1.目的
ライブラリSeabornを使いJupyter上でのグラフ表示の方法をメモする。
2.内容
##2-1 時系列データを表示する。
SEABORNを使い時系列グラフを描写する。
sample.py
import datetime
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import seaborn as sns
import pandas as pd
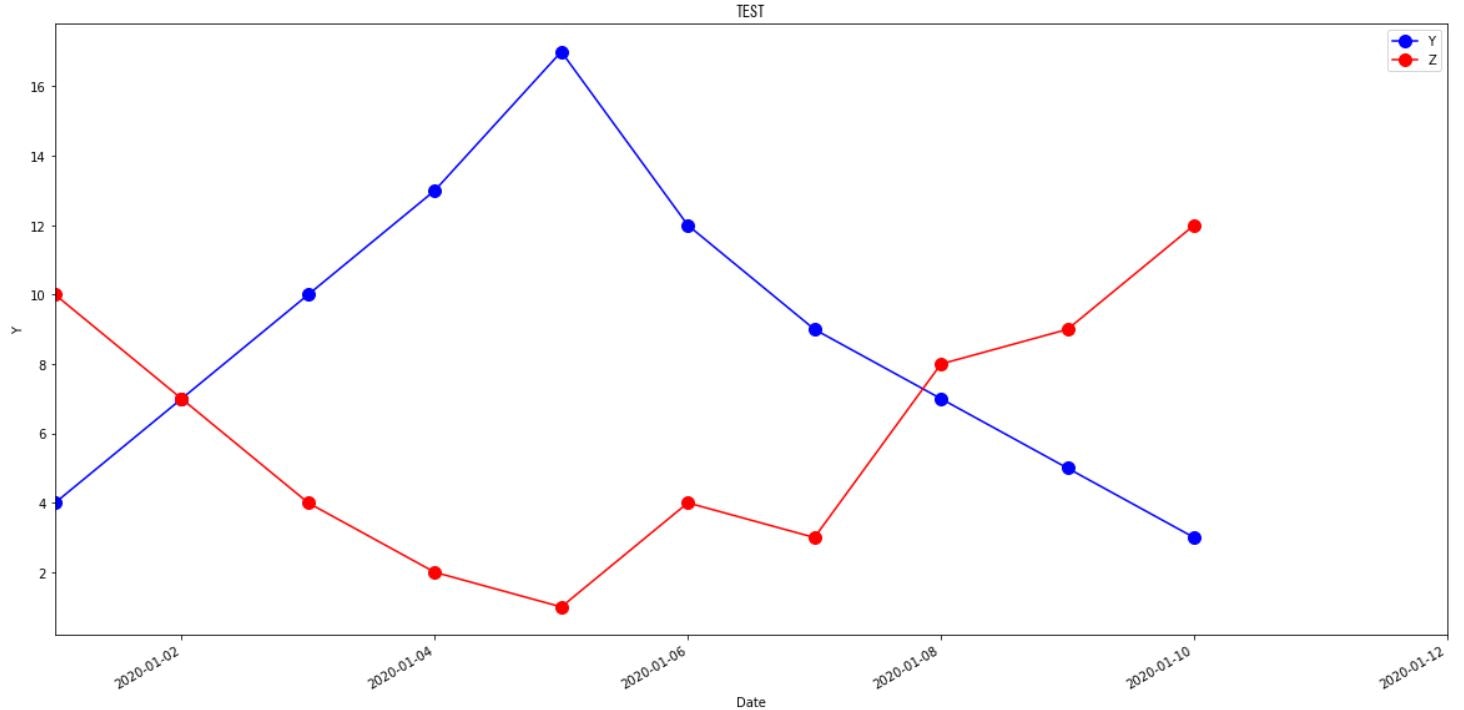
def dayseries(dat,COL,FIG,XLIMD,XLIMU):
dat['DATE'] = mdates.date2num(dat['DATE']) #ここを追加する Convert datetime objects to Matplotlib dates.
dat.set_index("DATE",inplace=True) #横軸に表示する日付をDataFrameのindexにする。
print(dat)
fig = sns.mpl.pyplot.figure() #グラフを描写するオブジェクトを生成する。
ax=dat.plot(marker="o",figsize=FIG)
ax.legend() #凡例を描写する
# グラフのフォーマットの設定(横軸の日付の表示方法を設定する。)
days = mdates.DayLocator(bymonthday=None, interval=INTERVAL, tz=None) # 横軸:「毎日」を表示対象にする。(この行がないと日付が重複表示される)
daysFmt = mdates.DateFormatter('%Y-%m-%d') #横軸:フォーマットをY-M-Dにする。
ax.xaxis.set_major_locator(days) #横軸に日付を表示する。
ax.xaxis.set_major_formatter(daysFmt) #横軸に日付を表示する。
fig.autofmt_xdate() #横軸の日付を見やすいように斜めにしてくれる。
# グラフに名前を付ける
ax.set_xlabel('Date') #X軸のタイトルを設定する
ax.set_ylabel('Y') #Y軸のタイトルを設定する
plt.title(r"TEST",fontname="MS Gothic") #グラフのタイトルを設定する。日本語を指定するときは、fontnameの指定が必要
#グラフのサイズを設定する
fig.set_figheight(10)
fig.set_figwidth(20)
#横軸の表示範囲を設定する
ax.set_xlim(XLIMD, XLIMU)
# Dataセットを定義する。(日付はdatetime.datetimeで記載する。日付型で表記する)
dat = [
[datetime.datetime(2020,1,1),4,10],
[datetime.datetime(2020,1,2),7,7],
[datetime.datetime(2020,1,3),10,4],
[datetime.datetime(2020,1,4),13,2],
[datetime.datetime(2020,1,5),17,1],
[datetime.datetime(2020,1,6),12,4],
[datetime.datetime(2020,1,7),9,3],
[datetime.datetime(2020,1,8),7,8],
