モデル)をダウンロードして以下に配置してください。('ω')
\Data\Packages\stable-diffusion-webui\extensions\sd-webui-controlnet\model
これで準備は完了です。
実際にダンスをしている動画像を生成する
流れとしては「動かす元画像を作る工程」→「動き方として参考にする動画像を入手」→「動画像生成開始」となります。
1. 踊るキャラクターがいる画像を生成する
AnimeDiffでの動画生成と同じ要領でまずシーンを記述してみましょう(^▽^)
筆者はこのようなプロンプトを記述しました。

すると以下のような画像が生成されました。

ここからはAnimeDiffとControlNetを併用することでダンスをしている動画像を生成しようと思います。
2. 動きの参考にする動画像を見つける
参考にする動画は以下の条件を満たしていることを推奨します。※精度を向上させるため
・全身が映っている。
・正面を向いている。
・回転などの動作がない。
今回はダンスをしているフリー素材を動きの参考にしようと思います。

3. 参考にしたい動画を下記の「Video source」部分にドロップorアップロードします。
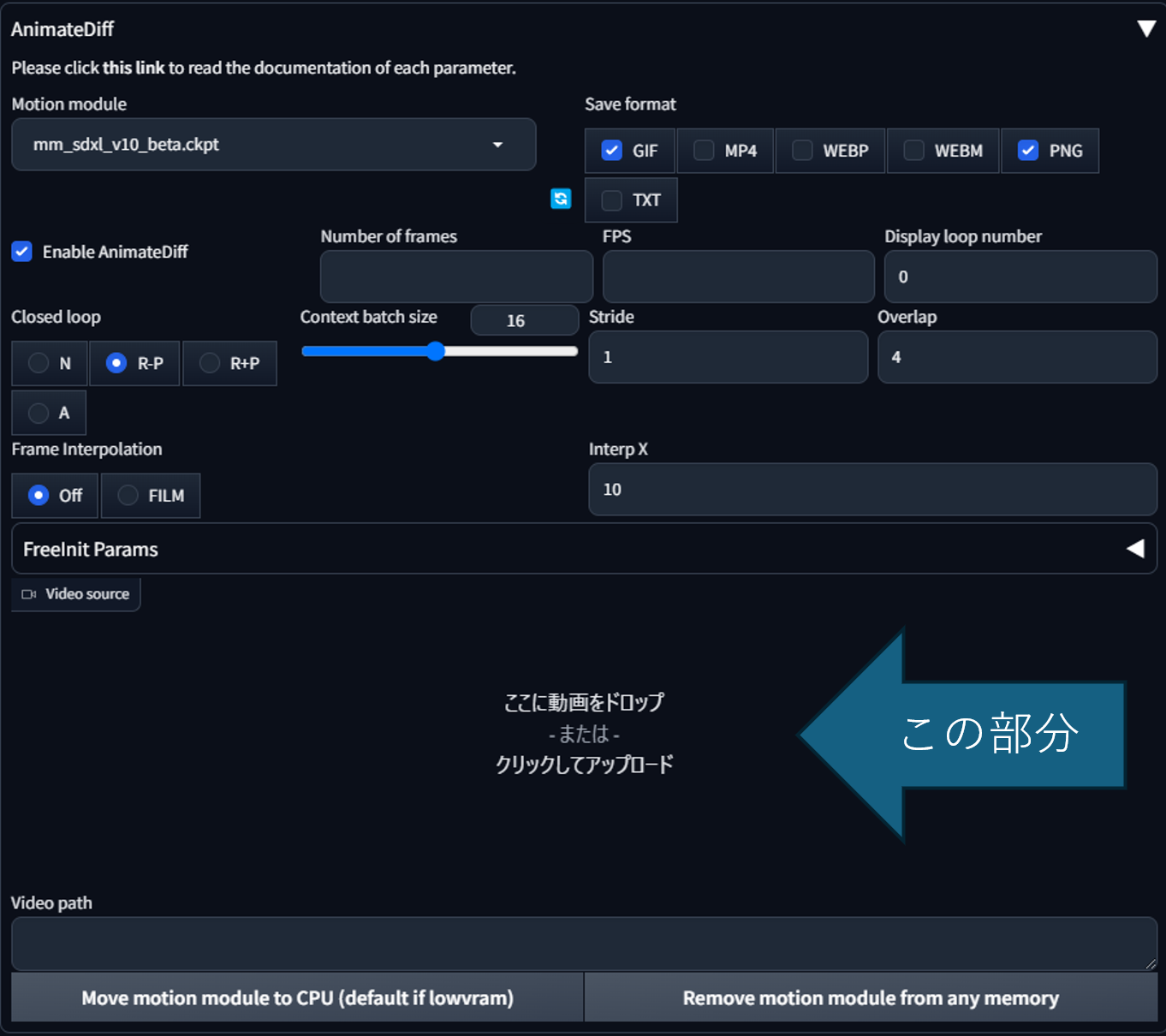
この際「Number of frames」と「FPS」は選択した動画と同じ数値である必要があります。
※自動的にシステム側で設定してくれるので触らなければ基本問題ないはずです。
4. ControlNetの設定を行う
今回はダンス中の人骨格を抽出するためにdw_openposeを使います。
又dw_openposeで取得できなかった部分を補正するためにdepthを使用します。
チェックボックス群を以下の図のように設定します。
また「Preprocessor」を[dw_openpose_full]に「Model」を[thibaud_xl_openpose.safetensors]に設定します。