[datetime.datetime(2020,1,9),5,9],
[datetime.datetime(2020,1,10),3,12],
]
COL=["DATE","Y","Z"] #datの行ラベルを定義する。0要素目は"DATE"にする。
XLIMD=datetime.datetime(2020,1,1) #横軸開始日
XLIMU=datetime.datetime(2020,1,14) #横軸終了日
FIG=[10,5] #グラフの大きさ
dat=pd.DataFrame(dat,columns=["DATE","Y","Z"]) #グラフ化するデータ系列
INTERVAL=5 #横軸日付表示間隔
#横軸日付け、縦軸データのグラフを書く。
dayseries(dat,COL,FIG,XLIMD,XLIMU)
実行結果
Y Z
DATE
2020-01-01 4 10
2020-01-02 7 7
2020-01-03 10 4
2020-01-04 13 2
2020-01-05 17 1
2020-01-06 12 4
2020-01-07 9 3
2020-01-08 7 8
2020-01-09 5 9
2020-01-10 3 12
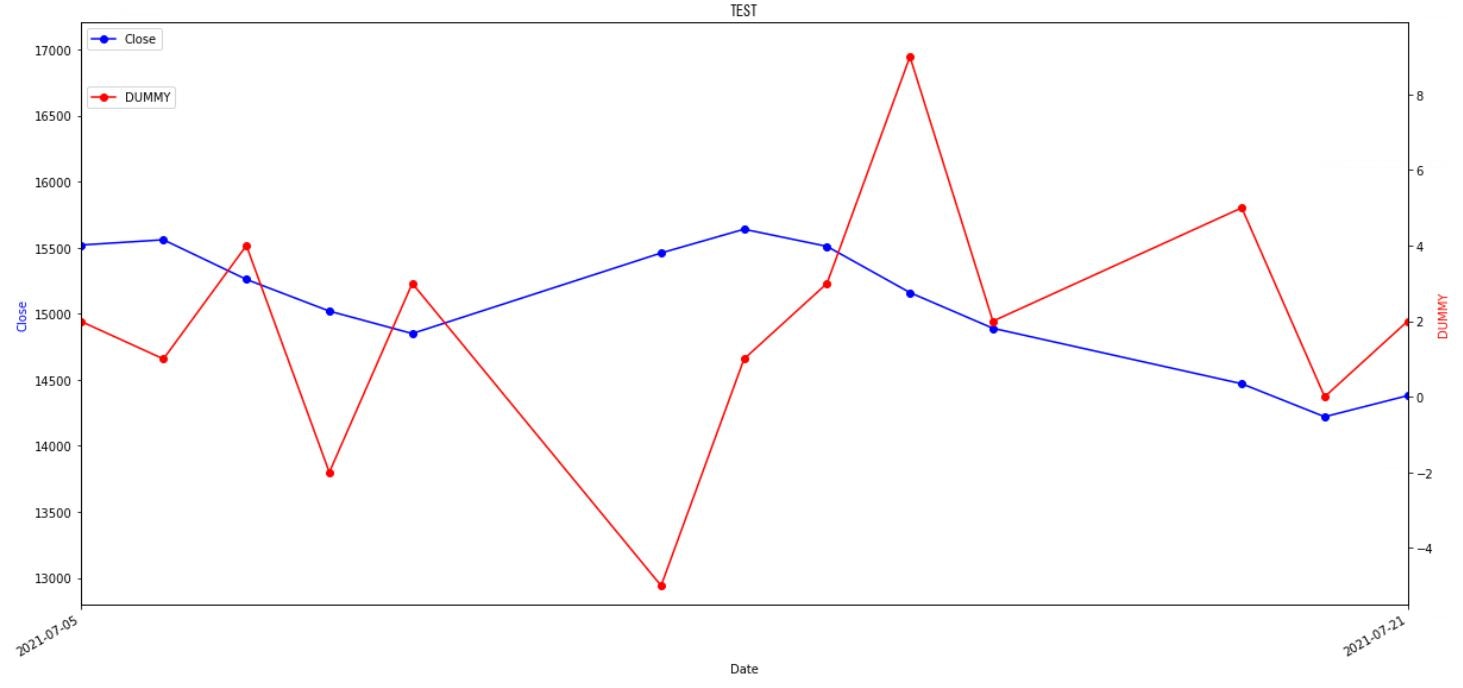
##2-1 時系列データを表示する(2軸データ)。
sample.py
#時系列グラフを表示する
def dayseries(dat,COL,FIG,XLIMD,XLIMU):
dat['Date'] = mdates.date2num(dat['Date']) #ここを追加する Convert datetime objects to Matplotlib dates.
#第一軸(ax1)と第二軸(ax2)を作って関連付ける
fig, ax1 = plt.subplots(figsize=FIG)
ax2 = ax1.twinx()
ax1.plot(dat[COL[0]], dat[COL[1]], marker ="o", linestyle = "-", color ="blue",label=COL[1])
ax2.plot(dat[COL[0]], dat[COL[2]], marker ="o", linestyle = "-", color ="red",label=COL[2])
ax1.set_ylim([np.min(dat[COL[1]])-np.abs(np.min(dat[COL[1]])*0.1),np.max(dat[COL[1]])*1.1])
ax2.set_ylim([np.min(dat[COL[2]])-np.abs(np.min(dat[COL[2]])*0.1),np.max(dat[COL[2]])*1.1])
ax1.set_ylabel(COL[1], color='blue')
ax2.set_ylabel(COL[2], color='red')
ax1.legend(bbox_to_anchor=(0, 1), loc='upper left', borderaxespad=0.5, fontsize=10)
ax2.legend(bbox_to_anchor=(0, 0.9), loc='upper left', borderaxespad=0.5, fontsize=10)
# グラフのフォーマットの設定(横軸の日付の表示方法を設定する。)
days = mdates.DayLocator(bymonthday=None, interval=INTERVAL, tz=None) # 横軸:「毎日」を表示対象にする。(この行がないと日付が重複表示される)