次にUnitタブを変更し、チェックボックス群を同様に設定します。
そして「Preprocessor」を[depth]に「Model」を[diffusers_xl_depth_full.safetensors]に設定します。
ControlNetの機能は多岐にわたるため、ここでは多くは説明しません。
より詳しいことが知りたい場合、下記のサイトがおすすめです。
※ほかの解説サイトよりも各内容が詳しく記述されているので、おすすめです。
5. 動画像生成を実行する
画像生成と同じ要領で生成できます。
SDXLを用いた動画像生成は非常に時間がかかると思われます。
本当に想像している10倍以上の時間がかかるので気長に待ちましょう。( ;∀;)
コンソールを見るとしばらく固まっているような動きをするので、失敗したかのように見えることがありますが、処理が重たいだけですので、気にせず放置してください。
筆者の環境では、18FPSの6秒動画を作るのに12時間かかりました。(;´Д`)
非常に長い時間を待つと次のようなものができました。

腕や足の動きは想定通りですが、動画像が全体的に不鮮明になっており、結果逆光した映像のようになっています。
原因として考えられるのは、SDXLは本来「1024×1024」の出力が想定されているところ、今回はGPUスペックの都合上「480×240」で生成したことによって生成画像にひずみが生じ、このような結果になったと考えられます。
そのため、GPUの性能を上げて「1024×768」で生成すれば、動画像が鮮明になると考えられます。
しかしその場合であっても、地面が分かれて別のビルになってしまっていること、背景の部分が安定せず、山がでた後に消えてしまう現象は再現されてしまうと考えられます。
これにてControlNetを使用した動画像生成は終了になります。
ヤタ━━━━━ヽ(゚∀゚)ノ━━━━━!!!!
おわりに(>_<)
皆様自身の望む動画像を生成することはできましたでしょうか?
今回は「Stability Matrix」の使用方法と「SDXL」を用いた画像生成、「AnimeDiff」を活用したSDXLアニメーション生成、「ContorolNet」と「AnimeDiff」を併用したSDXLアニメーションダンスモーション生成などを行ってきました。
SDXLアニメーションダンスモーション生成ではダンス動画をモチーフにしましたが、それ以外にも空手の型や新体操等の体全体が見えるものであれば比較的うまく作れると思います。しかし回転している人物もとにすると首や体があらぬ方向に曲がった動画像を生成することや洋服などが常に変化しているなどまだまだ発展途上な部分が多い技術になっています。
現状ではそれら発展途上な部分を別の技術(ControlNetのdepthなど)を使って補うことで一貫性のある動画を生成するのが関の山となっています。
ですが筆者自身、画像生成AI「Stable Diffusion」が発表された当時には自然な物体移動の再現や、キャラクターの一貫性を担保した動画像生成等がものの数年で達成されるとは想像できませんでした。
まだ組み合わされていない技術などもあることから、画像生成AIの進歩はしばらく続いていくのではないかと考えています。
※新たにSD3.5などの技術も開発されましたし…( ..)φメモメモ
これからも暇があればこの技術を触っていきたいと思っていますので今後ともよろしくお願いいたします。
ご拝読ありがとうございました。