daysFmt = mdates.DateFormatter('%Y-%m-%d') #横軸:フォーマットをY-M-Dにする。
ax1.xaxis.set_major_locator(days) #横軸に日付を表示する。
ax1.xaxis.set_major_formatter(daysFmt) #横軸に日付を表示する。
fig.autofmt_xdate() #横軸の日付を見やすいように斜めにしてくれる。
# グラフに名前を付ける
ax1.set_xlabel('Date') #X軸のタイトルを設定する
plt.title(r"TEST",fontname="MS Gothic") #グラフのタイトルを設定する。日本語を指定するときは、fontnameの指定が必要
#グラフのサイズを設定する
fig.set_figheight(10)
fig.set_figwidth(20)
#横軸の表示範囲を設定する
ax1.set_xlim(XLIMD, XLIMU)
dat=[
[1570,"2021/7/5",15650,15670,15490,15520,2],
[1570,"2021/7/6",15620,15690,15500,15560,1],
[1570,"2021/7/7",15050,15340,15030,15260,4],
[1570,"2021/7/8",15200,15280,14990,15020,-2],
[1570,"2021/7/9",14620,14880,14240,14850,3],
[1570,"2021/7/12",15440,15500,15360,15460,-5],
[1570,"2021/7/13",15630,15780,15610,15640,1],
[1570,"2021/7/14",15410,15610,15370,15510,3],
[1570,"2021/7/15",15430,15480,15120,15160,9],
[1570,"2021/7/16",14840,15090,14700,14890,2],
[1570,"2021/7/19",14500,14650,14320,14470,5],
[1570,"2021/7/20",14200,14400,14140,14220,0],
[1570,"2021/7/21",14610,14730,14260,14380,2],
]
#datをDataFrame型変数dfに格納する。
df = pd.DataFrame(dat,columns=["Code","Date","Open","High","Low","Close","DUMMY"])
df['Date'] = pd.to_datetime(df['Date'], format='%Y/%m/%d') #文字列型を日付型に変更する
print("### 銘柄番号1305,1570の日足株価データ")
display(df)
COL=["Date","Close","DUMMY"]
XLIMD=datetime.datetime(2021,7,5) #横軸開始日
XLIMU=datetime.datetime(2021,7,21) #横軸終了日
dayseries(df.loc[:,COL],COL,FIG,XLIMD,XLIMU)
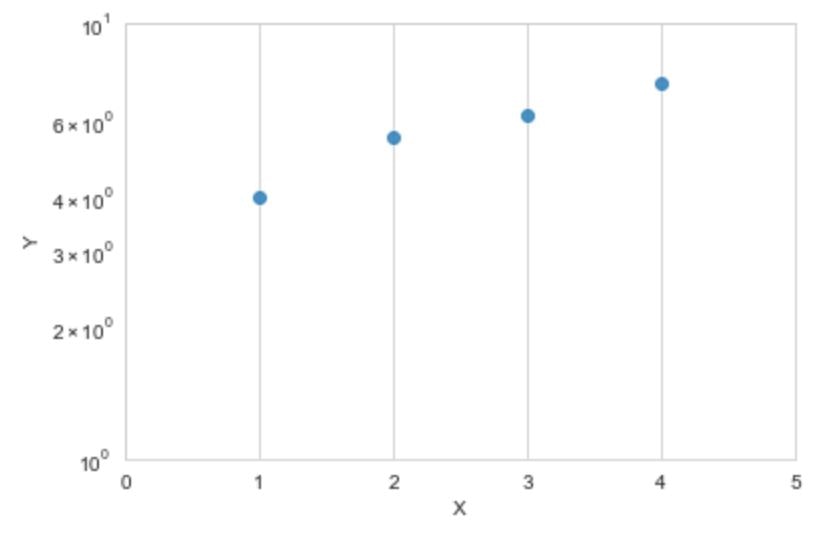
##2-2 散布図データを表示する。
sample.py
import seaborn as sns
sns.set_style("whitegrid")
df1 = pd.DataFrame({'X': [1, 2, 3,4,5],'Y': [4, 5.5, 6.2,7.3,7.8]})
sns.regplot('X', 'Y', data=df1,fit_reg=False)
ax.set_yscale("log") #Y軸をlog表記する。
ax.set_xlim(0, 5) #X軸の範囲を設定する。
ax.set_ylim(1, 10) #Y軸の範囲を設定する。
##2-3 ヒストグラム付き散布図を作成する。
sample.py
import pandas as pd
import numpy as np
#テスト用のデータを作成する。(2次元正規分布に従う乱数を発生させている。)
mean=[0,0]
cov=[[1,0],[0,10]]
dset=np.random.multivariate_normal(mean,cov,1000) #データを1000個発生させる
df=pd.DataFrame(dset,columns=['X','Y'])
# 背景を白に設定
sns.set(style="white", color_codes=True)
# グラフを出力
p=sns.jointplot(x="X", y="Y", data=df)
# グラフにタイトルを追加する。
p.fig.suptitle("Your title here")
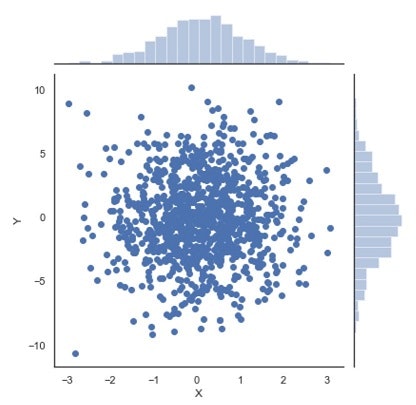
SEABOANを使わない場合
https://pythonyoutube.work/archives/5915380.html
##2-4 複数のグラフを並べる1
sample.py
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#テスト用のデータを作成する。(2次元正規分布に従う乱数を発生させている。)
mean=[0,0]
cov=[[1,0],[0,10]]
dset=np.random.multivariate_normal(mean,cov,1000) #データを1000個発生させる
df0=pd.DataFrame(dset,columns=['X','Y'])
df1=pd.DataFrame(dset,columns=['X','Y'])
fig,(axis1,axis2)=plt.subplots(1,2,sharey=True) #1行2列のグラフ配置場所を作る
sns.regplot('X','Y',df0,ax=axis1)
sns.regplot('X','Y',df0,ax=axis2)
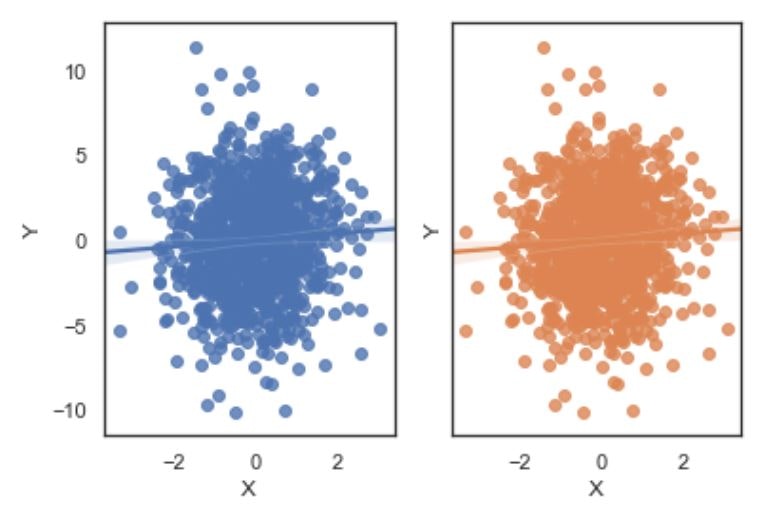
##2-5 複数のグラフを並べる2
sample.py
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(0, 6, 0.1)
y1 = np.sin(x)
y2 = np.cos(x)
plt.subplot(2,1,1)
plt.plot(x,y1)
plt.subplot(2,1,2)
plt.plot(x,y2)
plt.show()
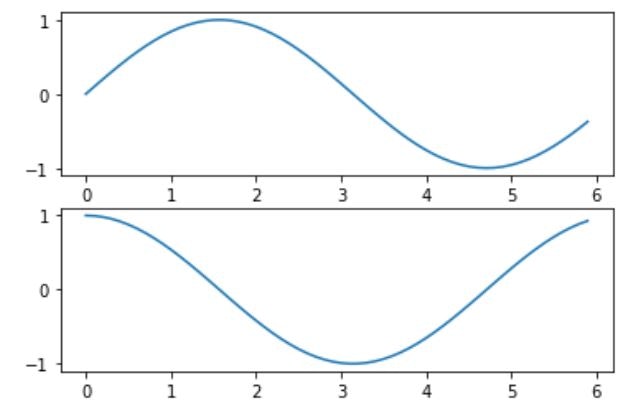
##2-5 複数のグラフを並べる3
sample.py
import datetime
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import seaborn as sns
import pandas as pd
# Dataセットを定義する。(日付はdatetime.datetimeで記載する。日付型で表記する)
dat = [
[4,10],
[7,7],
[10,4],
[13,2],
[17,1],
[12,4],
[9,3],
[7,8],
[5,9],
[3,12],
]
dat=pd.DataFrame(dat,columns=["Y","Z"])
datYave=np.mean(dat["Y"])
datZave=np.mean(dat["Z"])
fig, ax = plt.subplots(ncols=2, figsize=(15, 4))
sns.distplot(dat['Y'],ax=ax[0])
ax[0].set_xlabel('sample')
ax[0].set_ylabel('prob')
ax[0].set_xlim(-50, 50)
#ax[0].set_ylim(11, 16)
ax[0].set_title(f'sample | AVE: {datYave:.2f}');
sns.distplot(dat['Z'],ax=ax[1])
ax[1].set_xlabel('sample')
ax[1].set_ylabel('prob')
ax[1].set_xlim(-50, 50)
#ax[1].set_ylim(11, 16)
ax[1].set_title(f'sample | AVE: {datZave:.2f} | MAX: {dfhist_n_min:.2f}')
print(dat)
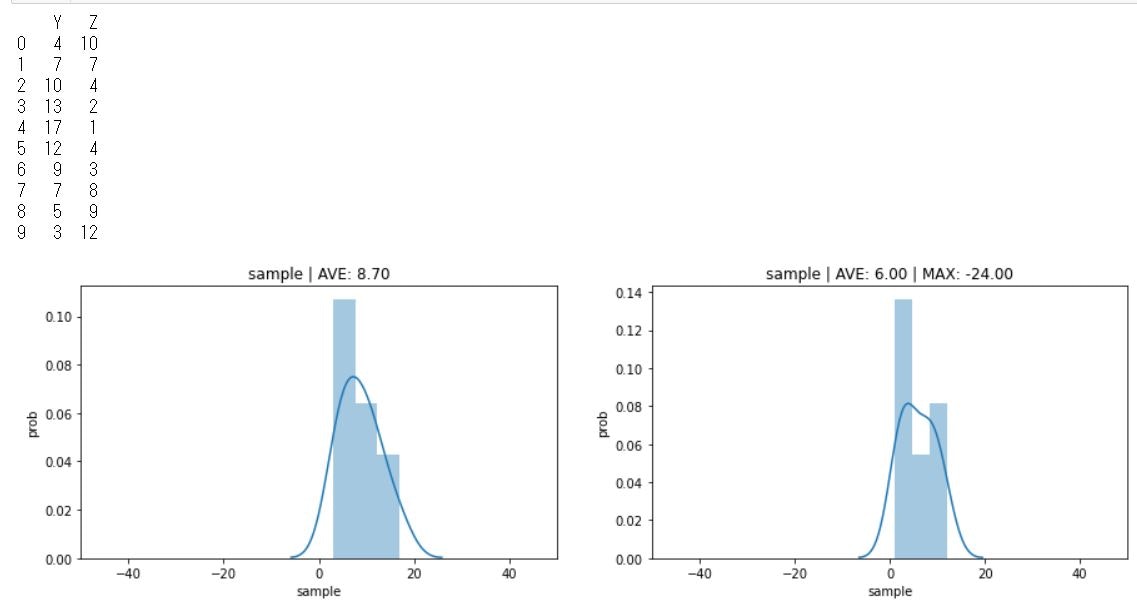
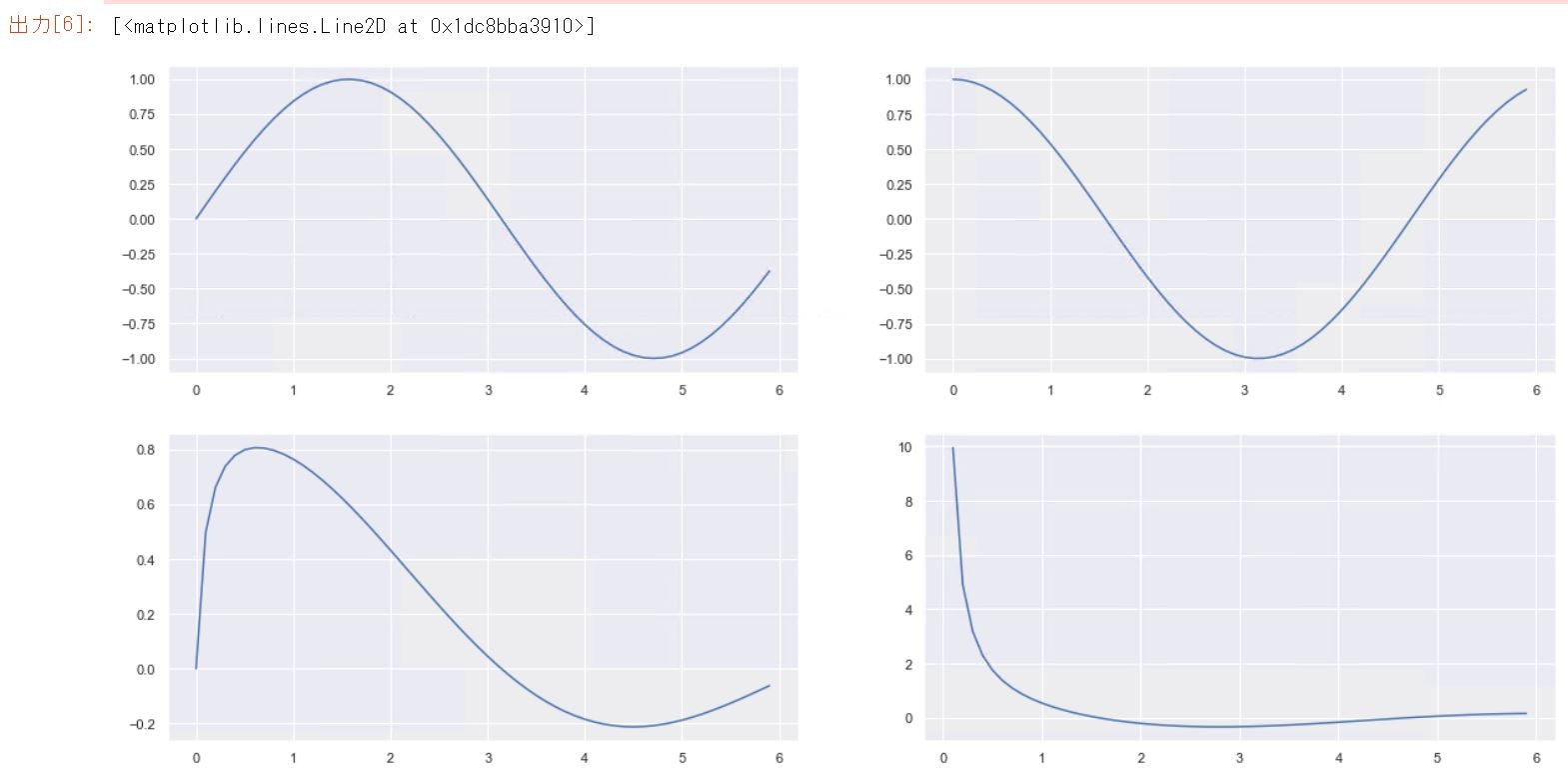
##2-5-1 複数のグラフを並べる4
sample.py
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
fig,axes = plt.subplots(nrows=2,ncols=2,figsize=(20,10))
x = np.arange(0, 6, 0.1)
y1 = np.sin(x)
y2 = np.cos(x)
y3 = np.sin(x)/(x+0.1)
y4 = np.cos(x)/x
axes[0,0].plot(x,y1)
axes[0,1].plot(x,y2)
axes[1,0].plot(x,y3)
axes[1,1].plot(x,y4)
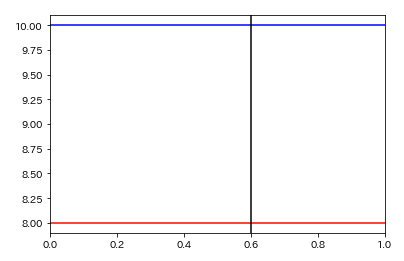
##2-6 グラフにラインをひく
sample.py
import datetime
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import seaborn as sns
import pandas as pd
import numpy as np
plt.axhline(8,c='r') #8に水平ラインを引く
plt.axhline(10,c='b') #10に水平ラインを引く
plt.axvline(0.6,c='black') #10に垂直ラインを引く
実行結果
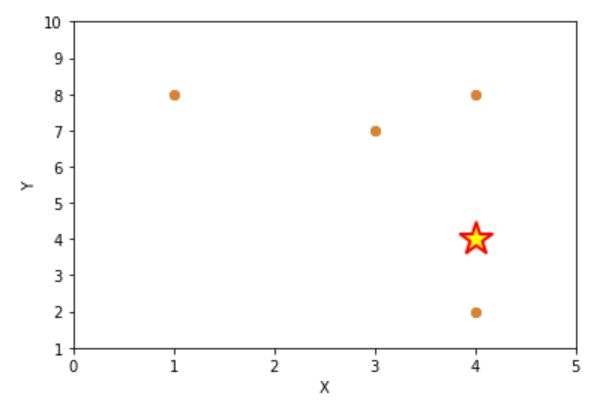
##2-5 1点データをプロットする。
1点のみプロットの場合は、replotは使用できないので(データセット).plotを使用する
sample.py
import numpy as np
import pandas as pd
import seaborn as sns
#サンプルデータの定義
dat = [
[1,8],
[4,2],
[7,6],
[4,8],
[20,15],
[3,7]
]
dat1=[[4,4]]
df0 = pd.DataFrame(dat,columns=["X","Y"]) #第1データセット
df1 = pd.DataFrame(dat1,columns=["X","Y"]) #第2データセット
ax=sns.regplot('X', 'Y', data=df0,fit_reg=False) #第1データセット
ax.set_xlim(0, 5) #X軸の範囲を設定する。
ax.set_ylim(1, 10) #Y軸の範囲を設定する。
#第2データセットをプロットする。
#1点のみプロットの場合は、replotは使用できないので(データセット).plotを使用する。
df1.plot(kind="scatter",x="X", y="Y",s=500,c="yellow",marker="*", alpha=1, linewidths=2,edgecolors="red",ax=ax)
#sはマークの大きさ,alphaは透明度(0:透明,1:不透明)
実行結果
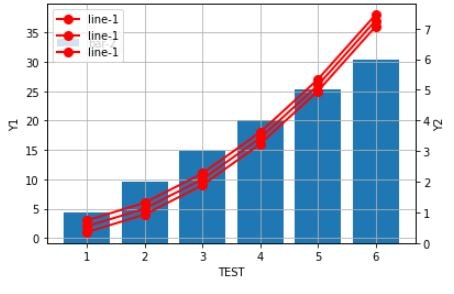
##2-6 2軸データをプロットする。(1軸折れ線、2軸棒グラフ)
sample.py
def test_plot(x,y1,y2,xtitle,y1title,y2title,label):
#第一軸(ax1)と第二軸(ax2)を作って関連付ける
fig, ax1 = plt.subplots(figsize=(10, 8))
ax2 = ax1.twinx()
#第一軸を折れ線グラフ、第二軸を棒グラフに
for i in range(0,len(y1)):
ax1.plot(x, y1[i], linewidth=2, color="red", linestyle="solid", marker="o", markersize=8, label=label[i])
ax2.bar(x, y2, label='bar-2')
#y軸の範囲 今回は第二軸のみとした
ax2.set_ylim([np.min(y2)*0,np.max(y2)*1.3])
#重ね順として折れ線グラフを前面に。
#そうしないと棒グラフに折れ線が隠れてしまうので。
ax1.set_zorder(2)
ax2.set_zorder(1)
#折れ線グラフの背景を透明に。
#そうしないと重ね順が後ろに回った棒グラフが消えてしまう。
ax1.patch.set_alpha(0)
#凡例を表示(グラフ左上、ax2をax1のやや下に持っていく)
ax1.legend(bbox_to_anchor=(0, 1), loc='upper left', borderaxespad=0.5, fontsize=10)
ax2.legend(bbox_to_anchor=(0, 0.9), loc='upper left', borderaxespad=0.5, fontsize=10)
#グリッド表示(ax1のみ)
ax1.grid(True)
#軸ラベルを表示
ax1.set_xlabel(xtitle)
ax1.set_ylabel(y1title)
ax2.set_ylabel(y2title)
#グラフ表示
plt.show()
#dataを定義する。
dat = [
[1,1,1],
[2,4,2],
[3,9,3],
[4,16,4],
[5,25,5],
[6,36,6],
]
#datをDataFrame型変数dfに格納する。
df = pd.DataFrame(dat,columns=["A","B","C"])
x=df["A"]
y1=(df["B"],df["B"]+1,df["B"]+2) #第1軸のデータ(4系列まで配置可能)
y2=df["C"] #第2軸のデータ
xtitle='TEST' #X軸ラベル
y1title='Y1' #第1軸のラベル
y2title='Y2' #第2軸のラベル
label=["l1","l2","l3"] #第1軸のデータ凡例(4系列まで配置可能)
#グラフを描写する。
test_plot(x,y1,y2,xtitle,y1title,y2title,label)
実行結果
##2-6 円グラフの書き方
sample.py
import matplotlib.pyplot as plt
df_pie = pd.DataFrame([[1, 50,3,54],
[2, 20,15,3],
[3, 30,32,12]],
index=['a', 'b', 'c'], columns=['ONE', 'TWO','THREE','FOUR'])
display(df_pie)
fig, ax = plt.subplots(2,2, figsize=(20, 10))
df_pie['ONE'].plot.pie(subplots=True,counterclock=False, startangle=90,ax=ax[0,0],autopct="%1.1f%%")
df_pie['TWO'].plot.pie(subplots=True,counterclock=False, startangle=90,ax=ax[0,1],autopct="%1.1f%%")
df_pie['THREE'].plot.pie(subplots=True,counterclock=False, startangle=90,ax=ax[1,0],autopct="%1.1f%%")
df_pie['FOUR'].plot.pie(subplots=True,counterclock=False, startangle=90,ax=ax[1,1],autopct="%1.1f%%")
ax[0,0].set_title("EX1")
ax[0,1].set_title("EX2")
ax[1,0].set_title("EX3")
ax[1,1].set_title("EX4")
実行結果
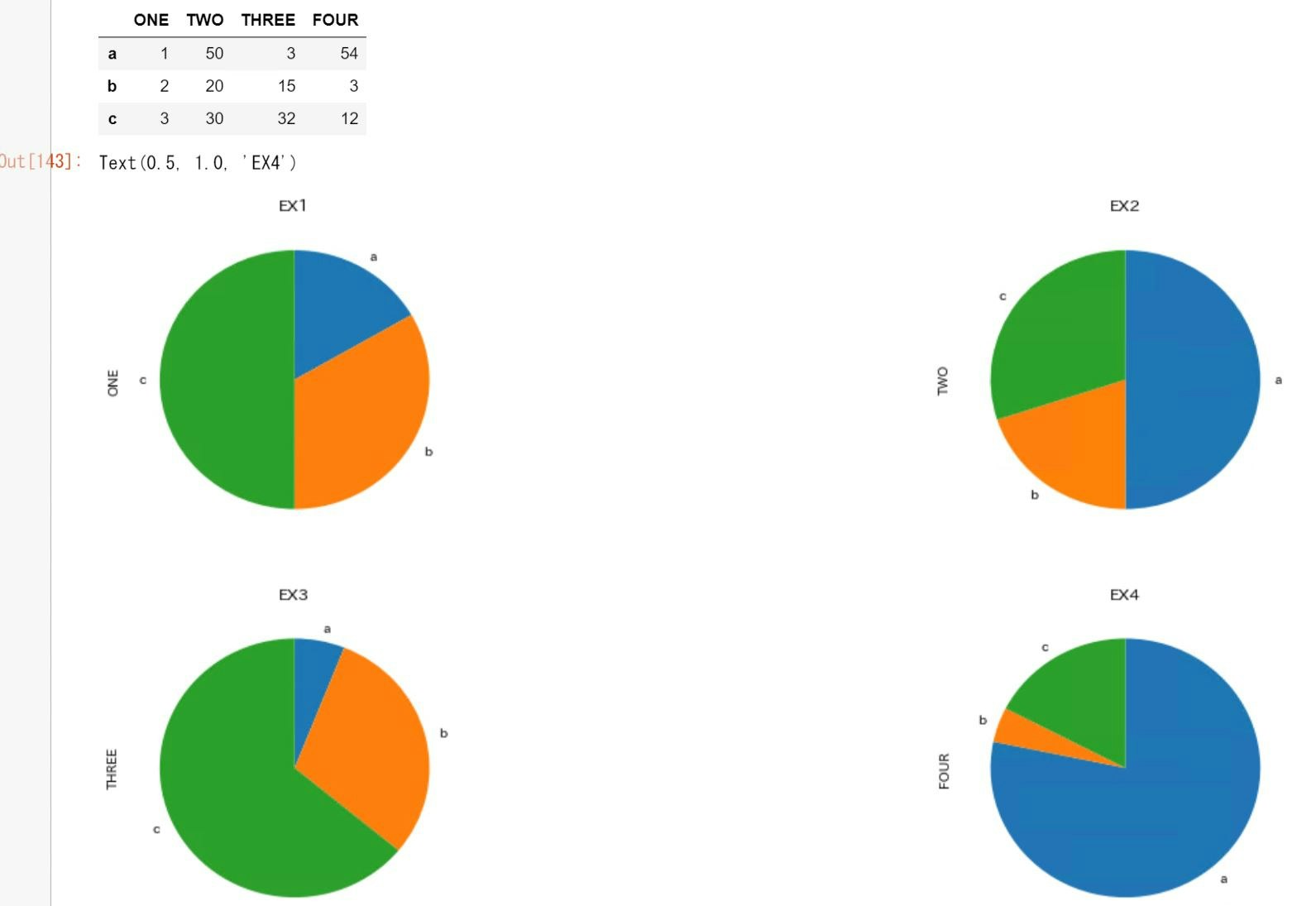
##2-7 単純棒グラフの書き方
sample.py
import pandas as pd
import matplotlib.pyplot as plt
data=[["Rudra",23,156,70],
["Nayan",20,136,60],
["Alok",15,100,35],
["Prince",30,150,85]
]
df=pd.DataFrame(data,columns=["Name","Age","Height(cm)","Weight(kg)"])
df=df.set_index("Name")
display(df)
df.plot(y=["Age"], kind="bar",figsize=(9,8))
plt.show()
実行結果
##2-8 Heatmapグラフの書き方
sample.py
import pandas as pd
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
dict1={"X":[1,2,3],"Y":[4,5,6]}
print("dict型変数 dict1を表示する")
print(dict1)
dict1=pd.DataFrame(dict1,columns=['X', 'Y'])
print("DataFrane型 dict1を表示する")
display(dict1)
plt.figure(figsize=(9, 6))
sns.heatmap(dict1)
#コメント カラーマップを配置をLog型にしたい場合
#sns.heatmap(df_numt,cmap='Blues',norm=LogNorm()) と記述する
実行結果
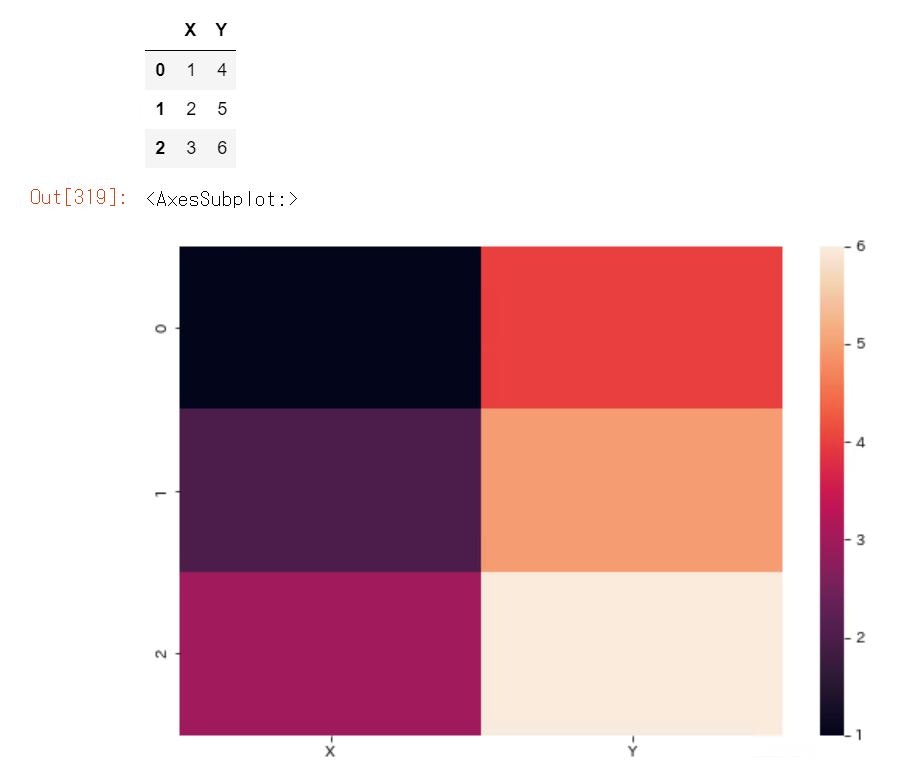
##2-9 ヒストグラムの書き方
sample.py
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#ヒストグラムを描写する
def makehist(dat,FIG,COL): #dat:描写するデータ, FIG:描写するサイズ, COL:データ名
fig = plt.figure(figsize=FIG)
ax = fig.add_subplot(1,1,1)
ax.hist(dat, bins=20,label=COL) #binは階級数
ax.set_xlabel(COL)
ax.set_ylabel('fleq')
plt.title(COL,fontname="MS Gothic") #グラフのタイトルを設定する。日本語を指定するときは、fontnameの指定が必要
fig.show()
# 平均 50, 標準偏差 10 の正規乱数を1,000件生成
x = np.random.normal(50, 10, 1000)
COL="NONE"
FIG=(15,9)
makehist(x,FIG,COL)
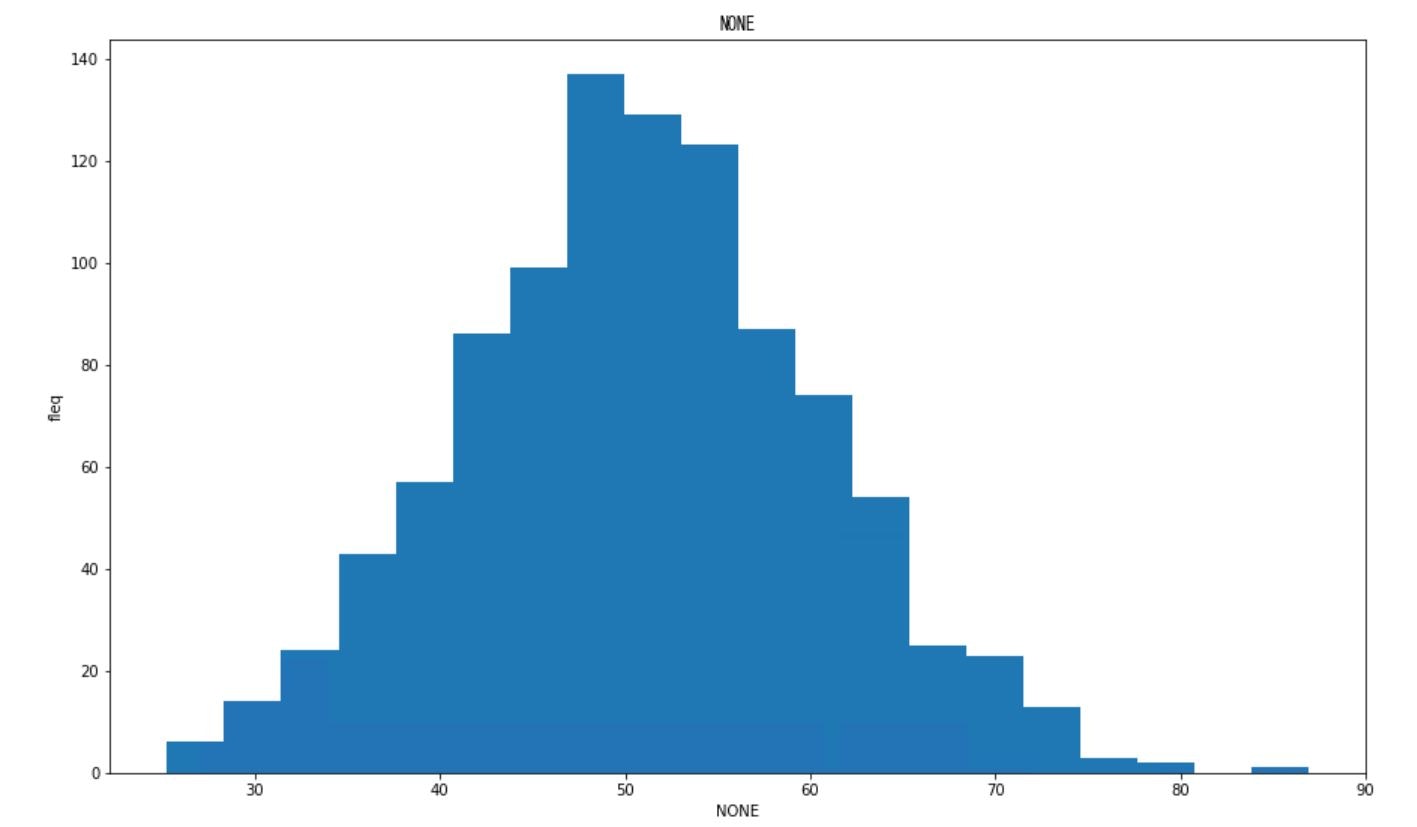
#3 統計処理の方法
##3-1 カーネル密度関数の書き方
カーネル密度関数の説明
https://www.ie-kau.net/entry/kernel_density_est
/home/sampletest/sample.py
from numpy.random import randn
import seaborn as sns
import numpy as np
dataset=randn(100) #一様分布に従う乱数を100個発生させる。
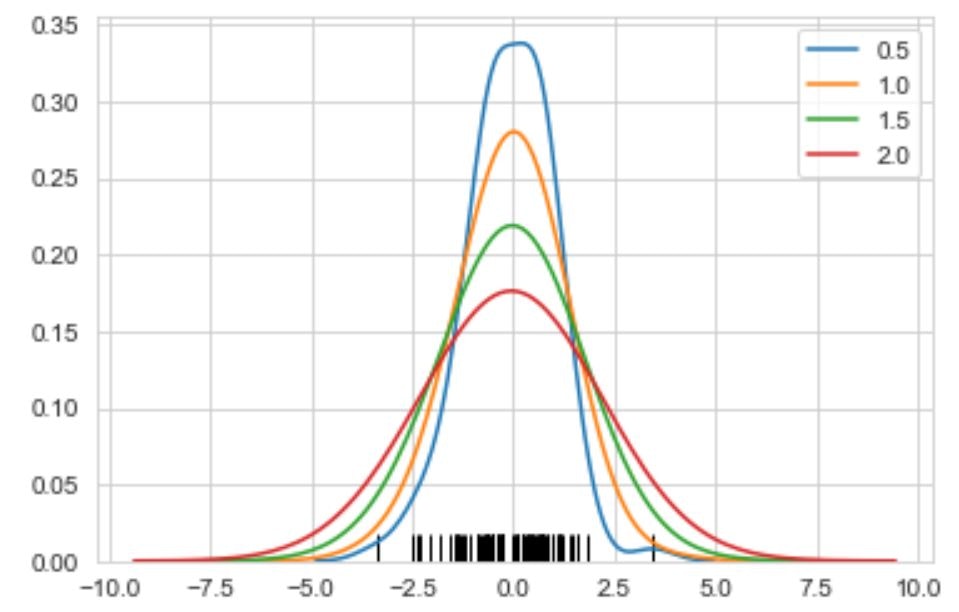
sns.kdeplot(dataset)
sns.rugplot(dataset,color='black') #datasetをプロットしている。
for bw in np.arange(0.5,2.5,0.5): #バンド幅を0.5,1.0,1.5,2.0まで変化させてカーネル密度関数を書く
sns.kdeplot(dataset,bw=bw,label=bw)